TCMalloc原理解析(下)
上章在TCMalloc的简介,介绍了TCMalloc中的核心结构,以及算法简介,但对其中大部分细节是没有说明的,本篇文章着重于在代码层面去讲解TCMalloc内存分配以及回收机制的核心原理,对于更多细节以及参数,由于博主研究的不够深,可以去知乎、CSDN等等的平台看看大佬们的文章,待博主研究后会出后续细节补充。
1. Common
1.1 Size Class
size class这个这个概念我们前面讲到它是用来划分内存大小的,而common.h 这个文件就记录着size class相关的信息。这个头文件中定义了许多内存划分相关的参数,也有对象怎么对齐size class的算法。
//common.h
//uintptr_t 无符号整数类型
typedef uintptr_t PageID;
typedef uintptr_t Length;// 每个线程缓存大小的下限 --256KB
static const size_t kMaxSize = 256 * 1024; // 256KB
static const size_t kMinThreadCacheSize = kMaxSize * 2;// 对于小内存占用情况,使整体线程缓存不超过单个线程的缓存大小。 -- 32MB
static const size_t kMaxThreadCacheSize = 4 << 20; // 4MB
#ifdef TCMALLOC_SMALL_BUT_SLOW
static const size_t kDefaultOverallThreadCacheSize = kMaxThreadCacheSize;
#else
static const size_t kDefaultOverallThreadCacheSize = 8u * kMaxThreadCacheSize; //32MBclass SizeMap {private:
// ...// 这里的KMaxSize是小内存的最大值--256KB,// 这个表达式实际上是在做向上取整的除法运算。加上127是为了在除以128时实现向上取整。// 计算class_array_数组需要的大小static const size_t kClassArraySize =((kMaxSize + 127 + (120 << 7)) >> 7) + 1;// 无符号字符数组,用于存储不同内存大小对应的大小类索引。unsigned char class_array_[kClassArraySize];//...//当size<=1024时,class的 index = (size + 7) >> 3static inline size_t SmallSizeClass(size_t s) {return (static_cast<uint32_t>(s) + 7) >> 3;}//当size>1024时,class的 index = (size + 127 + (120 << 7)) >> 7static inline size_t LargeSizeClass(size_t s) {return (static_cast<uint32_t>(s) + 127 + (120 << 7)) >> 7;}// ...
}
// ...当申请的的内存大小小于1024字节时,就按index = (size + 7) >> 3来映射,同理,大于的则按index = (size + 127 + (120 << 7)) >> 7来映射。
前面提到size class的划分,这部分逻辑在SizeMap::Init()函数中实现了。在这个初始化函数中,AlignmentForSize()划分了对齐边界
//common.h
static const size_t kClassSizesMax = 128;
// 记录每个Size Class对应的实际内存大小
int32_t class_to_size_[kClassSizesMax];
//记录每个Size Class申请的页数(如8KB页)
size_t class_to_pages_[kClassSizesMax];
//记录每个size class每次要批量移动的对象数
int num_objects_to_move_[kClassSizesMax];这三个数组是核心元数据结构,它们分别记录了size class的对象移动数量、对象大小和占用的页数,共同支撑了TCMalloc的高效内存分配和回收机制。只要在Span中拿到size class,就可以知道这个Span对应对象的大小,后续用于内存分配和回收。
// 相关变量 -- common.cc
static const size_t kPageSize = 1 << kPageShift; // 一页对齐8KB
static const size_t kAlignment = 8;
static const size_t kMaxSize = 256 * 1024; // 256KB
#if defined(TCMALLOC_ALIGN_8BYTES)
// 除非我们强制使用8字节对齐,否则我们使用至少16字节对齐以满足某些SSE类型的对齐要求。
// 记住,当使用16字节对齐时,由于对齐浪费了25%的空间。(例如,malloc 24字节将得到32字节)
static const size_t kMinAlign = 8;
#else
static const size_t kMinAlign = 16;// 动态调整对齐边界
static int AlignmentForSize(size_t size) {int alignment = kAlignment;if (size > kMaxSize) {// 大于kMaxSize时,将对齐限制为kPageSize。 -- 8KBalignment = kPageSize;} else if (size >= 128) {// 由于对齐,浪费的空间最多为1/8,即12.5%。alignment = (1 << LgFloor(size)) / 8; // 确定所需对齐的字节数} else if (size >= kMinAlign) {// 我们需要至少16字节的对齐以满足某些SSE类型的要求。alignment = kMinAlign;}// 最大对齐是页面大小对齐。if (alignment > kPageSize) {alignment = kPageSize;}CHECK_CONDITION(size < kMinAlign || alignment >= kMinAlign);CHECK_CONDITION((alignment & (alignment - 1)) == 0);return alignment;
}// 最大整数 log2(n) 的向下取整
static inline int LgFloor(size_t n)
{int log = 0; // 初始化对数值为0for (int i = 4; i >= 0; --i) { // 从高位到低位检查int shift = (1 << i); // 计算当前要检查的位移量:16, 8, 4, 2, 1size_t x = n >> shift; // 右移shift位,检查这些位是否存在if (x != 0) { // 如果右移后不为0,说明n大于等于2^shiftn = x; // 更新n为右移后的值log += shift; // 累加位移量到对数结果中}}ASSERT(n == 1);return log;
}
// 确保最小对齐为128字节
alignment = std::max(alignment, 128); 1.1.1 size class跨度
其定义的跨度为:
0 ~ kMinAlign(8/16字节):按KMinAlign大小对齐,例如size = 3 ->对齐到 size = KMinAlign。
kMinAlign ~ 128:跨度为16字节。25对齐到32。
128 ~ kMaxSize(256KB):按算法 (1 << LgFloor(size)) / 8对齐。LgFloor当成向下取整的log2(size)。例如↓
128 ~ 16KB:对齐到128,以130字节为例,LgFloor得到的数为7,计算
(1 << 7)>>3=16。alignment=max(16,128)=128,因此按128字节分配。16KB ~ 256KB(动态拓展):以17KB为例子,LgFloor得到的数为14,
(1<<14)>>3 =2048,alignment=max(2048,128)=2048,但Size Class可能会取最近的2的指数为步长(如16KB),因此实际对齐16KB;以此类推...
