Agent Laboratory: 利用 LLM Agent 作为研究助手
机构:AMD, JHU
论文链接: https://arxiv.org/abs/2501.04227
代码链接: https://AgentLaboratory.github.io
Abstract
从历史上看,科学发现一直是一个漫长且昂贵的过程,从最初的构思到最终成果往往需要投入大量的时间与资源。为加速科学发现、降低科研成本并提升研究质量,我们提出了 Agent Laboratory ——一个基于大型语言模型(LLM)的自主科研框架,能够完成整个研究流程。该框架以人类提供的研究想法为起点,依次经历文献综述、实验实施与报告撰写三个阶段,最终产出完整的科研成果,包括代码仓库与研究报告。同时,用户可以在各阶段提供反馈与指导。
我们基于多种最新的 LLM 部署了 Agent Laboratory,并邀请多位研究人员通过问卷调查、阶段性反馈与最终论文评估来考察其研究质量。研究结果表明:
(1) 由 o1-preview 驱动的 Agent Laboratory 生成的研究成果质量最佳;
(2) 其生成的机器学习代码在性能上可达到与现有方法相当甚至更优的水平;
(3) 人类在各阶段的反馈显著提升了整体研究质量;
(4) 与以往的自动化科研方法相比,Agent Laboratory 将研究成本降低了 84%。
我们期望 Agent Laboratory 能帮助研究者将更多精力投入到创造性构思而非低层次的编程与写作中,从而进一步加速科学发现的进程。
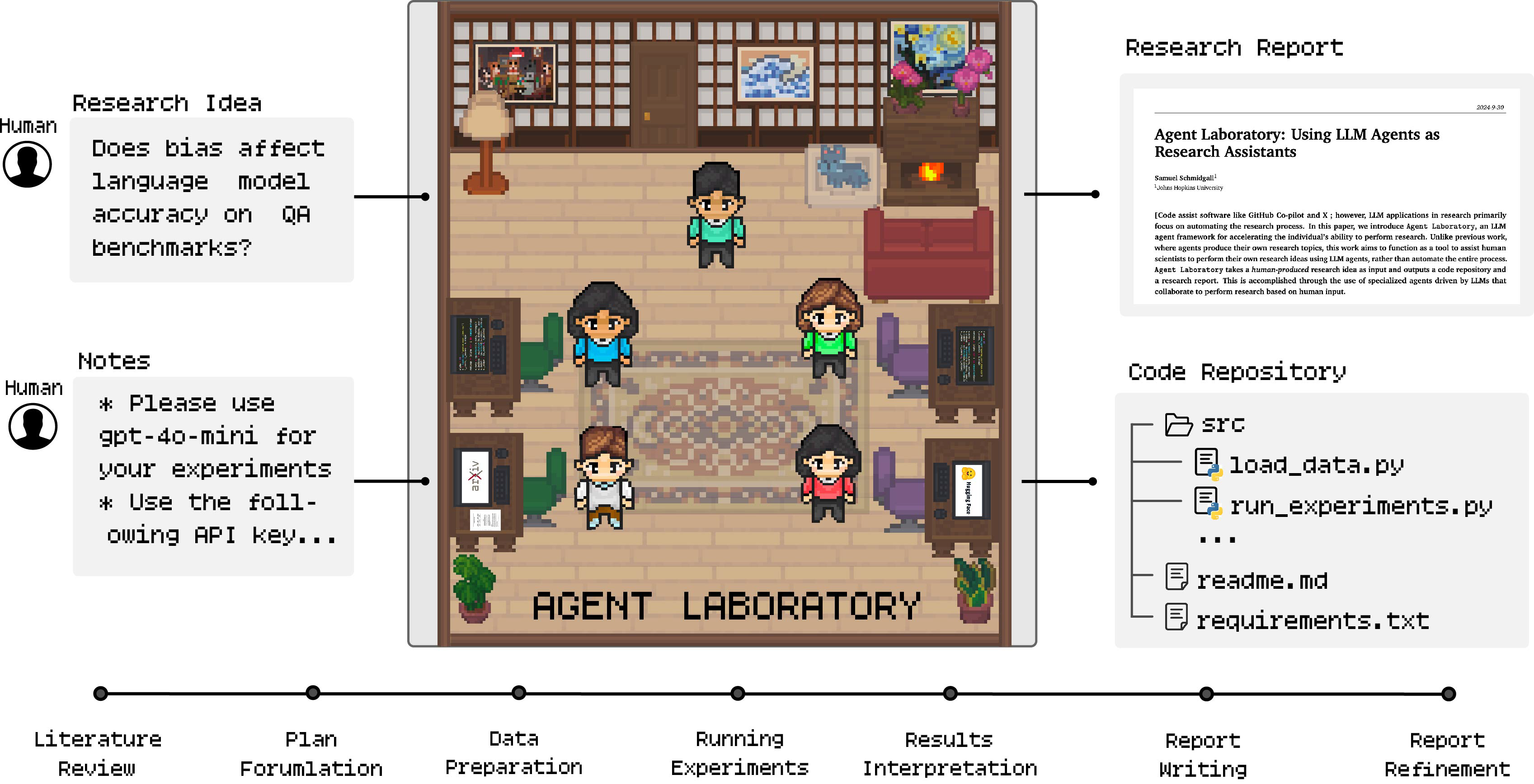
Agent Laboratory将人类的研究想法和一组笔记作为输入,将其提供给专门的llm驱动的代理管道,并生成研究报告和代码存储库。
Contribution
-
我们提出了 Agent Laboratory,一个开源的大语言模型(LLM)智能体框架,用于加速个体在机器学习领域的科研能力。为了适配不同类型的用户,Agent Laboratory 具备灵活的计算分配机制,可根据用户的计算资源(如 CPU、GPU、内存)与推理预算自动调整模型规模与运行配置。
-
人工评估结果表明,使用 Agent Laboratory 生成的论文在实验质量、报告质量与实用性等维度上均表现良好。虽然 o1-preview 后端被认为是最具实用性的,但 o1-mini 在实验质量评分中表现最佳,而 gpt-4o 在所有指标中均略逊一筹。
-
NeurIPS 风格的评审结果显示,o1-preview 在多个后端中表现最佳,尤其在清晰度与可靠性方面获得最高人类评分。然而,人工评审与自动化评估之间仍存在显著差距——自动化评估往往高估研究质量(平均得分 6.1/10 对比人工 3.8/10)。类似的偏差也出现在清晰度与贡献度指标中,这表明需要结合人类反馈与自动化评估,才能更准确地衡量科研成果的质量。
