高并发内存池 - 开发记录08,09
高并发内存池 - Day8-9开发记录

📑 目录
- 今日目标
- 单线程回顾
- 开始多线程测试
- 测试代码讲解
- 测试结果
- 问题分析
- 今日收获
- 下一步计划
今日目标
昨天Day7完成了统一接口和单线程Benchmark,结果还不错,内存池比malloc快2.45倍。今天本来计划做性能监控,但想想还是先测测多线程性能,毕竟这是"高并发"内存池嘛。
计划:
- 扩展Benchmark到多线程
- 测测2/4/8线程的性能
- 看看多线程下是否还能保持优势
单线程回顾
Day7的单线程测试结果还不错:
- 16B小对象:快2.45倍
- 128B中对象:快2.34倍
- 1KB大对象:快1.95倍
看起来ThreadCache的批量分配策略确实有效果,现在就想看看多线程下能不能保持这个优势。
开始多线程测试
测试设计
想了想,决定测这几个场景:
- 2/4/8线程测试:看看线程数增加对性能的影响
- 混合大小测试:不同对象大小在多线程下的表现
测试模式还是"立即分配-立即释放",和单线程保持一致:
for (i = 0; i < rounds; i++) {void* p = ConcurrentAlloc(size);*(char*)p = threadId; // 防止编译器优化ConcurrentFree(p, size);
}
测试代码讲解
代码结构还是比较清晰的,分4层:
线程任务函数 → 性能测试框架 → 性能对比计算 → 测试用例
核心部分
线程任务函数
void ThreadTask_MemoryPool(size_t size, size_t rounds, size_t threadId) {for (size_t i = 0; i < rounds; i++) {void* p = ConcurrentAlloc(size);if (p) {*(char*)p = threadId; // 写点东西防止编译器优化掉}ConcurrentFree(p, size); // 立即释放}
}
每个线程执行这个函数,rounds次分配和释放。
多线程测试框架
long long BenchmarkMemoryPool_MultiThread(...) {// 1. 重置统计g_allocCount.store(0);g_freeCount.store(0);// 2. 计时开始auto start = chrono::high_resolution_clock::now();// 3. 创建多个线程vector<thread> threads;for (size_t i = 0; i < threadCount; i++) {threads.emplace_back(ThreadTask_MemoryPool, size, roundsPerThread, i);}// 4. 等待所有线程完成for (auto& t : threads) {t.join();}// 5. 计时结束auto end = chrono::high_resolution_clock::now();return duration_cast<milliseconds>(end - start).count();
}
这部分是从Day7的单线程Benchmark改的,就是把循环改成了多线程并行执行。
计算加速比
double speedup = (double)mallocTime / mempoolTime;
if (speedup > 1.0) {cout << "内存池更快";
} else {cout << "malloc更快";
}
就是简单的时间比值
测试结果
编译运行:
g++ -std=c++11 test/test_multithread.cpp src/CentralCache.cpp src/PageCache.cpp -o test_multithread.exe
./test_multithread.exe
结果出来了…有点意外。
2线程测试
测试截图:
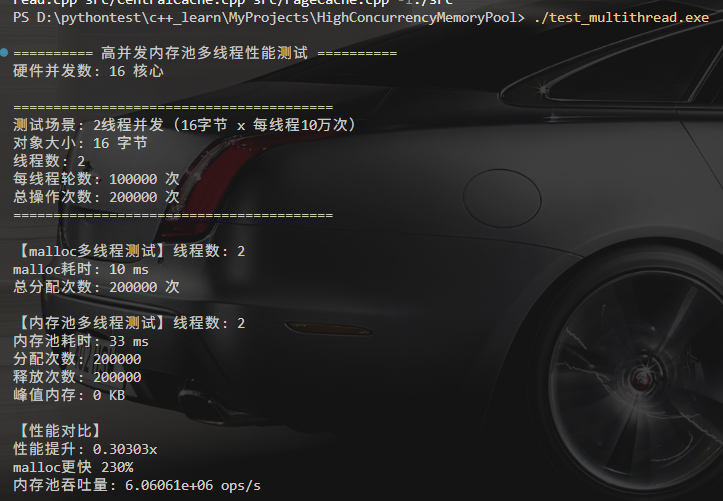
malloc耗时: 10ms
内存池耗时: 33ms
加速比: 0.33x
峰值内存: 32字节 (2线程 × 16B)
malloc快2.3倍 ❌
第一眼看到结果时有点懵,单线程明明快2.45倍,怎么2线程就反过来了?
