AI大模型-深度学习相关概念
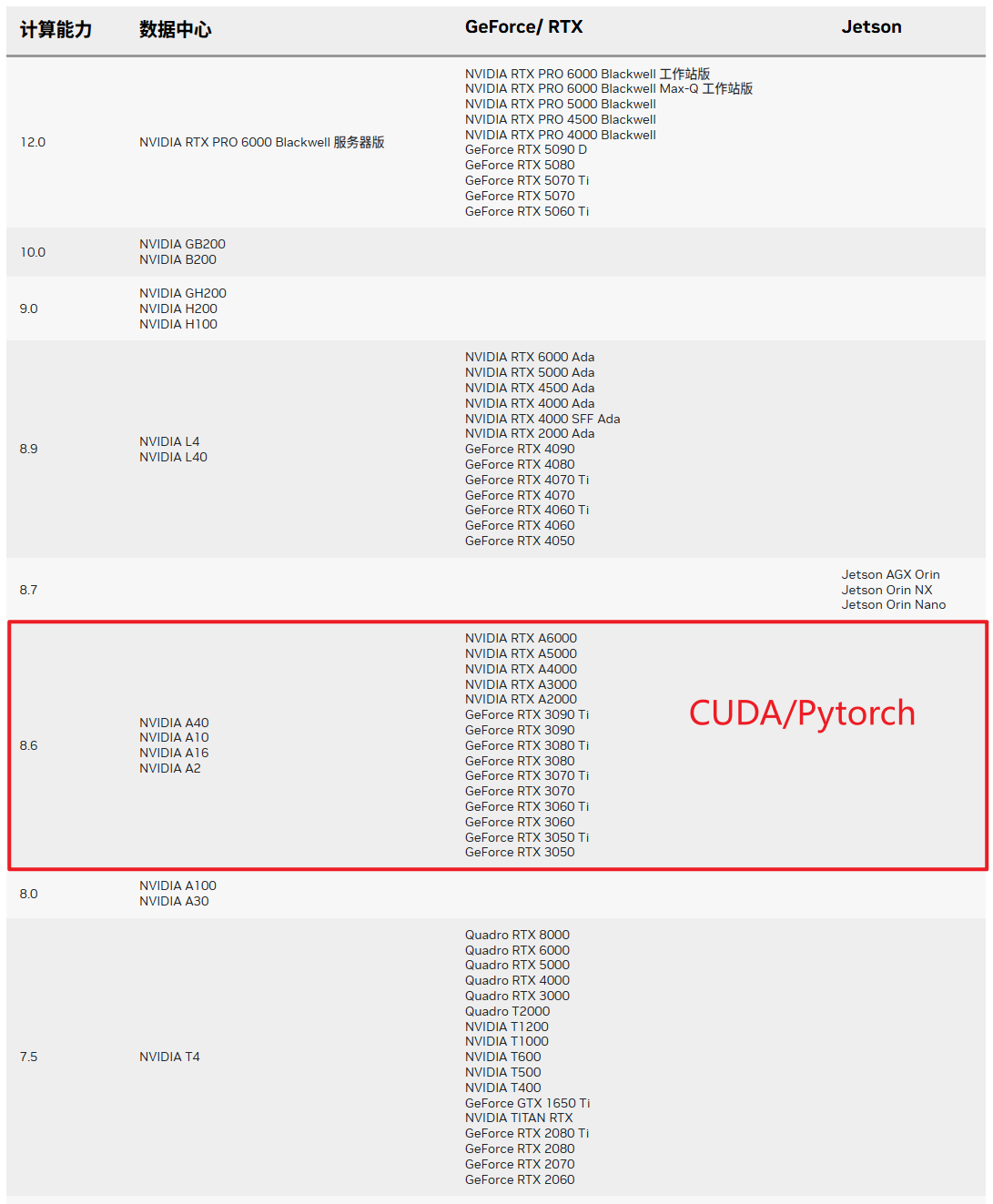
NVIDIA-GPU
标量 / 向量 / 矩阵 / 张量
你提的问题很关键,这些概念是理解大模型数据流转和计算逻辑的基础。简单说,它们是不同维度的“数值容器”,在大模型中分别承担着存储单个参数、单个特征、批量特征和高维复杂特征的角色。
1. 标量(Scalar):单个数值,0维
标量是最简单的“数值容器”,只有大小,没有方向,属于0维数据。
- 核心定义:单个实数或整数,比如1.5、3、0.001。
- 大模型举例:
- 学习率(Learning Rate):比如训练时设置的0.001,控制模型参数更新的步长。
- 损失值(Loss):每次模型迭代后输出的“误差分数”,比如0.3,代表预测结果与真实结果的差距。
- 困惑度(Perplexity):评估语言模型生成文本流畅度的指标,比如12,数值越低模型效果越好。
2. 向量(Vector):有序数值列表,1维
向量是“排成一列(或一行)的数值”,有方向和大小,属于1维数据,维度等于数值的个数。
- 核心定义:用方括号包裹的有序数组,比如[1.2, 3.4, 5.6],这个向量的维度是3。
- 大模型举例:
- 词嵌入(Token Embedding):大模型中每个“词/字(Token)”都会被转换成向量,比如GPT-3中每个Token对应12288维的向量,用来表示这个词的语义信息。
- 输出Logits向量:模型预测时,会输出一个与“词汇表大小”相同维度的向量,比如 vocab_size=50257 时,向量维度就是50257,每个数值代表对应词的“预测分数”。
3. 矩阵(Matrix):二维数值数组,2维
矩阵是“排成多行多列的数值表格”,属于2维数据,维度用“行数×列数”表示。
- 核心定义:用大括号或方括号包裹的二维数组,比如[123456]\begin{bmatrix}1 & 2 \\ 3 & 4 \\ 5 & 6\end{bmatrix}135246,这个矩阵的维度是3×2(3行2列)。
- 大模型举例:
- 批量词嵌入矩阵:当处理“一批(Batch)”文本时,比如一次输入32个Token,每个Token是12288维向量,就会形成32×12288的矩阵, rows=批量大小,cols=嵌入维度。
- 注意力权重矩阵:在Transformer的自注意力(Self-Attention)中,Query(查询)和Key(键)会计算出一个“序列长度×序列长度”的矩阵,比如序列长度为512时,矩阵维度是512×512,每个数值代表两个Token之间的“注意力强度”。
4. 张量(Tensor):≥3维的数值数组
张量是对标量、向量、矩阵的“维度扩展”,只要维度≥3,都可以称为张量,维度用“阶数”描述(3维=3阶张量)。
- 核心定义:多维度的数值集合,比如3维张量可以理解为“多个相同维度的矩阵堆叠”,维度表示为“深度×行数×列数”(或其他顺序,需看数据格式)。
- 大模型举例:
- 批量图像张量:如果大模型处理图像(如多模态模型),输入的批量图像会是4维张量,格式通常为“Batch×Channel×Height×Width”(BCHW)。比如32张RGB图像(3通道)、分辨率224×224,对应的张量维度就是32×3×224×224。
- 模型中间特征张量:Transformer层的输出通常是3维张量,维度为“Batch Size×Sequence Length×Hidden Dimension”(批量大小×序列长度×隐藏层维度)。比如批量32、序列长度512、隐藏层维度12288,张量维度就是32×512×12288,存储了整批文本经过当前层后的特征信息。
四者核心对比表
| 概念 | 维度(阶数) | 核心特点 | 大模型典型应用场景 |
|---|---|---|---|
| 标量 | 0维 | 单个数值,无方向 | 学习率、损失值、困惑度 |
| 向量 | 1维 | 有序列表,1个索引定位 | 单个Token的词嵌入、输出Logits |
| 矩阵 | 2维 | 表格结构,2个索引定位 | 批量词嵌入、注意力权重矩阵 |
| 张量 | ≥3维 | 多维度集合,≥3个索引定位 | 批量图像数据、Transformer层特征 |