KMaxSize < ~:则按KMaxSize对齐。
1.1.2 size class对象大小调整
在SizeMap初始化,涉及到size class对象大小的调整,旨在减少内存碎片化,见代码:
// common.cc
void SizeMap::Init() {// ...for(;;){// ...int sc = 1; // 下一个要分配的size class// ...// 调整size class对象的大小const size_t my_pages = psize >> kPageShift;// 判断 my_pages是否等于前一个size class的页数if (sc > 1 && my_pages == class_to_pages_[sc-1]){// See if we can merge this into the previous class without// increasing the fragmentation of the previous class.// 如果我们可以将这个合并到前一个size class中而不增加前一个类的碎片化程度,看看是否可以const size_t my_objects = (my_pages << kPageShift) / size;const size_t prev_objects = (class_to_pages_[sc-1] << kPageShift)/ class_to_size_[sc-1];if (my_objects == prev_objects) // 判断my_objects是否等于前一个size class的对象数{// Adjust last class to include this size// 调整前一个size class的大小class_to_size_[sc-1] = size;continue;}}// Add new classclass_to_pages_[sc] = my_pages;class_to_size_[sc] = size;sc++;}// ...
} 这段代码的逻辑是:这次指向的size class对象(用sc表示),上一个size class对象(用sc - 1表示)
对比
sc与sc - 1对象所需的page数是否一样,若不一样跳过逻辑---设置sc;若一样↓对比
sc与sc - 1对象按size class所划分的对象数量是否相同,若不同跳过逻辑---设置sc;若相同↓将
sc - 1的size class大小调整为sc的size class大小,然后设置sc。
如下图↓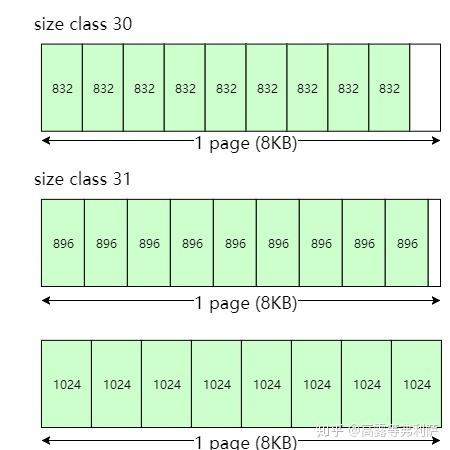
1.2 Page
在TCMalloc中Page是管理内存的基本单位,增大Page尺寸可提升分配速度(减少跨Page操作),但会增加内存碎片;减小Page尺寸则反之。使用大尺寸页面的优缺点↓
优点:使用大页面可以加快执行速度,但代价是更大的内存使用。释放速度可能会加快8倍,因为页面映射的8倍更小,所以页面映射的查找导致更少的L2缓存未命中,这转化为对于有高L2缓存压力的应用/平台组合的加速。
缺点:随着大页面的增加,我们增加线程缓存的配额,以避免将更多的空闲范围传递给中央列表和从中央列表传递。大页面更不容易被释放。两个因素导致内存使用的增加是有限的。
原话↓
// Using large pages speeds up the execution at a cost of larger memory use.
// Deallocation may speed up by a factor as the page map gets 8x smaller, so
// lookups in the page map result in fewer L2 cache misses, which translates to
// speedup for application/platform combinations with high L2 cache pressure.
// As the number of size classes increases with large pages, we increase
// the thread cache allowance to avoid passing more free ranges to and from
// central lists. Also, larger pages are less likely to get freed.
// These two factors cause a bounded increase in memory use.1.3 PageID
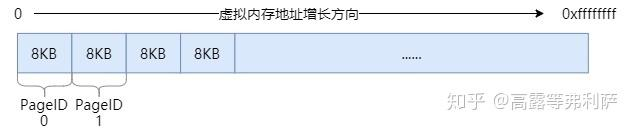
对于TCMalloc,整个虚拟空间的内存不过是一个个Page,从0x00开始,每个Page都可以通过计算得到它们的PageID。按照page对齐的大小(static const size_t kPageShift = 13; -- 8KB),将它进行位运算即可。const PageID p = reinterpret_cast<uintptr_t>(object) >> kPageShift;所以可以算的 object所在Page的PageID为: object >> 13。
2. Span 与 PageMap
2.1 Span
Span作为PegeHeap向操作系统申请内存的单位,它是由至少一个连续的物理页组成的内存块。
//span.h
struct Span {PageID start; // Starting page number -- 起始页号Length length; // Number of pages in span -- span中的页数Span* next; // Used when in link listSpan* prev; // Used when in link listunion {void* objects; // Linked list of free objects -- 用于链接空闲对象的链表// ...}// ...// span 所在的空闲链表:如果不在任何链表上,则为 IN_USE,否则为 normal 或 returnedenum { IN_USE, ON_NORMAL_FREELIST, ON_RETURNED_FREELIST };// 在normal链表,表示该Span内存块已释放但仍在TCMalloc的// 缓存体系中(如CentralCache或ThreadCache的空闲列表),可快速复用。// 在returned链表中,表示内存块已从缓存体系移除,归还到更底层的PageHeap或系统,// 处于“冷空闲”状态,可能被合并或释放回操作系统。
