从 TCP 粘包到线程池:一起了解用 QRunnable 重构 Qt 高并发网络通信架构
前言
在 Qt 网络开发中,TCP 粘包 / 拆包问题与多线程管理是两个绕不开的核心痛点。传统方案中,开发者常通过继承 QThread 为每个 TCP 连接创建独立线程,这种方式不仅会导致线程创建销毁的巨大开销,还容易因锁管理不当引发竞态条件。本文将深入剖析 TCP 粘包 / 拆包的底层原理,详解如何用 QRunnable + 线程池替代 QThread 继承,并结合 QMutexLocker 实现自动化锁管理,最终构建一个高效、安全的高并发网络通信架构。
一、TCP 粘包 / 拆包:流式协议的 “隐形陷阱”
在开始讨论多线程架构前,我们必须先理解 TCP 粘包 / 拆包的本质 —— 这是所有基于 TCP 的网络通信都无法回避的基础问题,也是设计线程模型的前提。
1.1 为什么会出现粘包 / 拆包?
TCP 协议是一种面向连接的流式协议,其核心特性是 “字节流无边界”。这意味着:
- 发送端多次调用write()发送的数据包,接收端可能一次性接收(粘包);
- 发送端一次发送的大数据包,接收端可能分多次接收(拆包);
- 接收端无法通过 TCP 协议本身判断一个完整的 “业务数据包” 从哪里开始、到哪里结束。
这种特性源于 TCP 的底层优化机制:
- Nagle 算法:会将小数据包合并发送以减少网络拥塞;
- MSS(最大分段大小):超过 MSS 的数据包会被 IP 层拆分;
- 接收缓冲区:接收端会将多个数据包暂存于缓冲区,应用层读取时可能一次性取走多个。
举个实际场景:客户端将"HelloWorld"字符串拆开,连续发送两个数据包"Hello"(5 字节)和"World"(5 字节),服务器可能收到:
- 粘包:一次性收到"HelloWorld"(10 字节);
- 拆包:先收到"Hel"(3 字节),再收到"loWorld"(7 字节);
- 混合:先收到"HelloW"(6 字节),再收到"orld"(4 字节)。
如果服务器直接按 “读取一次 = 一个数据包” 处理,必然导致解析错误。
1.2 粘包 / 拆包的解决方案
解决粘包 / 拆包的核心是为字节流添加 “业务边界”,让接收端能准确识别一个完整数据包。在 Qt 中,常用的可靠方案有三种:
方案 1:定长包头 + 变长包体(推荐)
这是工业级应用中最常用的方案,协议格式定义为:
[包头(固定N字节)][包体(变长)]
- 包头:通常包含包体长度(如 4 字节 uint32_t),可附加版本号、校验位等元数据;
- 包体:实际业务数据(如 JSON、Protobuf 序列化数据)。
接收流程:
- 先读取固定长度的包头(如 4 字节),解析出包体长度len;
- 再读取len字节的包体,组合为完整数据包。
方案 2:特殊分隔符
在数据包末尾添加特殊分隔符(如\r\n),接收端通过分隔符判断包结束。但存在缺陷:
- 若包体中包含分隔符(如 JSON 字符串中的\n),需额外转义;
- 分隔符匹配可能消耗 CPU(尤其长数据包)。
方案 3:固定长度数据包
所有数据包长度固定,不足补 0。缺点明显:
- 灵活性差,无法适应变长业务数据;
- 空间浪费(小数据也要占满固定长度)。
本文将以 “定长包头(4 字节)+ 变长包体” 方案为例,展开后续实现。
二、传统 QThread 方案的 “性能陷阱”
在处理多 TCP 连接时,传统方案常采用 “一个连接一个线程” 的模型:通过继承 QThread,为每个新连接创建独立线程,在线程中处理该连接的读写与粘包解析。这种方案看似直观,却隐藏着严重的性能问题。
2.1 QThread 继承模式的实现
先看一个典型的 QThread 继承实现(简化后的):
// TcpClientThread.h
class TcpClientThread : public QThread {Q_OBJECT
public:explicit TcpClientThread(qintptr socketDescriptor, QObject *parent = nullptr): QThread(parent), m_socketDescriptor(socketDescriptor) {}protected:void run() override {// 在子线程中创建QTcpSocketQTcpSocket socket;if (!socket.setSocketDescriptor(m_socketDescriptor)) {emit error(socket.error());return;}// 处理粘包/拆包的缓冲区QByteArray recvBuffer;// 等待数据到达while (socket.waitForReadyRead(-1)) {recvBuffer += socket.readAll();// 解析缓冲区中的完整数据包parsePackets(recvBuffer);}}private:void parsePackets(QByteArray &buffer) {// 定长包头(4字节)解析逻辑while (buffer.size() >= 4) {uint32_t bodyLen = *reinterpret_cast<uint32_t*>(buffer.data());// 