-
Co-pilot模式评估结果显示,在自定义与预设主题上,该模式整体得分高于全自动模式。Co-pilot 模式生成的论文在实验质量与实用性上表现出更高的平衡性,但也揭示了智能体输出与研究者意图之间的对齐挑战(确实,我觉得肯定要有人提供反馈的)。
-
Co-pilot功能的总体评价显示,其具有较高的实用性与可用性。大多数受试者在体验后均表示愿意继续使用该功能。
-
详细的成本与推理时间统计表明,Agent Laboratory 在不同模型后端下的论文生成成本极低。例如,使用 gpt-4o 后端时,每篇论文的平均成本仅为 2.33 美元,远低于其他自动化科研系统,证明其在成本效率上的显著优势。
-
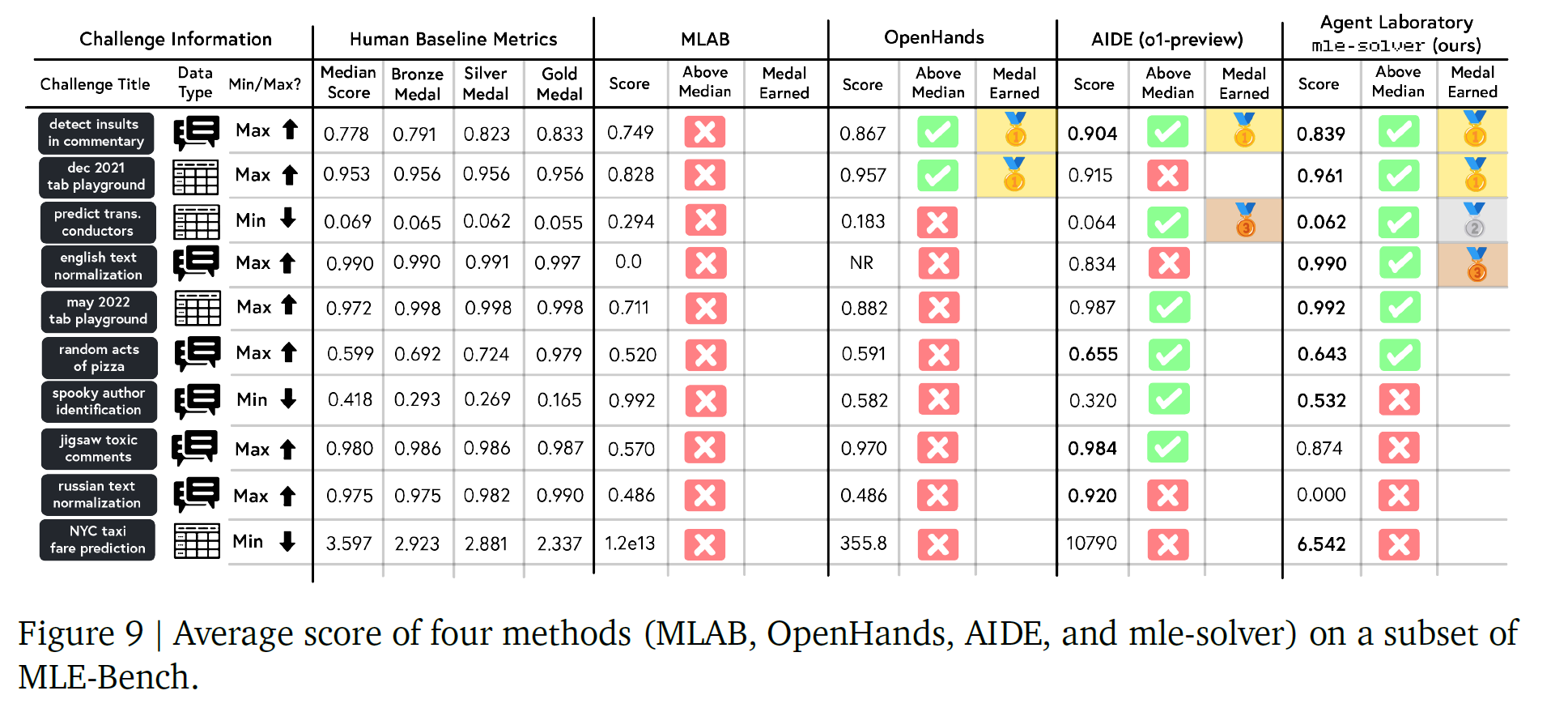
在 MLE-Bench 挑战集上的表现显示,Agent Laboratory 提出的 mle-solver 模块取得了最先进的性能表现,在稳定性与得分一致性方面优于其他求解器,并获得了比 MLAB、OpenHands 和 AIDE 更多的奖牌(包括金牌和银牌)。
Related Works
Large language models
LLM Agents
这两个不解释
Automated machine learning
总之这些方法是自动去解决kaggle 问题的
AI in Scientific Discovery
These approaches position AI as a tool rather than an agent performing research in autonomous research.
LLMs for research related tasks
These findings suggest that, with the current LLMs, the strongest research systems would combine human-guided ideation with LLM-based workflows.
LLMs for autonomous research
Studies like Si et al. (2024) highlight limitations in the feasibility and implementation details of LLM ideation, indicating a complementary rather than replacement role for LLMs in autonomous research.