}Span内记录着它管理着的连续物理页的起始地址,也就是PageID。这里可以看到Span类中,还包含有链表指针,这里的链表指针是用于管理Span的,若Span存在于returned链表中,那么该Span的物理内存已经释放给操作系统,但它的虚拟地址仍然是可以访问的,等待可能的复用或彻底释放,不过在下一次访问时,会触发page fault(见Linux-11中缺页异常)以0来初始化这段内存,需要重新映射物理页,到后面会详细讲解。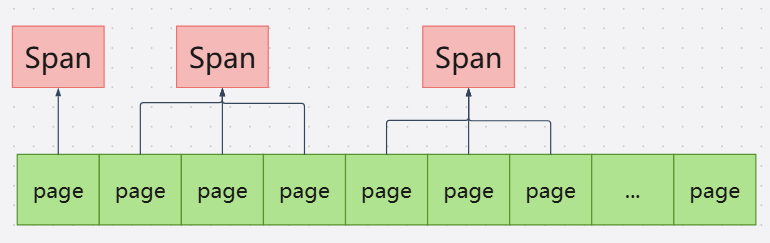
2.1.1 空闲链表
当中的链接空闲对象链表void* object。当Span被切割为多个小对象的时候,object指针就指向一个链表,它记录着整块内存的起始地址,其中内存块按size class进行切割,并且在每个小内存对象头部用指针将它们链接。
//central_freelist.cc
void CentralFreeList::Populate() {// Release central list lock while operating on pageheaplock_.Unlock();// 按size class来映射需要申请多少页const size_t npages = Static::sizemap()->class_to_pages(size_class_);// 申请spanSpan* span = Static::pageheap()->NewWithSizeClass(npages, size_class_);if (span == nullptr) {Log(kLog, __FILE__, __LINE__,"tcmalloc: allocation failed", npages << kPageShift);lock_.Lock();return;}ASSERT(span->length == npages);// 预先缓存sizeclass信息。不需要锁定。// (与其急于替换有关此span的任何过时信息,不如在实践中更好。)for (int i = 0; i < npages; i++) {Static::pageheap()->SetCachedSizeClass(span->start + i, size_class_);}// 将块拆分为多个部分并添加到空闲列表中// TODO: 对象着色以避免缓存冲突?void** tail = &span->objects;char* ptr = reinterpret_cast<char*>(span->start << kPageShift); // page块的首地址char* limit = ptr + (npages << kPageShift); // page块末尾地址const size_t size = Static::sizemap()->ByteSizeForClass(size_class_);int num = 0;// 当ptr接近地址空间顶部时,ptr + size可能会在超出limit之前溢出地址空间顶部。// 因此,我们需要小心。参见https://github.com/gperftools/gperftools/issues/1323。ASSERT(limit - size >= ptr);// for内这段就是切割Span内存为小内存对象的逻辑for (;;) {
#ifndef USE_ADD_OVERFLOWauto nextptr = reinterpret_cast<char *>(reinterpret_cast<uintptr_t>(ptr) + size);if (nextptr < ptr || nextptr > limit) {break;}
#else// Same as above, just helping compiler a bit to produce better codeuintptr_t nextaddr;if (__builtin_add_overflow(reinterpret_cast<uintptr_t>(ptr), size, &nextaddr)) {break;}char* nextptr = reinterpret_cast<char*>(nextaddr);if (nextptr > limit) {break;}
#endif// [ptr, ptr+size) bytes are all valid bytes, so append them*tail = ptr; // tail指向当前空闲块tail = reinterpret_cast<void**>(ptr); // tail指向下一个空闲块num++;ptr = nextptr;}ASSERT(ptr <= limit);ASSERT(ptr > limit - size); // same as ptr + size > limit but avoiding overflow*tail = nullptr;span->refcount = 0; // No sub-object in use yet// Add span to list of non-empty spanslock_.Lock();tcmalloc::DLL_Prepend(&nonempty_, span);++num_spans_;counter_ += num;
}切割的流程大致是:
初始化void **tail = &span->objects。指向Span->objects指针。
*tail(tail指向的指针)= ptr。让tail指向的指针,指向ptr(例如Span->objects = ptr)。
tail = ptr,让tail指向ptr。为下一次链接作准备。
ptr = nextptr,让ptr指向下一个空闲空间的首地址。
这样一个内存对象的首地址,就是本内存块的地址,解引用就是下个内存块的首地址,复用空闲对象的空间来构建链表。如图↓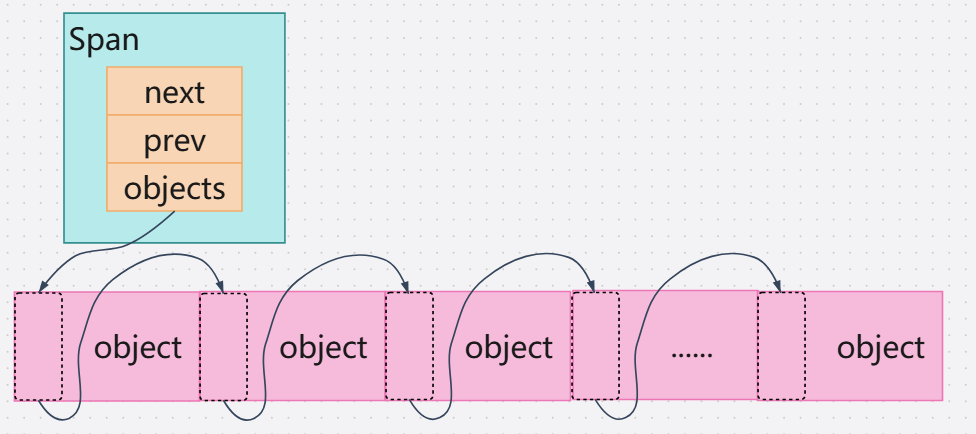
不过这个链表的顺序只是初始化时的顺序,在经过分配归还之后,肯定会乱,不过不需要担心其顺序,因为Span内记录着这整块内存的信息,只要object全部归还完毕,那么这块内存就是完整连续的。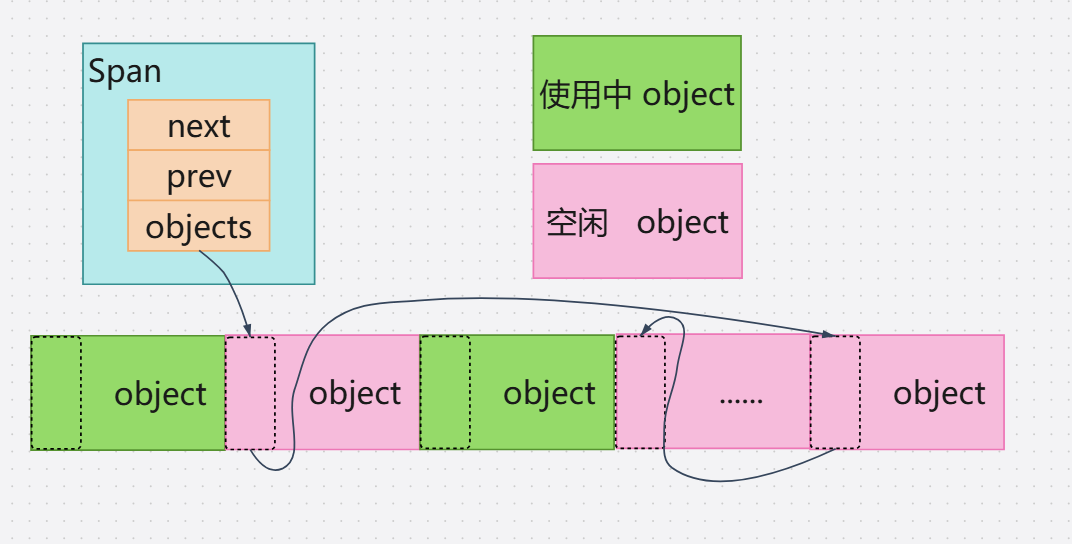
2.1.2 Span链表相关的操作
//span.h
// 初始化*list为一个空列表。
void DLL_Init(Span* list);// Remove 'span' from the linked list in which it resides, updating
// the pointers of adjacent Spans and setting span's next and prev to
// nullptr.