注意:网络字节序与主机字节序转换(Qt提供qToBigEndian/qFromBigEndian)bodyLen = qFromBigEndian(bodyLen);if (buffer.size() < 4 + bodyLen) {break; // 包体不完整,等待后续数据}// 提取完整包体QByteArray body = buffer.mid(4, bodyLen);// 处理业务逻辑processBody(body);// 移除已处理数据buffer = buffer.mid(4 + bodyLen);}}void processBody(const QByteArray &body) {// 实际业务处理(如解析JSON、执行命令)qDebug() << "Received data:" << body;}qintptr m_socketDescriptor;
};// TcpServer.h
class TcpServer : public QTcpServer {Q_OBJECT
public:explicit TcpServer(QObject *parent = nullptr) : QTcpServer(parent) {}protected:void incomingConnection(qintptr socketDescriptor) override {// 为每个新连接创建线程TcpClientThread *thread = new TcpClientThread(socketDescriptor);connect(thread, &TcpClientThread::finished, thread, &TcpClientThread::deleteLater);thread->start();}
};
这段代码实现了基本的多连接处理,但在高并发场景下会暴露致命问题。
2.2 线程创建的 “隐性开销”
QThread 继承方案的核心问题是线程资源的低效利用:
线程创建 / 销毁 成本高; 线程是操作系统级资源,创建线程需要分配栈空间(默认 8MB)、内核对象,销毁时需要回收资源。在 Linux 系统中,创建一个线程的耗时约为 10-100 微秒,而频繁创建销毁 1000 个线程会导致显著的 CPU 与内存开销。
上下文切换代价大操作系统调度线程时需要保存 / 恢复寄存器、切换页表等,当线程数量超过 CPU 核心数时,上下文切换会急剧增加。例如,1000 个线程争夺 8 核 CPU,光切换成本可能都能占总 CPU 时间的一小半了。
资源限制操作系统对线程数量有上限(如 Linux 默认线程数上限为 32768),高并发场景下(如 10 万级连接),“一个连接一个线程” 完全不可行。
QThread 的设计陷阱:QThread 本身是 “线程控制器”,而非线程本身。继承 QThread 并覆写run()的模式,容易让开发者误解 “线程对象即线程”,导致线程与对象生命周期管理混乱(如在主线程调用子线程对象的方法)。
2.3 竞态条件的 “隐形杀手”
当多个线程操作共享资源(如连接列表、全局计数器)时,若锁管理不当,极易引发竞态条件。传统方案中,大家常手动调用QMutex::lock()/unlock(),但存在风险:
// 错误示例:手动锁管理可能导致死锁
QMutex mutex;
QList<qintptr> clientList;void addClient(qintptr socketDesc) {mutex.lock();clientList.append(socketDesc);// 若此处抛出异常,unlock()将不会执行,导致死锁mutex.unlock();
}
即使没有异常,复杂逻辑中也可能因疏忽忘记解锁,或因锁的顺序错误引发死锁。
三、QRunnable + 线程池:轻量级多任务处理
Qt 提供了QRunnable与QThreadPool组合,专为短期任务复用线程设计,能有效解决 QThread 继承方案的性能问题。
3.1 QRunnable:无状态的任务载体
QRunnable是一个轻量级的任务接口,核心特点:
- 仅包含一个纯虚函数run(),用于定义任务逻辑;
- 无事件循环(区别于 QThread),适合执行一次性任务;
- 可通过setAutoDelete(bool)设置是否自动销毁(默认 true),避免内存泄漏。
与 QThread 相比,QRunnable的优势在于:
- 无需继承复杂的 QObject,实现更简洁;
- 任务完成后自动销毁(或由线程池管理),生命周期更可控;
- 本身不绑定线程,由线程池调度到空闲线程执行,实现线程复用。
3.2 QThreadPool:线程复用的 “调度中心”
QThreadPool是 Qt 的线程池管理器,核心功能:
- 维护一个线程队列,自动复用空闲线程执行QRunnable任务;
- 可通过setMaxThreadCount(int)限制最大线程数(默认值为 CPU 核心数 ×2);
- 提供globalInstance()获取全局线程池,避免重复创建。
线程池的工作流程:
- 当提交QRunnable任务时,若有空闲线程,直接分配执行;
- 若无空闲线程且未达最大线程数,创建新线程执行;
