oj题 ——— 单链表oj题
单链表oj题
移除链表元素
203. 移除链表元素 - 力扣(LeetCode)
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
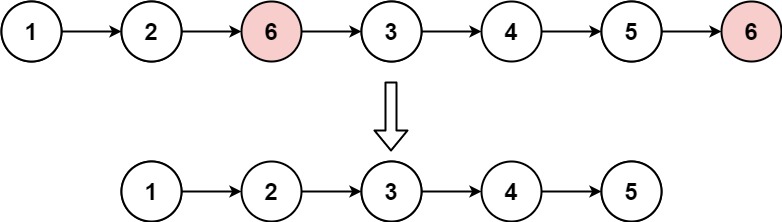
输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1 输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7 输出:[]
代码演示:
struct ListNode* removeElements(struct ListNode* head, int val)
{if(head == NULL)return NULL;struct ListNode* cur = head;struct ListNode* prev = NULL;while(cur != NULL){if(cur->val == val){if(cur == head) //头删{head = cur->next;free(cur);cur = head;}else{prev->next = cur->next;free(cur);cur = prev->next;}}else{prev = cur;cur = cur->next;}}return head;
}代码解析:
1. 定义双指针辅助遍历与删除
使用两个指针cur和prev:
cur:从链表头节点开始,逐个遍历节点,用于检查当前节点的值是否为val(即是否需要删除)。prev:始终指向cur的前一个节点(仅在cur不是头节点时有效),作用是在cur需要删除时,通过prev调整链表的连接关系,避免删除后链表断裂。
2. 遍历链表并删除目标节点
通过while(cur != NULL)循环遍历整个链表(直到cur指向NULL,即遍历完所有节点),根据cur->val是否等于val分两种情况处理:
情况一:当前节点需要删除(cur->val == val)
此时需删除cur指向的节点,根据cur是否为头节点,处理方式不同:
-
若
cur是头节点(cur == head):头节点没有前一个节点,删除时需直接更新头指针:- 让
head指向cur->next(将头节点更新为当前节点的下一个节点,即新头节点); - 调用
free(cur)释放被删除节点的内存(避免内存泄漏); - 让
cur指向新的头节点(cur = head),继续遍历剩余节点。
- 让
-
若
cur不是头节点:此时prev已记录cur的前一个节点,通过prev调整指针连接:- 让
prev->next指向cur->next(前一个节点的next跳过cur,直接连接到cur的下一个节点,断开cur与链表的联系); - 调用
free(cur)释放被删除节点的内存; - 让
cur指向prev->next(即被删除节点的下一个节点),继续遍历。
- 让
情况二:当前节点无需删除(cur->val != val)
此时cur是有效节点,无需删除,只需将prev和cur依次后移,继续检查下一个节点:
prev移动到当前cur的位置(prev = cur);cur移动到下一个节点(cur = cur->next)。
3. 返回处理后的头节点
循环结束后,所有值为val的节点已被删除,head指向调整后的链表头节点(可能已不是原头节点,若原头节点被删除),因此返回head作为结果。
链表的中间节点
876. 链表的中间结点 - 力扣(LeetCode)
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:

输入:head = [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个中间结点,值为 3 。
示例 2:

输入:head = [1,2,3,4,5,6] 输出:[4,5,6] 解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。
代码演示:
struct ListNode* middleNode(struct ListNode* head)
{if (head == NULL)return NULL;struct ListNode* slow = head;struct ListNode* fast = head->next;while (slow != NULL && fast != NULL && fast->next != NULL){slow = slow->next;fast = fast->next->next;}if(fast == NULL)return slow;elsereturn slow->next;
}代码解析:
1. 空链表边界处理
代码先判断if (head == NULL),若链表为空(头节点是NULL),直接返回NULL。这一步是避免后续指针操作时访问空地址,提前处理无节点的特殊情况。
2. 快慢指针的初始化
- 慢指针(
slow):从head(头节点)开始,作用是最终定位中间节点,每次只向后移动 1 步。 - 快指针(
fast):从head->next(头节点的下一个节点)开始,作用是快速遍历到链表末尾,每次向后移动 2 步。这种初始位置设计是关键 —— 能确保链表长度为偶数时,最终返回的是第二个中间节点(符合题目要求)。
3. 循环移动指针:让快指针先到末尾
循环条件是slow != NULL && fast != NULL && fast->next != NULL,目的是防止快指针移动时访问空指针(比如fast已到最后一个节点,再执行fast->next->next会出错)。循环内部:
slow = slow->next:慢指针每次走 1 步;fast = fast->next->next:快指针每次走 2 步。因为快指针速度是慢指针的 2 倍,当快指针接近末尾时,慢指针会自然停在中间位置附近。
4. 根据快指针位置确定中间节点
循环结束后,快指针的位置能反映链表长度的奇偶性,进而确定返回值:
- 若
fast == NULL:说明链表长度是奇数(比如示例 1 的 5 个节点)。此时慢指针slow正好指向唯一的中间节点,直接返回slow。 - 若
fast != NULL:说明链表长度是偶数(比如示例 2 的 6 个节点)。此时快指针fast指向最后一个节点,慢指针slow指向第一个中间节点,按题目要求返回slow->next(第二个中间节点)。
合并两个有序链表
21. 合并两个有序链表 - 力扣(LeetCode)
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
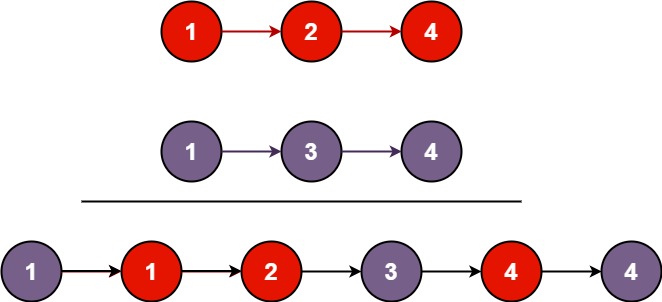
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = [] 输出:[]
示例 3:
输入:l1 = [], l2 = [0] 输出:[0]
代码演示:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{if (list1 == NULL)return list2;if (list2 == NULL)return list1;struct ListNode* retList = NULL, * cur = NULL;while (list1 != NULL && list2 != NULL){if (list1->val < list2->val){if (retList == NULL){retList = cur = list1;}else{cur->next = list1;cur = cur->next;}list1 = list1->next;}else{if (retList == NULL){retList = cur = list2;}else{cur->next = list2;cur = cur->next;}list2 = list2->next;}}if (list1 != NULL)cur->next = list1;if (list2 != NULL)cur->next = list2;return retList;
}代码解析:
1. 先处理空链表的特殊情况
