LangChain4j学习8:RAG (检索增强生成)
LLM 的知识仅限于它已经训练过的数据。 如果你想让 LLM 了解特定领域的知识或专有数据,你可以:
使用 RAG,我们将在本节中介绍
用你的数据微调 LLM
结合 RAG 和微调
什么是 RAG?
简单来说,RAG 是一种在发送给 LLM 之前,从你的数据中找到并注入相关信息片段到提示中的方法。 这样 LLM 将获得(希望是)相关信息,并能够使用这些信息回复, 这应该会降低产生幻觉的概率。
相关信息片段可以使用各种信息检索方法找到。 最流行的方法有:
全文(关键词)搜索。这种方法使用 TF-IDF 和 BM25 等技术, 通过匹配查询(例如,用户提问的内容)中的关键词与文档数据库进行搜索。 它根据每个文档中这些关键词的频率和相关性对结果进行排名。
向量搜索,也称为"语义搜索"。 文本文档使用嵌入模型转换为数字向量。 然后根据查询向量和文档向量之间的余弦相似度 或其他相似度/距离度量找到并排序文档, 从而捕捉更深层次的语义含义。
混合搜索。结合多种搜索方法(例如,全文 + 向量)通常可以提高搜索的有效性。
目前,本页主要关注向量搜索。 全文和混合搜索目前仅由 Azure AI Search 集成支持, 详情请参阅 AzureAiSearchContentRetriever。 我们计划在不久的将来扩展 RAG 工具箱,包括全文和混合搜索。
RAG 阶段
RAG 过程分为两个不同的阶段:索引和检索。 LangChain4j 为这两个阶段提供了工具。
索引
在索引阶段,文档会被预处理,以便在检索阶段进行高效搜索。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及清理文档、用额外数据和元数据丰富文档、 将文档分割成更小的片段(也称为分块)、嵌入这些片段,最后将它们存储在嵌入存储(也称为向量数据库)中。