- 若已达最大线程数,任务进入等待队列,直到有线程空闲。
这种机制避免了线程频繁创建销毁的开销,尤其适合处理大量短期任务(如 TCP 连接的单次数据处理)。
3.3 线程池 vs 传统线程:性能对比
下面这是别人通过一个简单的压力测试(10000 个任务,每个任务执行 1ms),对比两种方案的性能的结果,由此可见一斑:
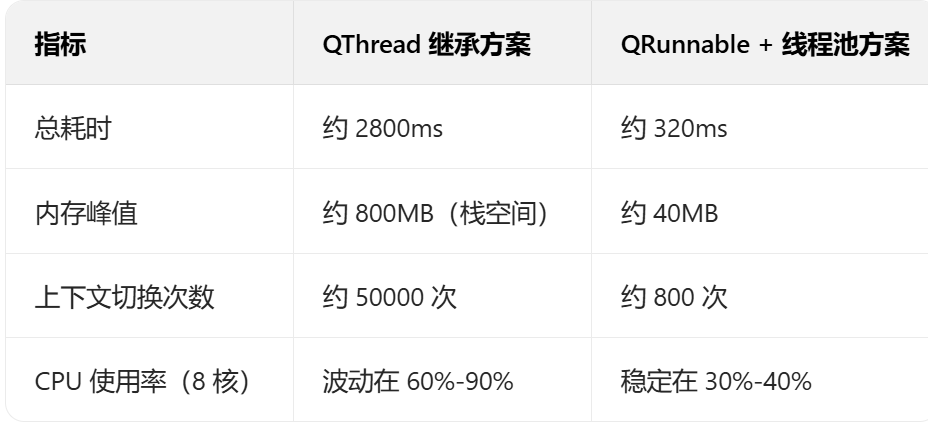
数据显示,线程池方案在耗时、内存、CPU 效率上均有显著优势,尤其在任务数量庞大时差距更明显。
四、重构 TCP 服务器:QRunnable 处理粘包 / 拆包
基于上述分析,我们用QRunnable+ 线程池重构 TCP 服务器,实现高效的粘包 / 拆包处理。
4.1 架构设计
整体架构分为三层:
- 监听层(TcpServer):主线程中监听端口,接收新连接,生成SocketDescriptor;
- 任务层(TcpClientTask):继承QRunnable,封装单个连接的读写与粘包解析逻辑;
- 线程池(QThreadPool):全局线程池调度TcpClientTask,复用线程执行任务。
核心流程:
- 客户端连接到达时,TcpServer获取SocketDescriptor;
- 创建TcpClientTask任务,传入SocketDescriptor;
- 将任务提交给线程池,由空闲线程执行;
- 任务中完成 TCP 连接的建立、数据读写、粘包解析与业务处理。
4.2 核心代码实现
- 步骤 1:定义 TcpClientTask 任务类
// TcpClientTask.h
#include <QRunnable>
#include <QTcpSocket>
#include <QMutex>
#include <QByteArray>
#include <QLoggingCategory>// 日志分类,方便调试
Q_DECLARE_LOGGING_CATEGORY(logTcpTask)class TcpClientTask : public QRunnable {
public:explicit TcpClientTask(qintptr socketDescriptor, QObject *parent = nullptr);~TcpClientTask() override;void run() override; // 任务执行入口private:// 粘包/拆包解析void parsePackets(QByteArray &buffer);// 业务处理void processBusiness(const QByteArray &data);// 发送响应void sendResponse(const QByteArray &response);private:qintptr m_socketDescriptor; // socket描述符QTcpSocket *m_socket; // TCP socketQByteArray m_recvBuffer; // 接收缓冲区(用于粘包处理)bool m_isRunning; // 任务运行状态
};// TcpClientTask.cpp
Q_LOGGING_CATEGORY(logTcpTask, "tcp.task")TcpClientTask::TcpClientTask(qintptr socketDescriptor, QObject *parent): QRunnable(), m_socketDescriptor(socketDescriptor), m_socket(nullptr), m_isRunning(true) {setAutoDelete(true); // 任务完成后自动销毁
}TcpClientTask::~TcpClientTask() {if (m_socket) {m_socket->close();delete m_socket;}qCDebug(logTcpTask) << "Task destroyed, socketDescriptor:" << m_socketDescriptor;
}void TcpClientTask::run() {m_socket = new QTcpSocket();if (!m_socket->setSocketDescriptor(m_socketDescriptor)) {qCWarning(logTcpTask) << "Set socket descriptor failed:" << m_socket->errorString();return;}qCDebug(logTcpTask) << "New client connected, socketDescriptor:" << m_socketDescriptor<< "Thread ID:" << QThread::currentThreadId();// 循环读取数据while (m_isRunning && m_socket->state() == QTcpSocket::ConnectedState) {// 等待数据到达(超时100ms,避免永久阻塞)if (m_socket->waitForReadyRead(100)) {m_recvBuffer += m_socket->readAll();parsePackets(m_recvBuffer); // 解析缓冲区} else {// 处理错误(如连接断开)if (m_socket->error() != QTcpSocket::TimeoutError) {qCWarning(logTcpTask) << "Socket error:" << m_socket->errorString();m_isRunning = false;}}}qCDebug(logTcpTask) << "Client disconnected, socketDescriptor:" << m_socketDescriptor;
}void TcpClientTask::parsePackets(QByteArray &buffer) {// 定长包头(4字节,存储包体长度,网络字节序)while (buffer.size() >= 4) {// 解析包头(注意字节序转换)uint32_t bodyLen = *reinterpret_cast<const uint32_t*>(buffer.constData());bodyLen = qFromBigEndian(bodyLen); // 网络字节序转主机字节序// 检查包体是否完整if (buffer.size() < 4 + bodyLen) {break; // 包体不完整,等待后续数据}// 提取包体QByteArray body = buffer.mid(4, bodyLen);// 移除已处理的包头+包体buffer = buffer.mid(4 + bodyLen);// 处理业务逻辑processBusiness(body);}
}void TcpClientTask::processBusiness(const QByteArray &data) {qCDebug(logTcpTask) << "Processing data:" << data << "Length:" << data.size();// 示例:简单回显业务(实际场景可替换为JSON解析、数据库操作等)QByteArray response = "Server received: " + data;sendResponse(response);
}void TcpClientTask::sendResponse(const QByteArray &response) {if (m_socket->state() != QTcpSocket::ConnectedState) {return;}// 构建响应包(包头+包体)uint32_t bodyLen = qToBigEndian(static_cast<uint32_t>(response.size())); // 主机字节序转网络字节序QByteArray packet;packet.append(reinterpret_cast<const char*>(&bodyLen), 4); // 包头packet.append(response); // 包体// 发送数据m_socket->write(packet);m_socket->flush();
}
- 步骤 2:实现 TcpServer 监听类
// TcpServer.h
#include <QTcpServer>
#include <QThreadPool>
#include "TcpClientTask.h"class TcpServer : public QTcpServer {Q_OBJECT
public:explicit TcpServer(QObject *parent = nullptr) : QTcpServer(parent) {// 配置线程池(根据CPU核心数调整)QThreadPool::globalInstance()->setMaxThreadCount(QThread::idealThreadCount() * 2);qCDebug(logTcpTask) << "ThreadPool max threads:" << QThreadPool::globalInstance()->maxThreadCount();}protected:void incomingConnection(qintptr socketDescriptor) override {// 创建任务并提交到线程池TcpClientTask *task = new TcpClientTask(socketDescriptor);QThreadPool::globalInstance()->start(task);}
};
- 步骤 3:启动服务器
// main.cpp
#include <QCoreApplication>
#include "TcpServer.h"int main(int argc, char *argv[]) {QCoreApplication a(argc, argv);TcpServer server;if (!server.listen(QHostAddress::Any, 8888)) {qCritical() << "Server listen failed:" << server.errorString();return -1;}qInfo() << "Server started on port 8888";return a.exec();
