StarRocks 在 Cisco Webex 的探索与实践

作者:
白旭:Cisco Software Engineer, Apache Amoro PPMC member
许鸿坤:Cisco Senior Software Engineer
导读:本文内容整理自 白旭 与 许鸿坤 两位嘉宾在 StarRocks Connect 2025 上的联合演讲。
基于 Cisco Webex 的核心分析场景,分享了从 Pinot 技术栈迁移至 StarRocks 的完整实践路径——涵盖存算分离与存算一体架构的落地,以及多项性能与治理优化。
迁移后,系统实现多项显著提升:
查询性能提升超 50%,70% 的查询语句优于 Trino;
物化视图让查询加速 10 倍以上;
Flat JSON 优化后磁盘占用降低 80%,查询时延减少 80%;
基于 Rack 的资源隔离实现多业务共集群部署;
向量化引擎与倒排索引优化显著提升复杂查询效率。
Cisco Webex 是一款专业的视频会议软件,其业务范围涵盖语音与视频通话、在线会议、会议设备以及即时通讯(Message)等核心功能。
在实际使用中,常见的应用场景包括:
问题排查(Troubleshooting):通过分析会议指标(如入会延时、通话质量等),定位并解决性能问题;
数据分析:数据科学家或分析师利用 OLAP 技术进行查询与取数;
通过 Dashboard 做可视化报表展示。
为什么引入 StarRocks?
原有 OLAP 技术栈概览
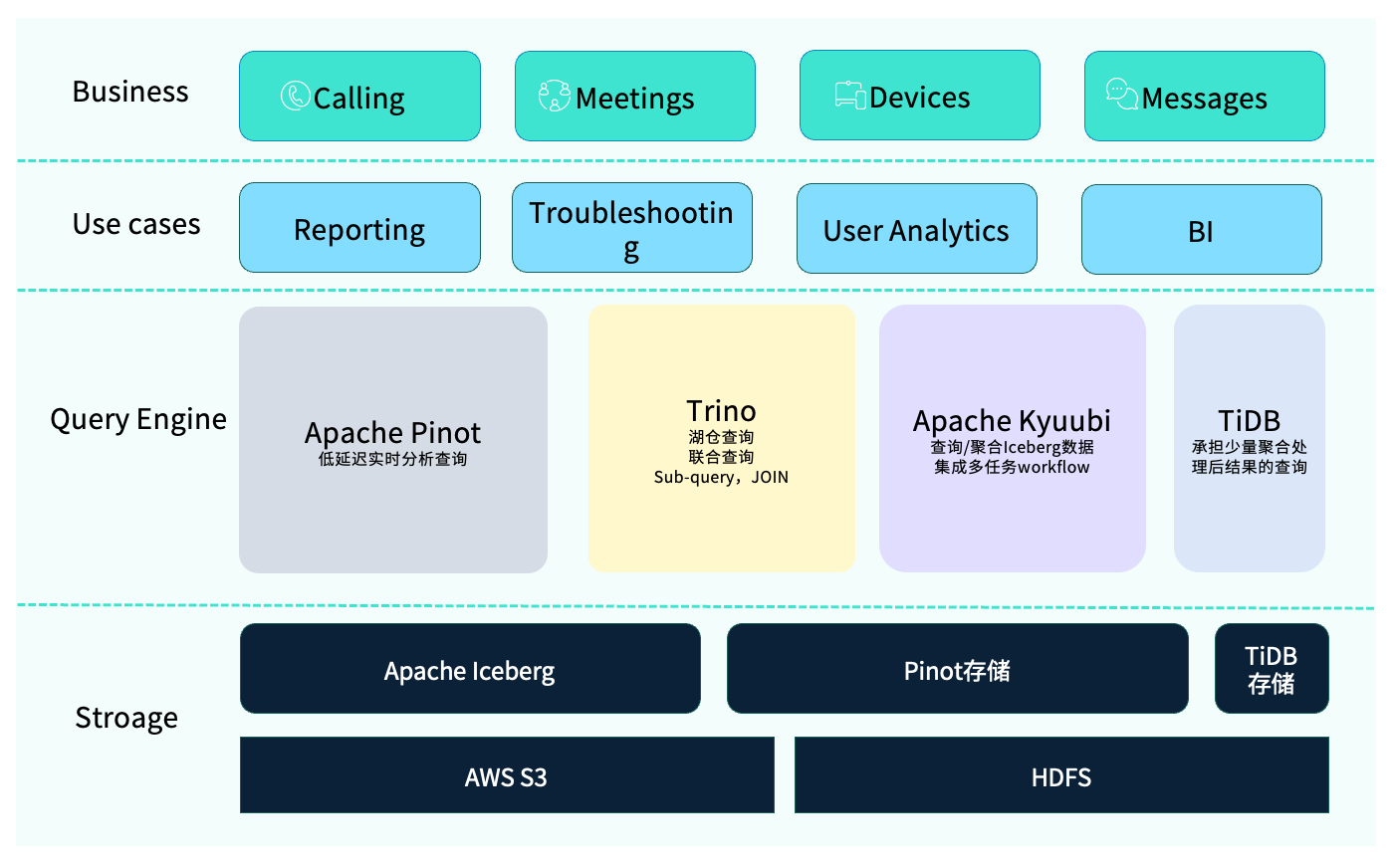
在此前的架构中,我们采用了一套相对复杂的 OLAP 技术栈。
其中使用最频繁的是 Apache Pinot,主要用于低延时的实时查询。然而,Pinot 也存在一些限制,例如不支持子查询及多表 Join。为弥补这部分能力,我们引入了 Trino,用于处理复杂查询逻辑及访问湖仓(Iceberg)中的数据。实际业务中,Trino 与 Pinot 的联邦查询已成为常见的分析模式。
此外,部分经过聚合后的结果数据,工程师会通过 Python 或 Spark 写入 TiDB,以便后续灵活取数。我们还使用 Apache Kyuubi 来处理多任务的工作流,它基于 Apache Spark 与内部数据平台协同工作,用于执行数据查询、下游数据分发及简单的 ETL 操作(如 Insert into)。
在存储层面,整体架构同样具备多元化特征。由于 Webex 的业务覆盖全球,不同区域的数据合规要求差异较大——例如欧盟地区对数据隐私与合规性要求更为严格,而北美地区部分组织则对敏感数据的管理有额外限制。因此,我们采用了混合存储方案:部分数据存放在 AWS S3,另一部分则保存在私有 HDFS 集群中,以满足不同地区的安全与合规标准。
面临的挑战

然而,这套 OLAP 技术栈在实际使用过程中也暴露出不少问题,尤其是对 Pinot 的反馈最为集中。主要痛点包括:
维护与成本高:Apache Pinot 的运维复杂度更高,日常管理负担较重。除了自身的高维护成本外,系统同时运行 Trino 与 Pinot 两套体系,还需建立独立或额外的监控方案,进一步加重了运维负担。
节点稳定性与依赖复杂:在部分场景下,Pinot 实例可能出现宕机,需要通过双副本机制保证数据冗余;当节点故障时,系统会自动切换至备用节点,或执行 backfill 操作修复数据错误。此外,Pinot 依赖 ZooKeeper 等外部组件实现高可用(HA),使得系统结构更复杂、维护链条更长。
功能缺失:Pinot 不支持多表 Join 与子查询。虽然可以借助 Trino 进行联邦查询,但性能表现仍不理想,尤其缺乏物化视图(Materialized View) 支持。在典型场景中,查询过去 180 天数据时,其中大部分为重复扫描,导致计算资源浪费;若具备物化视图能力,可通过增量计算显著提升查询效率。
数据新鲜度与 SLA 风险:对于 Pinot 的实时表,当某一时间段数据出现错误时,往往需要重新回放整段数据以修复,既增加了系统负担,也影响数据时效性和稳定性。
用户体验割裂:由于系统中存在多种查询引擎,分析师需要掌握不同语法与操作方式,学习成本较高。对于性能较差的 SQL,还需工程师反复手动优化,影响效率。
需要什么样的 OLAP 引擎?