索引阶段通常是离线进行的,这意味着最终用户不需要等待其完成。 例如,可以通过定时任务在周末每周重新索引一次公司内部文档来实现。 负责索引的代码也可以是一个单独的应用程序,只处理索引任务。
然而,在某些情况下,最终用户可能希望上传自己的自定义文档,使 LLM 能够访问这些文档。 在这种情况下,索引应该在线进行,并成为主应用程序的一部分。
以下是索引阶段的简化图表:
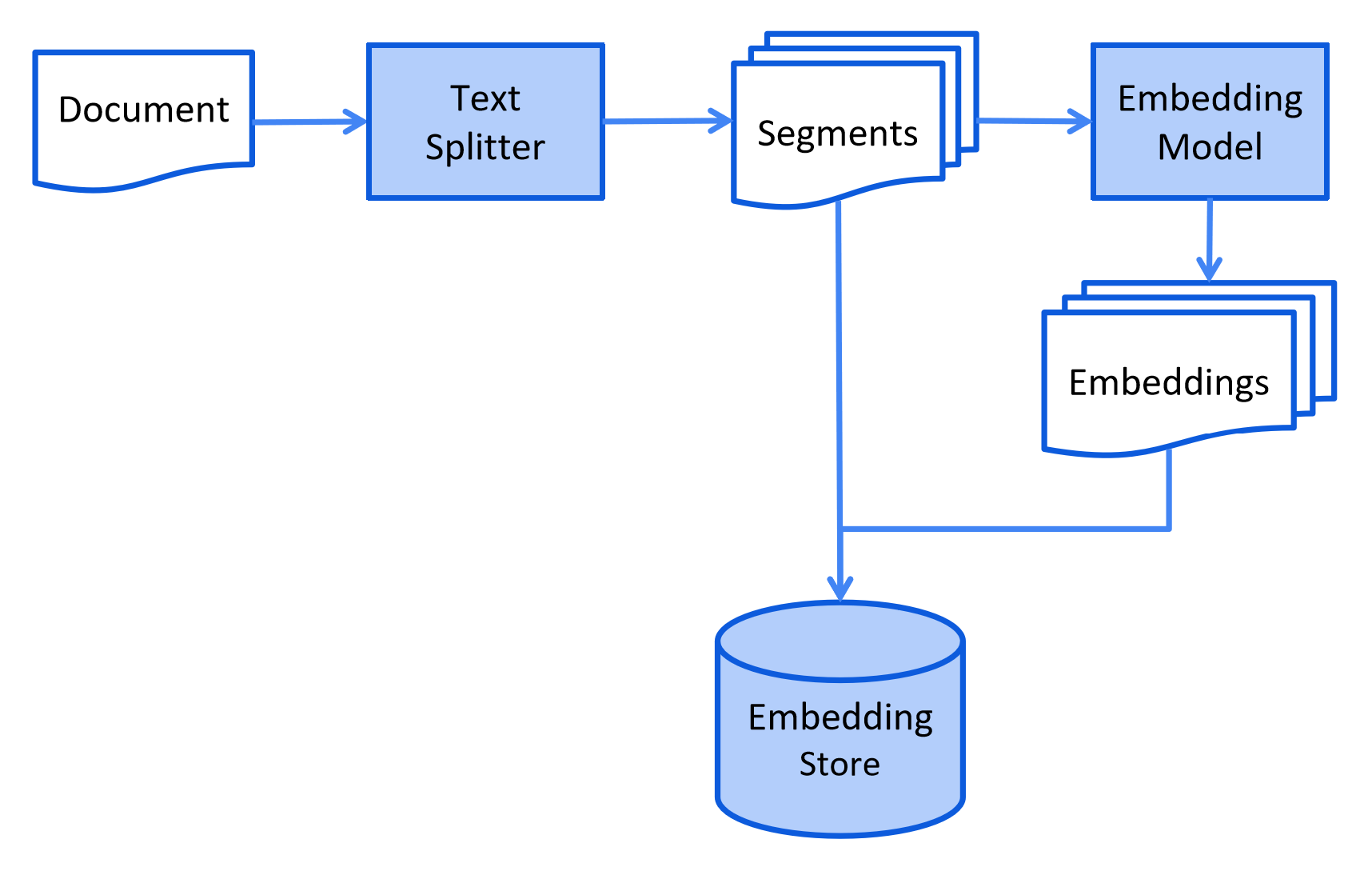
检索
检索阶段通常在线进行,当用户提交一个应该使用索引文档回答的问题时。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及嵌入用户的查询(问题) 并在嵌入存储中执行相似度搜索。 然后将相关片段(原始文档的片段)注入到提示中并发送给 LLM。
以下是检索阶段的简化图表:
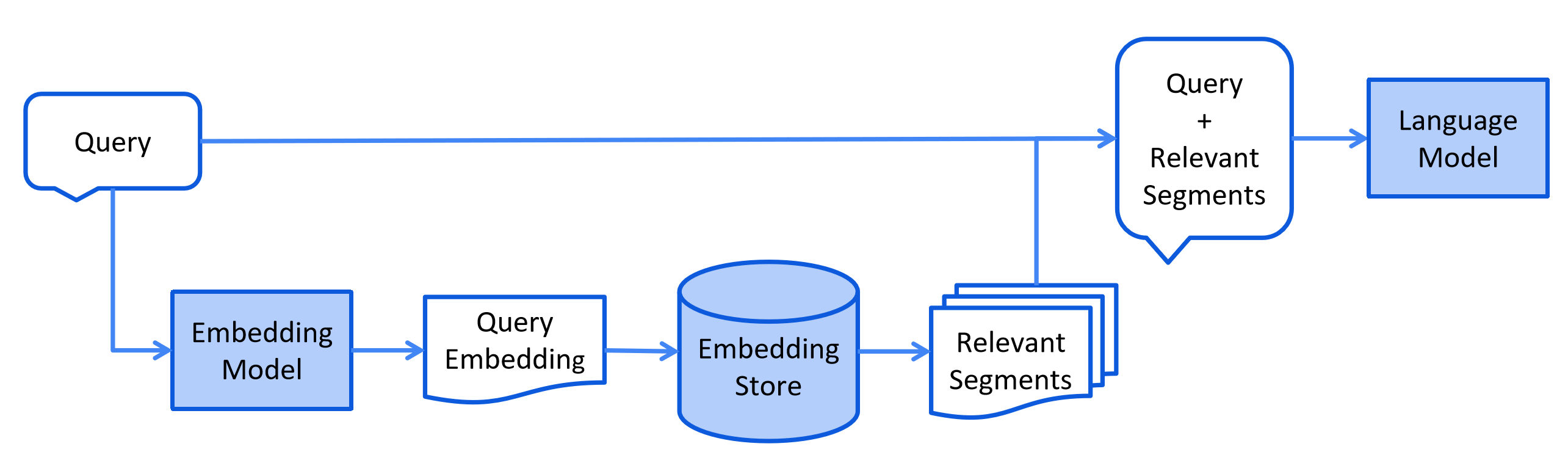
LangChain4j 有一个 DocumentSplitter 接口,带有几个开箱即用的实现:
DocumentByParagraphSplitter
DocumentByLineSplitter
DocumentBySentenceSplitter
DocumentByWordSplitter
DocumentByCharacterSplitter
DocumentByRegexSplitter
递归:DocumentSplitters.recursive(...)
