构建有记忆的 AI Agent:SQLite 存储 + 向量检索完整方案示例
现在的 Agent 系统有个很明显的问题 —— 会话一结束,什么都忘了。
这不是个技术缺陷,但是却限制了整个系统的能力边界。Agent 可以做推理、规划、执行复杂任务,但就是记不住之前发生过什么。每次对话都像是第一次见面,这种状态下很难说它真正"理解"了什么。
记忆能力是把 LLM 从简单的问答工具变成真正协作伙伴的关键。一个只能"回答当前问题",另一个能"基于历史经验做决策",这就是增加了记忆能力后的改进。
这篇文章会讲怎么给 Agent 加上记忆、反思和目标跟踪能力。技术栈很简单:
- SQLite 做结构化存储
- 向量数据库(Pinecone、FAISS、Chroma 都行)处理语义检索
- LLM 层负责反思和总结
这套架构可以直接集成到现有框架里,不管你用 LangChain、CrewAI 还是自己写的框架。
记忆为什么这么重要
Agent 的自主性需要记忆支撑,先说跨会话连续性,一个数据质量监控 Agent 如果能记住哪些数据集经常出问题,就能提前预警而不是每次都从头排查。
而且通过记忆还可以增加反思的能力,Agent 可以自己评估"这次任务完成得怎么样"、“推理过程有没有问题”,这种自我评估不需要复杂的奖励函数,用自然语言就能实现强化学习的效果。
长期目标跟踪也是一个很大的需求,数据整理、研究辅助这类工作往往跨越多次交互,需要 Agent 记住目标、追踪进度、理解任务之间的依赖关系。
没有记忆的 Agent 永远困在当下,无法积累经验也无法改进。
系统架构
整体设计分两个记忆层面:情景记忆记录发生的事情,语义记忆提炼学到的经验。
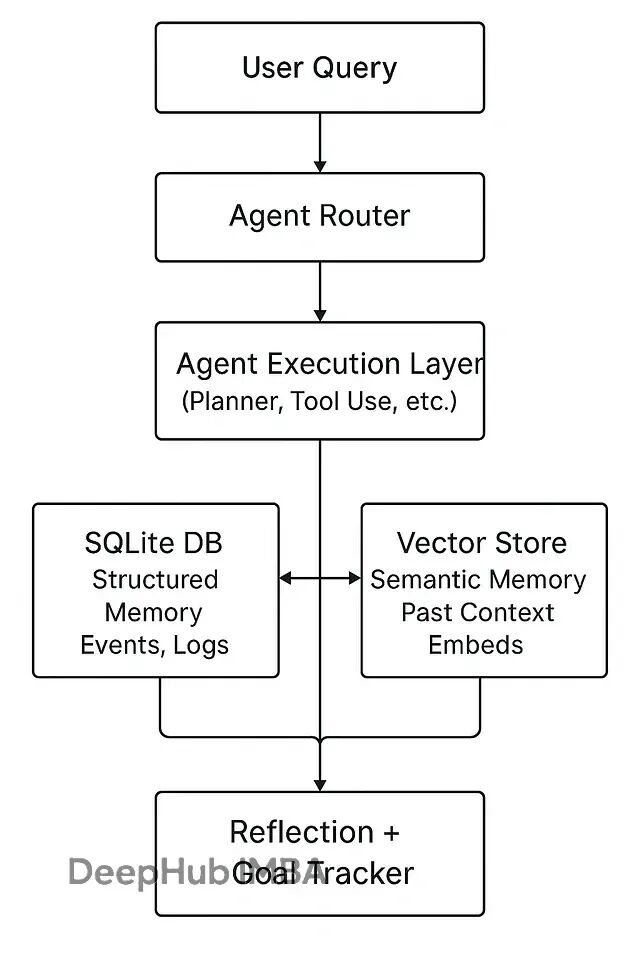
这个架构的核心是让 Agent 既能查询"我之前做过什么",也能理解"类似的情况该怎么处理"。
数据库设计
为了演示,我们使用SQLite ,因为它轻量、本地化、跨平台支持好。对于大多数场景够用了,除非你的 Agent 需要处理海量并发。
数据库如下:
CREATE TABLE IF NOT EXISTS memory_events ( id INTEGER PRIMARY KEY AUTOINCREMENT, agent_name TEXT, timestamp DATETIME DEFAULT CURRENT_TIMESTAMP, input TEXT, output TEXT, summary TEXT, embedding BLOB
); CREATE TABLE IF NOT EXISTS goals ( id INTEGER PRIMARY KEY AUTOINCREMENT, agent_name TEXT, goal TEXT, status TEXT DEFAULT 'in_progress', last_updated DATETIME DEFAULT CURRENT_TIMESTAMP );
memory_events 表存交互历史和摘要,goals 表追踪目标状态。每个任务执行完就自动记录,这些数据后面会用来做反思分析。
记录情景记忆
每次任务执行完,把关键信息存下来:
def log_memory_event(agent_name, input_text, output_text, summary, embedding): conn = sqlite3.connect("memory.db") cur = conn.cursor() cur.execute(""" INSERT INTO memory_events (agent_name, input, output, summary, embedding) VALUES (?, ?, ?, ?, ?) """, (agent_name, input_text, output_text, summary, embedding)) conn.commit() conn.close()
summary 可以让 LLM 生成:
summary_prompt = f"Summarize this agent interaction:\n\nInput: {input_text}\nOutput: {output_text}\n" summary = llm.complete(summary_prompt)
然后把摘要转成向量存起来:
embedding = embedding_model.embed(summary)
这样做的好处是,检索时不依赖关键词匹配,而是基于语义相似度。Agent 记住的不是原始文本,是事情的"意思"。
语义检索实现