Method
Agent Laboratory begins with the independent collection and analysis of relevant
research papers, progresses through collaborative planning and data preparation, and results in automated experimentation and comprehensive report generation. As shown in Figure 2, the overall workflow consists of three primary phases: (1) Literature Review, (2) Experimentation, and (3) Report Writing.
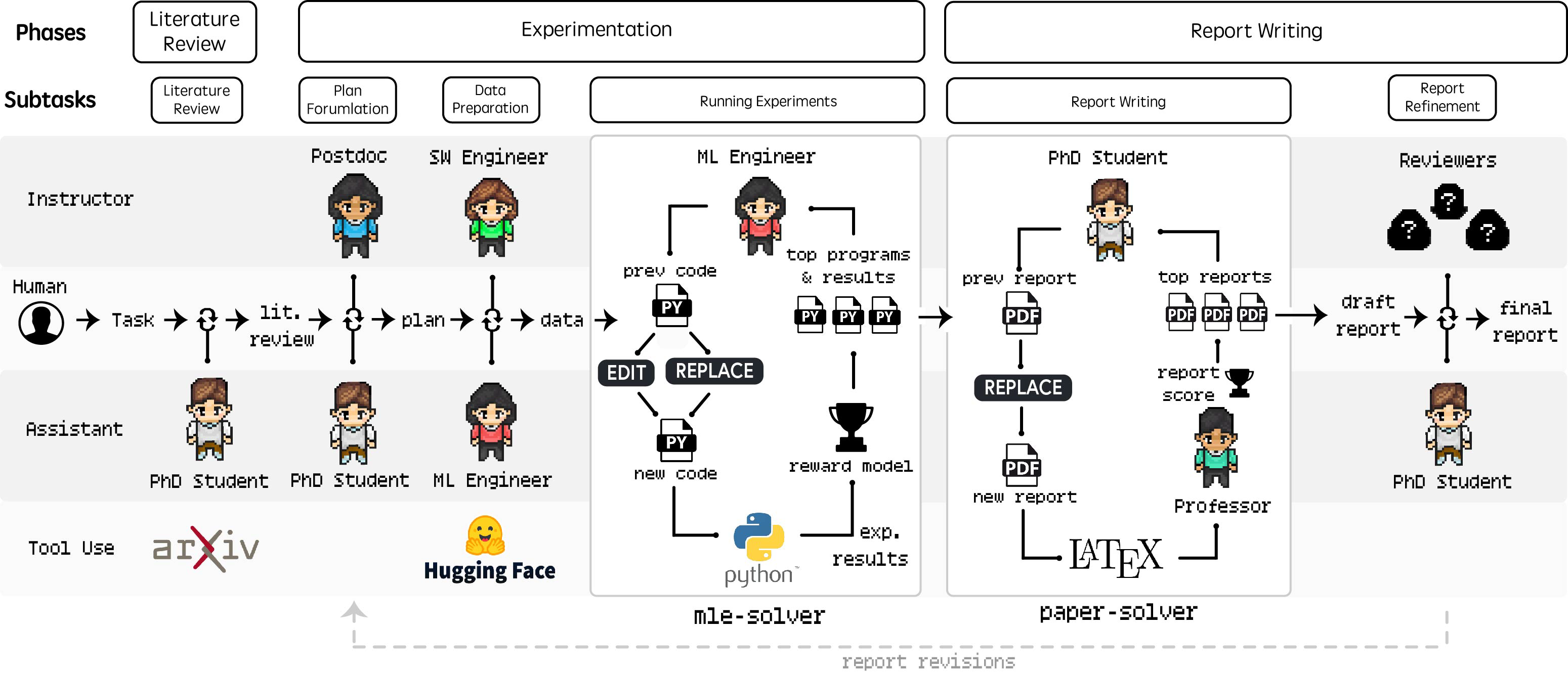
Fig2. Agent Laboratory Workflow: 此图展示了“代理实验室”的三个主要阶段:文献综述 Literature Review、实验操作Experimentation 和报告撰写 Report Writing,每个阶段都有不同的任务、工具和human-agent roles。该流程将人类的输入与诸如博士和博士后代理等由大型语言模型驱动的代理相结合,这些代理负责文献综述、实验规划、数据准备和结果解读。像 mle-solver 这样的实验专用工具以及用于报告生成的 paper-solver 等工具,能够自动完成繁琐的研究任务,从而促进人类研究人员与人工智能之间的协作,以产出高质量的研究成果。
Literature Review
The literature review phase involves gathering and curating relevant research papers for the given research idea to provide references for subsequent stages. During this process,
the PhD agent utilizes the arXiv API to retrieve related papers and performs three main actions:
summary, full text, and add paper.
The summary action retrieves abstracts of the top 20 papers relevant to the initial query produced by the agent.
The full text action extracts the complete content of specific papers, and the add paper action incorporates selected summaries or full texts into the curated review. (这一步模型不断接待区生成一个更好的review)
Once the specified number of relevant texts (N=max) is reached via the add paper command, the curated review is finalized for use in subsequent phases.
感觉这个阶段好像没啥特别值得斟酌的事情,要是能生成知识图谱的话又是另外一回事了
Experimentation
Plan Formulation
The plan formulation phase focuses on creating a detailed, actionable research plan based on the literature review and research goal.
During this phase, the PhD and Postdoc agents collaborate through dialogue to specify how to achieve the research objective, detailing experimental components needed to complete the specified research idea such as which machine learning models to implement, which datasets to use, and the high-level steps of the experiment. 当达到一致后就把plan 传递给后续步骤,像一个自我探讨版的planner
Data Preparation.
The goal of the data preparation phase is to write code that prepares data for running experiments, using the instructions from the plan formulation stage as a guideline.
The ML Engineer agent 1)executes code using Python command and observes any printed output. 2) access to HuggingFace datasets, searchable via the search HF command.
the code is first passed through a Python compiler to ensure that there are no compilation issues and iteratively executed until the code is bug-free. (这是人工的还是模型去重复调整的?)