综合来看,我们希望新的 OLAP 引擎能够在性能、功能、成本与运维等方面全面提升。主要诉求包括:
新的引擎需要在性能上具备足够优势,能够支持多表 Join 与子查询等复杂操作,确保查询结果的准确性与响应速度。同时,应支持物化视图以加速常见查询。
对半结构化数据的良好支持:在日常业务中,我们的明细数据结构(schema)变化频繁,例如不同日期的字段内容、统计维度都会有所调整,因此需要引擎能够灵活处理半结构化(Semi-structured)数据,保证查询的兼容性与稳定性。
统一的查询与使用体验:希望能够通过统一的查询体系,减少分析师在不同引擎间切换的学习成本,同时降低平台自身的维护负担。
更低的总体成本
可通过将部分原存于 Pinot 的数据迁移至更经济的存储介质(如 S3 或 HDFS),实现显著的存储降本;
可依托自适应压缩(ZSTD)、Compaction 等优化机制进一步提升资源利用率。
通过统一的告警体系和自动扩缩容能力。目前团队在存算一体与存算分离两种架构下,均已实现基于 StarRocks 的统一查询能力。
存算分离架构的迁移与实践
Trino VS StarRocks
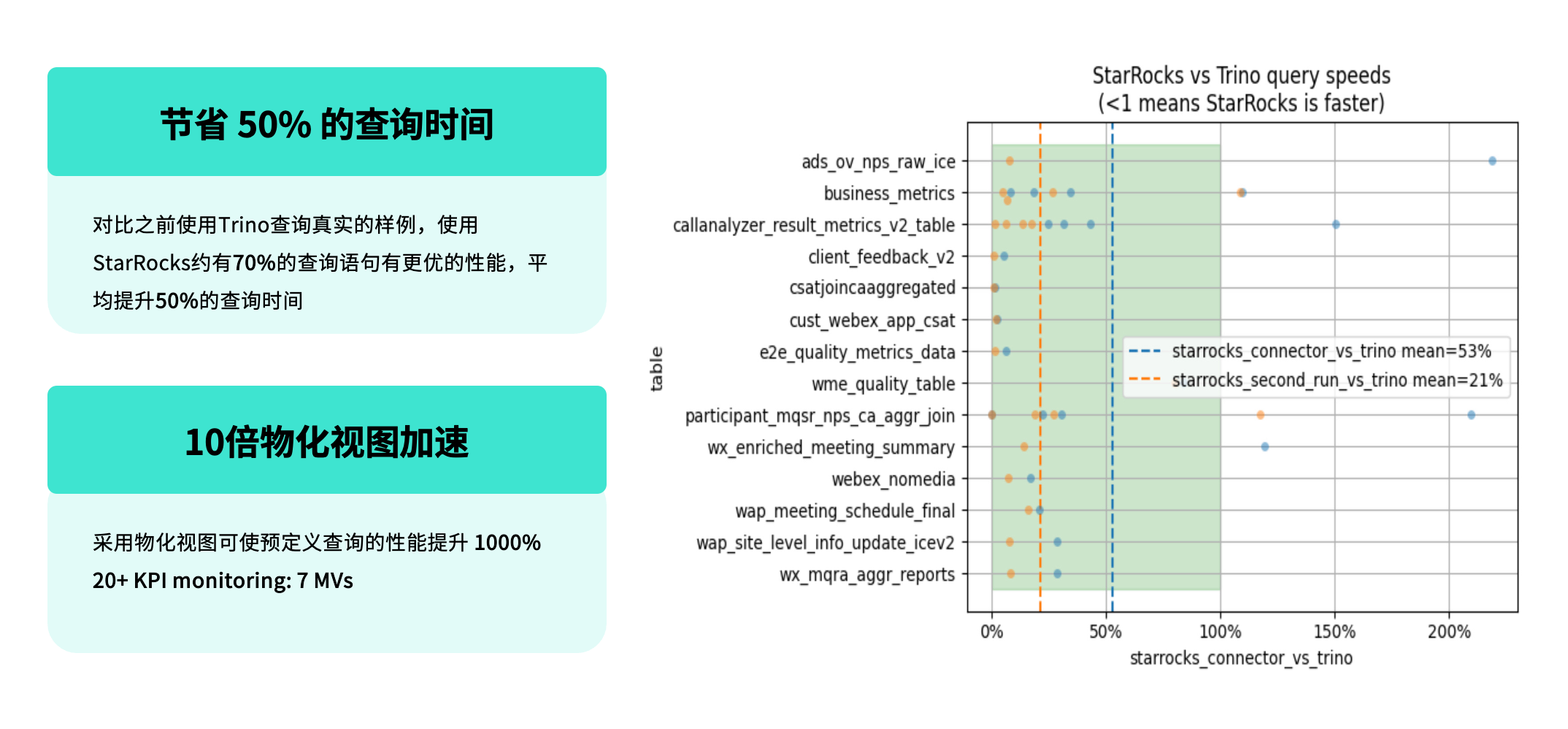
在采用存算分离架构后,我们重点评估了 StarRocks 与 Trino 在实际业务场景中的性能表现,并基于真实查询负载进行了对比测试。
测试结果显示:
在相同的业务查询场景下,约 70% 的查询语句在 StarRocks 上的性能优于 Trino;
平均查询时延较 Trino 提升约 50%;
在第二次查询(即缓存命中场景)中,StarRocks 的性能仍然领先,平均提升约 21%。
团队预定义了一批通用 SQL,通过物化视图机制统一管理,支持多种实际查询场景的复用,使整体查询性能提升超过 10 倍。
HPA 自动扩所容
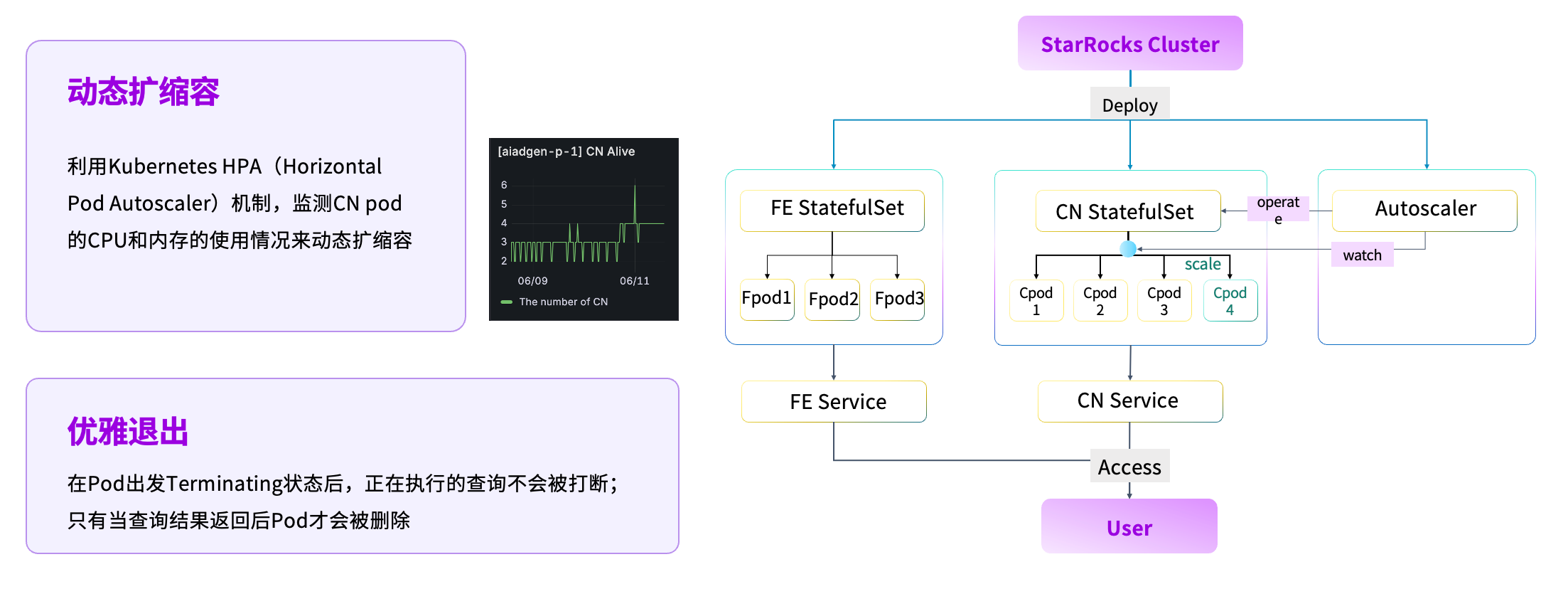