void DLL_Remove(Span* span);// Return true iff "list" is empty.
inline bool DLL_IsEmpty(const Span* list) {return list->next == list;
}// Add span to the front of list.
void DLL_Prepend(Span* list, Span* span);// Return the length of the linked list. O(n)
int DLL_Length(const Span* list);2.2 PageMap
在TCMalloc中,PageMap是一个关键的数据结构,它管理着每个page与Span的映射关系,通过存储每个page的PageID到所属Span的指针映射,来实现通过PageID快速定位到Span的操作。
PageMap采用Radix Tree(基数树)来优化性能。
在32位系统下,通常使用TCMalloc_PageMap2(二级基数树),根节点包含512个指针,每个叶节点管理1024个PageID,共覆盖219个页(对应32位地址空间)。
在64位系统下,则使用TCMalloc_PageMap3(三级基数树),将64位地址减去8KB页偏移(13位)和高16位未使用部分后,剩余35位分为12位、12位、11位,分别对应根、中间、叶节点,减少内存占用。
// pagemap.h // Two-level radix tree template <int BITS> class TCMalloc_PageMap2 {private:static const int LEAF_BITS = (BITS + 1) / 2;static const int LEAF_LENGTH = 1 << LEAF_BITS;static const int ROOT_BITS = BITS - LEAF_BITS;static const int ROOT_LENGTH = 1 << ROOT_BITS;// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // 子节点的指针void* (*allocator_)(size_t); // 内存分配器// ... }// Three-level radix tree template <int BITS> class TCMalloc_PageMap3 {private:// 每个内部节点消耗的位数static const int INTERIOR_BITS = (BITS + 2) / 3; // 向上取整static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;// 叶子节点消耗的位数static const int LEAF_BITS = BITS - 2*INTERIOR_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Interior nodestruct Node {Node* ptrs[INTERIOR_LENGTH];};// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Node root_; // Root of radix tree -- 基数树的根节点void* (*allocator_)(size_t); // Memory allocator -- 内存分配器// ... }以32位系统为例,如图↓
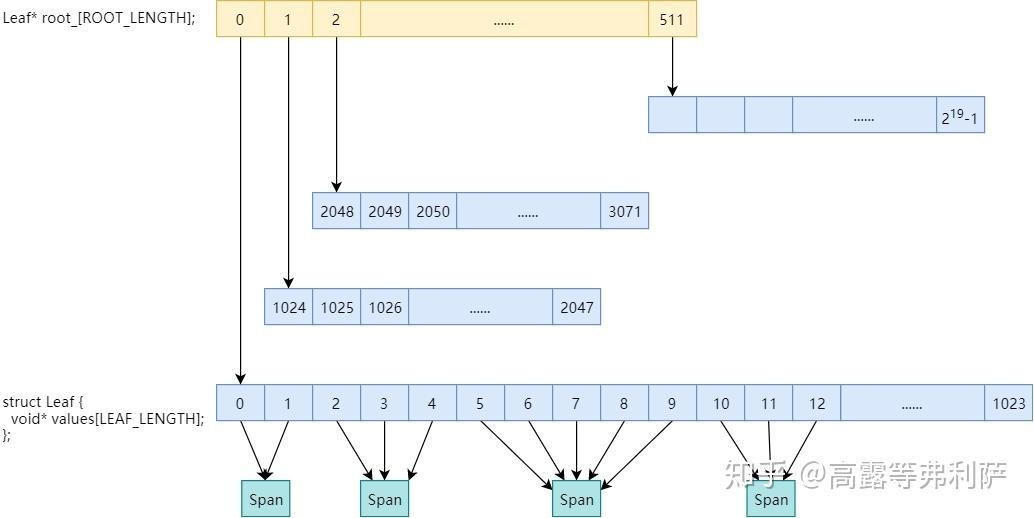
为什么使用基数树而不使用哈希表?
其中也可以用哈希表模拟,只是相比于基数树,哈希表并不适合TCMalloc对高性能且低延迟的需求,一方面哈希表在出现哈希冲突时,其时间复杂度会从O(1)退化到O(n),还有哈希表为了降低哈希冲突最好保持占有在70%以下,这会带来额外的内存开销,而且哈希桶通常随机分布在内存各处,会降低CPU的缓存命中率,对于频繁访问的TCMalloc显然会降低效率,基数树使用路径压缩、延时分配(到使用时才分配内存)等等的技术以及其有确定性的优势,所以TCMalloc中采用基数树。
3. PageHeap
PageHeap对于TCMalloc是唯一向系统申请内存供下层CentralCache以及ThreadCache使用的缓存层,向系统申请来的Span有相应的链表以及有序集进行管理。
//page_heap.h
// 通用选择器使用3级映射
template <int BITS> class MapSelector {public:typedef TCMalloc_PageMap3<BITS-kPageShift> Type;
};#ifndef TCMALLOC_SMALL_BUT_SLOW
// x86-64和arm64使用48位的地址空间。所以我们可以使用两级映射,
// 但由于这种模式下的初始ram消耗有点高,所以我们选择在
// TCMALLOC_SMALL_BUT_SLOW模式下禁用它。
template <> class MapSelector<48> {public:typedef TCMalloc_PageMap2<48-kPageShift> Type;
};#endif // TCMALLOC_SMALL_BUT_SLOW// A two-level map for 32-bit machines
template <> class MapSelector<32> {public:typedef TCMalloc_PageMap2<32-kPageShift> Type;
};class PageHeap {// ...typedef MapSelector<kAddressBits>::Type PageMap;PageMap pagemap_; // 管理PageID对应的Span// ...//空闲Span统计信息struct LargeSpanStats {int64_t spans; // Number of such spans -- Span的数量int64_t normal_pages; // Combined page length of normal large spans -- 正常span的长度int64_t returned_pages; // Combined page length of unmapped spans -- 返回span的长度};// ...//这个就是前面带过的normal和returned链表//normal是热空闲,returned是冷空闲struct SpanList {Span normal;Span returned;};SpanList free_[kMaxPages];// Span有序集,区分与上面类似,超过128KB的页面就会存在这SpanSet large_normal_;SpanSet large_returned_;// ...