After agreeing on the finalized data preparation code, the SW Engineer agent submits it using the submit code command.
有一说一感觉可以cursor 替代但是不知道怎么集成,到时候看看
可以看出以下的agent 完全是这个团队弄出来的,我其实感觉自己弄也弄不好hhh
Running Experiments.
In the running experiments phase, the ML Engineer agent focuses on implementing and executing the experimental plan formulated prior.
This is facilitated by mle-solver, a specialized module designed to generate, test, and refine machine learning code autonomously based on the research plan and insights from the
literature review.
For the first mle-solver step, the program is empty and must generate a file from scratch, which is used as the top scoring program.
接下来是 mle-solver 的步骤:多轮的「生成—执行—评分—反思—稳定化」循环
| 阶段 | 名称 | 核心目标 | 关键机制 |
|---|---|---|---|
| A | Command Execution | 初始化与代码生成 | EDIT / REPLACE 操作 |
| B | Code Execution | 验证代码可运行性 | 编译检查 + 错误修复 |
| C | Program Scoring | 衡量代码质量 | LLM 奖励模型评分 (0–1) |
| D | Self Reflection | 自我改进 | 错误/成功反思与记录 |
| E | Performance Stabilization | 维持系统稳定 | 高分样本池 + 并行多样性优化 |
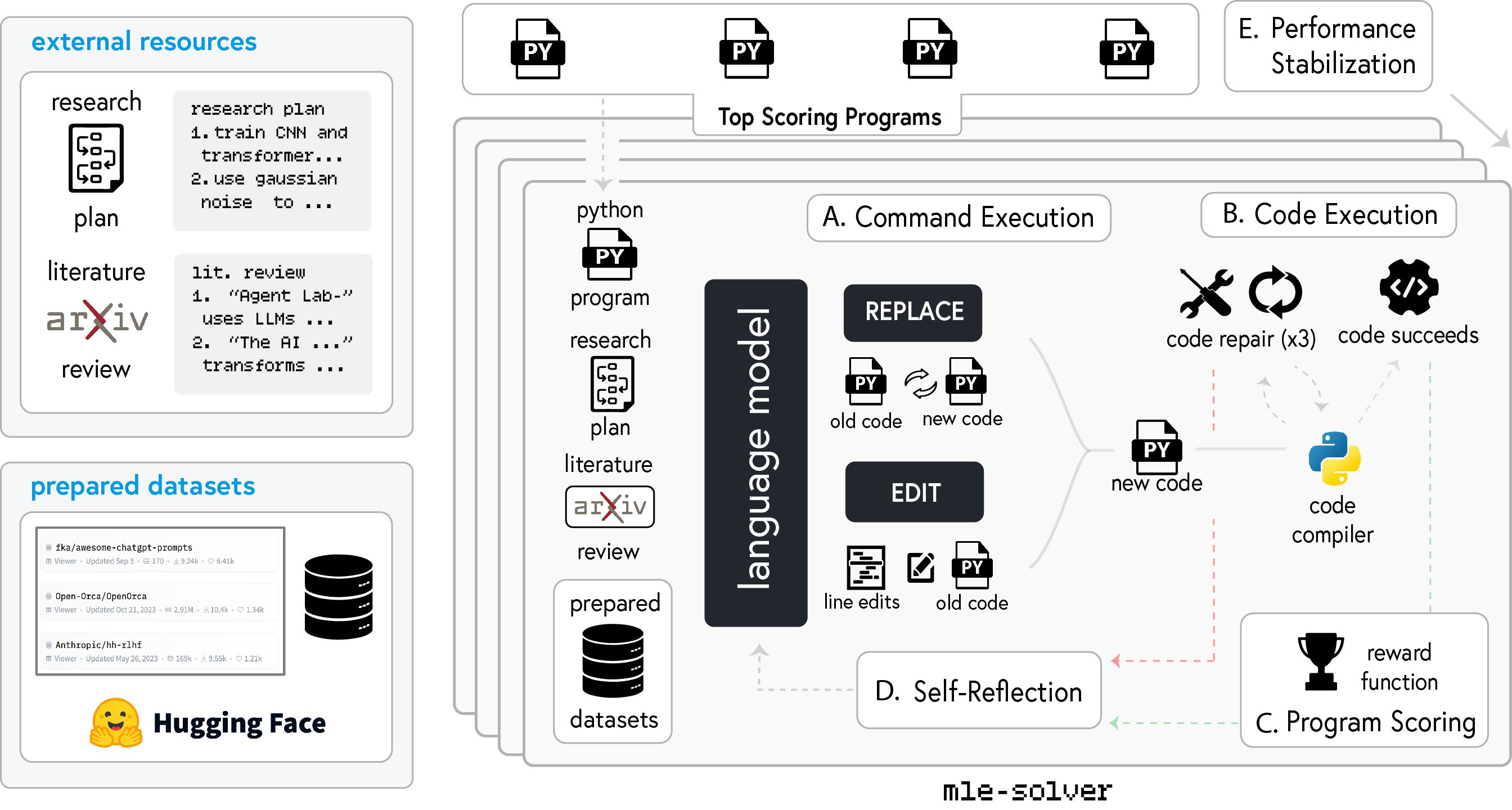
Fig3 (A), where new code is generated, followed by code execution (B) to compile and repair issues if needed. Program scoring (C) evaluates the generated code using a reward function, while self-reflection (D) helps refine future iterations based on results. Performance stabilization (E) ensures consistent outcomes by maintaining a pool of top-performing programs and iterative optimization.