在资源管理层面,我们基于 Kubernetes 完成了自动扩缩容能力建设。当前绝大多数组件均运行在 Kubernetes 环境中,我们通过引入 HPA(Horizontal Pod Autoscaler),动态监测 CN Pod 的 CPU 与内存使用情况,实现计算资源的按需伸缩。当业务负载降低时,系统可自动释放计算资源。同时,为确保正在执行的任务不受影响,平台会在 Pod 退出前检测其状态,仅在 SQL 执行完成后才允许回收资源,实现优雅退出。
Self-Help Provisioning
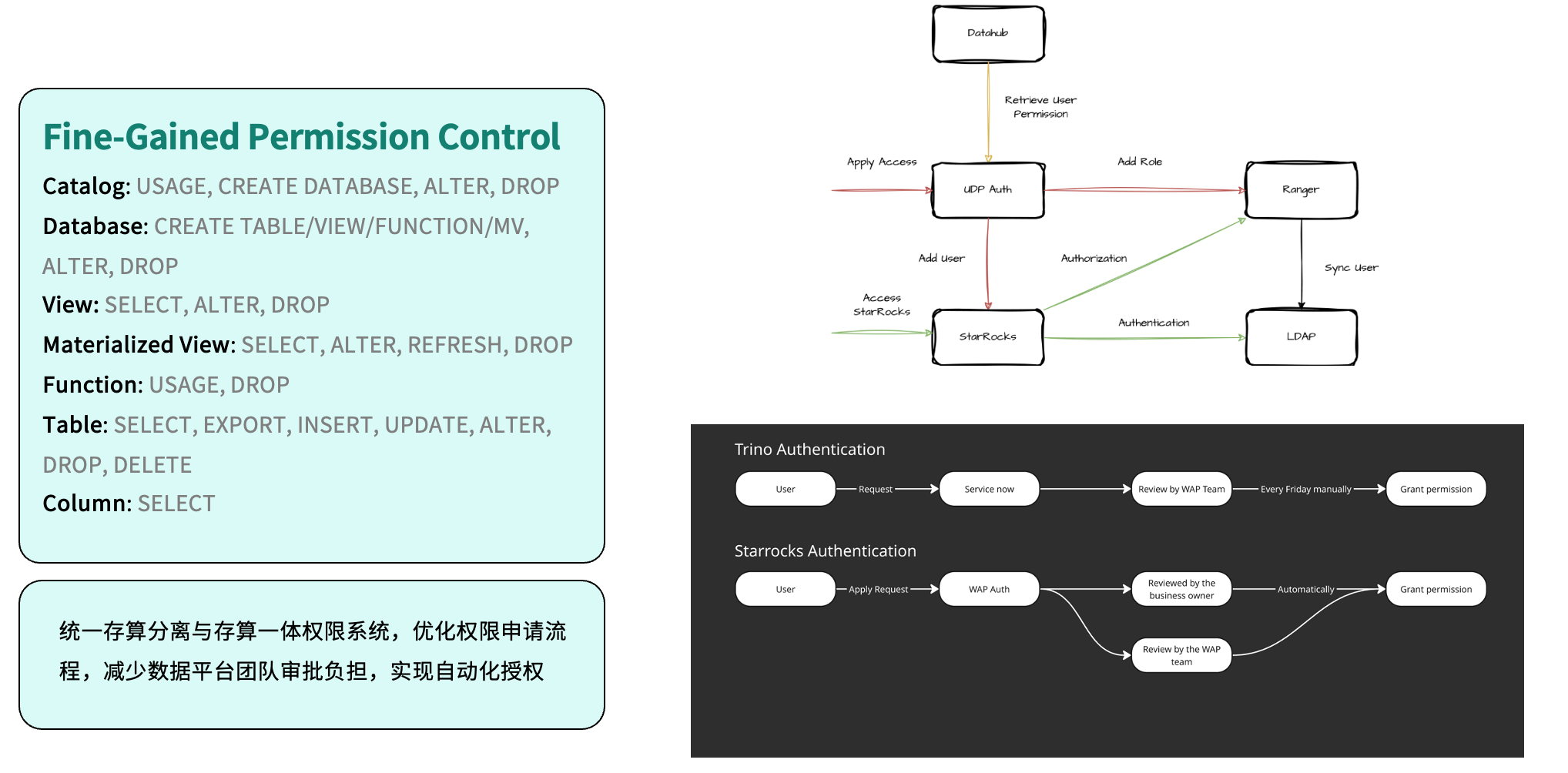
在安全与权限管理方面,我们完成了权限体系的统一整合。系统集成 Apache Ranger 进行规则配置,并通过 LDAP 实现集中身份认证,所有权限最终统一至自研平台 UDP(Unified Data Platform) Auth 进行管理。相比此前基于 Trino 的人工授权流程,如今用户申请权限后即可由业务维护者或系统自动审批,实现了授权的自动化。这不仅提升了安全与合规性,也显著减少了人工操作与运维负担。
统一 SQL 查询
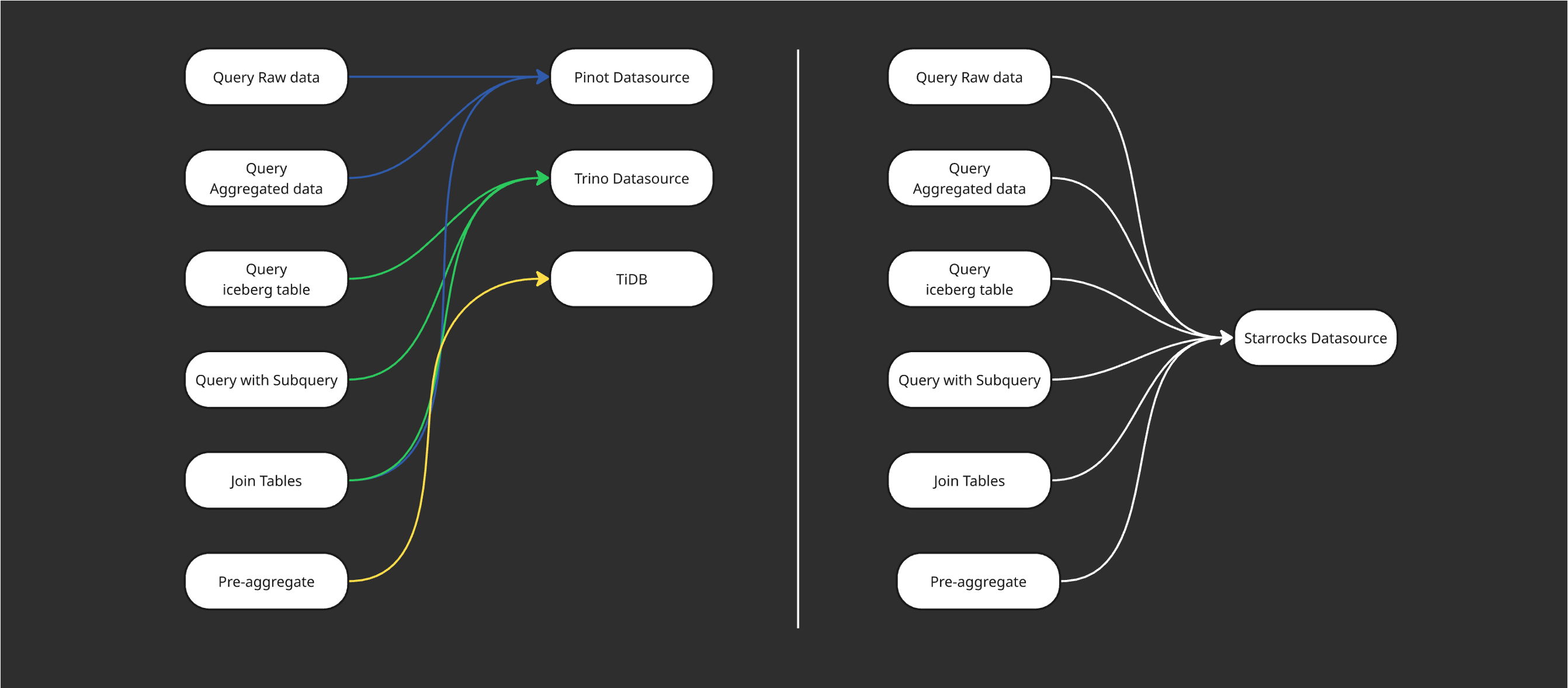
在查询体系的统一过程中,我们也针对不同场景的语法差异进行了兼容与优化。此前,团队会根据业务特征选择不同的 OLAP 引擎进行查询;而在统一架构后,所有查询均基于 StarRocks 进行执行。
为实现平滑迁移,我们对 Trino 与 Pinot 的查询方言进行了适配与转换。以 Trino 为例,团队在内部进行了覆盖率测试,结果显示约 90% 的场景可通过 Trino Dialect 实现语法转换,极大简化了用户迁移的成本与使用难度。
与此同时,我们还针对 Pinot 的语法特性进行了系统化的方言转换(下文将详细介绍),确保不同架构模式下(无论是存算一体还是存算分离),均可通过 StarRocks 实现统一的查询体验与结果一致性。
半结构化数据类型 —— Variant
什么是 VariantDataType?