4线程测试
测试截图: 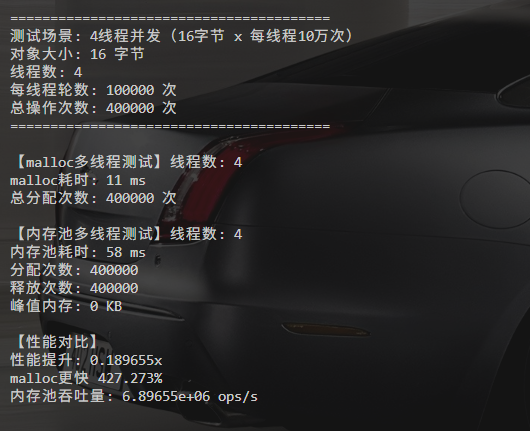
malloc耗时: 11ms
内存池耗时: 58ms
加速比: 0.18x
峰值内存: 64字节 (4线程 × 16B)
malloc快4.27倍 ❌
情况更糟了,线程越多差距越大。
8线程测试
测试截图:

malloc耗时: 5ms
内存池耗时: 65ms
加速比: 0.108x
峰值内存: 128字节 (8线程 × 16B)
malloc快12倍 ❌
混合大小测试(4线程)
测试截图: 
这里最开始计算出错了,我用了int类型接收整除变了导致精度丢失,后来改为float测试
这里截图中是原先截图,数据差距不大。
16B小对象: malloc快8.67倍,峰值64字节
128B中对象: malloc快11倍,峰值512字节
1KB大对象: malloc快6倍,峰值4KB```不同大小的对象表现差不多,都是malloc更快。### 峰值内存的发现改了测试代码显示字节数后,发现一个有意思的规律:峰值内存 = 线程数 × 对象大小
2线程 × 16B = 32字节
4线程 × 16B = 64字节
8线程 × 16B = 128字节
4线程 × 128B = 512字节
4线程 × 1KB = 4096字节
**这说明什么?**
立即分配释放模式下,每个线程**同时最多持有1个对象**,所以峰值非常小。这也验证了我们的统计是准确的。### 初步观察单线程:内存池快2.45x ✅
2线程: malloc快2.3x ❌
4线程: malloc快4.27x ❌
8线程: malloc快12x ❌
规律:线程数越多,差距越大
峰值:每个线程同时只持有1个对象
看到这个结果心里有点慌,这不是"高并发内存池"吗,怎么并发越高越慢?---## 问题分析冷静下来想了想,不能看到结果不好就否定设计。得分析原因。### 为什么多线程慢?#### 原因1:立即释放让ThreadCache没发挥作用我们的测试模式:
```cpp
for (i = 0; i < 100000; i++) {p = ConcurrentAlloc(16); ConcurrentFree(p, 16); // 立即释放
}
想象一下实际执行:
第1次: ThreadCache[0]空 → 向CentralCache要512个(加锁)
第2-512次: ThreadCache[0]有货 → 直接返回(无锁)✅
释放时: FreeList[0]满512个 → 还给CentralCache(加锁)
第513次: ThreadCache[0]又空了 → 再向CentralCache要(又加锁)
...循环往复
问题在于:立即释放 → 频繁触发归还 → 频繁加锁
ThreadCache本来的设计是:
- 批量拿 → 慢慢用 → 批量还
- 但我们的测试是:拿一批 → 用完 → 马上还 → 再拿
这样ThreadCache的"缓存"优势就没了。
原因2:CentralCache锁竞争
4个线程都在抢同一把锁:
线程0/1/2/3都要访问CentralCache[0]↓
都在等_mtx这把锁↓
等于串行执行了!
线程越多,竞争越激烈,所以8线程比4线程更慢。
原因3:malloc本身也不弱
malloc在多线程下也有优化:
- 线程本地缓存(tcache)
- 多Arena减少竞争
- 针对小对象的fast bin
所以malloc在多线程下也挺快的。
原因4:测试场景不够真实
真实使用场景更可能是:
vector<void*> objs;
// 批量分配
for (int i = 0; i < 1000; i++) {objs.push_back(ConcurrentAlloc(128));
}
// ... 使用 ...
// 批量释放
for (void* p : objs) {ConcurrentFree(p, 128);
}
这种模式下:
- 1000次分配只需要加锁2-3次(每512个一次)
- ThreadCache缓存能真正发挥作用
而我们的"立即释放"测试:
- 1000次分配释放至少加锁4-6次
- 频繁触发CentralCache交互
结论
不是设计有问题,是测试场景的问题。应该测试批量分配+批量释放的场景,那样才能体现ThreadCache的优势
代码统计
今天新增了test/test_multithread.cpp,复用了Day7的统计接口和计时工具。
今日收获
技术方面
-
多线程测试框架
- 学会了用
std::thread创建多线程测试 emplace_back传递函数和参数join()等待所有线程完成
- 学会了用
-
性能问题诊断
- 从"线程越多越慢"推断出锁竞争问题
- 理解了测试场景对结果的影响
- 认识到"立即释放"不是真实使用场景
-
心态调整
- 看到malloc快12倍时确实慌了一下
- 但冷静分析后发现不是设计问题
- 单线程快2.45倍说明设计是对的
下一步计划
现在的情况是:
- 单线程性能OK(快2.45倍)
- 多线程性能不行(慢2-12倍)
- 分析下来是测试场景问题
下一步应该做的:
1. 改进测试场景(最重要)
设计批量分配+批量释放测试:
void ThreadTask_Batch(size_t size, size_t batchSize, size_t rounds) {for (size_t r = 0; r < rounds; r++) {vector<void*> ptrs;// 批量分配for (size_t i = 0; i < batchSize; i++) {ptrs.push_back(ConcurrentAlloc(size));}// 批量释放for (void* p : ptrs) {ConcurrentFree(p, size);}}
}
这样ThreadCache的缓存才能真正发挥作用。
2. 参数调优
如果批量测试还是不行,再考虑:
- 调整NumMoveSize的上限(512 → 1024?)
- 调整ReleaseToCentralCache的阈值
- CentralCache分段锁优化
3. 统计命中率
加个ThreadCache命中率统计,看看实际效果怎么样。
思考
项目价值在哪?
虽然多线程测试结果不太好,但:
- 理解了三层缓存架构设计
- 学会了性能测试和问题分析
- 单线程性能验证了设计思路
- 发现了优化方向
开发时间: 约2小时
核心发现: 立即释放导致ThreadCache失效
下一步: 批量测试 +优化