基于AI框架LangGraph对比Workflow模式与Agent模式

一. 一段话总结
LangGraph 是 LangChain 生态中用于构建Workflows(工作流) 和 Agents(智能体) 的工具,其中 Workflows 基于预定义代码路径按固定顺序执行(如 Prompt Chaining、Parallelization 等模式),Agents 则具备动态决策能力,可根据环境反馈自主选择工具和操作流程;核心支持 LLM 增强(结构化输出、工具绑定),提供持久化、流处理、调试与部署等生产级能力,基础配置需安装 langchain_core、langchain-anthropic 等依赖并初始化 Anthropic(如 claude-3-5-sonnet-latest)等支持工具调用的 LLM,可满足文档翻译、多任务并行、动态路由、迭代优化等多样化业务需求。
二. 思维导图
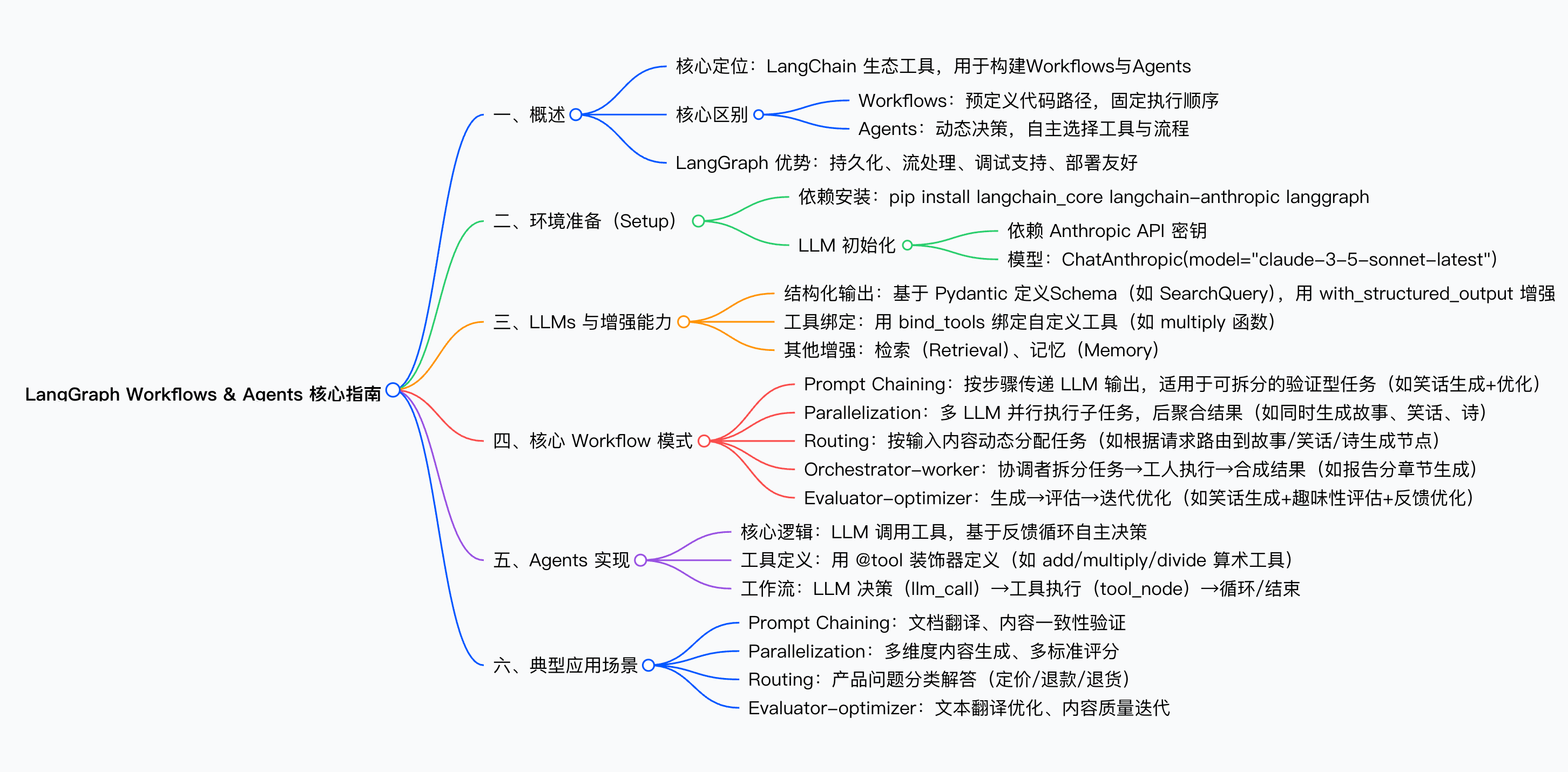
三. 详细总结
1. 概述:Workflows 与 Agents 核心定义
LangGraph 聚焦于构建两种核心系统,二者在控制流和自主性上存在本质差异,具体对比如下:
| 类型 | 核心特征 | 控制流来源 | 典型适用场景 |
|---|---|---|---|
| Workflows | 基于预定义代码路径,按固定顺序执行 | 开发者预设 | 文档翻译、多任务并行处理、固定流程验证 |
| Agents | 动态决策,可根据环境反馈自主选择工具与流程 | LLM 基于反馈自主判断 | 算术计算、未知问题求解、动态工具调用 |
同时,LangGraph 提供生产级支撑能力:持久化(状态存储)、流处理(实时输出)、调试(可视化工作流)、部署友好,降低从原型到生产的门槛。
2. 环境准备(Setup)
2.1 依赖安装
需安装 3 类核心依赖,命令如下:
pip install langchain_core langchain-anthropic langgraph
2.2 LLM 初始化
需使用支持结构化输出和工具调用的 Chat 模型(示例为 Anthropic),步骤如下:
- 配置环境变量:通过
getpass动态输入ANTHROPIC_API_KEY,避免硬编码; - 初始化模型:指定模型为
claude-3-5-sonnet-latest(Anthropic 最新高性能模型),代码如下:
import os
import getpass
from langchain_anthropic import ChatAnthropicdef _set_env(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"{var}: ")_set_env("ANTHROPIC_API_KEY")
llm = ChatAnthropic(model="claude-3-5-sonnet-latest")
3. LLM 增强能力:适配业务需求的核心手段
LangGraph 通过 “结构化输出” 和 “工具绑定” 两种核心方式增强 LLM 能力,满足不同场景需求:
3.1 结构化输出
基于 Pydantic 定义输出 Schema,确保 LLM 输出格式统一,适用于需要精准解析的场景(如查询生成、路由决策)。示例:定义搜索查询(SearchQuery)的 Schema 并增强 LLM:
from pydantic import BaseModel, Fieldclass SearchQuery(BaseModel):search_query: str = Field(None, description="优化后的网页搜索查询")justification: str = Field(None, description="查询与用户需求的相关性理由")structured_llm = llm.with_structured_output(SearchQuery)
# 调用:输出格式严格遵循 SearchQuery
output = structured_llm.invoke("Calcium CT 评分与高胆固醇的关系是什么?")
3.2 工具绑定
将自定义工具(如算术函数、API 调用)绑定到 LLM,让 LLM 可自主触发工具执行,适用于需要外部计算或数据的场景。示例:绑定乘法工具(multiply)并触发调用:
# 定义工具
def multiply(a: int, b: int) -> int:return a * b# 绑定工具到 LLM
llm_with_tools = llm.bind_tools([multiply])
# 调用:LLM 自动识别需求并触发工具
msg = llm_with_tools.invoke("2乘以3等于多少?")