A. Command Execution / 命令执行阶段
-
从高性能程序池中随机选取一个初始程序作为起点。
-
通过两种操作进行迭代优化:
-
EDIT:局部编辑(替换指定行号范围内的代码段)。
-
REPLACE:全文件替换(生成一个全新的 Python 文件)。
-
-
每次操作的目标是让代码输出更符合实验目标。
B. Code Execution / 代码执行阶段
-
执行生成的代码并编译,检查是否存在运行时错误。
-
若能正常编译,则计算得分并更新最优程序列表。
-
若编译失败,则尝试修复该程序,最多尝试 Nrep=3 次。
-
修复失败后弃用该程序,重新采样新的候选代码。
C. Program Scoring / 程序评分阶段
-
成功运行的代码会交给评分函数,判断其是否优于已有结果。
-
评分使用基于 LLM 的奖励模型(reward model),按 0–1 打分。
-
评估维度包括:
-
研究计划与代码实现的一致性;
-
输出结果与预期目标的符合度。
-
-
打分机制类似于 LLM reasoning tree(Yao et al., 2024)或 AIDE (Schmidt et al., 2024) 的自评机制,但这里更关注科研代码与实验目标的匹配,而非单纯准确率。
D. Self Reflection / 自我反思阶段
-
无论代码成功或失败,系统都会生成反思内容。
-
失败时,solver 反思并记录错误原因(例如编译错误),以指导下次修复;
-
成功时,solver 反思如何进一步提升得分。
-
这种反思机制源于 Renze & Guven (2024)、Shinn et al. (2024),旨在增强模型的自我改进能力。
-
反思记录用于下一轮优化,提高生成代码的稳健性与质量。
E. Performance Stabilization / 性能稳定阶段
-
目的:防止性能漂移(performance drift)。
-
采用两种机制:
-
Top Program Sampling(高分样本采样):
-
维护高分程序集合;
-
每次随机选择一个程序继续修改,确保探索与质量平衡。
-
-
Batch Parallelization(批量并行优化):
-
同时执行 N 次代码修改;
-
将最高得分的改进保留到候选集中,替换最低分的版本。
-
-
-
这两种策略共同实现高熵采样(高探索性)与高质量收敛之间的平衡。
Report Writing
In the report writing phase, the PhD and Professor agent synthesize the research findings into a comprehensive academic report. This process is facilitated by a specialized module paper-solver, which iteratively generates and refines the report.