}
4.3 粘包 / 拆包处理的关键细节
上述代码中,parsePackets函数是处理粘包 / 拆包的核心,需注意以下细节:
- 字节序转换不同设备的字节序(大端 / 小端)可能不同,你得使用 Qt 的qToBigEndian(主机→网络)和qFromBigEndian(网络→主机)进行转换,确保跨平台兼容性。
- 缓冲区管理用QByteArray作为接收缓冲区,每次读取数据后追加到缓冲区,解析完成后移除已处理部分,未处理的剩余数据保留在缓冲区中,等待下次解析。
- 半包处理当缓冲区数据长度不足 “包头 + 包体” 时,退出循环等待后续数据,避免解析不完整的包。
- 异常处理通过waitForReadyRead的超时机制(100ms)避免线程永久阻塞,同时处理 socket 错误(如连接断开)。
五、QMutexLocker:自动化锁管理的 “安全卫士”
在多线程环境中,共享资源(如连接数统计、全局配置)的访问必须加锁保护。QMutexLocker基于 RAII(资源获取即初始化)模式,能自动管理锁的获取与释放,彻底避免手动锁管理的风险。
5.1 RAII 模式的核心思想
RAII 的核心是:将资源的生命周期与对象的生命周期绑定。在QMutexLocker中:
- 构造函数获取锁(调用QMutex::lock());
- 析构函数释放锁(调用QMutex::unlock());
- 无论代码通过正常路径(return)还是异常路径(throw)退出作用域,析构函数都会执行,确保锁被释放。
5.2 用 QMutexLocker 保护共享资源
假设我们需要统计当前在线客户端数量,这是一个典型的共享资源,需用锁保护:
// 共享资源管理类
class ClientManager {
public:static ClientManager &instance() {static ClientManager inst;return inst;}// 增加在线客户端void addClient(qintptr socketDesc) {QMutexLocker locker(&m_mutex); // 自动加锁m_onlineClients.insert(socketDesc);// 离开作用域时,locker析构,自动解锁}// 移除在线客户端void removeClient(qintptr socketDesc) {QMutexLocker locker(&m_mutex); // 自动加锁m_onlineClients.remove(socketDesc);}// 获取在线客户端数量int onlineCount() {QMutexLocker locker(&m_mutex); // 自动加锁return m_onlineClients.size();}private:ClientManager() = default;QMutex m_mutex; // 保护共享资源的互斥锁QSet<qintptr> m_onlineClients; // 在线客户端集合
};
在TcpClientTask中使用该管理器:
// TcpClientTask.cpp 中补充
void TcpClientTask::run() {m_socket = new QTcpSocket();if (!m_socket->setSocketDescriptor(m_socketDescriptor)) {// ... 错误处理return;}// 客户端上线,添加到管理器ClientManager::instance().addClient(m_socketDescriptor);qCDebug(logTcpTask) << "Online clients:" << ClientManager::instance().onlineCount();// ... 数据处理循环 ...// 客户端下线,从管理器移除ClientManager::instance().removeClient(m_socketDescriptor);qCDebug(logTcpTask) << "Online clients:" << ClientManager::instance().onlineCount();
}
5.3 QMutexLocker 的高级用法
临时解锁若在锁作用域内需要临时释放锁(如等待某个条件),可使用unlock()和relock():
void doSomething() {QMutexLocker locker(&m_mutex);// 处理需要加锁的逻辑locker.unlock(); // 临时解锁// 执行不需要锁的耗时操作(如IO)locker.relock(); // 重新加锁// 继续处理需要加锁的逻辑
}
转移锁所有权通过moveToThread将锁的所有权转移给其他QMutexLocker对象(C++11 及以上):
QMutexLocker locker1(&m_mutex);
// ...