# 获取工具调用结果
print(msg.tool_calls) # 输出工具调用参数与名称
4. 核心 Workflow 模式:按场景选择预定义流程
LangGraph 提供 5 种核心 Workflow 模式,每种模式对应特定的任务拆分与执行逻辑,具体如下表:
| 模式名称 | 核心定义 | 适用场景 | 关键节点 / 逻辑 | 示例任务 |
|---|---|---|---|---|
| Prompt Chaining (链式执行) | 前一个 LLM 输出作为后一个 LLM 输入,按步骤执行可拆分的验证型任务 | 文档翻译、内容一致性验证、多步优化 | 1. 生成节点(如 generate_joke);2. 校验节点(如 check_punchline);3. 优化节点(如 improve_joke) | 生成关于 “猫” 的笑话→校验笑点→优化趣味性 |
| Parallelization (并行执行) | 多个 LLM 并行执行独立子任务,最终聚合结果,提升效率或增加结果多样性 | 多维度内容生成、多标准评分 | 1. 并行生成节点(如 call_llm_1/2/3);2. 聚合节点(如 aggregator) | 同时生成 “猫” 的故事、笑话、诗,后合并输出 |
| Routing (路由) | 先通过 LLM 决策输入类型,再路由到对应子任务流程,适配多场景统一入口 | 产品问题分类解答(定价 / 退款 / 退货)、内容类型生成 | 1. 路由决策节点(如 llm_call_router);2. 条件路由(如 route_decision) | 根据用户请求 “写关于猫的笑话”,路由到笑话生成节点 |
| Orchestrator-worker (总分总) | 协调者(Orchestrator)拆分任务→工人(Worker)执行→合成者(Synthesizer)整合结果 | 多章节报告生成、多文件内容更新 | 1. 协调节点(如 orchestrator,拆分报告章节);2. 工人节点(如 llm_call,写单章节);3. 合成节点(如 synthesizer) | 生成 “LLM 缩放定律” 报告,拆分章节→写章节→合并报告 |
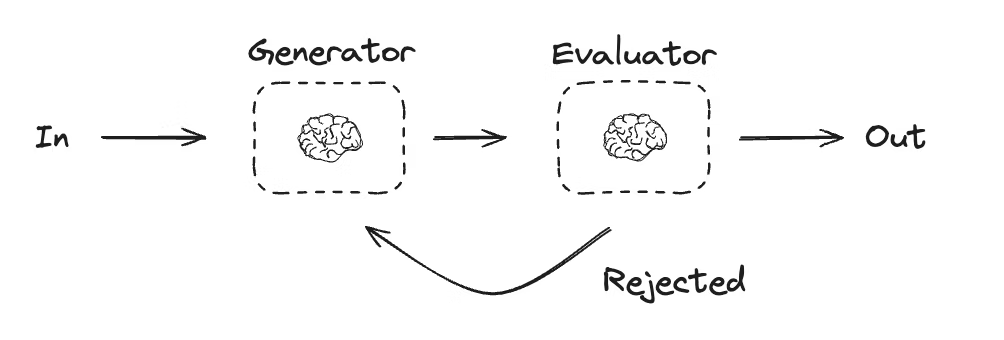
| Evaluator-optimizer (持续优化) | 生成节点生成内容→评估节点判断是否达标→不达标则反馈优化,循环至合格 | 文本翻译优化、内容质量迭代(如笑话趣味性) | 1. 生成节点(如 llm_call_generator);2. 评估节点(如 llm_call_evaluator);3. 条件路由(如 route_joke) | 生成 “猫” 的笑话→评估趣味性→不达标则根据反馈重写 |
示意图-Prompt Chaining
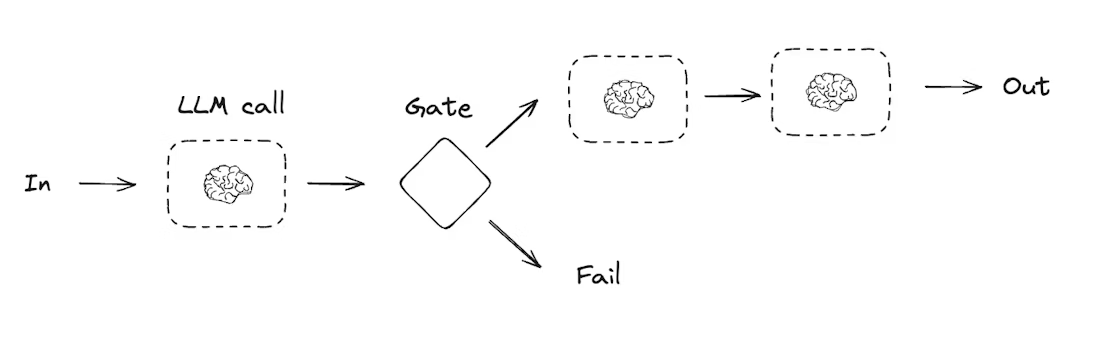
示意图-Parallelization
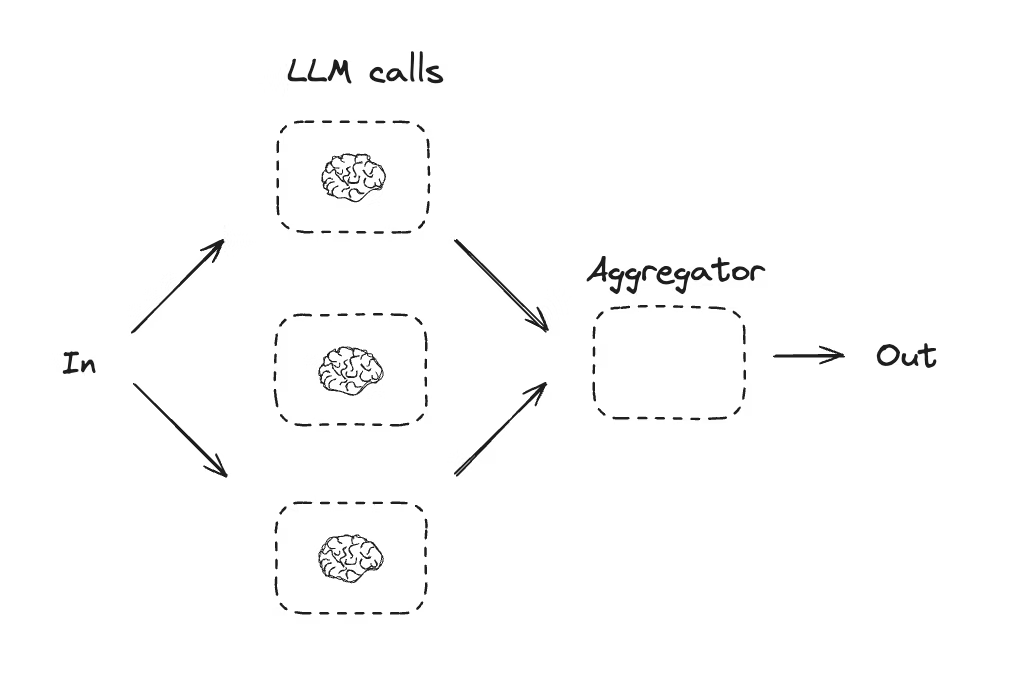