新查询来的时候,先找出相关的历史记忆:
def recall_related_memories(query, top_k=3): query_embedding = embedding_model.embed(query) results = pinecone_index.query(vector=query_embedding, top_k=top_k) return [r['metadata']['summary'] for r in results]
检索出来的摘要直接注入到 prompt 里:
“以下是一些相关的历史经验,处理当前问题时可以参考……”
这个过程模拟了人类决策前回忆类似经历的思维方式。向量检索能找到语义上相关但表述完全不同的内容,比传统的全文搜索要智能得多。
反思机制
有了记忆以后,还可以让 Agent 学会从记忆中学习。反思循环把被动的存储变成主动的能力提升。每隔几次交互触发一次:
reflection_prompt = f"""
You are reviewing your recent actions. Based on the following summaries, what patterns,
mistakes, or improvements do you notice? {recent_summaries} Provide 3 takeaways and 1 improvement plan for your future tasks.
""" reflection = llm.complete(reflection_prompt)
可以把这个反思结果作为元记忆存起来,也可以生成 embedding 用于后续检索。
更进一步还可以加自我批评机制。每个主要任务完成后,Agent 评估是否达成目标。没达成就写个修正笔记,下次遇到类似情况知道该怎么改进。
这种方式实现了推理层面的强化学习,不需要梯度更新,纯靠自然语言就能调整行为模式。
目标管理
Agent 需要目标感。可以动态定义、更新、评估目标:
def update_goal(agent_name, goal, status): conn = sqlite3.connect("memory.db") cur = conn.cursor() cur.execute(""" UPDATE goals SET status = ?, last_updated = CURRENT_TIMESTAMP WHERE agent_name = ? AND goal = ? """, (status, agent_name, goal)) conn.commit() conn.close()
可以专门跑一个目标跟踪 Agent,定期检查未完成的目标然后提醒相关 Agent:
“目标:提升数据时效性当前进度:70%建议行动:检查上周的数据延迟情况”
这样整个系统就有了持续性。Agent 不再是处理单次请求的工具,而是在追求长期目标的过程中持续运作。
完整流程
把这些组件串起来流程就是这样的:
1、用户请求进来,Agent 执行任务,同时把交互记录写入 SQLite 和向量库。
2、处理新请求之前,先做语义检索调出相关记忆,把这些信息加到上下文里。
3、每隔 N 次交互,Agent 总结最近的行为表现,写反思笔记存档。
4、目标独立于单次会话存在,可以跨越多天甚至多周追踪进度。
5、这样构建出来的 Agent 更接近一个能学习、能记忆、能进化的系统。
一些实践经验
存摘要比存完整对话有效得多,既节省空间又便于检索。
定期清理数据很重要。比如说设置个定时任务,合并相似的记忆或者删掉不再有用的旧记录。
语义压缩是个好技巧 —— 把多个相关事件总结成一条元记忆,减少信息冗余的同时保留关键模式。
提示词设计也要引导元认知。给 Agent 一个明确角色比如"反思分析师",会让自我评估的质量明显提升。
如果想直观看到效果,可以搭个 Streamlit 或 React 界面,实时展示记忆聚类、目标进度、反思内容这些信息。可视化对调试和优化很有帮助。
最后
加上记忆、反思、目标追踪,Agent 就从一次性的工具变成了学习型伙伴。他们的区别在于一个只会执行任务,另一个能理解意图的演变并主动适应。
Agent AI 这个方向发展下去,记忆系统会成为基础设施。数字助手需要记住昨天发生的事,反思今天的表现,规划明天的行动。
最简单的记忆功能实现起来并不复杂,SQLite 加个向量库,写几个精心设计的 prompt,就能让 Agent 开始进化了。
https://avoid.overfit.cn/post/44c8d547475340d59aa4480f634ea67f
作者:Kyle knudson