这个模块最大的意义是解读之前的成果,而非直接帮你写好,因为很难直接达到写作的标准
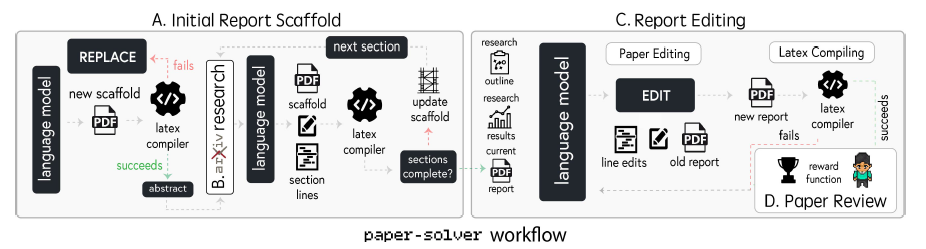
Fig.4 The workflow starts with the creation of an initial report scaffold (A) by iteratively generating LaTeX-based sections, followed by updates to ensure structural completeness. (B) Research is performed through an Arxiv tool during relevant sections. In the Report Editing phase (C), the language model applies targeted edits to improve the document, with LaTeX compilation verifying the integrity of changes. Finally, the completed report undergoes a reward-based evaluation during the Paper Review phase (D), ensuring alignment with academic standards and research goals.
Initial Report Scaffold
-
任务:生成论文的基础结构(scaffold)。
-
结构包括 8 个标准部分:Abstract、Introduction、Background、Related Work、Methods、Experimental Setup、Results、Discussion。
-
在每个章节中插入占位符(placeholders),以便后续内容填充。
-
scaffold 含有 LaTeX 格式要求,可直接编译与后续修改。
-
特别注意章节标题与内容格式需符合学术规范。
Arxiv Research
-
在搭建框架时,允许 paper-solver 调用 arXiv 数据库接口。
-
通过与早期文献综述阶段相同的接口扩展引用文献。
-
该步骤非强制,但能帮助系统找到合适的引用对象。
-
仍保留初始文献库访问权限,但可在此基础上扩展,以支持撰写特定研究主题的章节。
Report Editing
英文要点:
-
在 scaffold 建成后,系统进入编辑阶段。
-
使用专门的 EDIT 命令 进行行级修改,确保:
-
内容符合研究计划;
-
论证清晰;
-
格式正确。