如果其中一个链表是空的(比如list1为NULL),直接返回另一个链表即可 —— 因为空链表和任何链表合并,结果都是那个非空链表。如果两个都是空链表,最终也会返回空,符合题目要求。
2. 用两个指针追踪新链表的状态
定义了retList和cur两个指针:
retList用来记录合并后新链表的头节点,最后作为结果返回;cur用来追踪新链表当前的末尾位置,方便后续拼接新的节点,保证链表的连续性。
3. 循环比较两个链表的节点,按升序拼接
当两个链表都还有剩余节点时,进入循环,每次比较两个链表当前节点的值:
- 如果
list1的当前节点值更小,就把这个节点接到新链表的末尾。如果新链表还没有头节点(retList为空),就把这个节点作为头节点,同时让cur指向它;如果已有头节点,就通过cur的next指针把节点接在后面,再让cur后移到这个新节点。之后list1后移,继续处理下一个节点。 - 如果
list2的当前节点值更小或相等,处理逻辑和上面类似,只是拼接的是list2的节点,之后list2后移。
4. 拼接剩余节点
当其中一个链表的节点全部处理完(变成NULL),循环结束。此时另一个链表剩下的节点都是升序的,直接通过cur的next指针把这些剩余节点接到新链表末尾即可。
链表的中间结点
876. 链表的中间结点 - 力扣(LeetCode)
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:

输入:head = [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个中间结点,值为 3 。
示例 2:

输入:head = [1,2,3,4,5,6] 输出:[4,5,6] 解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。
代码演示:
struct ListNode* middleNode(struct ListNode* head)
{if (head == NULL)return NULL;struct ListNode* slow = head;struct ListNode* fast = head->next;while (slow != NULL && fast != NULL && fast->next != NULL){slow = slow->next;fast = fast->next->next;}if(fast == NULL)return slow;elsereturn slow->next;
}代码解析:
1. 边界处理:空链表直接返回 NULL
代码开头判断if (head == NULL),若链表为空(头节点head是NULL),则不存在中间节点,直接返回NULL。这一步是为了避免后续指针操作访问空地址,提前拦截无效场景。
2. 初始化快慢指针:关键的初始位置设计
定义两个指针,初始位置的差异是 “偶数长度返回第二个中间节点” 的核心:
- 慢指针(
slow):从head(头节点)开始,每次循环移动 1 步,最终用于定位中间节点附近; - 快指针(
fast):从head->next(头节点的下一个节点)开始,每次循环移动 2 步,用于快速遍历到链表末尾,通过速度差带动slow定位。
这种初始位置设计,能确保后续循环结束时,即使链表长度为偶数,也能精准返回第二个中间节点(符合题目要求)。
3. 循环移动指针:通过速度差逼近中间位置
循环条件为while (slow != NULL && fast != NULL && fast->next != NULL),循环内每次按速度移动指针:
- 循环条件的作用:
slow != NULL:防止slow意外为空(实际因fast先到末尾,slow不会先空,属于兜底);fast != NULL+fast->next != NULL:确保fast移动 2 步时不会访问空指针(若fast->next为NULL,fast->next->next会崩溃,因此提前终止循环)。
- 指针移动逻辑:
slow = slow->next:慢指针每次走 1 步;fast = fast->next->next:快指针每次走 2 步(速度是慢指针的 2 倍)。
通过 “速度差”,当fast逐渐逼近链表末尾时,slow会自然向中间位置移动。
4. 根据快指针位置返回结果:区分链表长度奇偶性
循环结束后,fast的位置能直接反映链表长度的奇偶性,进而确定中间节点:
-
情况 1:
fast == NULL→ 链表长度为奇数此时fast已走到链表末尾(如示例 1:head = [1,2,3,4,5],长度 5),slow恰好指向唯一的中间节点(示例 1 中slow指向 3),因此返回slow。 -
情况 2:
fast != NULL→ 链表长度为偶数此时fast停在链表的最后一个节点(fast->next为NULL,如示例 2:head = [1,2,3,4,5,6],长度 6),slow指向第一个中间节点(示例 2 中slow指向 3),根据题目要求返回第二个中间节点,即slow->next(示例 2 中为 4)。
核心逻辑总结
快慢指针的 “速度差”(2 倍)是找到中间节点的基础,而fast初始位置(head->next)和循环后的判断逻辑,是满足 “偶数长度返回第二个中间节点” 的关键。整个过程仅遍历链表一次,时间复杂度 O (n),空间复杂度 O (1),是高效且简洁的实现方式。
反转链表
206. 反转链表 - 力扣(LeetCode)
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
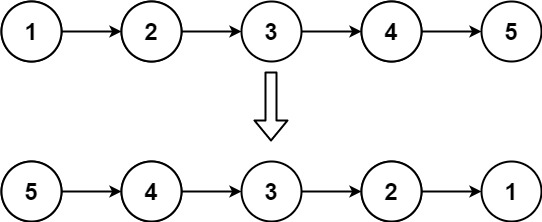
输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]
示例 2:
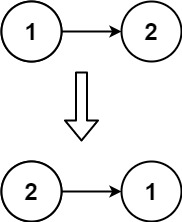
输入:head = [1,2] 输出:[2,1]
示例 3:
输入:head = [] 输出:[]
解法一:反转节点的指针方向
代码演示:
struct ListNode* reverseList(struct ListNode* head)
{if (head == NULL)return NULL;struct ListNode* n1 = NULL;struct ListNode* n2 = head;struct ListNode* n3 = NULL;while (n2 != NULL){n3 = n2->next;n2->next = n1;n1 = n2;n2 = n3;}return n1;
}代码解析:
1. 边界处理:空链表直接返回 NULL
代码开头判断if (head == NULL),如果链表为空(头节点head是NULL),则直接返回NULL。这是因为空链表没有节点可反转,提前处理可避免后续指针操作出错。
2. 定义三指针:追踪前、中、后三个节点
代码中定义了三个指针,分工明确:
n1:指向当前节点的前一个节点(初始为NULL,因为原链表的头节点反转后会变成尾节点,尾节点的next是NULL);n2:指向当前正在处理的节点(初始为head,即从原链表的头节点开始处理);n3:指向当前节点的后一个节点(用于临时保存n2的下一个节点,避免反转n2的指针后丢失后续节点)。
3. 核心循环:逐个反转节点的指针方向
循环条件为while (n2 != NULL)(只要当前节点n2存在,就继续处理),每次循环完成一个节点的反转,步骤如下:
-
保存当前节点的下一个节点:
n3 = n2->next—— 将n2的下一个节点(n2->next)保存到n3,防止后续修改n2->next后,无法找到原链表的下一个节点。 -
反转当前节点的指针:
n2->next = n1—— 让当前节点n2的next指针指向它的前一个节点n1,完成当前节点的反转(例如,原节点 2 的next是 3,反转后指向 1)。 -
移动指针,准备处理下一个节点:
n1 = n2——n1后移到n2的位置(成为下一个节点的 “前一个节点”);n2 = n3——n2后移到n3的位置(成为新的 “当前节点”)。
4. 返回反转后的头节点
当循环结束时,n2会变为NULL(所有节点都已处理完毕),此时n1恰好指向原链表的最后一个节点(即反转后链表的新头节点),因此返回n1。
解法二:找到尾节点后头插
代码演示:
struct ListNode* reverseList(struct ListNode* head)