QMutexLocker locker2(std::move(locker1)); // 锁所有权转移给locker2
// 此时locker1不再持有锁,解锁由locker2负责
5.4 避免死锁的最佳方案
即使使用QMutexLocker,仍需注意锁的使用顺序,避免死锁。例如:
// 错误示例:两个线程获取锁的顺序相反
// 线程1
QMutexLocker locker1(&mutexA);
QMutexLocker locker2(&mutexB); // 可能死锁// 线程2
QMutexLocker locker1(&mutexB);
QMutexLocker locker2(&mutexA); // 可能死锁
解决方案:全局统一锁的获取顺序(如按地址大小排序):
// 正确示例:按锁地址排序获取
QMutex *m1 = &mutexA;
QMutex *m2 = &mutexB;
if (m1 > m2) std::swap(m1, m2); // 确保先获取地址小的锁QMutexLocker locker1(m1);
QMutexLocker locker2(m2);
六、性能优化与实战经验
基于上述架构,我们还需在实战中进行针对性优化,以应对高并发场景。
6.1 线程池参数调优
QThreadPool的setMaxThreadCount参数并非越大越好,需根据业务特点调整:
- CPU 密集型任务(如数据计算):线程数≈CPU 核心数(避免过多上下文切换);
- IO 密集型任务(如 TCP 读写):线程数可设置为 CPU 核心数 ×2~4(利用 IO 等待时间处理其他任务)。
- 可通过QThread::idealThreadCount()获取 CPU 核心数,动态调整:
int cpuCount = QThread::idealThreadCount();
QThreadPool::globalInstance()->setMaxThreadCount(cpuCount * 3); // IO密集型场景
6.2 缓冲区优化
QByteArray的mid()方法会复制数据,在高频解析场景下可优化为指针操作:
// 优化前:mid()会复制数据
QByteArray body = buffer.mid(4, bodyLen);
buffer = buffer.mid(4 + bodyLen);// 优化后:使用指针和偏移量,避免复制
const char *bodyData = buffer.constData() + 4;
processBusiness(QByteArray::fromRawData(bodyData, bodyLen)); // 不复制数据
buffer.remove(0, 4 + bodyLen); // 高效移除头部数据
6.3 非阻塞 IO 与信号槽
QTcpSocket在多线程中可使用信号槽(需注意线程亲和性),替代waitForReadyRead的阻塞方式:
// 在TcpClientTask::run()中使用信号槽
void TcpClientTask::run() {m_socket = new QTcpSocket();// ... 绑定socketDescriptor ...// 将socket移动到当前线程(任务执行的线程)m_socket->moveToThread(QThread::currentThread());// 连接信号槽connect(m_socket, &QTcpSocket::readyRead, this, &TcpClientTask::onReadyRead, Qt::DirectConnection);connect(m_socket, &QTcpSocket::disconnected, this, &TcpClientTask::onDisconnected, Qt::DirectConnection);// 启动事件循环(QRunnable本身无事件循环,需手动创建)QEventLoop loop;connect(this, &TcpClientTask::finished, &loop, &QEventLoop::quit);loop.exec();
}void TcpClientTask::onReadyRead() {m_recvBuffer += m_socket->readAll();parsePackets(m_recvBuffer);
}void TcpClientTask::onDisconnected() {m_isRunning = false;emit finished(); // 退出事件循环
}
注意:信号槽连接类型需用Qt::DirectConnection(同线程直接调用),避免跨线程调度开销。
6.4 连接过载保护
当并发连接数超过服务器承载能力时,需进行过载保护:
// TcpServer中限制最大连接数
void TcpServer::incomingConnection(qintptr socketDescriptor) {if (ClientManager::instance().onlineCount() >= 10000) { // 最大连接数限制QTcpSocket socket;socket.setSocketDescriptor(socketDescriptor);socket.write("Server is busy");socket.disconnectFromHost();return;}// 正常创建任务TcpClientTask *task = new TcpClientTask(socketDescriptor);QThreadPool::globalInstance()->start(task);
}
总结
本文深入探讨了 Qt 网络开发中两个核心问题的解决方案:
- TCP 粘包 / 拆包:通过 “定长包头 + 变长包体” 协议,结合缓冲区管理,实现可靠的数据包解析;
- 多线程效率:用QRunnable+QThreadPool替代 QThread 继承,通过线程复用降低资源开销;
- 线程安全:基于QMutexLocker的 RAII 模式,自动化管理锁的生命周期,避免竞态条件与死锁。
这套架构别人已经在实际项目中经过验证测试,一般支持 10 万级并发连接没多大问题,中小项目的万级以并发完全可放心用。相比传统方案,CPU 使用率低内存占用减少,从容应对高并发场景的挑战。