}
//span.h
using SpanSet = std::set<SpanPtrWithLength, SpanBestFitLess, STLPageHeapAllocator<SpanPtrWithLength, void>>;
using SpanSetIter = SpanSet::iterator;PageHeap用下面这张图来表示应该更加好一点,虽有许多细节未画出。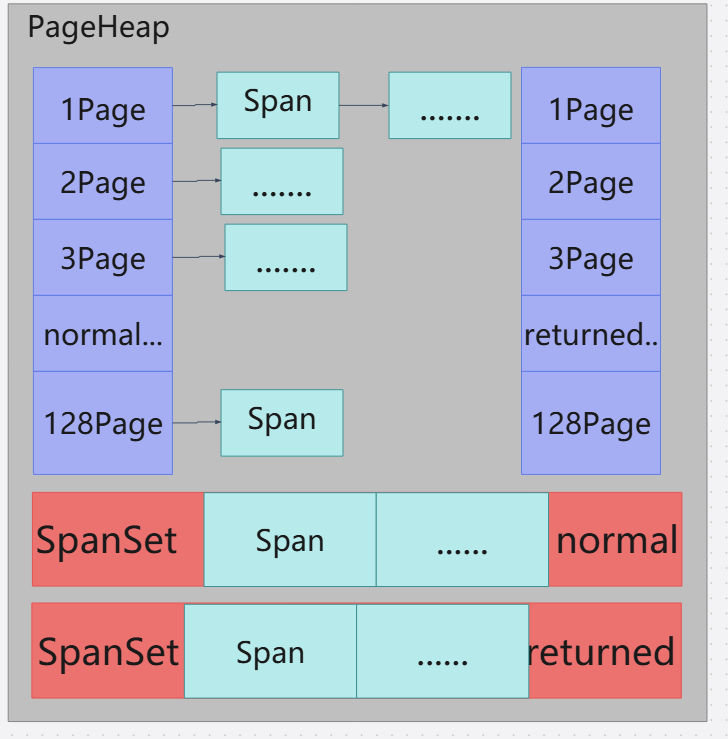
在PageHeap中,我可以通过设置环境变量FLAGS_tcmalloc_heap_limit_mb(默认为0,即不做限制)这个参数来限制PageHeap的大小,当开启这个设置之后,当PageHeap的内存接近这个值的时候,TCMalloc会更积极得去释放空闲内存给操作系统,在释放内存后,如果再次申请内存,会触发软分页错误(Minor Page Fault),即触发缺页中断,导致性能短暂下降。
函数:bool PageHeap::EnsureLimit(Length n, bool withRelease);
3.1 PageHeapAllocator
PageHeapAllocator是PageHeap模块中负责向系统申请内存的底层分配器,它提供了两个核心功能new以及delete。
page_heap_allocator.h
template <class T>
class PageHeapAllocator {public:// 初始化void Init() {ASSERT(sizeof(T) <= kAllocIncrement);inuse_ = 0;free_area_ = nullptr;free_avail_ = 0;free_list_ = nullptr;// 保留一些空间以避免碎片化。Delete(New());}// 分配对象T* New() {// Consult free listvoid* result;//如果空闲链表不为空,则从空闲列表中分配,头删if (free_list_ != nullptr) {result = free_list_;free_list_ = *(reinterpret_cast<void**>(result));} //如果空闲列表为空,则从free_area_中分配else {// 如果可用空间不足,则从chunk中获取内存到free_area_中再作分配,若chunk不够则向系统申请if (free_avail_ < sizeof(T)) {// 需要更多空间。我们假设MetaDataAlloc返回对齐的内存。free_area_ = reinterpret_cast<char*>(MetaDataAlloc(kAllocIncrement));if (free_area_ == nullptr) {Log(kCrash, __FILE__, __LINE__,"FATAL ERROR: Out of memory trying to allocate internal ""tcmalloc data (bytes, object-size)",kAllocIncrement, sizeof(T));}free_avail_ = kAllocIncrement;}result = free_area_;// 总空间增加free_area_ += sizeof(T);// 可用空间减少free_avail_ -= sizeof(T);}inuse_++;return reinterpret_cast<T*>(result);}void Delete(T* p) {
#ifndef NDEBUGmemset(static_cast<void*>(p), 0xAA, sizeof(T));
#endif// 头插到 free_list_中,p的下一个对象指向free_list_。*(reinterpret_cast<void**>(p)) = free_list_;free_list_ = p;inuse_--;}int inuse() const { return inuse_; }private:// 一次像系统申请的内存数(128KB)static const int kAllocIncrement = 128 << 10; //128KB// 从中划分新对象的空闲区域char* free_area_;size_t free_avail_;// 已经划分好的对象空闲列表void* free_list_;// 已分配但未释放的对象数量int inuse_;
};当PageHeapAllocator中的内存不足支持分配时,就会到MetaDataAlloc中申请内存,也就是向操作系统申请。有兴趣的可以到MetaDataAlloc中追踪函数调用。最后调的是mmap以及sbrk。
system_alloc.h
void* TCMalloc_SystemAlloc(size_t size, size_t *actual_size,size_t alignment) {// ...// 多态调用void* result = tcmalloc_sys_alloc->Alloc(size, actual_size, alignment);// ...
}// static allocators
class SbrkSysAllocator : public SysAllocator {
public:SbrkSysAllocator() : SysAllocator() {}void* Alloc(size_t size, size_t *actual_size, size_t alignment);
};
static tcmalloc::StaticStorage<SbrkSysAllocator> sbrk_space;class MmapSysAllocator : public SysAllocator {
public:MmapSysAllocator() : SysAllocator() {}void* Alloc(size_t size, size_t *actual_size, size_t alignment);
private:uintptr_t hint_ = 0;
};
static tcmalloc::StaticStorage<MmapSysAllocator> mmap_space;class DefaultSysAllocator : public SysAllocator {
public:// ...void* Alloc(size_t size, size_t *actual_size, size_t alignment);// ...