{if (head == NULL)return NULL;// 找尾节点struct ListNode* tail = head;while (tail->next != NULL)tail = tail->next;// 头插struct ListNode* cur = head;struct ListNode* curnext = NULL;while (cur != tail){curnext = cur->next;cur->next = tail->next;tail->next = cur;cur = curnext;}return tail;
}代码解析:
1. 边界处理:空链表直接返回 NULL
代码开头判断if (head == NULL),若链表为空(头节点head是NULL),则直接返回NULL。这是因为空链表没有节点可反转,提前处理可避免后续操作出错。
2. 第一步:找到原链表的尾节点(作为反转后链表的头节点)
- 作用:通过循环让
tail指针从head开始向后移动,直到tail->next == NULL(即tail指向原链表的最后一个节点)。 - 意义:原链表的尾节点,在反转后会成为新链表的头节点(例如原链表
1->2->3->4->5,尾节点是5,反转后新头节点就是5)。
3. 第二步:通过头插法,将原链表节点依次插入到尾节点后
这是反转的核心步骤,通过循环将原链表的节点从头部开始,逐个 “移动” 到tail的后面,从而实现顺序反转,具体逻辑如下:
-
定义指针:
cur:从原链表的头节点head开始,逐个指向需要移动的节点;curnext:临时保存cur的下一个节点(避免移动cur后丢失后续节点)。
-
循环条件:
while (cur != tail)—— 当cur移动到tail时,所有节点已处理完毕(tail本身无需移动)。 -
循环内操作(以示例 1:原链表
1->2->3->4->5为例):- 保存
cur的下一个节点:curnext = cur->next(例如第一次循环cur=1,curnext=2,防止移动1后找不到2)。 - 将
cur的next指向tail的下一个节点:cur->next = tail->next(初始时tail->next=NULL,所以1->next=NULL;后续tail->next会指向已插入的节点,确保新链表连续)。 - 将
cur插入到tail的后面:tail->next = cur(例如第一次循环后,tail->next=1,此时链表变为5->1)。 - 移动
cur到下一个待处理节点:cur = curnext(例如第一次循环后cur=2,准备处理2)。
- 保存
4. 返回反转后的头节点
循环结束后,所有节点已按顺序插入到tail后面,tail成为反转后链表的头节点,因此返回tail。
链表中倒数第k个结点
链表中倒数第k个结点__牛客网
输入一个链表,输出该链表中倒数第k个结点。
示例1
输入:1,{1,2,3,4,5}
输出:{5}
代码演示:
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k)
{if (pListHead == NULL)return NULL;struct ListNode* fast = pListHead, * slow = pListHead;while (k--){if (fast == NULL)return NULL;fast = fast->next;}while (fast != NULL){slow = slow->next;fast = fast->next;}return slow;
}代码解析:
1. 边界处理:空链表直接返回 NULL
代码开头判断if (pListHead == NULL),若链表为空(头节点是NULL),则直接返回NULL。因为空链表没有任何节点,自然不存在 “倒数第 k 个节点”,提前处理可避免后续指针操作出错。
2. 初始化快慢指针,让快指针先 “领先” k 步
- 定义两个指针
fast和slow,初始都指向头节点pListHead。 - 通过
while (k--)循环,让fast指针向前移动 k 步:- 循环内先判断
if (fast == NULL):若在移动 k 步的过程中,fast提前变为NULL(说明 k 大于链表的总长度),直接返回NULL(此时不存在倒数第 k 个节点)。 - 否则,
fast = fast->next:fast每次后移一步,总共移动 k 次,最终与slow拉开 k 步距离。
- 循环内先判断
3. 快慢指针同步移动,直到快指针到达末尾
执行while (fast != NULL)循环,让slow和fast同时向后移动:
- 每次循环中,
slow = slow->next,fast = fast->next。 - 由于
fast已经领先slowk 步,当fast移动到链表末尾(变为NULL)时,slow恰好移动到 “倒数第 k 个节点” 的位置(因为slow距离末尾还有 k 步)。
4. 返回结果
循环结束后,slow指针指向的就是链表的倒数第 k 个节点,因此返回slow。
链表分割
链表分割_牛客题霸_牛客网
描述
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
代码演示:
struct ListNode* partition(struct ListNode* pHead, int x)
{if (pHead == NULL)return NULL;struct ListNode* mineHead = (struct ListNode*)malloc(sizeof(struct ListNode));if (mineHead == NULL){perror("partition.malloc");return NULL;}struct ListNode* mineTail = mineHead;struct ListNode* maxHead = (struct ListNode*)malloc(sizeof(struct ListNode));if (maxHead == NULL){perror("partition.malloc");free(mineHead);mineHead = mineHead = NULL;return NULL;}struct ListNode* maxTail = maxHead;struct ListNode* cur = pHead;while (cur != NULL){if (cur->val < x){mineTail->next = cur;mineTail = mineTail->next;}else{maxTail->next = cur;maxTail = maxTail->next;}cur = cur->next;}maxTail->next = NULL;mineTail->next = maxHead->next;pHead = mineHead->next;free(mineHead);free(maxHead);return pHead;
}代码解析:
1. 边界处理:空链表直接返回 NULL
代码开头判断if (pHead == NULL),若链表为空(头节点是NULL),则直接返回NULL。因为空链表没有节点可分区,提前处理可避免后续操作出错。
2. 创建两个 “哨兵节点”,简化链表操作
为了方便处理两个分区链表的头节点(避免头节点为空的特殊逻辑),代码创建了两个哨兵节点(不存储实际数据,仅用于辅助操作):
mineHead和mineTail:分别作为 “存储小于 x 的节点” 的链表的头指针和尾指针(mineTail始终指向该链表的最后一个节点,方便插入新节点)。maxHead和maxTail:分别作为 “存储大于等于 x 的节点” 的链表的头指针和尾指针(作用同上)。
哨兵节点的内存通过malloc分配,若分配失败则释放已分配的内存并返回NULL,避免内存泄漏。
3. 遍历原链表,按值分区到两个临时链表
用cur指针从原链表的头节点pHead开始遍历,逐个判断节点值与 x 的关系,将节点分到对应的临时链表中:
- 若
cur->val < x:将该节点插入 “小于 x 的链表” 末尾 ——mineTail->next = cur(连接节点),然后mineTail = mineTail->next(更新尾指针到新插入的节点)。 - 若