示意图-Routing
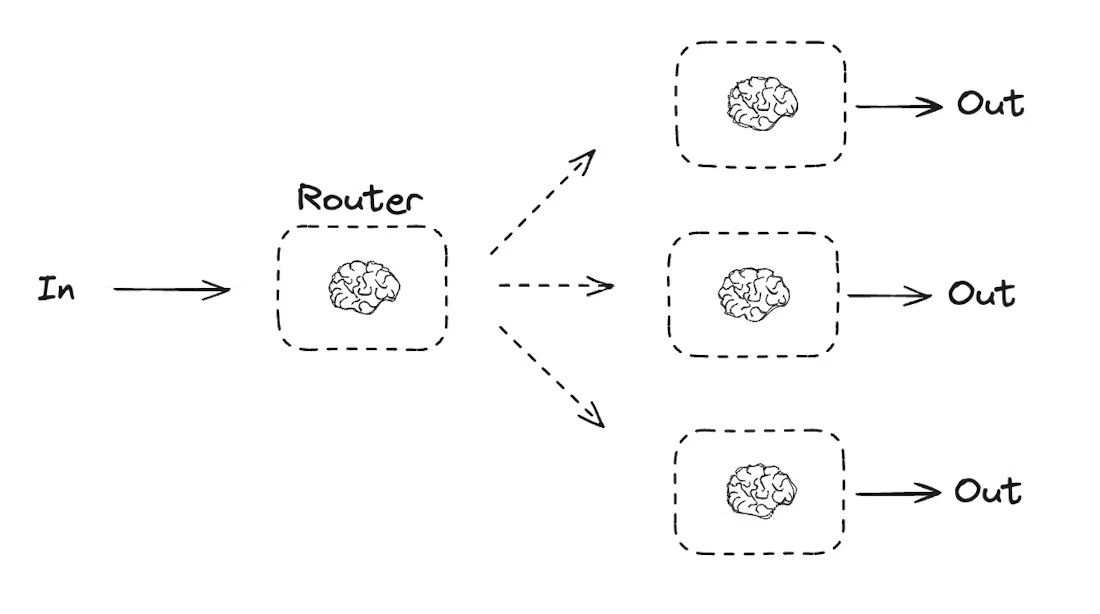
示意图-Orchestrator-worker
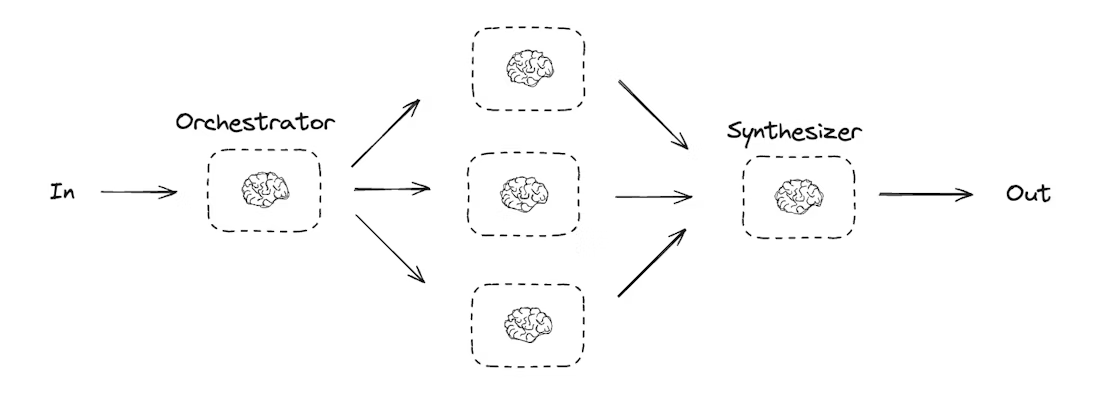
示意图-Evaluator-optimizer
5. Agents 实现:动态决策的自主执行系统
Agents 是 LangGraph 中具备高度自主性的系统,核心逻辑为 “LLM 决策→工具执行→反馈循环”,适用于问题和解决方案不可预测的场景(如算术计算、动态工具调用)。
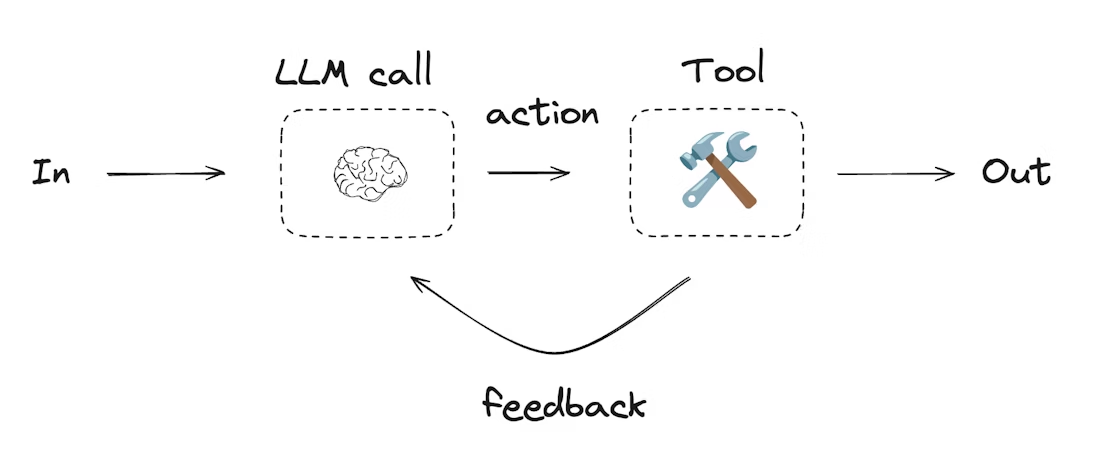
5.1 核心组件
- 工具集:用
@tool装饰器定义的可调用函数(如算术工具 add/multiply/divide); - LLM 决策节点:判断是否调用工具或直接返回结果(llm_call);
- 工具执行节点:执行 LLM 触发的工具调用(tool_node);
- 循环控制:根据 LLM 是否触发工具调用,决定继续循环或结束(should_continue)。
5.2 实现代码框架
# 1. 定义工具
from langchain.tools import tool
from langgraph.graph import MessagesState
from typing_extensions import Literal
from langgraph.graph import StateGraph, START, END
from common_llm import llm@tool
def multiply(a: int, b: int) -> int:return a * b
@tool
def add(a: int, b: int) -> int:return a + b
@tool
def divide(a: int, b: int) -> float:return a / bdef should_continue(state: MessagesState) -> Literal["tool_node", END]:'''决定是否继续循环或停止,根据 LLM 是否进行了工具调用'''messages = state["messages"]last_message = messages[-1]# 如果 LLM 进行了工具调用,那么执行工具调用if last_message.tool_calls:return "tool_node"# Otherwise, we stop (reply to the user)return END@tool
def add(a: int, b: int) -> int:"""加法运算,参数 a/b 为整数"""return a + btools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)# 2. 定义节点与状态
