测试题-4

常用的黑盒测试方法有:等价类划分法;边界值分析法;因果图法;场景法;正交实验设计法;判定表驱动分析法;错误推测法;功能图分析法。
白盒测试的测试方法有代码检查法、静态结构分析法、静态质量度量法、逻辑覆盖法、基本路径测试法、域测试、符号测试、路径覆盖和程序变异。 白盒测试法的覆盖标准有逻辑覆盖、循环覆盖和基本路径测试。其中逻辑覆盖包括语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖和修改条件判断覆盖。

1)非渐增组装测试(非增式集成测试):将单元测试后的模块按照总体的结构图一次性集成起来,然后把连接的整体进行程序测试。 一般用黑盒法来编写测试集并进行测试。 程序错误易出现,不容易集成成果。单元测试使用的辅助模块多,适合于规模小的开发系统。 2)渐增组装测试(增式集成测试):在单元测试的基础上,采用自顶向下或自底向上逐层安装测试,直到最后安装测试完毕。 也可采用自顶向下与自底向上相结合集成测试,单元测试与集成测试相结合来进行集成测试。 将错误分解,容易找到错误并测试成功,适合于大规模的开发系统。
竞争条件测试专门针对并发系统中操作的时序依赖问题,而其他选项不直接相关:等价类划分测试关注输入域分类(A),状态转换测试针对系统状态变迁(B),故障注入测试涉及人为引入故障以评估系统鲁棒性(C)。
测试类型 | 类比 | 核心目标 |
|---|---|---|
竞争条件测试 | 多人抢同一张票 | 发现并发操作导致的隐藏bug |
等价类划分 | 按身高分组测过山车 | 用最少测试覆盖所有输入类型 |
状态转换测试 | 检查摩天轮状态流程图 | 确保状态切换逻辑正确 |
故障注入测试 | 故意拔电源看应急措施 | 评估系统容错能力 |

数值检测属于功能测试的范围,主要用于验证程序计算结果的正确性,而不是测试系统性能。
def can_access(has_permission, is_adult):if has_permission and is_adult: # 这是一个判定,包含两个条件return True # 分支1else:return False # 分支21. 判定覆盖(D. 判定覆盖)
目标: 让 if判定的两种结果(True和 False)都至少执行一次。
•判定结果1(True):执行 return True
•判定结果2(False):执行 return False
测试用例设计:
•用例1: has_permission=True, is_adult=True-> 判定结果为 True(覆盖了分支1)
•用例2: has_permission=False, is_adult=False-> 判定结果为 False(覆盖了分支2)
分析: 我们用两个测试用例就让判定的真和假都执行了。达标!
但是,我们只测试了 (True, True)和 (False, False)这两种情况。如果代码误写成了 if has_permission or is_adult(把 and错写成 or),我们的测试用例能发现吗?发现不了!因为 (False, True)这种情况没测到,而这种情况下 and和 or的结果是不同的。
2. 条件覆盖(A. 条件覆盖)
目标: 让每个条件(has_permission和 is_admission)的真假值都至少出现一次。不关心判定的结果。
•条件1 (has_permission):需要出现 True和 False
•条件2 (is_adult):需要出现 True和 False
测试用例设计:
•用例1: has_permission=True, is_adult=False(条件1为真,条件2为假)
•用例2: has_permission=False, is_adult=True(条件1为假,条件2为真)
分析: 两个条件的真和假都出现了。达标!
但是,你看这两个用例的判定结果都是 False!我们根本没有测试到 return True这个重要的分支。所以条件覆盖虽然细致,但可能漏掉重要的判定路径。
3. 判定/条件覆盖(B. 判定/条件覆盖 - 图中选中项)
目标: 同时满足判定覆盖和条件覆盖。即:判定的真假都要出现,并且每个条件的真假也要出现。
这听起来很完美,但通常实现它只需要满足一个更强的标准(如下面的组合覆盖)就能自然满足。不过我们试着独立设计:
测试用例设计(一种方案):
•用例1: has_permission=True, is_adult=True-> 判定为 True(覆盖了条件1真,条件2真)
•用例2: has_permission=False, is_adult=False-> 判定为 False(覆盖了条件1假,条件2假)
分析:
•判定覆盖:True和 False都出现了。✔️
•条件覆盖:has_permission的 True/False和 is_adult的 True/False都出现了。✔️
看起来不错,但它和单纯的判定覆盖的例子一样,仍然没有测试 (True, False)和 (False, True)这两种组合,所以依然发现不了 and误写成 or的错误。
4. 组合覆盖(C. 组合覆盖)
目标: 让所有条件的所有可能取值组合都至少出现一次。这是最强的覆盖标准。
两个条件,每个有2种取值,一共有 2 x 2 = 4种组合。
测试用例设计:
•用例1: has_permission=True, is_adult=True-> 判定为 True
•用例2: has_permission=True, is_adult=False-> 判定为 False
•用例3: has_permission=False, is_adult=True-> 判定为 False
•用例4: has_permission=False, is_adult=False-> 判定为 False
分析: 我们穷举了所有4种输入组合。100%达标!
现在,如果代码有任何一个与条件逻辑相关的bug(比如 and错写成 or),在测试中一定会暴露出来。因为 (True, False)在 and下是 False,在 or下是 True,结果不同,测试会失败。