cur->val >= x:将该节点插入 “大于等于 x 的链表” 末尾 ——maxTail->next = cur(连接节点),然后maxTail = maxTail->next(更新尾指针)。
关键:由于遍历原链表时按顺序处理每个节点,且插入临时链表时始终加在末尾,因此两个临时链表的节点顺序与原链表中对应节点的顺序一致,保证了 “不改变原来的数据顺序” 的要求。
4. 拼接两个临时链表,处理收尾
遍历结束后,两个临时链表已分别存储了对应节点,需将它们拼接成一个完整链表:
- 防止环的形成:
maxTail->next = NULL—— 将 “大于等于 x 的链表” 的尾节点 next 设为 NULL(原链表的最后一个节点可能指向其他节点,不处理会导致链表成环)。 - 拼接链表:
mineTail->next = maxHead->next—— 将 “小于 x 的链表” 的尾节点与 “大于等于 x 的链表的实际头节点”(即maxHead->next,跳过哨兵节点)连接,形成完整分区后的链表。
5. 释放哨兵节点,返回结果
- 哨兵节点的使命已完成,通过
free(mineHead)和free(maxHead)释放其内存,避免内存泄漏。 - 分区后链表的实际头节点是 “小于 x 的链表的实际头节点”(即
mineHead->next),因此更新pHead为该节点并返回。
链表的回文结构
链表的回文结构_牛客题霸_牛客网
描述
对于一个链表,请设计一个时间复杂度为O(n),额外空间复杂度为O(1)的算法,判断其是否为回文结构。
给定一个链表的头指针A,请返回一个bool值,代表其是否为回文结构。保证链表长度小于等于900。
测试样例:1->2->2->1
返回:true
代码演示:
ListNode* middleNode(ListNode* pHead)
{if (pHead == NULL)return NULL;ListNode* slow = pHead, * fast = pHead;while (fast != NULL && fast->next != NULL){slow = slow->next;fast = fast->next->next;}return slow;
}
ListNode* reverseList(ListNode* pHead)
{if (pHead == NULL)return NULL;ListNode* tail = pHead;while (tail->next != NULL)tail = tail->next;ListNode* cur = pHead;while (cur != tail){ListNode* curNext = cur->next;cur->next = tail->next;tail->next = cur;cur = curNext;}return tail;
}
bool chkPalindrome(ListNode* pHead)
{ListNode* mid = middleNode(pHead); //找到中间节点ListNode* rmid = reverseList(mid); //从中间节点开始逆置(头插)while (rmid != NULL){if (rmid->val != pHead->val)return false;rmid = rmid->next;pHead = pHead->next;}return true;
}
代码解析:
1. 核心辅助函数 1:middleNode—— 找到链表的中间节点
该函数用快慢指针法定位链表的中间节点,为后续拆分前后半部分做准备:
- 定义
slow(慢指针)和fast(快指针),初始都指向头节点pHead; - 循环条件
fast != NULL && fast->next != NULL:快指针每次走 2 步,慢指针每次走 1 步; - 当快指针到达链表末尾(
fast或fast->next为NULL)时,慢指针slow恰好指向中间节点(若链表长度为奇数,指向正中间;若为偶数,指向后半部分的第一个节点)。
例如:链表1->2->2->1,slow最终指向第二个2(后半部分的起点)。
2. 核心辅助函数 2:reverseList—— 反转链表(从指定节点开始)
该函数通过 **“找尾节点 + 头插法”** 反转链表的后半部分(从中间节点mid开始),目的是将后半部分 “倒过来”,方便与前半部分对比:
- 先找到待反转部分的尾节点
tail(从pHead开始遍历,直到tail->next == NULL); - 用
cur指针从待反转部分的头节点(即pHead,此处实际是中间节点mid)开始遍历,通过头插法将每个节点依次插入tail后面,实现反转。
例如:后半部分2->1,反转后变为1->2。
3. 主函数chkPalindrome—— 判断是否为回文结构
这是判断逻辑的核心,通过对比前半部分和反转后的后半部分,验证是否对称:
步骤 1:拆分链表为前后两部分
调用middleNode(pHead)得到中间节点mid,以此为界,链表被分为前半部分(从pHead到mid的前一个节点)和后半部分(从mid到末尾)。
步骤 2:反转后半部分链表
调用reverseList(mid)得到反转后的后半部分头节点rmid(原后半部分的尾节点)。
步骤 3:逐一对比前后两部分节点值
同时遍历前半部分(从pHead开始)和反转后的后半部分(从rmid开始),循环条件为rmid != NULL(后半部分遍历完即停止):
- 若任意对应节点的值不相等,直接返回
false(不是回文); - 若所有对应节点值都相等,循环结束后返回
true(是回文)。
相交链表
160. 相交链表 - 力扣(LeetCode)
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
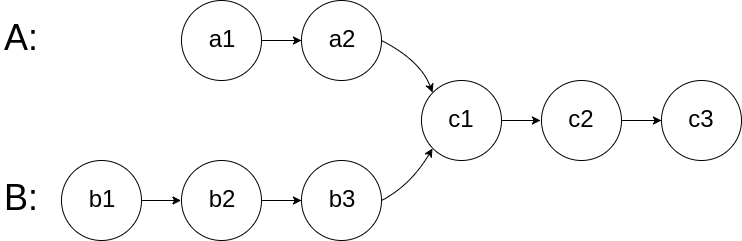
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
代码演示:
int my_abs(int a, int b)
{return (((a) > (b)) ? ((a)-(b)) : ((b)-(a)));
}
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB)
{if (headA == NULL)return NULL;if (headB == NULL)return NULL;int lenA = 1;struct ListNode* curA = headA;while (curA->next != NULL){lenA++;curA = curA->next;}int lenB = 1;struct ListNode* curB = headB;while (curB->next != NULL){lenB++;curB = curB->next;}if (curA != curB)return NULL;int gap = my_abs(lenA, lenB);struct ListNode* longList = headA;struct ListNode* shortList = headB;if (lenA < lenB){longList = headB;shortList = headA;}while (gap--)longList = longList->next;while (longList != shortList){longList = longList->next;shortList = shortList->next;}return longList;
}代码解析:
1. 边界处理:空链表直接返回 NULL
代码开头判断if (headA == NULL)和if (headB == NULL),若任意一个链表为空,则不可能存在相交节点,直接返回NULL。提前处理空链表,避免后续无效操作。
2. 第一步:计算两个链表的长度,并定位到各自的尾节点
这一步有两个核心目的:一是获取链表长度,为后续 “对齐长度” 做准备;二是通过尾节点是否相同,判断链表是否可能相交(相交链表的尾节点必然是同一个)。
-
计算链表 A 的长度(
lenA):定义curA指针从headA开始遍历,lenA初始值为 1(因为headA本身是第一个节点)。每次curA后移(curA = curA->next),lenA加 1,直到curA->next == NULL(curA停在 A 的尾节点)。 -