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, HumanMessage, ToolMessagedef llm_call(state: MessagesState):"""LLM 决策是否调用工具"""return {"messages": [llm_with_tools.invoke([SystemMessage(content="算术助手")] + state["messages"])]}def tool_node(state: dict):"""执行工具调用"""result = []for tool_call in state["messages"][-1].tool_calls:tool = tools_by_name[tool_call["name"]]observation = tool.invoke(tool_call["args"])result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))return {"messages": result}# 3. 构建 Agent 工作流
agent_builder = StateGraph(MessagesState)
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
agent_builder.add_edge("tool_node", "llm_call")# 4. 调用 Agent
agent = agent_builder.compile()
messages = agent.invoke({"messages": [HumanMessage(content="3加4等于多少?")]})6. LangGraph 核心优势总结
- 灵活性:支持 Workflows(固定流程)与 Agents(动态决策),适配从简单到复杂的业务场景;
- 生产级能力:提供持久化(状态存储)、流处理(实时输出)、调试(可视化工作流),降低部署难度;
- LLM 增强友好:无缝支持结构化输出、工具绑定、记忆等增强手段,无需额外集成;
- 可视化与可调试:通过
draw_mermaid_png()生成工作流图表,支持xray=True查看详细节点关系,便于问题定位。
四. 关键问题
问题 1:LangGraph 中的 Workflows 与 Agents 核心差异是什么?二者分别适用于什么场景?
答案:核心差异体现在控制流来源和自主性上。Workflows 的控制流由开发者预定义代码路径,执行顺序固定(如按 “生成→校验→优化” 步骤执行),自主性低;Agents 的控制流由 LLM 基于环境反馈自主决策,可动态选择工具、调整执行步骤,自主性高。适用场景:Workflows 适用于任务流程可预测的场景(如文档翻译、多章节报告生成);Agents 适用于问题与解决方案不可预测的场景(如动态算术计算、未知问题的工具调用)。
