Rust:复合类型内存布局
Rust:复合类型内存布局
- 结构体
- 内存对齐
- repr 属性
- 元组
- 联合体
- 枚举
- 判别值
- 携带参数
- repr 属性
- 零大小类型 ZST
- 空位优化
在Rust中,编译器要求在编译期就确定栈区的内存模型。对于复合类型来说,它内部往往由多个元素组成,那么这些元素在内存中如何布局就是一个重要的话题。本文将深入复合类型的内存布局,并讲解其impl的特性。
结构体
内存对齐
对于一个结构体,它的多个元素并不是简单的按顺序排列,而是有间隙地进行对齐。就像在一些排队的窗口,人不是紧密的一个挨着一个,而是隔开了合适的社交距离。
比如以下结构体:
#[repr(C)]
struct Example {a: u8,b: u16,c: u64,d: u32,
}fn main() {println!("{}", size_of::<Example>());
}
理论上,如果完全不考虑对齐,最小大小就是几个元素大小的加和 1 + 2 + 8 + 4 = 15。
但是实际运行 size_of 输出是 24,说明元素之间并不是紧密排列的,这个机制就叫做内存对齐。
内存对齐规则如下:
- 系统会有一个默认对齐数
N(通常等于 CPU 字长,常见 x86_64 下就是 8)。 - 第一个元素放在偏移量
0。 - 后续元素的对齐数
Si = min(自身大小, N),该元素的偏移量必须是Si的倍数。 - 结构体整体大小也必须是所有字段
Si的最大值的倍数。
回到刚才的例子:
#[repr(C)]
struct Example {a: u8,b: u16,c: u64,d: u32,
}
假设默认对齐数 N = 8,现在我们逐个计算偏移:
- 第一个元素
大小为1 byte,S1 = min(1, 8) = 1,由于它是第一个元素,自动对齐到偏移量为0的位置,共占1 byte。

- 第二个元素
大小为2 byte,S2 = min(2, 8) = 2,所以第二个元素必须对齐到偏移量为2的倍数处,在第一个元素填充完毕后,第一个2的倍数处就是2本身。所以它对齐到2,占用2 byte。

- 第三个元素
大小为8 byte,S3 = min(8, 8) = 8,所以第三个元素必须对齐到偏移量为8的倍数处,上一个元素结束后,下一个为8的倍数位置就是8本身。所以它对齐到8,占用8 byte。

- 第四个元素
大小为4 byte,S4 = min(4, 8) = 4,所以第四个元素必须对齐到偏移量为4的倍数处,上一个元素结束后,下一个为4的倍数位置是16本身。所以它对齐到16,占用4 byte。

最后取出max(S1, S2, S3, S4)的最大值8,整个结构体的大小还必须是8的倍数,因此在d后面又会多出4 byte的空白,整个结构体大小为24 byte。
另外的,当结构体内嵌套结构体,那么内部的结构体初始对齐数为它所有对齐数Si的最大值。
比如:
#[repr(C)]
struct Inner {x: u32,y: u16,
}#[repr(C)]
struct Outer {a: u8,b: Inner,c: u64,
}
这就是一个结构体嵌套的例子,它最终的内存模型如下:

对于a和c就不再讲解了,按照之前的规则就可以推出来,主要讲解内部嵌套的b: Inner。
对Inner本身,Sx = min(4, 8) = 4,Sy = min(2, 8) = 2。那么当Inner作为一个元素嵌套到别的结构体,它的初始对齐数是S_inner = max(Sx, Sy) = 4。
随后在对b对齐的时候,S2 = min(S_inner, 8) = 4,因此上图中b会对齐到4的倍数处。
repr 属性
也许你已经注意到了,之前所有的结构体前面我都加上了#[repr(C)]。如果你有C语言的经验,会发现内存对齐的规则和C语言一模一样。
回到这个案例:
你有没有觉得这个结构体浪费了好多内存?d刚好占用4 byte,而b和c之间刚好空开了4 byte,能不能把d塞进去?完全可以!