计算链表 B 的长度(
lenB):逻辑与 A 完全一致,curB从headB开始遍历,lenB初始为 1,最终curB停在 B 的尾节点。 -
判断是否相交的前提:尾节点是否相同若
curA != curB(A 和 B 的尾节点不是同一个),说明两个链表完全独立,不可能相交,直接返回NULL。这是关键判断,能提前排除无效场景,减少后续操作。
3. 第二步:处理长度差距,让长链表先走 “差距步”
由于相交链表的 “公共部分长度相同”,若两个链表长度不同,长链表的 “非公共前缀长度” 就是两者的长度差(gap)。让长链表先走gap步,可使后续两个链表的 “剩余长度完全相同”,方便同步遍历找交点。
-
计算长度差
gap:调用自定义函数my_abs(lenA, lenB),该函数返回两个长度的绝对值(即gap = |lenA - lenB|)。 -
确定长链表和短链表:初始化
longList(指向长链表头)和shortList(指向短链表头),默认longList=headA、shortList=headB。若lenA < lenB,则交换两者(longList=headB,shortList=headA),确保longList始终指向更长的链表。 -
长链表先走
gap步:通过while (gap--)循环,让longList向后移动gap次。例如:A 长 5、B 长 3,gap=2,longList(A)先走 2 步,此时longList到 A 的第 3 个节点,A 剩余长度 3,与 B 的长度相同。
4. 第三步:同步遍历,找到相交节点
此时longList和shortList的 “剩余长度相同”,若链表相交,两者会同时遍历到相交节点;若不相交(前面已通过尾节点排除,此处不会发生),会同时遍历到NULL。
-
同步遍历循环:执行
while (longList != shortList),每次循环让longList和shortList同时后移(longList = longList->next,shortList = shortList->next)。 -
返回相交节点:当
longList == shortList时,循环结束,该节点即为两个链表的相交起始节点,返回longList(或shortList,两者相同)。
环形链表
141. 环形链表 - 力扣(LeetCode)
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
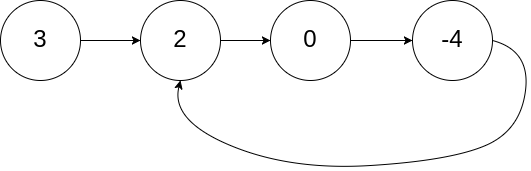
输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
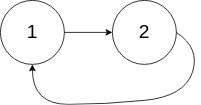
输入:head = [1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1 输出:false 解释:链表中没有环。
代码演示:
bool hasCycle(struct ListNode* head)
{if (head == NULL)return false;struct ListNode* fast = head->next, * slow = head;while (fast != NULL && fast->next != NULL){if (fast == slow)return true;slow = slow->next;fast = fast->next->next;}return false;
}代码解析:
1. 边界处理:空链表直接返回无环
代码开头判断if (head == NULL),若链表为空(头节点是NULL),则不可能存在环(没有节点可形成环),直接返回false,避免后续指针操作出错。
2. 初始化快慢指针:设置不同起点与速度
定义两个指针,初始位置和移动速度不同,为 “追上” 逻辑铺垫:
- 慢指针(
slow):初始指向head(链表头节点),每次循环向后移动1 步(速度慢,类似 “龟”); - 快指针(
fast):初始指向head->next(头节点的下一个节点),每次循环向后移动2 步(速度快,类似 “兔”)。
这样初始化是为了避免 “初始状态下快慢指针就相等”(若都从head开始,循环第一步会直接判断fast==slow,误判有环),确保初始状态两者不重叠。
3. 核心循环:遍历链表,判断是否相遇
循环条件为fast != NULL && fast->next != NULL,这是因为快指针每次走 2 步,需要确保它移动时不会访问空指针(比如fast已到最后一个节点,fast->next是NULL,再执行fast->next->next会崩溃)。循环内逻辑分两步:
第一步:判断是否追上(有环的标志)
若fast == slow,说明快指针在遍历过程中追上了慢指针 —— 只有链表存在环时,快指针才会绕环后追上慢指针(无环时快指针会一直领先到末尾),此时直接返回true(确认有环)。
第二步:移动指针,继续遍历
若未追上,则按各自速度移动指针:
slow = slow->next:慢指针走 1 步;fast = fast->next->next:快指针走 2 步。
4. 循环结束:快指针到末尾,返回无环
当循环退出时,说明fast已到达链表末尾(fast == NULL或fast->next == NULL)—— 若链表有环,快指针会一直绕环,永远不会到末尾,因此此时可确定链表无环,返回false。
关键逻辑:为什么有环时快指针一定能追上慢指针?
假设链表环的长度为L,当慢指针刚进入环时,快指针与慢指针的距离为d(d < L)。由于快指针每次比慢指针多走 1 步(速度差 1),每循环一次,两者距离会减少 1,最终必然会相遇(不会错过)—— 就像绕操场跑步,快的人总会追上慢的人。
环形链表2
142. 环形链表 II - 力扣(LeetCode)
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
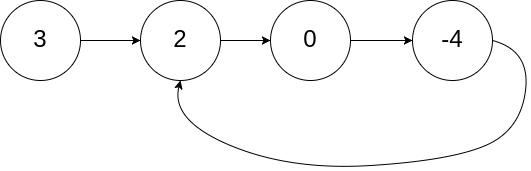
输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。
代码演示:
struct ListNode* detectCycle(struct ListNode* head)
{if (head == NULL)return NULL;struct ListNode* fast = head, * slow = head;while (fast != NULL && fast->next != NULL){slow = slow->next;fast = fast->next->next;if (fast == slow){struct ListNode* meet = slow;while (head != meet){head = head->next;meet = meet->next;}head->next = NULL;return head;}}return NULL;
}代码解析:
1. 第一步:用快慢指针判断是否有环,并找到相遇点
代码首先通过快慢指针遍历链表,判断是否存在环,若有环则记录相遇点:
- 初始化指针:
fast(快指针)和slow(慢指针)都从head(头节点)开始,fast每次移动 2 步,slow每次移动 1 步(速度差为 1)。 - 循环遍历:通过
while (fast != NULL && fast->next != NULL)循环,确保fast移动时不会访问空指针。循环中,slow和fast分别按速度移动。 - 检测到环并记录相遇点:若
fast == slow,说明两指针在环内相遇(只有环存在时,快指针才会追上慢指针),此时用meet指针记录相遇点(meet = slow)。
2. 第二步:从起点和相遇点同步遍历,找到环的入口
当确认有环后,代码通过 “双指针同步移动” 找到环的入口:
- 同步移动指针:让
head(从头节点开始)和meet(从相遇点开始)同时每次移动 1 步,进入while (head != meet)循环。 - 相遇即入口:当
head == meet时,循环结束,此时两指针指向的节点就是环的第一个入口节点,返回该节点。 - 无环情况:若循环中
fast或fast->next先变为NULL,说明链表无环,返回NULL。
关键问题:为什么从起点和相遇点同步走,一定会在入口相遇?