}3.1.1 sbrk
这里sbrk以及mmap是博主根据知乎大佬卡麦哈麦哈文章相关部分的讲解以及自己到网上查资料学习后得出的观点,可能有不严谨之处,若有错误请指出,这部分的图就借用知乎大佬卡麦哈麦哈的图(桀桀)。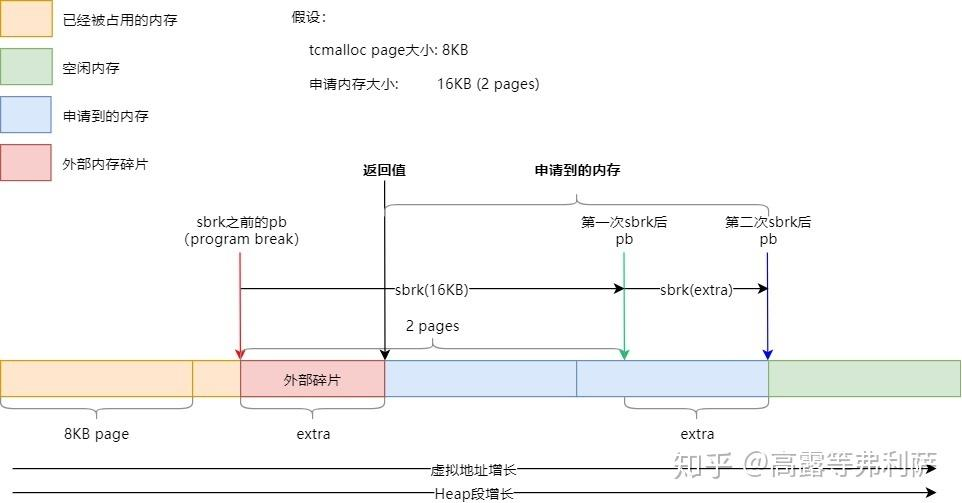
在TCMalloc中,sbrk向堆申请时,大部分情况的流程:假设在申请内存之前,pb(program break,堆的上边界)指向红色箭头所示位置,并没有内存对齐到以TCMaclloc page大小的page边界(TCMalloc page>= page)。
第一次申请16KB内存时,pb会移动到绿色箭头处。
在第一次申请后,pb的指向并没有按TCMalloc page对齐。所以要进行第二次sbrk,让pb指向蓝色箭头处,使其达到内存对齐的要求。
最后会返回黑色箭头指向的位置,也就是调整之后的16KB。
在进行二次sbrk后,在红色箭头以及黑色箭头之间就产生了一段内存,因为这段内存在上一个TCMalloc page中,并且那个TCMalloc page部分被占用,至使这段红色多出的内存无法使用,进而产生了内存外部碎片。
3.1.2 mmap
mmap的情况跟sbrk的情况差不多,若是没有对齐到TCMalloc page也是要进行调整,不过mmap过程中会调用两次munmap来清除因为对齐而产生的而外内存。
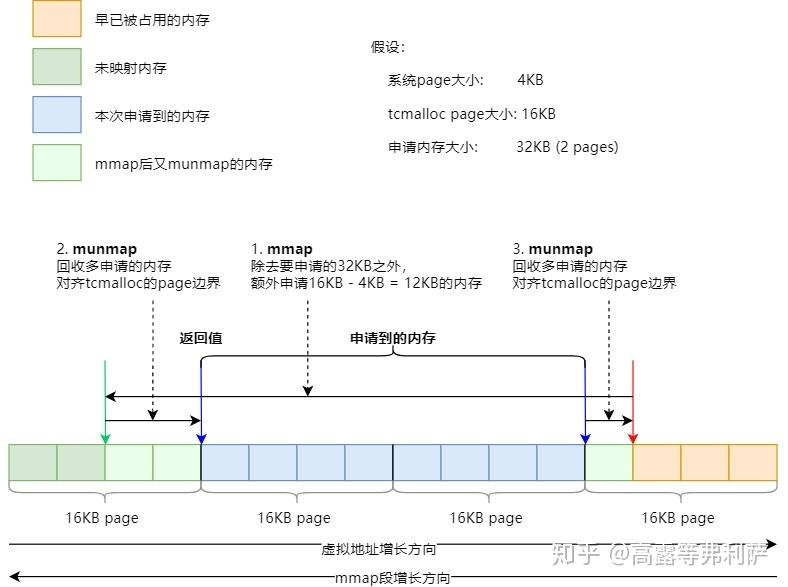
mmap的大致流程:一开始mmap段的边界指向红色箭头。
在第一次申请内存时,在原来申请的内存需求(32KB)上,再多申请:TCMalloc page大小 - 系统page大小,这里就是16KB - 4KB = 12KB(3个page),即mmap 35个page。
之后分别通过两次munmap将对齐后多余的内存回收掉。
最后返回蓝色箭头指向的已对齐的内存。
3.2 PageHeap中的内存分配流程
在介绍完PageHeap向系统申请内存的实现后,就可以来看在PageHeap这一层的内存分配流程了。
CentralCache对PageHeap的内存申请是开端,就从CentralFreeList::Populate() 开始。
central_freelist.h
class CACHELINE_ALIGNED CentralFreeList
{
public: // ...// 从page heap获取以填充缓存。// 可能临时释放锁。void Populate() EXCLUSIVE_LOCKS_REQUIRED(lock_);// ...
}
void CentralFreeList::Populate()
{// ...Span* span = Static::pageheap()->NewWithSizeClass(npages, size_class_);// ...
}
page_heap.h
class PageHeap
{
public:// ...// 前提是已经要分配的内存大小向上对齐了。// 分配“n”页的运行。如果内存不足,则返回零。// 调用者不应传递“n == 0”-相反,n应该已经向上取整了。Span* New(Length n) {return NewWithSizeClass(n, 0);}// ...