问题 2:在 LangGraph 中,如何通过 “增强 LLM” 实现结构化输出?请结合示例说明核心步骤。
答案:通过 “Pydantic Schema 定义 + LLM 增强” 两步实现,核心是让 LLM 输出格式严格符合业务需求,步骤如下:
- 定义 Schema:基于 Pydantic 的 BaseModel 定义输出结构,指定字段名称、类型与描述(如搜索查询的 SearchQuery 包含 search_query 和 justification 字段);
- 增强 LLM:调用 LLM 的
with_structured_output()方法,传入定义的 Schema,生成结构化 LLM; - 调用执行:用增强后的 LLM 处理用户请求,输出自动适配 Schema 格式。示例代码:
from pydantic import BaseModel, Field# 1. 定义 Schema
class SearchQuery(BaseModel):search_query: str = Field(None, description="优化后的网页搜索查询")justification: str = Field(None, description="查询与用户需求的相关性理由")# 2. 增强 LLM
structured_llm = llm.with_structured_output(SearchQuery)# 3. 调用执行
output = structured_llm.invoke("Calcium CT 评分与高胆固醇的关系是什么?")
print(output.search_query) # 输出结构化的搜索查询
print(output.justification) # 输出相关性理由
问题 3:LangGraph 的 Evaluator-optimizer 模式如何实现 “生成 - 评估 - 优化” 的闭环?其典型适用场景是什么?
答案:闭环通过 “生成节点→评估节点→条件路由” 三大组件实现,具体逻辑如下:
- 生成节点(Generator):LLM 生成初始内容(如笑话),若有历史反馈则基于反馈优化生成;
- 评估节点(Evaluator):用增强 LLM(绑定评估 Schema)判断内容是否达标(如笑话是否有趣),输出 “达标 / 不达标” 结果及优化反馈;
- 条件路由:若达标则结束流程,若不达标则将反馈传入生成节点,循环执行 “生成→评估”,直至内容合格。典型适用场景:需要迭代优化以满足明确标准的任务,如文本翻译(确保语义一致)、内容质量优化(如笑话趣味性、报告准确性)、创意内容打磨(如故事剧情优化)。
推荐阅读
基于AI Agent的数据资产自动化治理实验
吃透大数据算法-算法地图(备用)
吃透大数据算法-量体裁衣-HNSW场景化参数调优
字节多Agent架构Aime—— 让多个 AI 像 “灵活团队” 一样干活的新系统
吃透大数据算法-百万商品库的 “闪电匹配”:HNSW 算法的电商实战故事