构建确认是基础,测试用例设计指导测试执行,问题报告推动修复改进,而规范的提交过程则确保整个测试活动可控可追溯。因此这些过程共同构成了完整的集成测试体系。

根据测试金字塔模型理论,该情况最可能的原因是测试策略过度依赖端到端(E2E)测试。测试金字塔模型强调应以底层单元测试为基础(数量多、运行快、稳定性高),中层的集成测试为辅,顶层的E2E测试最少(运行慢、易受外部因素如UI变动或网络波动影响)。
测试类型 | 测试范围 | 示例 |
|---|---|---|
单元测试 | 单个函数/方法 |
|
集成测试 | 模块间交互 | API调用数据库 |
端到端测试 | 完整用户流程 | 用户登录→购物→支付 |
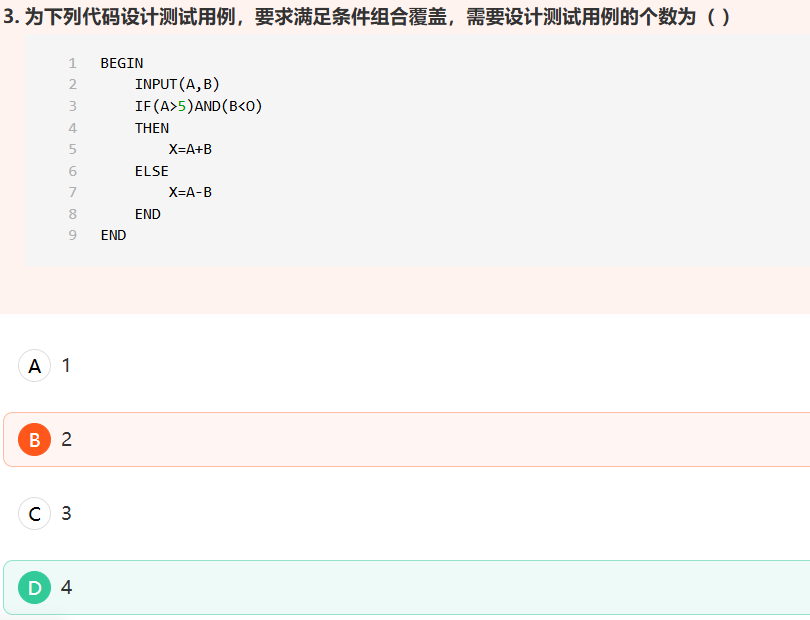
条件组合覆盖:在白盒测试法中,选择足够的测试用例,使得每个判定中条件的各种可能组合都至少出现一次。AB都符合,A符合B不符合,A不符合B符合,AB都不符合。

测试用例的有效性主要通过其发现缺陷的能力来体现。选项C'测试用例发现的缺陷数占该功能模块总缺陷数的比例'直接反映了这一能力,比例越高说明测试用例越有效

1. 正式验收测试(A):
- 由用户在软件实际运行环境下进行的最终测试
- 目的是验证软件是否满足合同规定的要求
- 是正式交付前的最后一道关
2. Alpha测试(C):
- 在开发环境下由用户参与进行的测试
- 开发人员在现场记录用户在使用过程中遇到的问题
- 主要发现软件在实际应用中可能存在的问题
3. Beta测试(D):
- 在用户环境下进行的测试
- 由软件的目标用户执行测试
- 开发者通常不在测试现场
- 用户直接向开发者报告发现的问题

系统测试是基于系统整体需求说明书的黑盒类测试,应覆盖系统所有联合的部件。
系统测试就是把开发完成的软件(比如一个手机App)当作一个完整的、黑箱的产品。
测试人员不关心内部代码怎么写,只关心它作为一个整体,在真实环境下能不能完成用户想要做的事情。

因果图是通过分析输入条件(原因)和输出结果(结果)之间的依赖关系来设计测试用例的方法,最适合根据输出对输入的依赖关系设计测试用例。因果图能够清晰地展示输入条件之间的组合关系以及它们对输出结果的影响。

用户验收测试(UAT)的核心目标是确保系统满足最终用户的业务需求,以便系统被正式接受。


度量标准 | 定义 | 关注点 | 覆盖强度 |
|---|---|---|---|
语句覆盖率 | 测试用例是否执行了代码中的每一条可执行语句。 | “行” 是否被执行过。 | 最弱 |
分支覆盖率 | 测试用例是否覆盖了每个判断条件的所有可能结果(True 和 False)。 | “岔路” 是否都走过了。 | 中等 |
路径覆盖率 | 测试用例是否覆盖了程序中所有可能的执行路径。 | “路线组合” 是否都走遍了。 | 最强 |
覆盖率类型 | 比喻 | 目标 |
|---|---|---|
语句覆盖率 | 你是否到达过每一个地点? | 确保所有“地点”都去过一次。 |
分支覆盖率 | 你在每个岔路口是否既向左转过,也向右转过? | 确保每个“岔路口”的所有方向都尝试过。 |
路径覆盖率 | 你是否走完了所有可能的路线组合? | 确保所有可能的“旅行路线”都体验过。 |