这一结论可通过数学推导证明,假设链表结构如下:
- 从头节点到环入口的距离为
L; - 从环入口到相遇点的距离为
X; - 环的长度为
C(即相遇点绕环一圈回到入口的距离为C - X)。
推导过程:
-
当快慢指针相遇时:
- 慢指针
slow走的总距离:L + X(从头节点到入口,再到相遇点); - 快指针
fast速度是慢指针的 2 倍,且已绕环n圈(n ≥ 1,因为必须追上),总距离:L + X + n*C(从头节点到入口,到相遇点,再绕环n圈)。
- 慢指针
-
由于快指针距离是慢指针的 2 倍,因此:
2*(L + X) = L + X + n*C化简得:L + X = n*C→L = n*C - X。
结论:
L = n*C - X的含义是:从头节点到入口的距离L,等于(n-1圈环的长度)加上(相遇点到入口的距离C - X)。
- 当
head从起点移动L步时,会到达入口; - 当
meet从相遇点移动L步时,相当于移动了(n-1)*C + (C - X)步(绕环n-1圈后,再从相遇点移动C - X步),最终也会到达入口。
因此,head和meet同步移动时,必然在环的入口节点相遇。
随机链表的复制
138. 随机链表的复制 - 力扣(LeetCode)
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
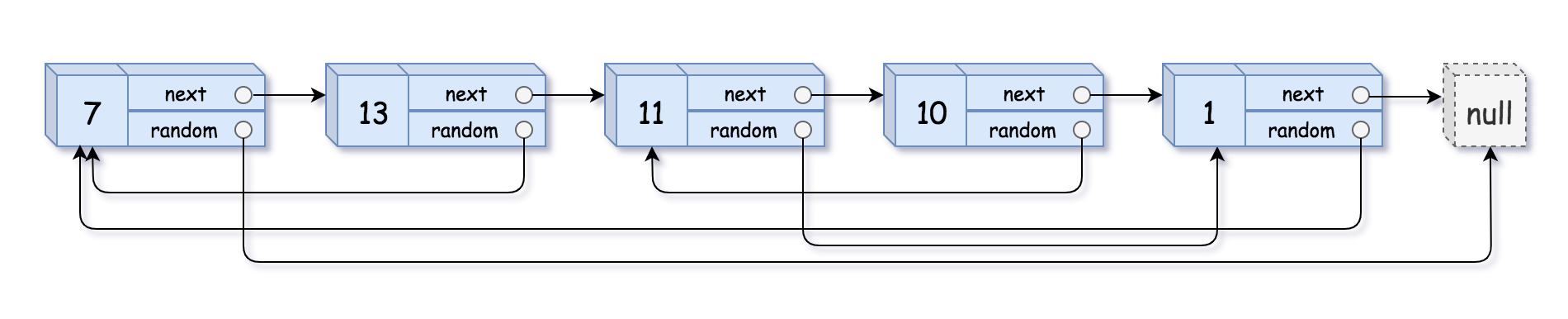
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
代码演示:
struct Node* BuyRandomNode(int val)
{struct Node* newnode = (struct Node*)malloc(sizeof(struct Node));if (newnode == NULL){perror("BuyRandomNode.malloc");return NULL;}newnode->val = val;newnode->next = NULL;newnode->random = NULL;return newnode;
}
struct Node* copyRandomList(struct Node* head)
{if (head == NULL)return NULL;// 在原链表的各个节点后链接对应的复制节点struct Node* cur = head;while (cur != NULL){struct Node* copynode = BuyRandomNode(cur->val);struct Node* next = cur->next;cur->next = copynode;copynode->next = next;cur = next;}// 处理复制节点的randomcur = head;while (cur != NULL && cur->next != NULL){if (cur->random == NULL)cur->next->random = NULL;elsecur->next->random = cur->random->next;cur = cur->next->next;}// 链接各个复制节点为新链表,并且恢复原链表struct Node* retList = head->next;struct Node* retcur = retList;cur = head;while (retcur != NULL && retcur->next != NULL){struct Node* next = cur->next->next;struct Node* retnext = retcur->next->next;retcur->next = retnext;retcur = retnext;cur->next = next;cur = next;}cur->next = NULL;return retList;
}代码解析:
1. 辅助函数BuyRandomNode:创建新的随机节点
该函数的作用是生成一个全新的Node节点,为后续复制节点提供基础,逻辑简单直接:
- 用
malloc分配节点内存,若分配失败(newnode == NULL),通过perror提示错误并返回NULL; - 初始化节点属性:
val设为传入的目标值,next和random均初始化为NULL(后续再按需调整指向); - 返回创建好的新节点。
2. 主函数copyRandomList:三步实现深拷贝
整个深拷贝逻辑分为三个核心步骤,每一步都围绕 “不依赖额外映射、利用原链表结构” 展开:
第一步:在原链表每个节点后,插入对应的复制节点
目的是让 “原节点” 与 “复制节点” 相邻(如原链表A→B→C变为A→A'→B→B'→C→C'),为后续快速定位复制节点的random做铺垫,具体操作:
- 用
cur指针从原链表头head开始遍历,直到cur == NULL(遍历完所有原节点); - 对每个原节点
cur:- 调用
BuyRandomNode(cur->val)创建复制节点copynode(如A的复制节点A'); - 保存原节点
cur的下一个节点next(如A的next是B,避免插入A'后丢失B); - 调整指针:让
cur->next = copynode(A指向A'),copynode->next = next(A'指向B),完成A'插入A和B之间; cur = next(cur移到下一个原节点B,重复上述操作)。
- 调用
第二步:处理复制节点的random指针
这是深拷贝的关键(随机指针难以直接定位),利用第一步 “原节点与复制节点相邻” 的特性,快速找到复制节点的random指向,具体操作:
cur重新从head开始遍历,每次跳两步(只处理原节点,跳过复制节点);- 对每个原节点
cur,其复制节点是cur->next(如A的复制节点是A'):- 若原节点
cur的random == NULL(无随机指向),则复制节点cur->next的random也设为NULL; - 若原节点
cur的random指向某原节点X(如A.random = X),则复制节点cur->next的random需指向X的复制节点 —— 而根据第一步的插入规则,X的复制节点就是X->next(X后面跟着X'),因此直接让cur->next->random = cur->random->next即可。
- 若原节点
cur = cur->next->next(cur跳两步,移到下一个原节点,继续处理)。
第三步:拆分链表(复制节点成新链表,恢复原链表)
此时链表是 “原节点 - 复制节点” 交替的结构(A→A'→B→B'→C→C'),需要拆分出独立的复制链表(A'→B'→C'),同时恢复原链表(A→B→C),具体操作:
- 初始化指针:
retList是复制链表的头节点(即原链表头的复制节点head->next,如A'),retcur用于遍历复制链表,cur用于遍历原链表; - 遍历并拆分(直到复制链表的当前节点
retcur无下一个复制节点):- 保存关键节点:
next是下一个原节点(cur->next->next,如A'的next是B,所以next = B),retnext是下一个复制节点(retcur->next->next,如B的next是B',所以retnext = B'); - 链接复制链表:让
retcur->next = retnext(A'指向B'),retcur = retnext(retcur移到B'); - 恢复原链表:让
cur->next = next(A指向B),cur = next(cur移到B);
- 保存关键节点:
- 最后处理原链表尾节点:拆分到最后,原链表的最后一个节点