-
-
每次编辑后重新编译 LaTeX,保证结构与语法无误。
-
通过多轮迭代提升逻辑连贯性、论述深度与整体学术质量。
Paper Review
-
为获得客观评分,系统使用改进的自动审稿系统(基于 Lu et al., 2024b)。
-
该系统模拟 NeurIPS 审稿流程,由 LLM-based agent 依据学术标准(原创性、质量、清晰度、重要性)生成评审意见。
-
该自动系统在 500 篇 ICLR 2022 OpenReview 数据上达到 65% 人类审稿一致率,并在 F1-score 上超过人类(0.57 vs. 0.49)。
-
论文中还展示了由 o1-mini 模型生成的实际审稿示例。


Paper Refinement
英文要点:
-
PhD agent 决定是否需要进一步修改或提交最终稿。
-
模拟 3 位审稿代理(reviewer agents),依据 NeurIPS 标准生成审稿反馈。
-
反馈维度包括:原创性(originality)、质量(quality)、清晰度(clarity)与重要性(significance)。
-
PhD agent 根据审稿结果决定是否回溯早期阶段(如实验或结果分析),进行针对性修订。
-
该阶段模拟真实的“学术修改循环”,直至论文达到高质量标准。
Result
因为是采用人工评估的所以就放个表,感兴趣的自己去看
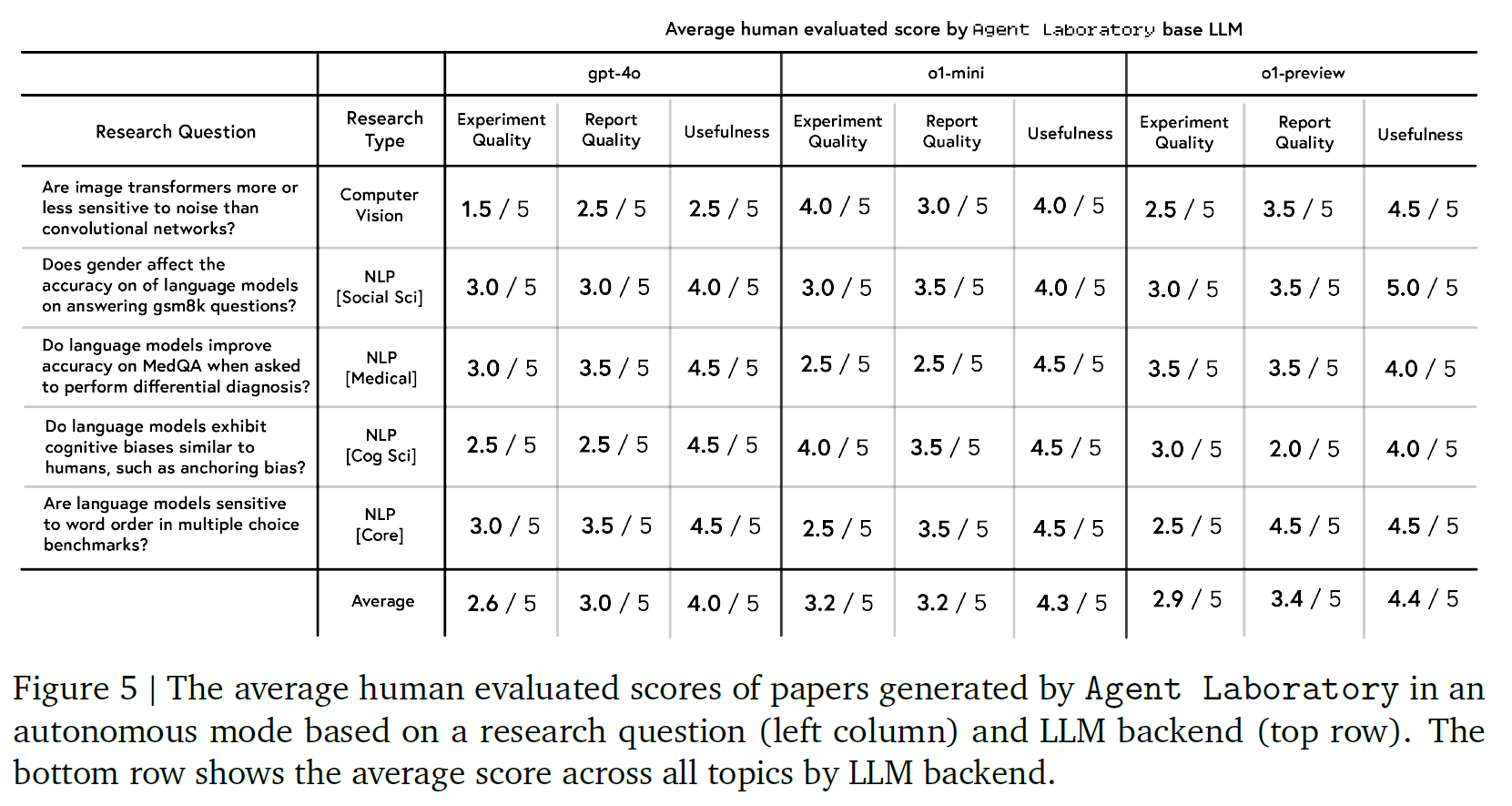
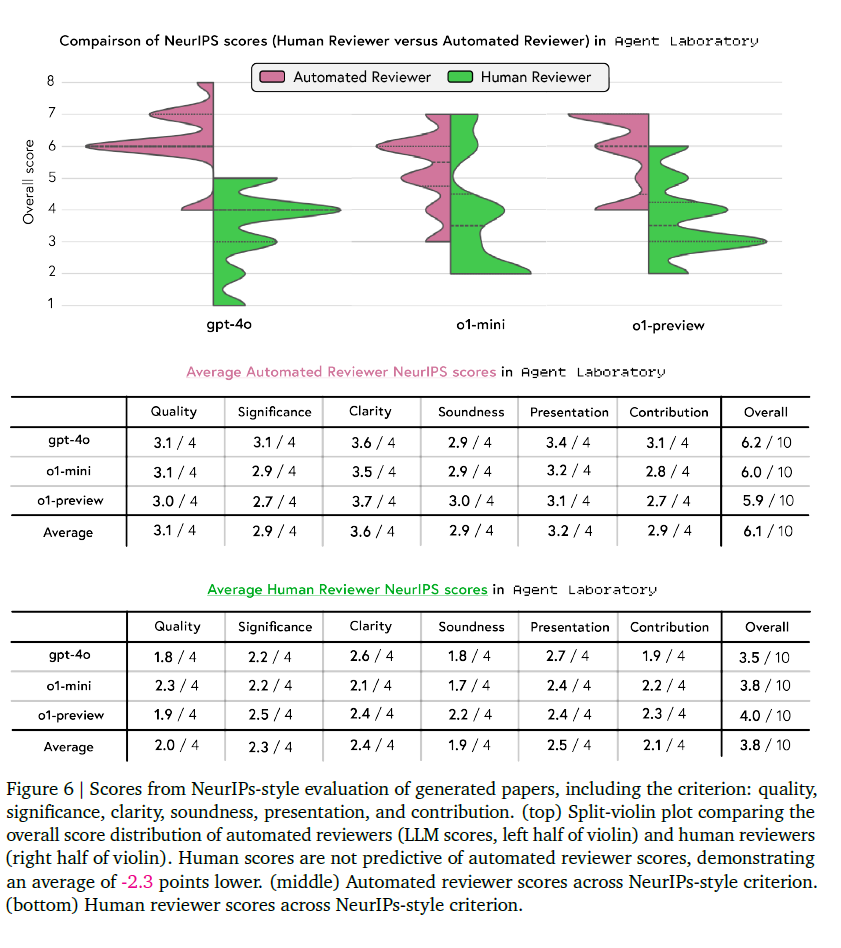
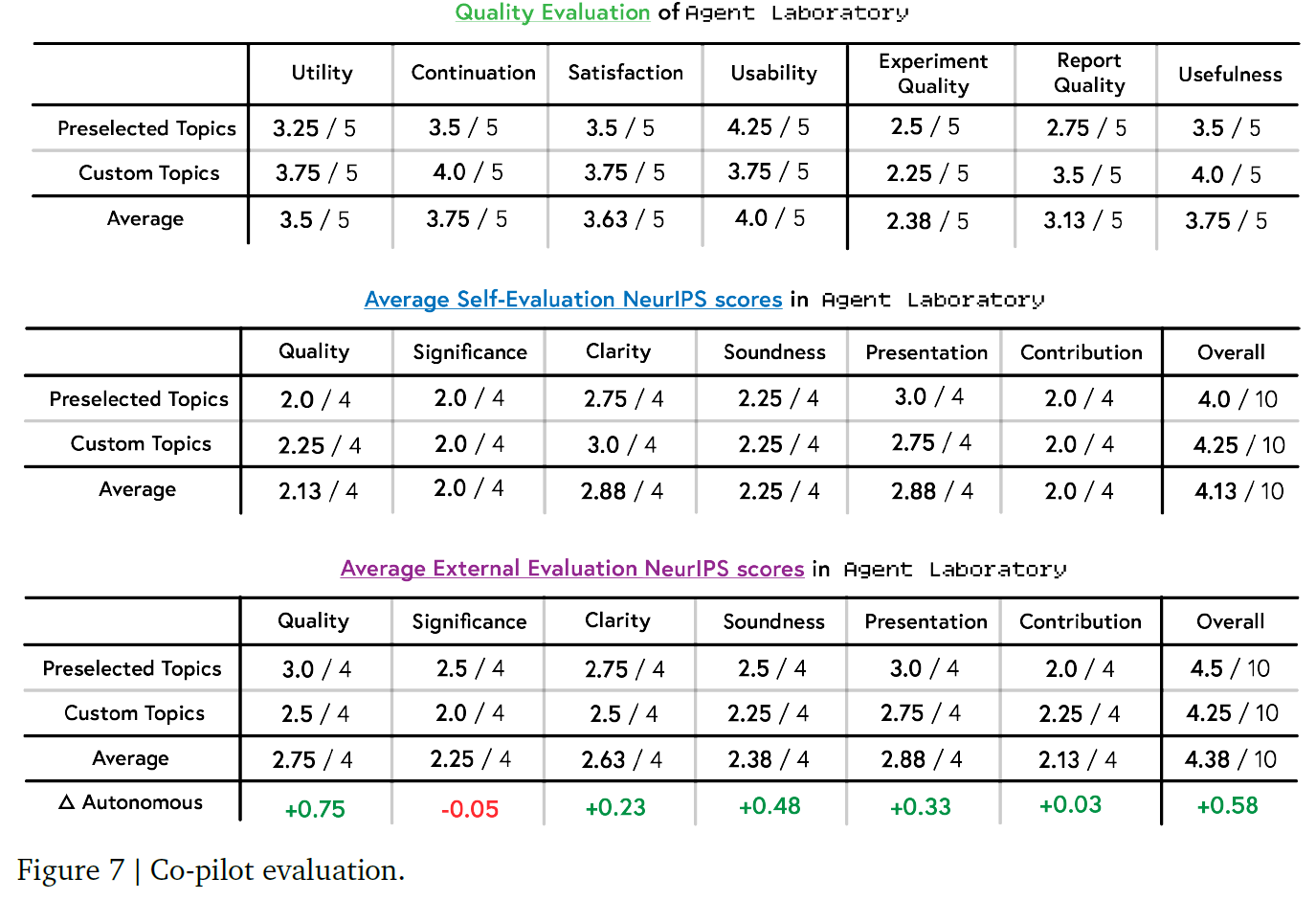
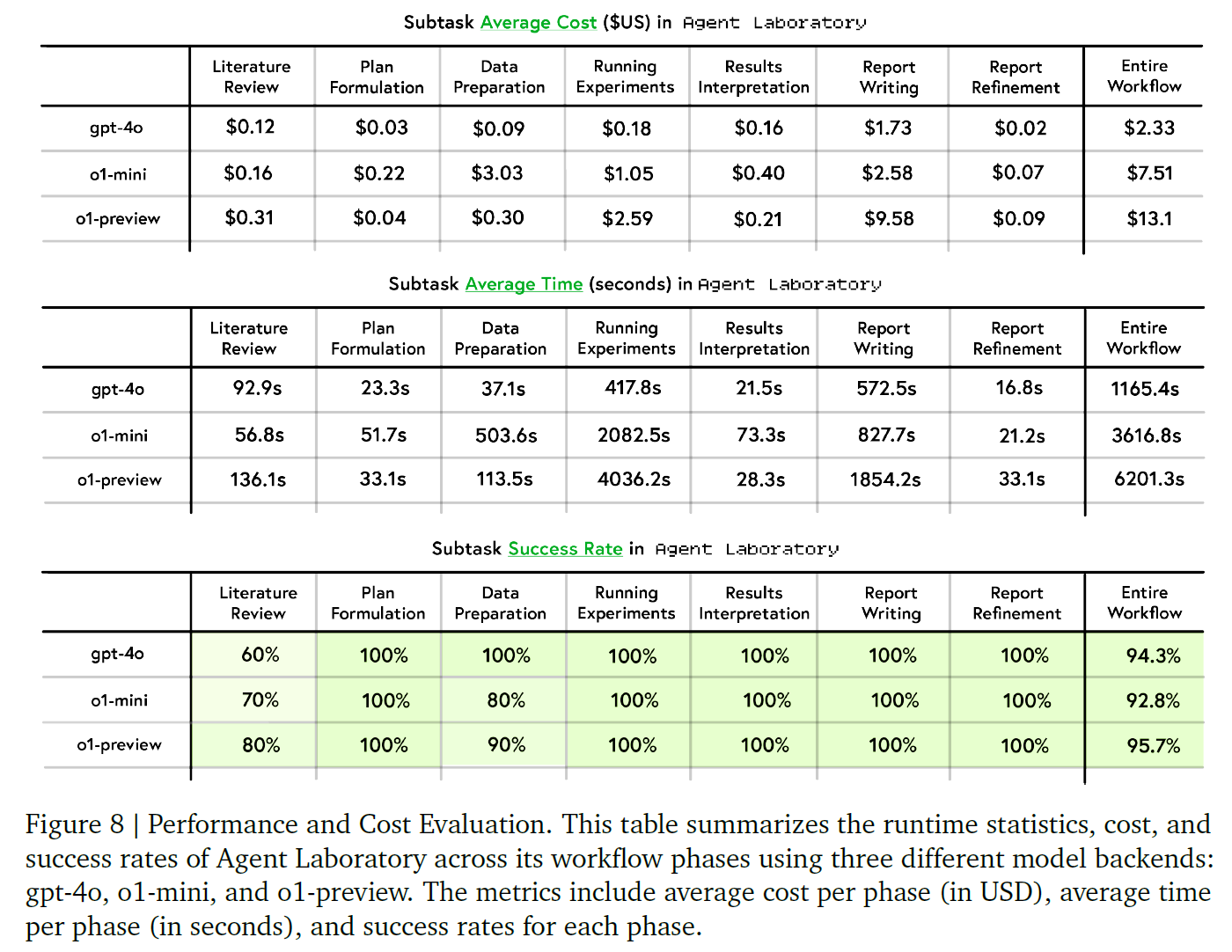
Limitations
Workflow limitations
Challenges with self-evaluation
-
paper-solver 的质量评估依赖 LLM 模拟的 NeurIPS 审稿人(Lu et al., 2024b)。
-
存在两大主要限制:
-
人工与自动评审结果不一致: 虽然自动评审与真实审稿的总体一致率较高(53.3% vs 56.1%),但 Agent Laboratory 生成的论文在人工评价中满意度较低。
-
研究报告定位不同: 系统生成的报告旨在总结实验成果,非完全取代科研写作流程,这与 The AI Scientist 等系统的目标不同。
-
-
模型在自评任务中表现不稳定:LLMs 往往依赖表层模式而非真正的学术评价标准,导致 LLM 评分与人类评分存在系统性偏差。
-
因此,LLM 在主观研究质量评价中的可靠性有限,影响了 mle-solver 与 paper-solver 的整体稳健性。
Challenges with automated structure
-