浸泡测试(Soak/Endurance Testing)专门用于在长时间(如72小时)持续运行预期正常负载下,评估系统的稳定性和资源使用情况(如内存泄漏或资源耗尽),这直接符合题目要求。而其他选项:压力测试(A)关注超负载下的行为;容量测试(B)关注系统最大处理能力;负载测试(C)通常针对短期正常负载下的性能指标(如响应时间),不强调长时间稳定性。

在软件测试领域,健全性测试(Sanity Testing)专指针对特定更改或修复进行的快速、窄范围测试,以确认其基本功能正常,确保版本稳定到可进一步测试。选项分析:A.冒烟测试(Smoke Testing)用于验证构建的基本功能,通常覆盖主要功能而非特定修复;B.回归测试(Regression Testing)涉及更全面的错误检查,不强调'快速';C.健全性测试与题目要求完全匹配,尤其是'心智健全'一词直接对应;D.随机测试(Ad-hoc Testing)是非结构化测试,不系统。

系统集成测试主要包括以下过程:
1. 构建的确认过程。
2. 补丁的确认过程。
3. 系统集成测试测试组提交过程。
4. 测试用例设计过程。
5. 测试代码编写过程。
6. Bug的报告过程。
7. 每周/每两周的构建过程。
8. 点对点的测试过程。
9. 组内培训过程


在持续集成流水线中,自动化端到端测试应优先用于验证核心业务功能,以确保整体系统流程的正确性和可靠性。选项B(核心交易链路的价格计算规则引擎)直接涉及关键业务逻辑,价格计算的错误可能导致财务损失、客户投诉或业务中断,而端到端测试能模拟用户交易完整路径(从前端输入到后端计算),提供高业务价值。
什么是端到端测试(End-to-End Testing, E2E)?
定义:模拟真实用户的操作流程,从开始到结束完整测试整个系统,验证所有组件是否能协同工作。
“端到端” = 从用户输入(如点击按钮)到最终结果(如生成订单)的全过程。

压力测试是专门用来评估系统在资源耗尽或极限负载情况下的表现的测试方法。它通过模拟极端条件(如内存不足、磁盘空间耗尽、网络带宽受限等)来测试系统的稳定性和容错能力。
其他选项:
A. 强度测试 - 主要测试系统在正常负载条件下长期运行的可靠性,不是专门针对资源耗尽情况
B. 容量测试 - 关注系统能够处理的最大数据量或并发用户数,但不是刻意制造资源耗尽的场景
C. 性能测试 - 测试系统在正常工作负载下的响应时间、吞吐量等指标,不涉及资源耗尽情况的测试

项目经理(A):作为项目的总负责人,需要确保测试计划与项目整体目标一致,并对测试资源分配、进度安排等做出决策。
SQA负责人(B):质量保证负责人需要从质量管理的角度评估测试计划是否完整、合理,能否有效保证软件质量。
配置负责人(C):负责确保测试环境配置、测试数据管理等计划符合配置管理规范,保证测试活动的有序进行。
测试组(D):作为测试计划的执行者,测试人员需要评估计划的可操作性,并提供实际测试经验的反馈。
这些角色的共同参与可以从不同维度对测试计划进行评审:
- 管理层面(项目经理)
- 质量保证层面(SQA负责人)
- 技术支持层面(配置负责人)
- 执行层面(测试组)
单元测试是软件测试中最基本也是最重要的环节之一,主要包含三种核心技术手段:驱动代码(Driver)、桩代码(Stub)和模拟对象(Mock)。
驱动代码(A正确):
驱动代码用于调用和测试目标代码单元,它模拟上层模块的行为,向被测试模块传入测试数据并验证其输出结果。驱动代码是单元测试中不可或缺的组成部分。
桩代码(B正确):
桩代码用于模拟被测试代码单元所依赖的其他模块,它替代了实际的依赖模块,返回预设的数据。这使得测试可以独立进行,不受其他模块的影响。
模拟对象(C正确):
Mock是一种更高级的桩代码实现方式,它不仅可以模拟依赖对象的行为,还能验证被测试代码是否正确调用了依赖对象的方法。Mock在单元测试中被广泛使用。
D选项错误原因:
GUI测试手段主要用于用户界面测试,属于系统测试或验收测试的范畴,不是单元测试的主要技术手段。单元测试主要关注代码逻辑的正确性,通常不涉及图形界面测试。
- 驱动代码:测试的“组织者”,负责“调用被测对象+验证结果”;
- Stub:依赖的“简化版替代品”,只返回固定值,不关心逻辑和交互;
- Mock:依赖的“智能模拟器”,可模拟逻辑、校验交互(如“是否按预期调用”),功能比Stub更强大。