【论文精读】DeepSeek-OCR:探索视觉 - 文本压缩的新范式
论文链接:DeepSeek-OCR: Contexts Optical Compression
代码仓库:https://github.com/deepseek-ai/DeepSeek-OCR
1. 引言
在大语言模型(LLMs)的发展过程中,处理长文本内容一直是一个重要挑战。由于计算复杂度随序列长度呈二次方增长,传统的文本处理方式在面对超长上下文时显得力不从心。DeepSeek-AI 团队提出的DeepSeek-OCR为这个问题提供了一个创新性的解决方案:利用视觉模态作为文本信息的高效压缩媒介。
这项工作不仅仅是一个 OCR(光学字符识别)工具,更是对视觉 - 语言模型(VLMs)的重新思考。它不再局限于人类擅长的视觉问答(VQA)任务,而是从 LLM 的角度出发,探索视觉编码器如何增强语言模型处理文本信息的效率。
2. 核心技术原理
2.1 视觉 - 文本压缩范式
DeepSeek-OCR 的核心思想是建立视觉表示和文本表示之间的自然压缩 - 解压缩映射。OCR 任务作为连接视觉和语言的中间模态,为这种压缩范式提供了理想的测试平台。
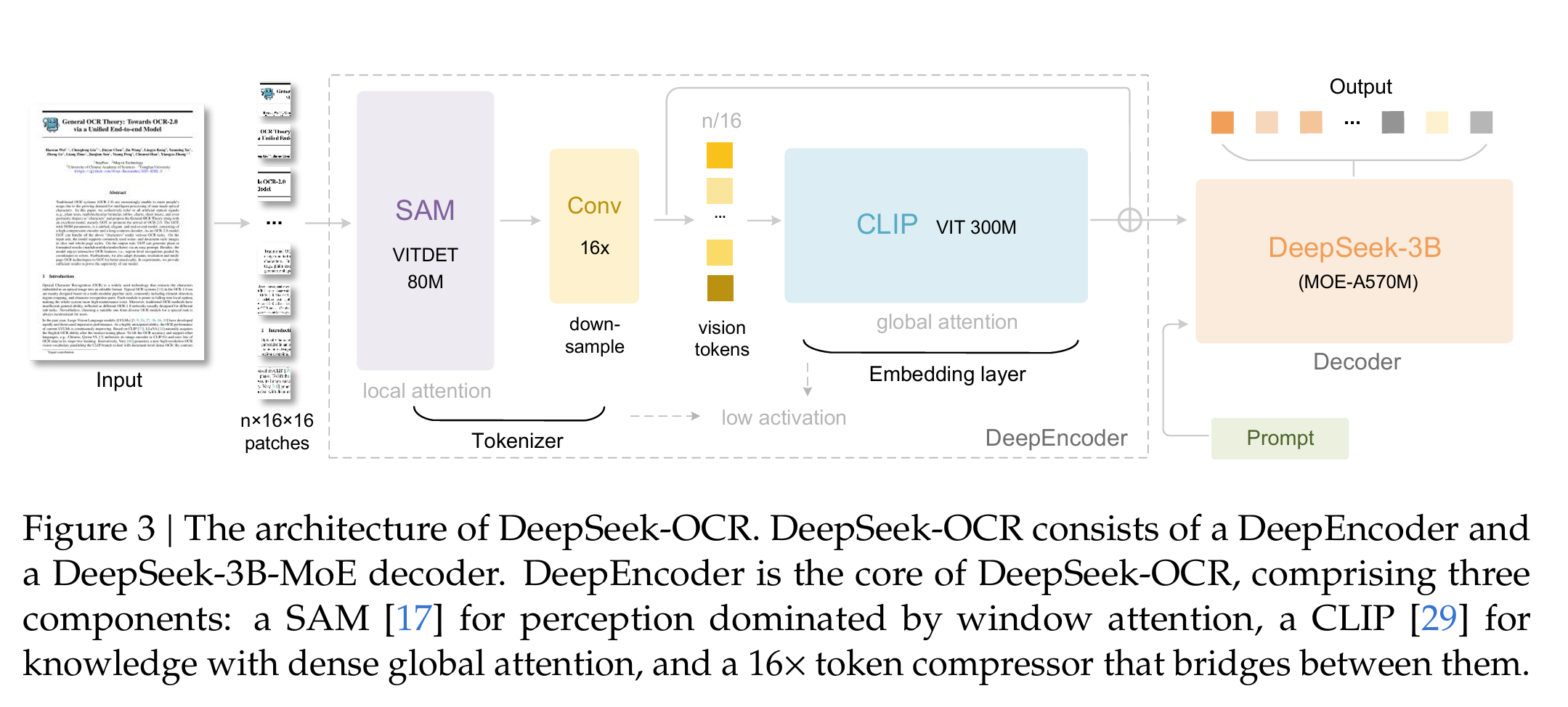
2.2 DeepEncoder 架构
DeepSeek-OCR 由两个主要组件构成:DeepEncoder 和 DeepSeek3B-MoE-A570M 解码器。其中 DeepEncoder 是整个系统的核心引擎,它的设计具有以下特点:
- 低激活内存设计:即使在高分辨率输入下也能保持较低的计算资源消耗
- 高效压缩比:通过创新的架构设计实现高压缩比,确保视觉 tokens 数量可控
- 混合注意力机制:
- 窗口注意力组件:处理大量视觉 tokens
- 全局注意力组件:捕获全局依赖关系
- 16× 卷积压缩器:连接两个注意力组件,实现有效压缩
这种设计确保了在保持识别精度的同时,最大限度地减少了视觉 tokens 的数量。
2.3 训练过程
2.3.1 训练数据准备
训练数据是模型性能的基础,DeepSeek-OCR 设计了 “OCR 核心数据 + 通用辅助数据” 的混合数据集,总规模超 150M 样本,各部分占比与细节如下:
| 数据类型 | 占比 | 核心内容与作用 |
|---|---|---|