}3.2.1 PageHeap中的内存申请
当CentralCache中空闲Span不足,无法满足内存分配请求时,会向PageHeap发起内存申请。请求的单位为Span。
page_heap.cc
Span* PageHeap::NewWithSizeClass(Length n, uint32_t sizeclass) {LockingContext context{this, &lock_}; // 上锁// 申请内存Span* span = NewLocked(n, &context);if (!span) {return span;}//InvalidateCachedSizeClass(span->start); if (sizeclass) {// 存入基数树中,建立该Span与其内存储的page的PageID的映射关系RegisterSizeClass(span, sizeclass);}return span;
}Span* PageHeap::NewLocked(Length n, LockingContext* context) {ASSERT(lock_.IsHeld());ASSERT(Check());n = RoundUpSize(n); // 对齐大小Span* result = SearchFreeAndLargeLists(n);if (result != nullptr)return result;if (stats_.free_bytes != 0 && stats_.unmapped_bytes != 0&& stats_.free_bytes + stats_.unmapped_bytes >= stats_.system_bytes / 4&& (stats_.system_bytes / kForcedCoalesceInterval!= (stats_.system_bytes + (n << kPageShift)) / kForcedCoalesceInterval)) {// 如果堆中有大量空闲页面,但它们由不同类型的“段”组成,那么页面堆搜索就无法找到它们。// 为了避免增长堆并浪费内存,我们将取消映射所有空闲页面。// 这样,所有空闲跨度都是最大程度地合并的。// 我们还限制进入此路径的“速率”最多每128兆堆增长一次。// 否则,频繁增长堆的程序(这意味着增长小量)可能会因更高的次要页面错误而受到惩罚。// 有关详细信息,请参见large_heap_fragmentation_unittest.cc和https://github.com/gperftools/gperftools/issues/371。ReleaseAtLeastNPages(static_cast<Length>(0x7fffffff));// 然后再次尝试。如果我们因为大跨度碎片化而被迫增长堆,而不是因为上面描述的问题,// 那么至少我们已经将空闲但不够大的大跨度取消映射到操作系统。// 因此,在非常不幸的内存碎片化情况下,我们将消耗虚拟地址空间,而不是实际内存。result = SearchFreeAndLargeLists(n);if (result != nullptr) return result;}// Grow the heap and try again.// 扩容堆并再次尝试。if (!GrowHeap(n, context)) {ASSERT(stats_.unmapped_bytes+ stats_.committed_bytes==stats_.system_bytes);ASSERT(Check());// 底层SysAllocator可能设置了ENOMEM,但我们可以通过EnsureLimit进入这里。// 在这里再次设置它,以避免在快速路径中处理它。errno = ENOMEM;return nullptr;}// 因为要走相同的逻辑,所以直接再调一次。return SearchFreeAndLargeLists(n);
}
Span* span = NewLocked(n, &context);在NewLocked中,覆盖了大部分PageHeap中内存分配的流程。
链表和有序集查找
page_heap.cc
Span* PageHeap::SearchFreeAndLargeLists(Length n)
{ASSERT(lock_.IsHeld());ASSERT(Check());ASSERT(n > 0);// 找到第一个大小 >= n 并且列表非空的列表for (Length s = n; s <= kMaxPages; s++) {Span* ll = &free_[s - 1].normal;// 如果幸运的话,ll是非空的,意味着它有一个合适的span。if (!DLL_IsEmpty(ll)) {ASSERT(ll->next->location == Span::ON_NORMAL_FREELIST);return Carve(ll->next, n);}// 或者,可能有一个可用的返回span。ll = &free_[s - 1].returned;if (!DLL_IsEmpty(ll)) {// 在调用EnsureLimit之前,我们并没有调用EnsureLimit,以避免立即取回的span。// 在这里调用EnsureLimit并不昂贵,因为它只有在没有更多的正常span时才会失败(并且它失败得很快)// 或者SystemRelease不起作用(可能没有返回的span)。if (EnsureLimit(n)) // 我们没有对PageHeap设置限制,这段逻辑可以跳过{// 由于合并,ll可能已经为空if (!DLL_IsEmpty(ll)) {ASSERT(ll->next->location == Span::ON_RETURNED_FREELIST);return Carve(ll->next, n);}}}}// 在空闲列表中没有运气,我们最后的希望是在更大的类中。return AllocLarge(n); // May be nullptr
}在申请内存时,会先对齐内存大小,调用SearchFreeAndLargeLists(n);先去找Span链表中空闲Span,若是在Span链表中可以找到空闲的Span,就会调用Carve从PageHeap中分配Span。
在Carve中会将Span从链表中摘除,然后将这个Span设置为Span::IN_USE状态,之后分割Span,若Span较大,就会再创建一个Span来管理分割剩下的内存,再将这个Span的元信息记录下来,这个剩下的Span同样要链到原来Span所处状态链表(normal/returned),这个参数由Span中的unsigned int location : 2记录 。
若没有空闲的链表,就会调用AllocLarge到Span有序集中查找空闲的Span,而后会先到normal SpanSet中,用upper_bound查找合适的Span(在normal中查找会多设置一个best_normal),然后会到returned SpanSet中再查找一次(同样也是二分),然后比对normal和returned的Span,在可分配的前提下哪个更小,选取其中最小的。若是normal中的Span则直接去调用Carve,去切分Span;若是returnedSet中的Span,在没对PageHeap没作限制时,会走以下逻辑。
page_heap.cc
if (EnsureLimit(n, false)) {return Carve(best, n); // 优先尝试在不扩容的情况下分割最佳适配块
}if (EnsureLimit(n, true)) {// 若最佳适配块已被销毁(如被合并到更大的空闲块),需重试return AllocLarge(n); // 回退到分配大块内存
}如果作限制,直接返回nullptr。
一次内存的释放与合并
在找不到空闲的Span时,会向系统申请内存,在此之前会检查一遍条件,条件满足时,就可以避免向系统申请内存,而去释放所有空闲的内存ReleaseAtLeastNPages,:
TCMalloc中的空闲内存normal+returned的总数 >= 已申请总内存的1/4,并且申请内存达128MB(控制申请的内存在128MB可以避免申请内存过小,导致多次软缺页)。
page_heap.cc// 如果堆中有大量空闲页面,但它们由不同类型的“段”组成,那么页面堆搜索就无法找到它们。// 为了避免增长堆并浪费内存,我们将取消映射所有空闲页面。// 这样,所有空闲跨度都是最大程度地合并的。// 我们还限制进入此路径的“速率”最多每128兆堆增长一次。// 否则,频繁增长堆的程序(这意味着增长小量)可能会因更高的次要页面错误而受到惩罚。// 有关详细信息,请参见large_heap_fragmentation_unittest.cc和https://github.com/gperftools/gperftools/issues/371。ReleaseAtLeastNPages(static_cast<Length>(0x7fffffff));这个释放的过程,会把normal中的空闲Span也释放了,将部分normal中的空闲内存释放,转变它们的状态为returned,然后与其相邻的空闲页合并成更大的页。释放完后,会再执行一次result = SearchFreeAndLargeLists(n);去寻找合适的空闲页。