它们的工作方式如下:
你实例化一个 DocumentSplitter,指定所需的 TextSegment 大小, 并可选择指定字符或令牌的重叠。
你调用 DocumentSplitter 的 split(Document) 或 splitAll(List<Document>) 方法。
DocumentSplitter 将给定的 Document 分割成更小的单元, 这些单元的性质因分割器而异。例如,DocumentByParagraphSplitter 将 文档分成段落(由两个或更多连续的换行符定义), 而 DocumentBySentenceSplitter 使用 OpenNLP 库的句子检测器将 文档分成句子,等等。
然后,DocumentSplitter 将这些更小的单元(段落、句子、单词等)组合成 TextSegment, 尝试在不超过步骤 1 中设置的限制的情况下,在单个 TextSegment 中包含尽可能多的单元。 如果某些单元仍然太大而无法放入 TextSegment,它会调用子分割器。 这是另一个 DocumentSplitter,能够将不适合的单元分割成更细粒度的单元。 所有 Metadata 条目都从 Document 复制到每个 TextSegment。 每个文本片段都添加了一个唯一的元数据条目"index"。 第一个 TextSegment 将包含 index=0,第二个 index=1,依此类推。
Text Segment Transformer
TextSegmentTransformer 类似于 DocumentTransformer(上面描述的),但它转换 TextSegment。
与 DocumentTransformer 一样,没有一种通用的解决方案, 所以我们建议实现你自己的 TextSegmentTransformer,根据你独特的数据定制。
一种对改善检索效果很好的技术是在每个 TextSegment 中包含 Document 标题或简短摘要。
Embedding
Embedding 类封装了一个数值向量,表示已嵌入内容(通常是文本,如 TextSegment)的"语义含义"。
在这里关于向量嵌入的信息:
https://www.elastic.co/what-is/vector-embedding
https://www.pinecone.io/learn/vector-embeddings/
https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings
有用的方法
Embedding Model
EmbeddingModel 接口表示一种特殊类型的模型,将文本转换为 Embedding。
当前支持的嵌入模型可以在这里找到。
有用的方法
…
Expanding Query Transformer
ExpandingQueryTransformer 使用 LLM 将给定的 Query 扩展为多个 Query。 这很有用,因为 LLM 可以以各种方式重新表述和重新表达 Query, 这将有助于检索更多相关内容。
Content
Content 表示与用户 Query 相关的内容。 目前,它仅限于文本内容(即 TextSegment), 但将来可能支持其他模态(例如,图像、音频、视频等)。
Content Retriever
ContentRetriever 使用给定的 Query 从底层数据源检索 Content。 底层数据源可以是几乎任何东西:
嵌入存储
全文搜索引擎
向量和全文搜索的混合
网络搜索引擎
知识图谱
SQL 数据库
等等
ContentRetriever 返回的 Content 列表按相关性排序,从最高到最低。
Embedding Store Content Retriever
EmbeddingStoreContentRetriever 使用 EmbeddingModel 嵌入 Query, 从 EmbeddingStore 检索相关 Content。
以下是一个例子:
EmbeddingStore embeddingStore = …
EmbeddingModel embeddingModel = …
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
// maxResults 也可以根据查询动态指定
.dynamicMaxResults(query -> 3)
.minScore(0.75)
// minScore 也可以根据查询动态指定
.dynamicMinScore(query -> 0.75)
.filter(metadataKey(“userId”).isEqualTo(“12345”))
// filter 也可以根据查询动态指定
.dynamicFilter(query -> {
String userId = getUserId(query.metadata().chatMemoryId());
return metadataKey(“userId”).isEqualTo(userId);
})
.build();
Web Search Content Retriever
WebSearchContentRetriever 使用 WebSearchEngine 从网络检索相关 Content。
所有支持的 WebSearchEngine 集成可以在这里找到。
以下是一个例子:
WebSearchEngine googleSearchEngine = GoogleCustomWebSearchEngine.builder()
.apiKey(System.getenv(“GOOGLE_API_KEY”))
.csi(System.getenv(“GOOGLE_SEARCH_ENGINE_ID”))
.build();
ContentRetriever contentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(googleSearchEngine)
.maxResults(3)
.build();
完整示例可以在这里找到。
SQL Database Content Retriever
SqlDatabaseContentRetriever 是 ContentRetriever 的一个实验性实现, 可以在 langchain4j-experimental-sql 模块中找到。
它使用 DataSource 和 LLM 为给定的自然语言 Query 生成并执行 SQL 查询。
有关更多信息,请参阅 SqlDatabaseContentRetriever 的 javadoc。
这里有一个示例。