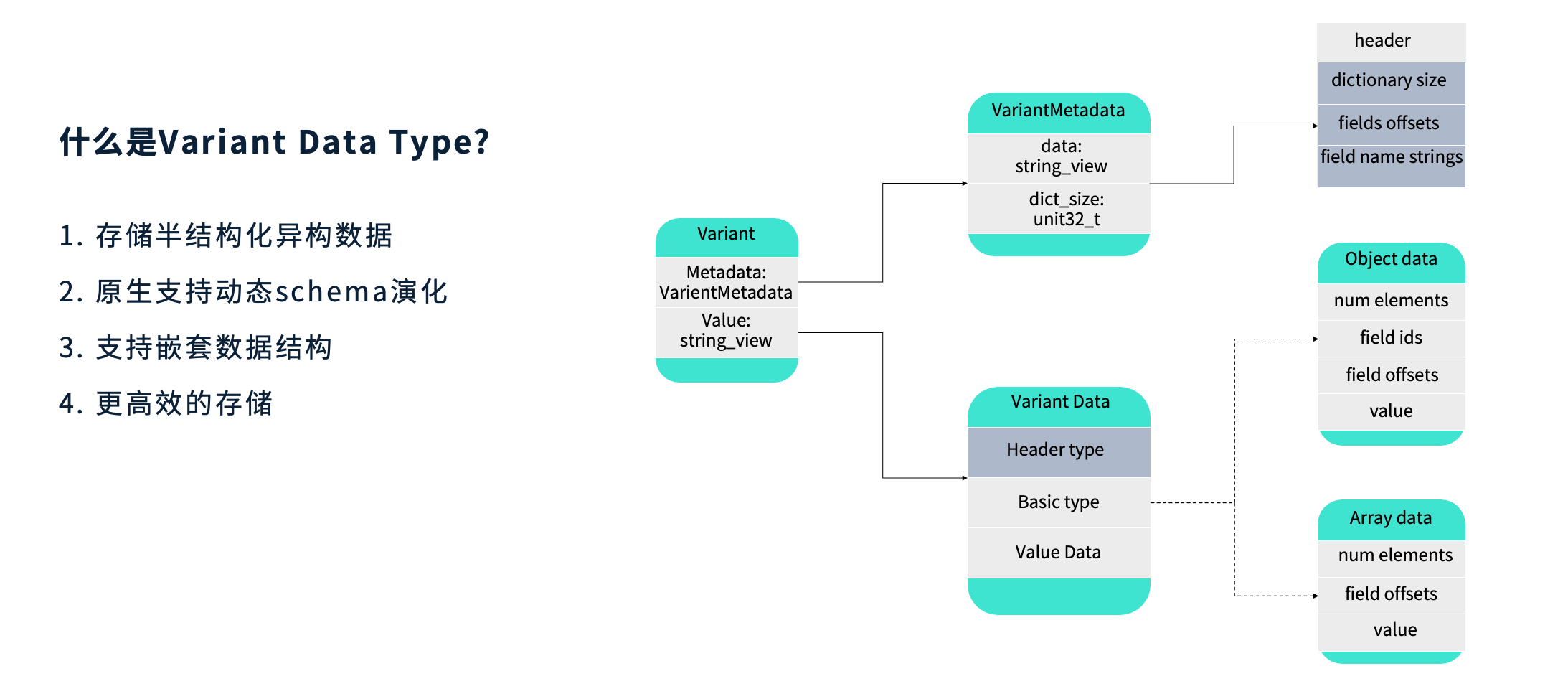
Variant 是一种用于存储动态变化的半结构化数据的数据类型,典型应用场景是查询 JSON。它能够原生支持动态 Schema 演化,并具备对嵌套数据结构的识别与处理能力。由于采用了更高效的编码方式,Variant 在性能与空间利用率之间取得了良好平衡。
Variant Encoding

从编码结构上看,Variant 由两部分组成:Metadata(元数据) 与 Value(数据值)。
Metadata 用于描述整体结构信息,如版本号、字段属性等。在当前版本(Version 1)中,Header 中记录了规范版本、字典是否为短字符串(short)或唯一(unique)等信息,以及便于后续读取的 offset 索引。
Dictionary 可理解为存储所有 JSON 字段名称的字符串集合;
Value 部分保存实际数据值,支持多种基础类型(Basic Type),例如 primitive、short string 等。针对短字符串类型,Variant 在 Value Header 中进行了特殊优化,会额外存储字符串的长度以便快速解析。
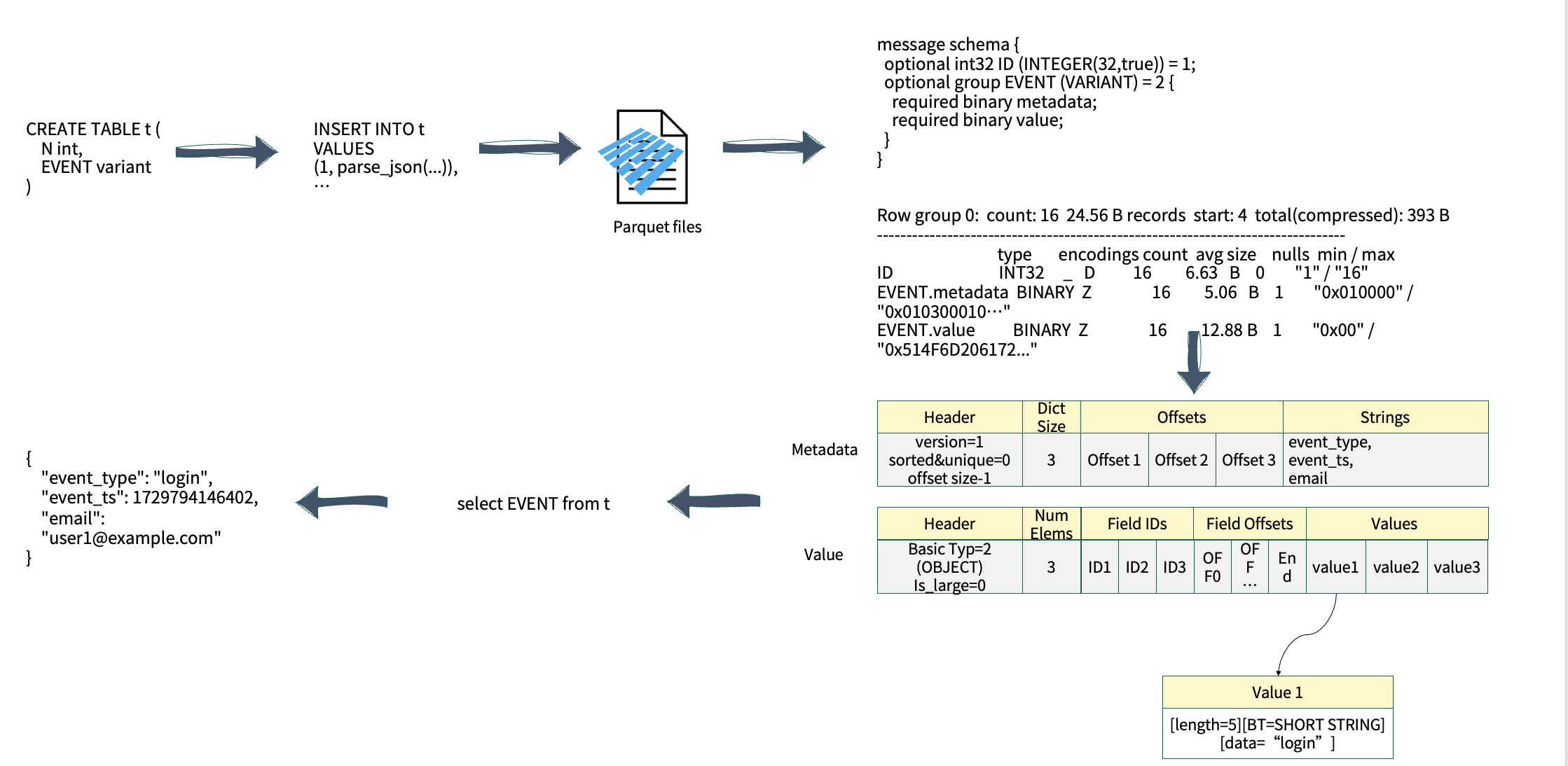
除了基础类型外,Variant 还支持 Object 与 Array 等复杂结构。以实际应用为例,当创建包含 Variant 字段的表并将数据写入 Parquet 文件时,其 Schema 结构会分为两部分(如上图右侧所示):
Metadata:使用 BINARY 类型存储整体元数据;
Value:同样以 BINARY 类型存储实际值。
在查询一个 Object 结构 JSON 的执行过程中,用户需访问 JSON 中的某个字段,系统会首先读取对应的 Object 元数据信息并判断目标 Key 是否存在。一旦定位到相应的 Key,系统会根据其 Offset 精确读取对应的内存地址。这一机制使得 Variant 查询的整体性能优于传统的字符串型 JSON 查询。
Implementation
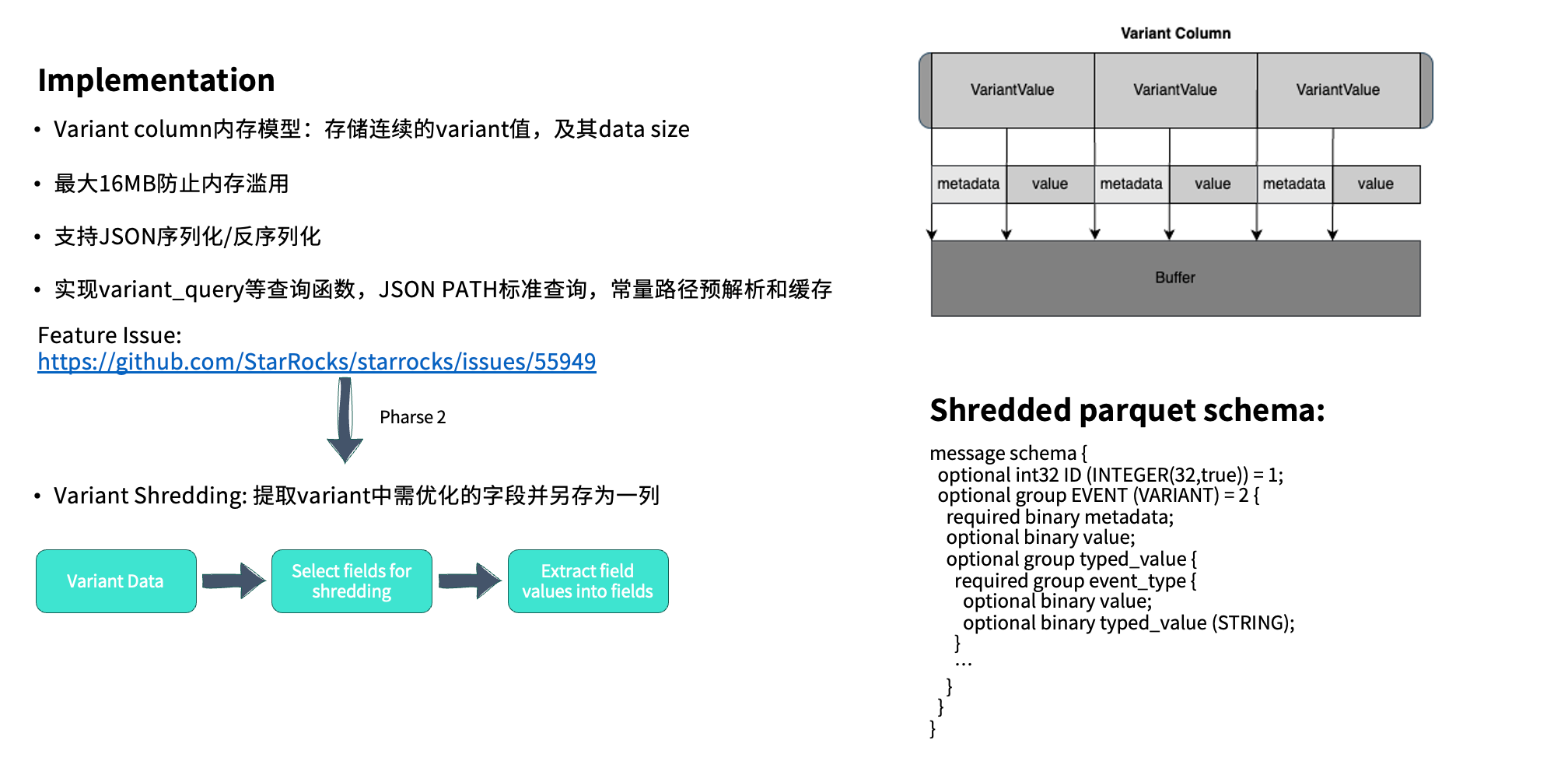
在此基础上,系统还引入了进一步的性能优化机制 —— Variant Shredding。对于查询频次较高的字段,可以将其单独拆解并存放在独立的字段(type_value)中。在实际查询时,只需直接访问 type_value 字段即可,无需再遍历完整的 Value 内容,从而进一步提升查询效率。
这一过程将在后续版本的 Feature 中持续完善。目前针对筛选字段的选取策略仍在优化中。根据与 Snowflake 团队的沟通,他们采用的方案相对直接——选择查询频率最高的前 10 个字段作为 Shredding 对象。
从底层实现来看,Variant Column 实际上会存储一系列连续的 Variant 值,其中包含完整的 Metadata 与 Value,并在最前端通过 Header 记录数据长度,以便实现高效的序列化与反序列化。
此外,我们还扩展了 Variant Query 相关函数,实现通过 JSON path 的标准化访问方式。
存算一体引擎的迁移与实践