| OCR 1.0 数据 | 70% | 传统 OCR 任务核心数据,含:1. 30M 页多语言 PDF(100 种语言,中 / 英文 25M 页,其他 5M 页),分 “粗标注”(fitz 提取,教基础文字识别)和 “细标注”(2M 页中 / 英文,用 PP-DocLayout+MinerU/GOT-OCR2.0 做布局 - 识别交织标注);2. 3M 页 Word 数据:无布局干扰的高质量图文对,优化公式 / HTML 表格识别;3. 20M 页自然场景数据:LAION/Wukong 来源,中 / 英文各 10M,PaddleOCR 标注,支持场景文字识别。 |
| OCR 2.0 数据 | 含于 OCR 数据中 | 复杂结构化解析数据,突破传统 OCR 边界:1. 10M 图表数据:pyecharts/matplotlib 生成(折线 / 柱状 / 饼图等),标注为 “图像→HTML 表格”;2. 5M 化学公式:PubChem 的 SMILES 格式→RDKit 渲染图像,构建图文对;3. 1M 平面几何:Slow Perception 方法生成,含线段 / 坐标标注,支持几何结构解析。 |
| 通用视觉数据 | 20% | 基于 DeepSeek-VL2 生成,含图像描述、目标检测、视觉定位等任务数据,不追求通用 VLM 能力,仅用于保留视觉接口,方便后续扩展研究。 |
| 纯文本数据 | 10% | 内部预处理的纯文本,统一截断为 8192 tokens(与模型序列长度一致),用于保障模型的语言生成能力。 |
数据处理的关键设计:
- 多语言支持:通过 “模型飞轮” 解决小语种标注稀缺 —— 用 fitz 切分小语种 PDF 为 patch,训练 GOT-OCR2.0 标注,最终生成 600K 小语种样本;
- 标注区分:训练时用不同 prompt 区分 “粗标注”(如\nFree OCR)和 “细标注”(含布局坐标),让模型适配不同精度需求。
2.3.2 两阶段训练流程
DeepSeek-OCR 采用 “先训编码器,再训端到端” 的两阶段流程,核心逻辑是:先确保 DeepEncoder 的视觉压缩能力,再结合解码器优化 “压缩→生成” 的端到端效果。
阶段 1:独立训练 DeepEncoder(核心编码器预训练)
DeepEncoder 是模型压缩能力的关键,需先独立训练以保障 “高分辨率处理 + 低激活内存 + 少视觉 tokens” 的核心特性。
- 训练目标:让 DeepEncoder 学会将高分辨率图像转化为紧凑的视觉 tokens,同时保留文本语义信息(为后续 OCR 解码做准备)。