依据内存对齐规则,以下代码只占16 byte:
#[repr(C)]
struct Example {a: u8,b: u16,d: u32,c: u64,
}
此处只是把c和d交换了位置,内存布局如下:

结构体瞬间缩小了1 / 3,而且只有1 byte的空白区域。
其实,如果你保持原来a、b、c、d的排列顺序,如果是C语言,那么就是24 byte,但如果是Rust规则,只占用16 byte。
如果你想启用Rust本身的规则,要么在结构体顶上添加 #[repr(Rust)],要么啥也不写,默认就是Rust规则。
struct Example {a: u8,b: u16,c: u64,d: u32,
}#[repr(Rust)]
struct Example {a: u8,b: u16,c: u64,d: u32,
}
以上两种写法,最后结构体都只占用16 byte,因为Rust会根据内存布局,自动重新排列元素,基于内存对齐规则前提下,让结构体占用最小空间。
之前为了展示内存对齐规则,我特地使用了 #[repr(C)] 来禁止这项优化。
在大部分场景下,我们不会使用 #[repr(C)] 这个属性,从而获取更高的性能。但是如果你需要让你的结构体可以传入到C语言接口中,那么你就需要使用这个属性,这也是这个属性原本的目的。
除此之外,repr还有几个常见的情况:
#[repr(Rust)](默认):编译器可重排字段以获得更优布局#[repr(C)]:按 C 语言规则布局,字段顺序即声明顺序,便于和C风格接口交互#[repr(packed)]:紧密打包,取消对齐填充#[repr(align(N))]:强制类型对齐到 N 字节
对于 #[repr(packed)],它直接禁用内存对齐规则,让所有元素一个挨着一个紧密排列。
之前的Example 结构体:
#[repr(packed)]
struct Example {a: u8,b: u16,c: u64,d: u32,
}fn main() {println!("{}", size_of::<Example>());
}
在这个情况下,最后输出的总大小就是15 byte,也就是1 + 2 + 4 + 8了。
还有之前一直默认系统的对齐数是8,实际上这个默认对齐数是可以自己指定的,就通过 #[repr(align(N))],一般来说N都会取2的幂。
元组
其实元组的排布,和结构体是完全相同的,同样遵循内存对齐的策略。
例如以下代码:
println!("{}", size_of::<(u8, u16, u64, u32)>());
println!("{}", size_of::<(u8, u16, u32, u64)>());
这其实就是刚才结构体的元组形式,两者输出的都是16 byte。说明元组同样遵循内存对齐策略,而且默认会别Rust进行调序处理,以缩减内存占用。
元组结构体也是同理:
struct ExampleTp1(u8, u16, u64, u32);
struct ExampleTp2(u8, u16, u32, u64);#[repr(C)]
struct ExampleTp3(u8, u16, u64, u32);fn main() {println!("{}", size_of::<ExampleTp1>());println!("{}", size_of::<ExampleTp2>());println!("{}", size_of::<ExampleTp3>());
}
此处输出:
16
16
24
相比于普通元组,元组结构体可以被#[repr(C)]这样的属性修饰,从而阻止Rust的内存调优。
联合体
联合体中,多个元素使用同一块内存,其实它的内存策略非常简单,联合体的大小取所有变体中最大的那个值。
union U {a: u32,b: u64,c: f32,
}fn main() {println!("{}", size_of::<U>());
}
例如以上的U,它的最终大小就是8 byte,因为三个变体中最大大小就是8 byte。
每当有新的元素出现,后面的值会直接在二进制上覆盖前面的值。
另外的,当联合体内嵌到结构体,默认对齐数也是所有变体的对齐数中最大的那个,与结构体相同。
枚举
判别值
对于普通的枚举,它只占1 byte。
例如:
enum Color {Red,Green,Blue,
}
此处的Color大小就为1 byte,底层通过一个u8类型的整数,来判别当前是哪一个枚举值,这个数字称为判别值。
携带参数
Rust的枚举种类很丰富,可以携带参数,此时内存模型就不只是一个u8判别值这么简单了,枚举中还需要对参数进行存储。
例如:
enum Message {Quit,Move { x: i32, y: i32 },ChangeColor(i32, i32, i32),
}
这是一个携带参数的枚举,不同分支下携带的参数不同。
Rust的处理方案是,存储一个判别值 + 联合体。
类似于以下结构体:
union Data {quit: (),mov: (i32, i32),change_color: (i32, i32, i32),
}struct EnumMemoryLayout {discriminant: u8, // 判别值data: Data, // 携带的数据
}
在整个结构体头部存了一个u8的判别值,随后把三个变体放到了同一个union中,最后取内存占用最大的值。
此处还有一个细节,就是枚举变体中,参数原本是命名参数Move { x: i32, y: i32 },但是这个等效结构体中,变成了一个元组mov: (i32, i32),它们效果是一样的。刚才讲解元组的内存布局就说了,两者遵循同样的内存布局规则。
这个枚举最后的大小是16 byte,布局如下:
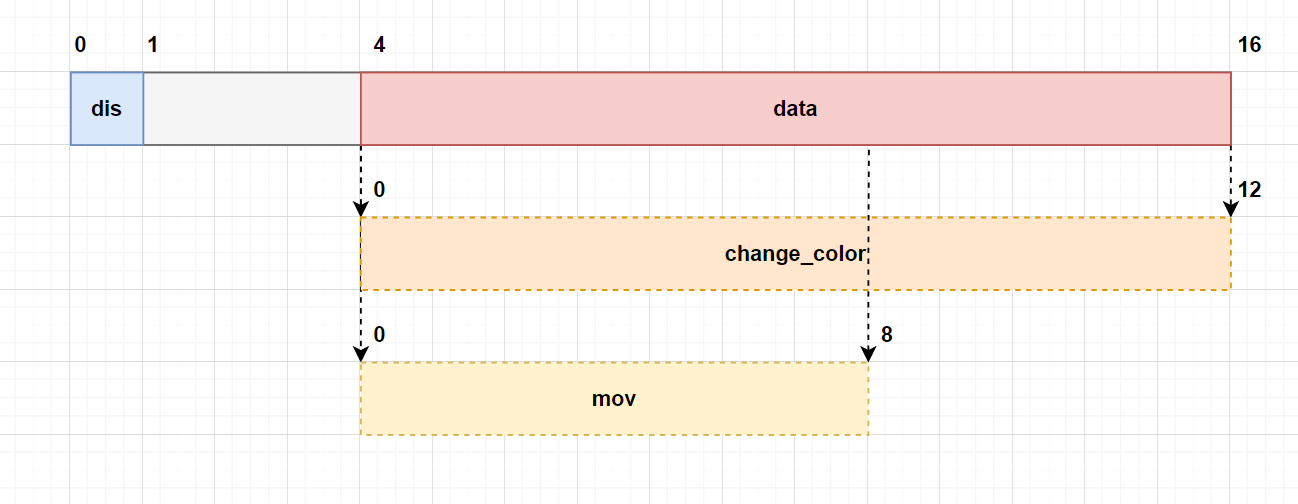
在这个过程中,实际上涉及了三层嵌套。
首先在data中有三个元素,quit、mov、change_color。其中mov和change_color可以视为内嵌的结构体,它们的对齐数分别为S_mov = max(4, 4) 和S_col = max(4, 4, 4),这里所有的4都是元组内i32的大小。
最后data的对齐数就是S_data = max(0, S_mov, S_col) = 4。因此当data内嵌到EnumMemoryLayout时,要对齐到4。
repr 属性
不仅仅结构体中可以使用repr属性进行优化,枚举同样适用。
与结构体相同的是,枚举默认使用#[repr(Rust)],底层会对枚举变体的顺序进行优化,让它占用更小的内存。使用#[repr[C]]可以阻止这项优化,保持与C语言的兼容性。但是,枚举不能直接用 #[repr(align(N))] 或 #[repr(packed)] 来指定对齐或取消对齐。
除去以上属性外,枚举还有自己特别的属性。之前所有案例中,我都说枚举的判别值类型为u8。实际上这个判别值类型是可以用户自己指定的,通过 #[repr(type)] 来使用指定类型的判别值。
例如:
#[repr(u64)]
enum MyEnum {A = 10,B,C = 20,
}
以上代码要求枚举的判别值使用u64类型,整个枚举的大小就是8 byte。
零大小类型 ZST
在讲解下一个知识点之前,我需要和大家科普一下零大小类型 ZST(Zero-Sized Type)。
零大小类型是指本身不占据任何内存空间的类型,比如单元类型()就是一个零大小类型。
它们往往用于进行一些标记属性,或者单纯用于承载一些方法,类似于面向对象语言中的接口类。
零大小类型的种类很多,比如空枚举,空结构体,空元组。
此外,只由零大小类型组合成的结构体和元组,还是一个零大小类型。
比如:
let zst_tuple: ((), ((), ())) = ((), ((), ()));
这元组由多个单元类型组成,它依然是一个零大小类型。还有比如说由零大小类型组成的数组[(); 100]它的大小也是0 byte。
空位优化
现在看一个奇怪的代码:
enum MayEmpty {Empty,Data(Box<i32>),
}fn main() {println!("{}", size_of::<Box<i32>>());println!("{}", size_of::<MayEmpty>());
}
以上代码中MayEmpty用于表示一个可能为空的枚举,如果为空,就用Empty枚举值,如果不为空,就用Data里面的Box指向数据。随后分别输出了Box<i32>和MayEmpty的大小。
输出结果:
8