在迁移之前,我们主要使用的 OLAP 引擎是 Apache Pinot。相比之下,Pinot 在国内的应用相对较少,国内更多团队采用的是 Apache Druid。实际上,Pinot 与 Druid 在架构设计上非常相似:
它们都依赖 ZooKeeper 进行集群协调,并通过 DeepStore 或其他 Web 组件实现数据存储;同时,两者都包含类似的系统角色设计,包括 Master Server、Broker 以及负责数据存储的 Historical 节点。
为什么从 Pinot 升级到 StarRocks ?
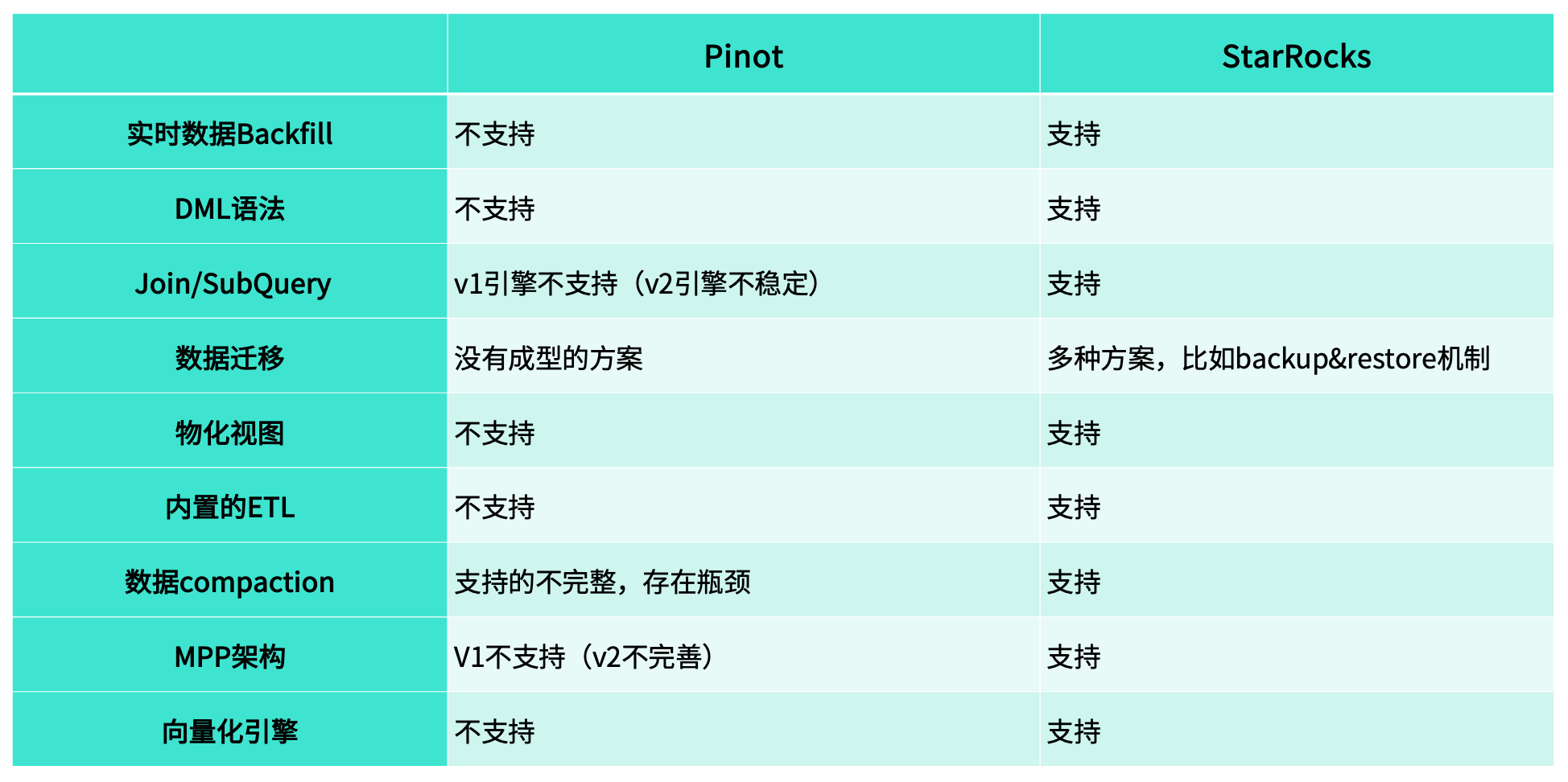
主要原因在于,Pinot 在实际使用中暴露出一系列结构性限制与痛点。
实时数据 Backfill
对于 Pinot 而言,它并不支持分区机制。这意味着,当实时数据不断写入时,单个 Segment 内往往会混杂多天的数据,因此无法实现精确的 Backfill 操作。
相比之下,StarRocks 原生支持分区管理,我们在实际使用中通常以“天”为分区单位。这种设计使得数据修复与回补更加灵活高效:当某一天的数据出现异常时,只需重新加载对应分区即可完成 Backfill,避免了重复处理历史数据。
DML 语法
在 Pinot 中,系统并不支持常见的 DML 操作,如 INSERT、DELETE 或 UPSERT / UPDATE。这意味着,一旦数据出现问题,即便只是个别记录出错,也必须依赖完整的 Backfill 流程来重新加载数据,操作繁琐且成本较高。
而 StarRocks 原生支持多种 DML 操作,用户可以根据实际情况灵活地进行数据插入、删除或更新。
这种能力在小规模数据修正场景中尤为高效——例如,当仅有少量记录(几十条甚至更少)需要修改时,无需重新执行大规模的回填操作,只需通过简单的 UPDATE 即可完成数据修复。
Join/SubQuery
我们使用 Pinot 的时间较早,从 0.8 版本开始部署。当时系统尚不支持 Subquery(子查询) 和 Join 操作。
虽然在 1.1 版本之后,Pinot 官方引入了新的查询引擎,开始支持这两类操作,但在实际使用中,我们发现其稳定性仍然不足——SQL 查询容易报错,内存占用高,整体运行不够稳定。
为弥补这些限制,我们曾使用 Trino 作为中间层,与 Pinot 进行联合查询。然而,这种组合在实践中也存在明显问题。首先,Trino 的算子下推受限。在访问半结构化数据时,部分函数无法下推至 Pinot 层执行,导致大量数据被 Trino 拉取到上层处理,不仅查询效率低下,也对 Pinot 集群造成较大压力。
其次,当 Trino 访问 Pinot 的数据量较大时,常常无法走通用的 HTTP Pipeline,而需要改用 gRPC 方式。但在这种模式下,Trino 的查询日志无法与 Pinot 的 Audit Log 系统对接,导致无法完整记录查询信息,不利于产线问题的排查。
这种分离式架构给运维带来了显著挑战。当 Pinot 出现异常时,我们无法通过 Query Metrics 快速定位问题,也无法进行有效的故障排查。而在 StarRocks 中,算子可直接下推至存储层执行,查询性能更优,且所有的查询有统一的管理位置,便于产线问题的排查和定位。
数据迁移
在实际业务中,我们经常会有数据迁移的需求。例如,原先部署在物理机上的集群,可能由于公司合规要求需要迁移至 S3;而当 S3 成本超出预算时,又需要将数据迁回本地集群。这类迁移任务频繁发生,但 Pinot 并未提供完善的迁移方案,缺乏统一的工具和流程支持。