- 训练框架:采用 “next token prediction”(类似 LLM 的自回归预训练),用紧凑语言模型衔接 DeepEncoder 的输出,模拟 “视觉 tokens→文本” 的映射预训练。
- 训练数据:所有 OCR 1.0+2.0 数据(约 58M 样本)+ 100M LAION 通用图像数据(补充视觉泛化能力)。
阶段 2:端到端训练 DeepSeek-OCR(编码器 + 解码器联合优化)
在 DeepEncoder 预训练完成后,接入 DeepSeek3B-MoE 解码器,进行端到端训练,优化 “视觉 tokens→文本生成” 的全流程。
-
训练平台与并行策略:
- 平台:HAI-LLM(高效大模型训练工具);
- 并行方式:流水线并行(PP)+ 数据并行(DP):
- 流水线并行(PP):将模型拆分为 4 段,DeepEncoder 占 2 段(PP0:SAM + 压缩器,参数冻结;PP1:CLIP,参数解冻),解码器占 2 段(PP2/PP3:DeepSeek3B-MoE 的 12 层各分 6 层);
- 数据并行(DP):20 个节点(每节点 8×A100-40G),DP=40,全局 batch size=640(平衡效率与梯度稳定性)。
-
训练数据:3.4 节提到的全量数据(OCR 70%+ 通用视觉 20%+ 纯文本 10%),按比例混合输入。
3. 实验结果与性能分析
3.1 压缩比与精度关系
DeepSeek-OCR 在 Fox 基准测试上的表现令人印象深刻:
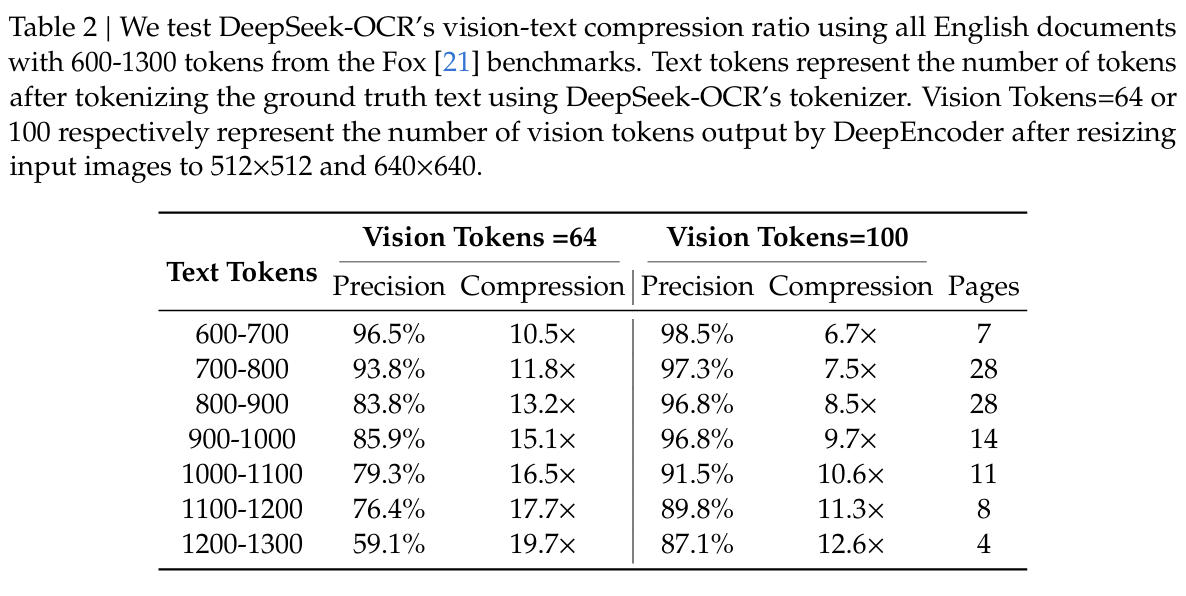
关键发现:
- 在 10 倍压缩比内,模型解码精度可达 97% 左右
- 即使压缩比达到 20 倍,OCR 准确率仍保持在约 60%
- 这表明通过文本到图像的方法可能实现近 10 倍的无损上下文压缩
3.2 实际应用性能
在 OmniDocBench 基准测试中,DeepSeek-OCR 展现出了强大的实用价值:
- 仅用 100 个视觉 tokens:超越了使用 256 个 tokens 的 GOT-OCR2.0
- 用 400 个视觉 tokens:与当前最先进的模型性能相当
- 少于 800 个 tokens:超越了需要近 7000 个视觉 tokens 的 MinerU2.0
这种高效率使得 DeepSeek-OCR 在实际应用中具有显著优势。
3.3 不同文档类型的表现
DeepSeek-OCR 对不同类型文档的处理能力各异:
- 幻灯片:仅需 64 个视觉 tokens 就能达到满意性能
- 书籍和报告:100 个视觉 tokens 即可实现良好效果
- 学术论文和杂志:需要更多 tokens 支持,但整体表现优秀
4. 实际应用价值
4.1 大规模数据生成
DeepSeek-OCR 不仅是一个研究模型,更具有强大的实用价值:
- 生产效率:单 A100-40G GPU 每天可生成 20 万 + 页面的训练数据
- 大规模部署:20 个节点(每节点 8 个 A100-40G)每天可生成 3300 万页面数据
- 多语言支持:支持近 100 种语言的 OCR 能力
- 多模态处理:能够解析图表、化学公式、几何图形和自然图像
4.2 为 LLM/VLM 提供训练数据
DeepSeek-OCR 可以为大语言模型和视觉 - 语言模型的预训练提供高质量的训练数据,这对于模型的持续改进至关重要。
4.3 创新的记忆遗忘机制
DeepSeek-OCR 的一个引人注目的应用是模拟人类的记忆遗忘机制:
- 渐进式压缩:通过逐步缩小渲染图像来进一步减少 token 消耗
- 生物学启发:模拟人类记忆随时间衰减的自然模式
- 多级别压缩:最近的信息保持高保真度,而遥远的记忆通过增加压缩比自然淡化
这种机制为实现理论上无限的上下文架构提供了新的思路。
4.4 未来发展方向
DeepSeek-OCR 代表了视觉 - 文本压缩研究的初步探索,未来还有许多值得深入研究的方向:
- 数字 - 光学文本交错预训练:进一步验证真正的上下文光学压缩
- Needle-in-a-haystack 测试:评估模型在超长上下文中的检索能力
- 多轮对话应用:实现对话历史的光学处理,达到 10 倍压缩效率
- 模型优化:进一步提高压缩比和识别精度
- 应用扩展:探索在更多场景中的应用可能性
5. 总结
DeepSeek-OCR 的提出为解决大语言模型的长上下文处理问题提供了一个全新的视角。通过将文本信息压缩到视觉表示中,它不仅实现了高达 10 倍的无损压缩,还为模拟人类记忆机制提供了技术基础。
这项工作的意义在于:
- 为 VLMs 和 LLMs 的发展开辟了新的研究方向
- 提供了一个高性能、高效率的 OCR 工具
- 为大规模预训练数据生成提供了实用解决方案
- 启发了更多关于视觉 - 文本交互的创新应用
随着研究的深入,我们有理由相信视觉 - 文本压缩技术将在未来的 AI 系统中发挥越来越重要的作用,为构建更高效、更智能的语言模型提供强有力的支持。