paper-solver 目前被约束在固定模板结构中(Abstract、Introduction、Methods 等)。
-
这种刚性结构降低了章节层级与论文组织方式的灵活性。
-
现阶段 mle-solver 与 paper-solver 仅支持生成 2 张图。
-
后续工作计划通过自动检测图像文件路径,使所有 mle-solver 生成的结果都能自由插入 paper-solver 输出。
-
当前系统还无法独立管理整个 repository 的文件,需人工提供路径;未来目标是实现灵活的仓库级文件修改与执行。
Challenges with hallucination
-
少数 LLM 生成的论文(尤其 gpt-4o 等较弱模型)出现实验结果幻觉。
-
示例:关于图像变换模型噪声敏感性的论文中,系统虚构了不存在的实验设置(学习率 0.001,batch size 32,epoch 50 等)。
-
这类问题虽不常见,但可能导致伪实验信息传播。
-
因此,后续研究需开发防幻觉机制以保障科研工具可信性。
Common failure modes
-
指令跟随失败(Literature Review 阶段)
-
大模型(gpt-4o、o1-mini、o1-preview)经常在执行文献综述任务时反复调用
summarize命令,直至达到最大步数后被迫终止。
-
-
Token 长度溢出
-
在文献检索过程中,检索结果超出模型上下文长度限制,导致后续分析被截断或不完整。
-
-
实验结果异常为 0% 准确率
-
mle-solver有时在全部测试任务中输出 0% 准确率,且在迭代结束前未能自动纠正。
-
-
代码编辑偏差
-
系统倾向于反复修改代码的第 0 行,易造成语法错误。
-
EDIT 换用
REPLACE可提高编译成功率。
-
-
输出导致 Token 溢出
-
实验日志或数据准备阶段的冗长输出易占满 token 上限,使模型无法继续生成分析结果。
-
-
生成退出命令
-
部分代码中出现
exit()指令,直接终止整个进程,需人工过滤。
-
-
系统命令调用风险
-
检测到个别代码通过
subprocess.run()调用系统命令,虽未出现安全问题,但建议未来增加沙箱保护。
-
-
arXiv 检索循环过长
-
paper-solver在调用 arXiv 引擎时,有时陷入长时间无效检索(最多达 100 次)。 -
后续通过设置最大 5 次重试限制解决了该问题。
-
Conclusion
总之,Agent Laboratory 是朝着更高效、以人为本的研究工作流程迈出的具有前景的一步,它充分利用了大型语言模型的力量。通过将具有特定功能的自主代理与人类监督相结合,我们的方法能够帮助研究人员减少在重复性任务上的花费,从而有更多时间投入到工作的创造性和概念性方面。我们希望 Agent Laboratory 最终能够成为一种工具,助力科学发现。