为了解决这一问题,我们团队曾基于 Trino 自行开发了一套 Migration Task 机制,用于在不同存储介质之间转移数据。然而,由于自研方案在设计时难以覆盖所有异常场景,在实际运行中仍会遇到稳定性与一致性问题。
相比之下,StarRocks 在数据迁移与备份方面提供了更成熟的体系。一方面,系统支持 Backup & Restore 功能,可在集群间快速恢复数据;另一方面,Sync Tool 工具能够实现数据的自动化同步与恢复,帮助我们在迁移任务中更高效地保障数据完整性与业务连续性。
物化视图
Pinot 至今仍未支持物化视图功能,在过去的使用中,我们只能通过外部服务实现替代方案:通常的做法是按天聚合原始数据,生成新的聚合表,再将结果写回系统中。这种方式不仅实现复杂,而且只能满足 “T-1” 的聚合需求。
而在 StarRocks 中,我们可以直接利用物化视图机制实现高效的实时聚合。无论是 15 分钟级还是 1 小时级的增量刷新,都能得到良好支持。
内置的 ETL
Pinot 并未提供直接的数据处理与重构功能,这在数据研究和生产应用中带来了较多不便。
在 StarRocks 中,这类需求可以通过简单的 SQL 实现——例如使用 INSERT INTO SELECT,即可基于现有表快速生成新的数据集,用于测试、验证或迁移。
而在 Pinot 中,即便仅需构建一份测试数据,也必须重建表结构、重新 Backfill 数据,操作繁琐且耗时。
数据 Compaction
在使用 Pinot 时,这一问题尤为明显。Pinot 的 Upsert 表虽然名义上支持更新操作,但实际上并不具备真正的 Compaction 能力——系统无法自动清理重复的 Key。因此,当同一主键下存在多条重复记录时,这些冗余数据仍会被完整保留,久而久之造成磁盘占用显著增加。
相比之下,StarRocks 的主键表原生支持 Compaction,能够自动合并重复数据、保留最新版本。
MPP 架构
Pinot 的 V1 引擎不支持 MPP,V2 虽开始支持但稳定性较弱;而 StarRocks 原生采用 MPP 架构,分布式计算能力更成熟、性能更稳定。
向量化引擎
Pinot 不支持向量化计算,而 StarRocks 原生具备这一能力。在我们的测试中,一张包含 80 亿行数据的表,即便未建立任何索引,也能在 约 1 秒内完成查询,性能优势十分显著。
SQL Dialect Transformer
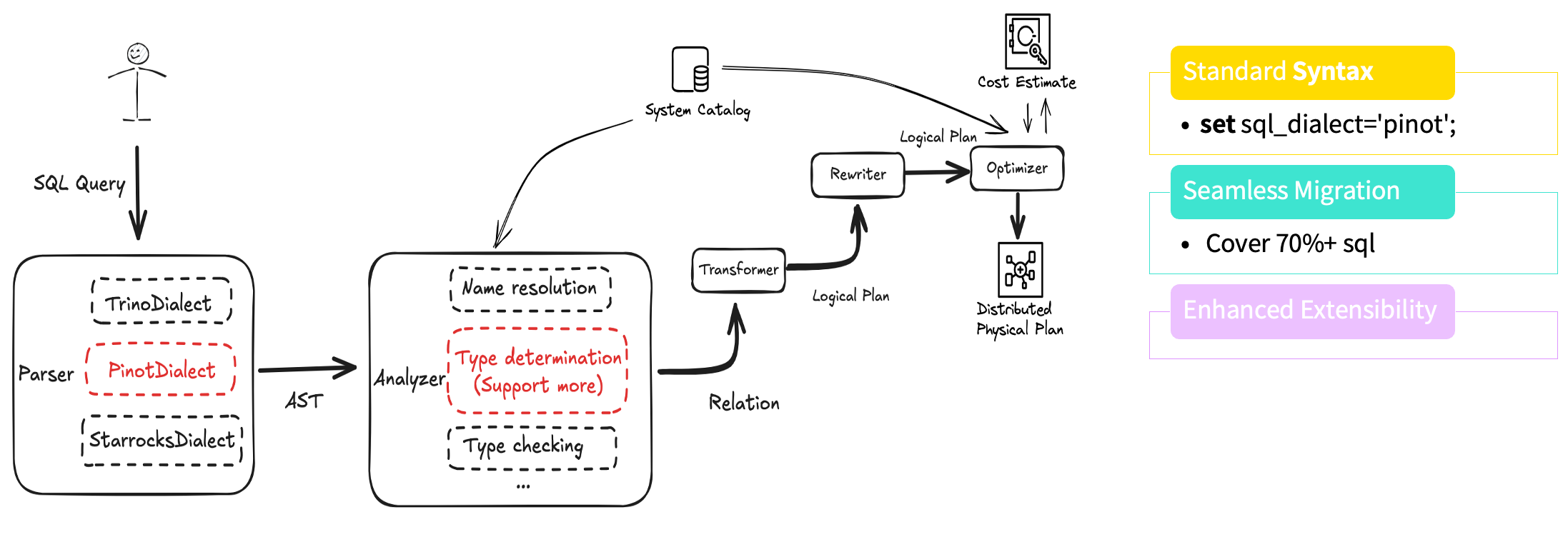
在迁移过程中,我们首先开展的工作是 SQL Dialect Transformer(SQL 方言转换)。如前所述,业务团队通常不希望修改已有 SQL 来适配新引擎。
一方面,SQL 改造对他们而言没有直接业务价值;另一方面,Pinot 本身在索引和内存利用方面表现良好,即使切换引擎,性能提升也未必直观,因此业务方缺乏改造动力。
为此,我们开发了 Pinot Dialect Transformer,让用户在无感知的情况下即可将原有 SQL 无缝迁移至 StarRocks。
在实现上,我们参考了 Trino Dialect 的设计思路,对函数名、参数位置及参数数量等差异进行了自动转换与重建。