Azure AI Search Content Retriever
AzureAiSearchContentRetriever 是与 Azure AI Search 的集成。 它支持全文、向量和混合搜索,以及重新排序。 它可以在 langchain4j-azure-ai-search 模块中找到。 请参阅 AzureAiSearchContentRetriever Javadoc 获取更多信息。
Neo4j Content Retriever
Neo4jContentRetriever 是与 Neo4j 图数据库的集成。 它将自然语言查询转换为 Neo4j Cypher 查询, 并通过在 Neo4j 中运行这些查询来检索相关信息。 它可以在 langchain4j-community-neo4j-retriever 模块中找到。
Query Router
QueryRouter 负责将 Query 路由到适当的 ContentRetriever。
Default Query Router
DefaultQueryRouter 是 DefaultRetrievalAugmentor 中使用的默认实现。 它将每个 Query 路由到所有配置的 ContentRetriever。
Language Model Query Router
LanguageModelQueryRouter 使用 LLM 决定将给定的 Query 路由到哪里。
Content Aggregator
ContentAggregator 负责聚合来自以下来源的多个排序 Content 列表:
多个 Query
多个 ContentRetriever
两者都有
Default Content Aggregator
DefaultContentAggregator 是 ContentAggregator 的默认实现, 它执行两阶段倒数排名融合(RRF)。 更多详细信息请参阅 DefaultContentAggregator 的 Javadoc。
Re-Ranking Content Aggregator
ReRankingContentAggregator 使用 ScoringModel(如 Cohere)执行重新排序。 支持的评分(重新排序)模型完整列表可以在 这里找到。 更多详细信息请参阅 ReRankingContentAggregator 的 Javadoc。
Content Injector
ContentInjector 负责将 ContentAggregator 返回的 Content 注入到 UserMessage 中。
Default Content Injector
DefaultContentInjector 是 ContentInjector 的默认实现,它简单地将 Content 附加到 UserMessage 的末尾,前缀为 Answer using the following information:。
你可以通过 3 种方式自定义 Content 如何注入到 UserMessage 中:
覆盖默认的 PromptTemplate:
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from(“{{userMessage}}\n{{contents}}”))
.build())
.build();
请注意,PromptTemplate 必须包含 {{userMessage}} 和 {{contents}} 变量。
扩展 DefaultContentInjector 并覆盖其中一个 format 方法
实现自定义 ContentInjector
DefaultContentInjector 还支持从检索到的 Content.textSegment() 中注入 Metadata 条目:
DefaultContentInjector.builder()
.metadataKeysToInclude(List.of(“source”))
.build()
在这种情况下,TextSegment.text() 将以 "content: " 前缀开头, 而 Metadata 中的每个值将以键作为前缀。 最终的 UserMessage 将如下所示:
How can I cancel my reservation?
Answer using the following information:
content: To cancel a reservation, go to …
source: ./cancellation_procedure.html
content: Cancellation is allowed for …
source: ./cancellation_policy.html
并行化
当只有一个 Query 和一个 ContentRetriever 时, DefaultRetrievalAugmentor 在同一线程中执行查询路由和内容检索。 否则,将使用 Executor 来并行处理。 默认情况下,使用修改后的(keepAliveTime 为 1 秒而不是 60 秒)Executors.newCachedThreadPool(), 但你可以在创建 DefaultRetrievalAugmentor 时提供自定义的 Executor 实例:
DefaultRetrievalAugmentor.builder()
…
.executor(executor)
.build;
访问来源
如果你希望在使用 AI Services 时访问来源(用于增强消息的检索到的 Content), 你可以通过将返回类型包装在 Result 类中轻松实现:
interface Assistant {
Result<String> chat(String userMessage);
}
Result result = assistant.chat(“How to do Easy RAG with LangChain4j?”);
String answer = result.content();
List sources = result.sources();
在流式处理时,可以使用 onRetrieved() 方法指定 Consumer<List>:
interface Assistant {
TokenStream chat(String userMessage);
}
assistant.chat(“How to do Easy RAG with LangChain4j?”)
.onRetrieved((List sources) -> …)
.onPartialResponse(…)
.onCompleteResponse(…)
.onError(…)
.start();