8
这个结果其实非常超乎意料,因为两者的大小都是8 byte。我刚讲过,枚举中占用的空间是所有变体中最大的那一个,外加一个1 byte判别值。
此处的问题就是,判别值去哪里了?按照以上规则,那么这个 MayEmpty 的大小经过内存对齐后,应该是12 byte。
此处就是Rust底层的空位优化在生效。
当枚举中存在无数据的变体,且另一个变体存在无效的值,那么枚举中后省略掉判别值,以减少内存
在Rust中,语法上不存在空指针这种东西,因为Rust认为它是危险的,未定义的。从用户角度,一个指针不可能为空。
但是实际上空指针是存在的,就是所有位都为0的指针,这样一个地址根本不可能是正常获取的,一定是用户使用了某些unsafe手段产生的。
如果一个枚举触发了以上空位优化的条件,那么Rust底层会这么做:省略判别值,用无效值来表示那个不携带数据的变体。
比如对于这个Box<i32>指针,它的地址范围可能是0x00000001到0xFFFFFFFF,唯独不可能是0x00000000。于是Rust底层对它进行优化,既然原本 0x00000000 没有用,是一个无效值,那当Box<i32> 的值为 0x00000000 时,表示Empty这个枚举值。
我刚才对空位优化下定义的时候,两个变体的描述比较宽泛。
无数据的变体,并不是说它一定是一个不带参数的变体,只要这个变体不占用任何内存,整体是零大小的都可以。
例如:
struct ZeroType {}enum MayEmpty1 {Empty,Data1(Box<i32>),
}enum MayEmpty2 {Empty(),Data1(Box<i32>),
}enum MayEmpty3 {Empty(ZeroType),Data1(Box<i32>),
}
以上三个枚举,都可以触发空位优化,因为Empty、Empty()、Empty(ZeroType)都是不占用内存的零大小类型。
对于有无效值的变体,并不是说它一定要是一个指针,只要它存在可以被Rust识别的无效值即可。
比如说bool类型:
enum MayEmpty {Empty,Data(bool),
}fn main() {println!("{}", size_of::<MayEmpty>());println!("{}", size_of::<bool>());
}
以上代码,MayEmpty和bool的大小都是1 byte,触发了空位优化。
因为bool类型占用1 byte,它可以表示256种值,但是bool只有两种有效取值,0表示false和1表示true,剩下的254种都是无效值。只要Data的值是剩下的无效范围内,就认为是空值变体。
那么空值优化必须是 一个空值变体 + 一个有无效值的变体吗?
并不是,只要无效值的变体中,无效值的数量大于空值数量,都可以触发优化。
比如bool类型有254中无效值,那么就可以用小于等于254个空值变体+一个bool触发空值优化。
比如:
enum MayEmpty {Empty1,Empty2,Data(bool),
}
以上代码还是1 byte,有可能底层当Data = {0, 1}的时候表示Data,当Data = 2表示Empty1,当Data = 3表示Empty2(可能根据编译器,有不同的取值),这依然是触发了空值优化的。
但是把bool换回Box指针,就无法触发空值优化了:
enum MayEmpty {Empty1,Empty2,Data(Box<i32>),
}
以上枚举体占用16 byte,因为Box指针只存在一种无效值,而枚举中有两个空值变体,无法覆盖所有情况,必须额外添加一个判别值,内存对齐后就是16 byte。
最后一点,空位优化支持嵌套。
struct FatPtr {ptr: Box<i32>,len: usize,
}enum MayEmpty {Empty,Data(FatPtr),
}fn main() {println!("{}", size_of::<MayEmpty>());println!("{}", size_of::<FatPtr>());
}
以上代码中,FatPtr和MayEmpty的大小都是16 byte。因为FatPtr::ptr是一个指针,它存在无效值,相当于整个FatPtr存在一个无效值,那么就可以触发空位优化。