在 SQL 解析阶段,系统能够自动识别并转换成 StarRocks 支持的语法,从而兼容原有查询逻辑。经过测试,目前该方案可自动覆盖约 70% 以上的 SQL 语句,大幅降低了人工修改与沟通成本。同时,该架构具备良好的可扩展性,后续只需扩展新的函数,即可快速支持新的语法特性。
基于 Rack 的资源隔离实践
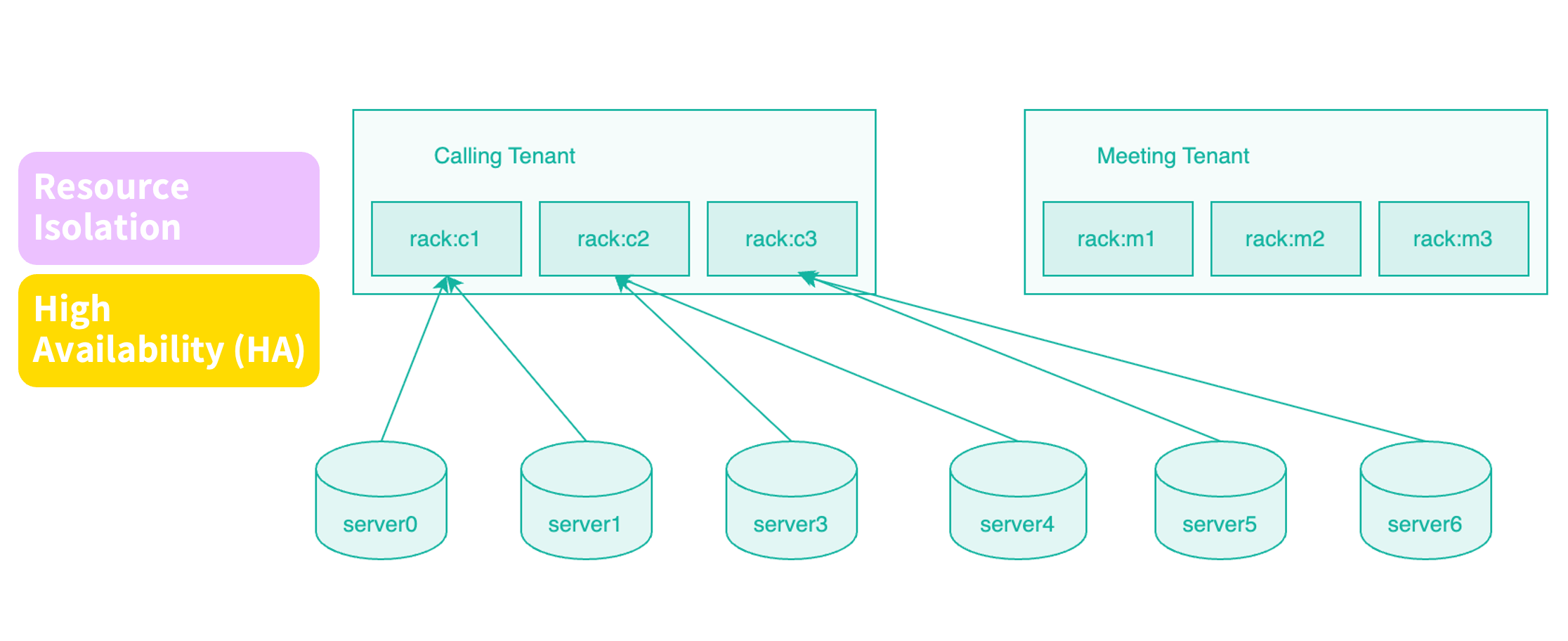
在 Pinot 中,我们长期使用 Tenant(租户)机制来实现多业务共存与资源隔离。StarRocks 目前尚未原生支持 Tenant 概念。为此,我们经过调研与验证,发现可以通过 Rack(机架)策略实现类似的隔离效果。
具体做法是:在同一集群中,为不同业务分配不同的机器组。例如,在一套包含 30 台节点的集群中,可将前 10 台用于 Device 服务,中间 10 台用于 Meeting,其余节点用于 Calling。
通过这种物理级别的资源划分,即便某个业务(如 Calling)执行了重负载或高频查询,也不会影响到其他服务的运行。这种设计在多业务共用集群的场景中尤为关键。根据我们在 Pinot 运维中的经验,如果缺乏明确的资源隔离,一个业务的异常常常会拖垮整个集群。
在真实生产环境中也遇到了一些问题。以我们当前的部署为例,共有 30 台机器,计划将前 10 台划分为 Device 业务节点。
理论上,我们希望只需在这 10 台机器上统一设置相同的 Rack 标签(例如“rack:device”),系统即可在该范围内自动分配副本,实现高可用。但在当时的版本中并不支持这种逻辑,必须将这 10 台机器进一步细分为多个 Rack(如 device1、device2、device3),系统才能正确分配副本。
针对这一问题,我们与社区深入讨论后,增加了一个可选参数,用于在调度过程中显式强调高可用性优先,从而实现 Rack 级别的副本控制。
此外,我们还优化了 BE 节点扩容时触发的 Rebalance(数据再均衡) 逻辑,并在内部调度算法中引入对 Rack 信息的识别与权重考虑。
Flat JSON 的使用与优化 1
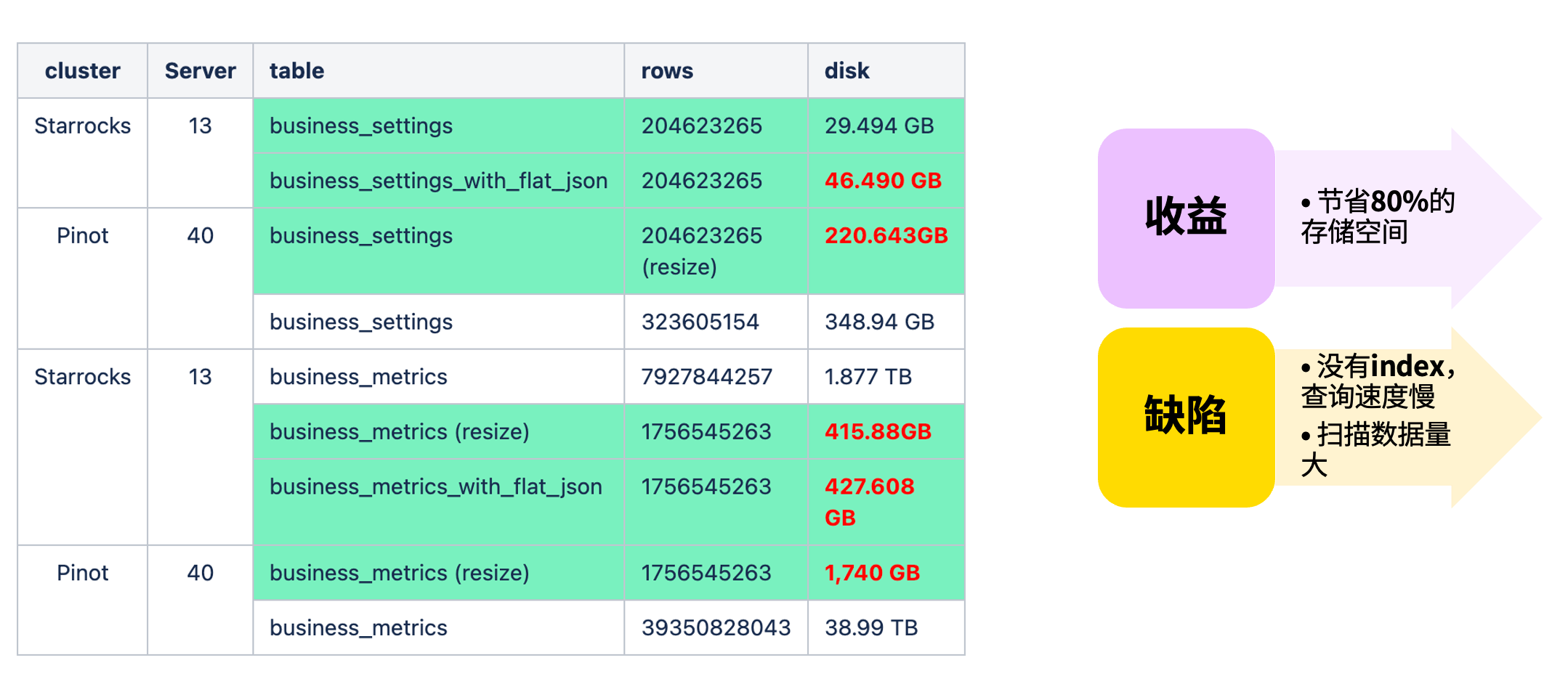
在 Pinot 中,我们主要通过基础方式处理半结构化数据;而迁移至 StarRocks 后,第一个业务场景就包含大量 Semi-Structured 数据,因此重点探索了 Flat JSON 的使用与优化。
我们在实际数据上进行了测试。通过将 JSON 字段展开为物化子列,存储空间显著减少。结果显示,使用 Flat JSON 后磁盘占用可降低约 80%,带来了非常可观的收益。
不过,目前的 Flat JSON 也存在一些局限:由于暂不支持建立索引,查询和扫描时仍会产生一定的性能损耗。为此,我们结合业务特性进行了进一步优化。
Flat JSON 的使用与优化 2

不同业务的数据规范差异较大。例如,同一张表可能同时记录来自不同客户的数据——沃尔玛的数据结构以销量、价格为主,而苹果的数据则侧重产品属性与配置。当这些结构差异较大的 JSON 混合存储时,现有 Flat JSON 无法有效提取物化子列,从而影响查询效果。