cur的next可能还指向复制节点,需手动设为NULL(cur->next = NULL),避免原链表残留无效指针; - 返回复制链表的头节点
retList。
核心优势
- 空间复杂度 O (1):无需用哈希表存储 “原节点→复制节点” 的映射,仅靠节点插入的相邻关系定位,额外空间仅为几个指针;
- 时间复杂度 O (n):三步遍历均为线性遍历(总遍历次数 3n),效率高;
- 不破坏原链表:最后一步会恢复原链表的结构,符合 “深拷贝不修改原数据” 的要求;
- random 指针处理精准:利用 “原节点 random 的复制节点 = 原 random 的 next”,直接定位,避免复杂查找。
删除链表中重复的结点
删除链表中重复的结点_牛客题霸_牛客网
描述
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表 1->2->3->3->4->4->5 处理后为 1->2->5
数据范围:链表长度满足 0≤n≤1000 0≤n≤1000 ,链表中的值满足 1≤val≤1000 1≤val≤1000
进阶:空间复杂度 O(n) O(n) ,时间复杂度 O(n) O(n)
例如输入{1,2,3,3,4,4,5}时,对应的输出为{1,2,5},对应的输入输出链表如下图所示:
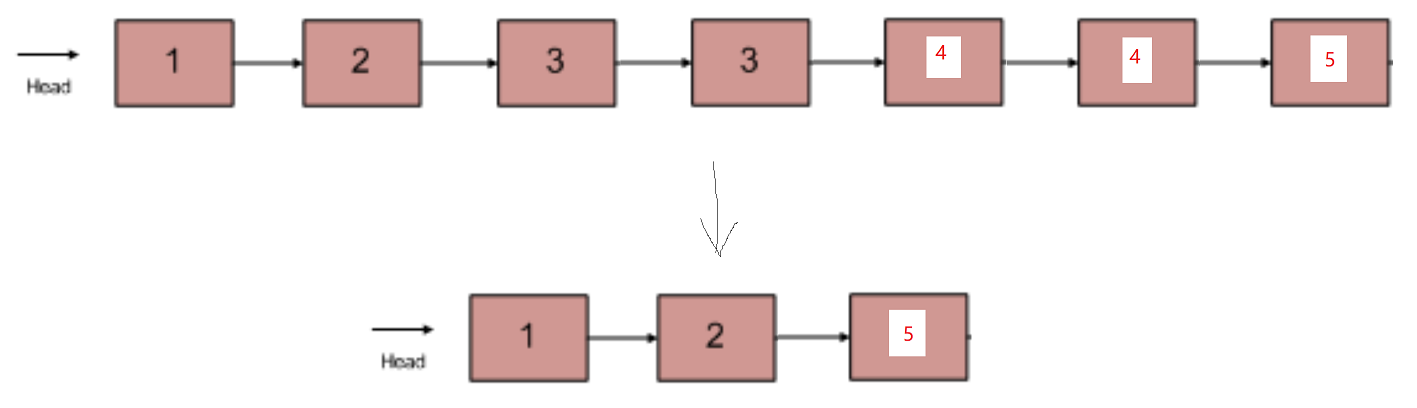
示例1
输入:{1,2,3,3,4,4,5}
返回值:{1,2,5}
示例2
输入:{1,1,1,8}
返回值:{8}
代码演示:
struct ListNode* deleteDuplication(struct ListNode* pHead)
{if (pHead == NULL)return NULL;struct ListNode* deleteHead = NULL;struct ListNode* deleteTail = NULL;struct ListNode* cur = pHead;while (cur != NULL){if ((cur->next != NULL) && (cur->val == cur->next->val)){int some = cur->val;while ((cur != NULL) && (cur->val == some))cur = cur->next;}else{if (deleteHead == NULL){deleteHead = deleteTail = cur;}else{deleteTail->next = cur;deleteTail = deleteTail->next;}cur = cur->next;}}if(deleteTail != NULL)deleteTail->next = NULL;return deleteHead;
}代码解析:
1. 边界处理:空链表直接返回 NULL
代码开头判断if (pHead == NULL),若原链表为空(头节点pHead是NULL),则没有节点可处理,直接返回NULL。这一步是为了避免后续指针操作访问空地址,提前拦截无效场景。
2. 定义新链表指针:追踪不重复节点的拼接
定义两个指针deleteHead和deleteTail,用于构建存储 “不重复节点” 的新链表:
deleteHead:新链表的头节点(最终需要返回的结果),初始为NULL(新链表未构建时为空);deleteTail:新链表的尾节点,始终指向新链表的最后一个节点(方便将新的不重复节点拼接到末尾,避免遍历新链表找尾),初始也为NULL。
3. 核心遍历逻辑:筛选不重复节点,跳过重复节点
用cur指针从原链表头pHead开始遍历,循环条件为while (cur != NULL)(遍历完所有原节点为止)。循环内分两种情况处理:当前节点重复和当前节点不重复。
情况 1:当前节点是重复节点 → 跳过所有相同节点
判断条件:(cur->next != NULL) && (cur->val == cur->next->val)
- 含义:若当前节点
cur的下一个节点存在,且两者值相等,说明cur是重复节点的开始,需要跳过所有值相同的节点。 - 处理步骤:
- 用
some记录当前重复节点的值(如原链表3->3,some=3),避免后续判断时重复获取; - 用
while ((cur != NULL) && (cur->val == some))循环,让cur持续后移,直到cur指向 “非some值的节点” 或NULL(如cur从第一个3移到4,跳过两个3)。
- 用
情况 2:当前节点是不重复节点 → 拼接到新链表
若不满足 “重复节点” 的判断条件,说明cur是不重复节点(要么cur->next为NULL,要么cur与cur->next值不同),需将其加入新链表:
- 若新链表为空(
deleteHead == NULL):这是第一个不重复节点,直接让deleteHead和deleteTail都指向cur(新链表的头和尾都是这个节点); - 若新链表已存在节点:用
deleteTail->next = cur将cur拼接到新链表末尾,再让deleteTail = deleteTail->next(尾指针后移,始终指向新链表最后一个节点); - 最后
cur = cur->next:cur后移,继续遍历原链表的下一个节点。
4. 收尾处理:避免新链表尾部残留原链表节点
循环结束后,需处理新链表的尾节点:
- 原因:
deleteTail指向的是原链表中的不重复节点,该节点的next可能还指向原链表的其他节点(甚至是已跳过的重复节点)。若不设为NULL,新链表末尾会残留原链表的无效节点,可能导致链表成环或结果错误。 - 逻辑:若新链表非空(
deleteTail != NULL),则将其next设为NULL,确保新链表是独立、完整的。
5. 返回结果:新链表的头节点
最后返回deleteHead,即存储所有不重复节点的新链表的头节点。
核心优势
- 利用排序特性:排序链表的重复节点必相邻,无需额外存储节点值判断重复,遍历一次即可处理;
- 时间复杂度 O (n):仅遍历原链表一次(
cur从pHead到NULL),无嵌套遍历; - 空间复杂度 O (1):仅用 4 个指针(
deleteHead、deleteTail、cur、some),未额外分配节点(新链表复用原链表的不重复节点,仅调整指针)。
通过 “跳过重复、拼接不重复” 的逻辑,代码高效完成了排序链表中重复节点的删除。
对链表进行插入排序
147. 对链表进行插入排序 - 力扣(LeetCode)
给定单个链表的头 head ,使用 插入排序 对链表进行排序,并返回 排序后链表的头 。
插入排序 算法的步骤:
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
- 重复直到所有输入数据插入完为止。
下面是插入排序算法的一个图形示例。部分排序的列表(黑色)最初只包含列表中的第一个元素。每次迭代时,从输入数据中删除一个元素(红色),并就地插入已排序的列表中。
对链表进行插入排序。
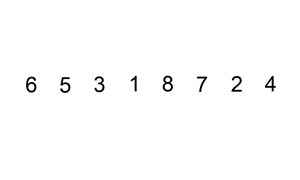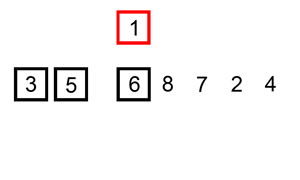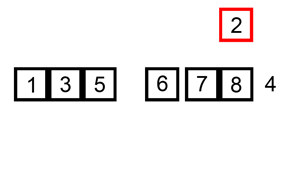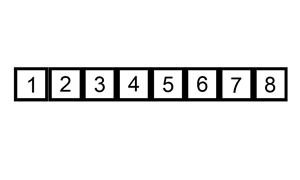
示例 1:
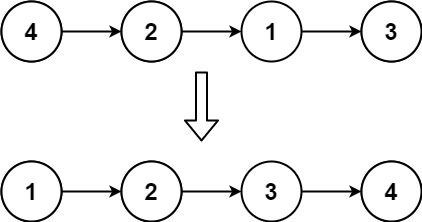
输入: head = [4,2,1,3] 输出: [1,2,3,4]
示例 2:
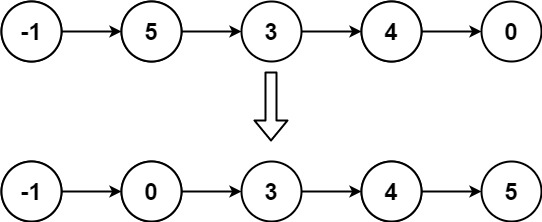
输入: head = [-1,5,3,4,0] 输出: [-1,0,3,4,5]
代码演示:
struct ListNode* FindPushPrevNode(struct ListNode* sortHead, int val)
{struct ListNode* cur = sortHead;while ((cur->next != NULL) && (cur->next->val < val))cur = cur->next;return cur;
}
struct ListNode* insertionSortList(struct ListNode* head)
{if (head == NULL)return NULL;struct ListNode* sortHead = (struct ListNode*)malloc(sizeof(struct ListNode));if (sortHead == NULL){perror("insertionSortList.malloc");return NULL;}struct ListNode* sortTail = head;sortHead->next = sortTail;struct ListNode* cur = head->next;struct ListNode* curPrev = head;while (cur != NULL){if (cur->val < sortTail->val){struct ListNode* curNext = cur->next;struct ListNode* PushPrevNode = FindPushPrevNode(sortHead, cur->val);struct ListNode* PushNextNode = PushPrevNode->next;PushPrevNode->next = cur;cur->next = PushNextNode;sortTail->next = curNext;cur = curNext;curPrev = sortTail;}else{curPrev = curPrev->next;sortTail = sortTail->next;cur = cur->next;}}sortTail->next = NULL;struct ListNode* result = sortHead->next;free(sortHead); sortHead = NULL; return result;
}代码解析:
1. 辅助函数FindPushPrevNode:找到待插入节点的前驱位置
该函数的核心作用是:在已排序的子链表中,找到 “待插入节点应该插入位置的前驱节点”,确保插入后子链表仍保持有序。
- 参数说明:
sortHead是已排序子链表的哨兵节点(不存储实际数据,仅用于统一操作),val是待插入节点的值。 - 逻辑细节:
- 用
cur从sortHead开始遍历(哨兵节点的next才是已排序子链表的第一个有效节点); - 循环条件
(cur->next != NULL) && (cur->next->val < val):cur->next != NULL:确保不访问空指针(避免已排序子链表遍历完);cur->next->val < val:只找 “下一个节点值小于待插入值” 的cur,直到遇到 “下一个节点值≥待插入值” 时停止;
- 返回
cur:此时cur就是待插入节点的前驱 —— 将待插入节点放在cur和cur->next之间,能保证已排序子链表有序。
- 用
例如:已排序子链表是[2,4](哨兵节点sortHead的next=2),待插入值是3,函数会找到cur=2(因为2->next=4的val=4≥3),后续将3插入2和4之间。
2. 主函数insertionSortList:核心排序逻辑(分 5 步)
主函数通过 “初始化→遍历→插入→收尾” 的流程完成排序,同时修复了内存泄漏和冗余遍历问题:
第一步:边界处理 —— 空链表直接返回
代码开头判断if (head == NULL),若链表为空(无任何节点),直接返回NULL,避免后续指针操作出错。
第二步:创建哨兵节点sortHead—— 简化头节点插入
- 哨兵节点作用:插入排序中,若待插入节点需放在已排序子链表的头部(如已排序部分是
[2,4],待插入1),无哨兵节点时需单独处理 “头节点更新”;有哨兵节点后,可统一按 “插入到前驱和前驱.next 之间” 操作,无需特殊判断。 - 操作细节:
- 用
malloc分配哨兵节点内存,若分配失败(sortHead == NULL),通过perror提示错误并返回NULL; - 初始化已排序子链表:插入排序的初始 “已排序部分” 只有原链表的第一个节点(
head),因此sortTail(已排序子链表的尾节点)初始指向head,sortHead->next = sortTail(哨兵节点的next链接到已排序部分的第一个节点)。
- 用
第三步:初始化待排序节点指针
定义两个指针追踪待排序节点及其前驱,避免冗余遍历:
cur:待排序节点的起始位置,从原链表的第二个节点(head->next)开始(第一个节点已在已排序部分);curPrev:cur的前驱节点,初始指向head(因为初始时cur=head->next,前驱就是head),后续随cur同步更新,避免之前 “从头找前驱” 的冗余操作。
第四步:核心循环 —— 遍历待排序节点,分情况处理
循环条件while (cur != NULL)(遍历完所有待排序节点为止),根据cur的值与已排序部分尾节点sortTail的值,分两种情况处理:
情况 1:cur->val < sortTail->val—— 需插入到已排序部分的中间
此时cur不能直接接在已排序部分末尾,需找到合适位置插入,步骤如下:
- 保存关键节点:
curNext = cur->next:保存cur的下一个待排序节点(避免插入cur后丢失后续节点);PushPrevNode = FindPushPrevNode(sortHead, cur->val):调用辅助函数,找到cur的插入前驱;PushNextNode = PushPrevNode->next:保存PushPrevNode的下一个节点(即cur要插入的位置)。
- 调整指针完成插入:
PushPrevNode->next = cur:让前驱指向cur;cur->next = PushNextNode:让cur指向原前驱的下一个节点,完成插入;sortTail->next = curNext:已排序部分的尾节点sortTail,需链接到cur的原下一个节点curNext(因为cur已被移走);
- 更新指针,准备下一轮:
cur = curNext:cur移到下一个待排序节点;curPrev = sortTail:curNext的前驱就是sortTail(已排序部分的尾节点),同步更新curPrev,避免冗余查找。
情况 2:cur->val >= sortTail->val—— 直接接在已排序部分末尾
此时cur是当前待排序节点中最大的,直接接在sortTail后面即可保持有序,步骤简单:
curPrev = curPrev->next:curPrev随cur同步后移;sortTail = sortTail->next:已排序部分的尾节点后移,包含cur;cur = cur->next:cur移到下一个待排序节点。
第五步:收尾处理 —— 避免链表成环 + 释放哨兵节点
sortTail->next = NULL:已排序子链表的尾节点sortTail,其next可能还指向原链表的无效节点,设为NULL可避免链表成环;- 释放哨兵节点,返回结果:
struct ListNode* result = sortHead->next:保存排序后链表的实际头节点(哨兵节点的next);free(sortHead):释放哨兵节点内存,避免内存泄漏;sortHead = NULL:避免野指针;- 返回
result:即排序后的链表头节点。