针对这一问题,我们优化了 Flat JSON 的配置机制。原先该功能仅支持集群级别配置,而现在我们将其下沉至表级别:每张表都可根据自身数据结构独立设置 sparsity factor (数据稀疏度)、null factor(空值处理方式)等参数。
该功能预计将在 StarRocks 4.0 版本中正式发布,届时用户可像修改表参数一样灵活调整配置,而无需逐一通过 API 触发每个 BE 节点。
Flat JSON 的使用与优化 3
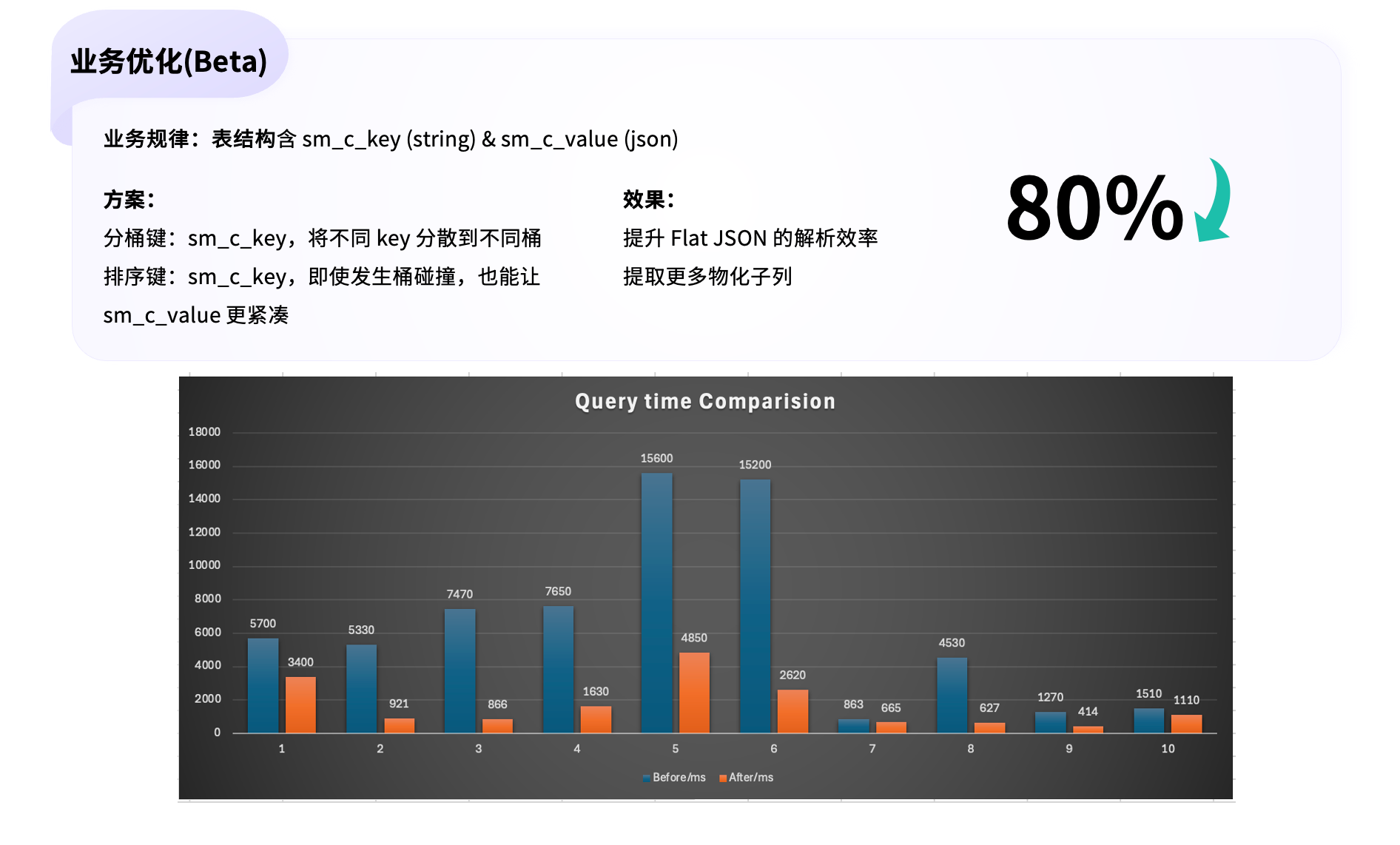
由于同一张表中往往同时存储多家公司的数据,不同业务的数据结构差异较大,这会削弱 Flat JSON 的效果——当多种 JSON 结构混合在同一表中时,物化子列的提取效率会显著下降。
为此,我们采用了更合理的分桶键(Bucket Key) 与排序键(Sort Key) 设计方案。
尽可能让不同公司的数据分布在不同的 Tablet 下,提高其数据局部性。即使在极端情况下,不同业务数据仍分布到了同一 Tablet (哈希冲突),我们依然可以利用排序键对数据进行重新分布,使其落入不同的 Segment。由于 Flat JSON 的优化效果最终作用于 Segment 级别,这一策略能够显著提升其整体性能。
根据测试结果,该优化方案相较于原始实现可 降低约 80% 的查询时延。
Gin Index 的优化
在倒排索引的使用中,我们发现其行为往往像一个“黑盒”——用户难以直接了解分词器在处理文本后的实际效果。
为此,我们新增了一个 tokenize 函数,用户可以通过该函数清楚地看到在指定分词器下,输入文本被解析成的最终 Token 形式,从而更好地理解索引效果。
此外,我们还针对算子(Operator) 进行了扩展与优化。为了更好地承接业务需求,我们将原有的 match 算子进行了抽象化处理,构建了一个可扩展的算子规则框架,使其能够灵活扩展基于 match 的等多种模式。基于这一框架,我们开发了新的 MATCH_ALL 以及 MATCH_ANY 算子,可直接下推至存储引擎执行,大幅提升查询效率。
由于 match phrase 的支持需要依赖 Clucene 组件。并且社区在早期为降低存储成本而移除了位置信息,我们在内部版本中恢复了该功能,使系统能够重新支持短语级匹配,目前相关测试已完成,后续功能开发仍在持续推进中。
未来规划

未来的优化工作主要聚焦在三个方向:
Query Insight
我们计划在现有社区提供的 Query Profile 基础上,进一步完善查询洞察体系,使系统能够更清晰地展示 SQL 各算子的执行耗时。此外,还将引入智能优化建议机制,当某些算子执行时间过长时,系统能够自动给出潜在的优化方案。
半结构化数据支持
当前的重点仍在 Flat JSON。尽管我们已在性能与易用性上进行了大量优化,但由于其暂不支持索引,查询性能与 Pinot 仍存在一定差距。同时,我们也在继续推进 Variant Shredding 的优化方案。
文本检索优化
在文本检索方面,我们仍有多项改进计划:
目前主键表与存算分离架构均不支持倒排索引,算子类型与配置选项也相对有限。我们正与社区合作,持续扩展支持范围,完善配置能力。
同时,我们也在探索新的搜索引擎方向。例如,社区正在构建新的存储引擎以替代 Clucene,我们内部也在探索是否可将 Clucene 升级至 Tantivy 等其他新一代的文本搜索引擎或者搭建 StarRocks 内置的文本搜索引擎。