向系统申请内存
再进行内存释放后,仍无法分配Span,则会向系统申请,这里调用GrowHeap(n, context)来增加堆的空间,如果增加成功就会再走一次SearchFreeAndLargeLists(n),再次进入到链表和SpanSet中查找。
在GrowHeap(n, context)申请内存前,会先将申请的内存大小与kMinSystemAlloc(128KB)对比,若小于则申请内存的大小按kMinSystemAlloc,否则保持原样,内部会调用TCMalloc_SystemAlloc来申请内存。一次向系统要较大的内存,可以减少向系统申请的次数,提升分配时的效率。
TCMalloc_SystemAlloc(ask << kPageShift, &actual_size, kPageSize);在底层会调sbrk以及mmap,去申请内存。
page_heap.cc// 如果已经分配了大量的页面,那么就预先为页面映射分配一大块内存。// 这可以防止程序不断分配和释放大块内存时页面映射元数据导致的碎片化。if (old_system_bytes < kPageMapBigAllocationThreshold&& stats_.system_bytes >= kPageMapBigAllocationThreshold) {pagemap_.PreallocateMoreMemory();}↑预分配↑,对于32位系统而言,128MB确实时比较合理的阈值,可以执行预分配,但对64位系统来说,128MB着实是微不足道,因此可能不需要预分配,也许阈值更大。32位系统PageMap需覆盖2^19个8KB页(约16GB虚拟地址),预分配确保元数据存储连续,减少合并/查找时的边界检查开销。64位系统通过更复杂的radix树层级(如三级树)或压缩技术(如48位地址仅用低48位)减少元数据占用。
如果这里向系统申请失败,就返回nullptr。
3.2.2 PageHeap中的内存释放
同样这里会从CentralCache开始,void CentralFreeList::ReleaseToSpans(void* object)这个函数是CentralCache释放内存给PageHeap的起点。在ThreadCache归回内存时,CentralCache在将内存收回时,还会调用ReleaseListToSpans函数,而ReleaseListToSpans底层调的是ReleaseToSpans。
central_freelist.cc
void CentralFreeList::ReleaseToSpans(void* object) {const PageID p = reinterpret_cast<uintptr_t>(object) >> kPageShift;Span* span = Static::pageheap()->GetDescriptor(p);ASSERT(span != nullptr);ASSERT(span->refcount > 0);// 如果Span中的对象被耗尽,则将它链入非空闲链表中if (span->objects == nullptr) {tcmalloc::DLL_Remove(span);tcmalloc::DLL_Prepend(&nonempty_, span);}// ...// ...counter_++; // 空闲对象的数量span->refcount--; //span中的引用计数,为0时表示没有被使用if (span->refcount == 0) {counter_ -= ((span->length<<kPageShift) /Static::sizemap()->ByteSizeForClass(span->sizeclass));tcmalloc::DLL_Remove(span);--num_spans_;// 释放中央列表锁,同时操作PageHeap,归还Span对象lock_.Unlock();Static::pageheap()->Delete(span);lock_.Lock();} else {*(reinterpret_cast<void**>(object)) = span->objects;span->objects = object;}
}在内存归还到CentralCache中时,CentralCache会检查相应Span的引用计数,若引用计数为0,则表示已无内存被占用,则执行Static::pageheap()->Delete(span);将Span归还PageHeap。
而pageheap()->Delete(span)底层调的是PageHeap::DeleteLocked(Span* span)。
在回收时,会尝试合并前后空闲的处于相同状态(normal)的Span,回收合并的逻辑比较简单,看代码。
page_heap.cc
void PageHeap::DeleteLocked(Span* span) {// ...const Length n = span->length;span->sizeclass = 0;span->sample = 0;span->location = Span::ON_NORMAL_FREELIST;// 在将span回收时,会尝试合并SpanMergeIntoFreeList(span); // Coalesces if possibleIncrementalScavenge(n); // 累计回收页面的数量,达到一定数量后会释放内存// ...
}void PageHeap::MergeIntoFreeList(Span* span) {const PageID p = span->start;const Length n = span->length;if (aggressive_decommit_ && span->location == Span::ON_NORMAL_FREELIST) {if (DecommitSpan(span)) {span->location = Span::ON_RETURNED_FREELIST;}}Span* prev = CheckAndHandlePreMerge(span, GetDescriptor(p-1));if (prev != nullptr) {// 合并前一个SpanASSERT(prev->start + prev->length == p);const Length len = prev->length;DeleteSpan(prev);span->start -= len;span->length += len;pagemap_.set(span->start, span); // 修改映射关系}Span* next = CheckAndHandlePreMerge(span, GetDescriptor(p+n));if (next != nullptr) {// 合并后一个SpanASSERT(next->start == p+n);const Length len = next->length;DeleteSpan(next);span->length += len;pagemap_.set(span->start + span->length - 1, span);}PrependToFreeList(span);
}
调用以下即可。
MallocExtension::instance()->SetNumericProperty("tcmalloc.aggressive_memory_decommit", value)
可以将value设置1,来开启;0为关闭。
MallocExtension::instance()->SetNumericProperty("tcmalloc.aggressive_decommit", 1);首先会检查aggressive_decommit_是否开启,如果开启,在存在需要释放的Span并且刚来Span是NORMAL状态,会先释放这个span的物理内存,将其状态置为RETURNED,再去检查其前后的Span是否也是空闲且状态相同的Span,若是则合并。最后将这个处理好的Span重新链入NORMAL_LIST或者RETURNED_LIST,或放入SpanSet中管理起来。
Span的合并
规则:虚拟地址连续,所处的状态相同(normal合normal,returned合returned)。如下图。
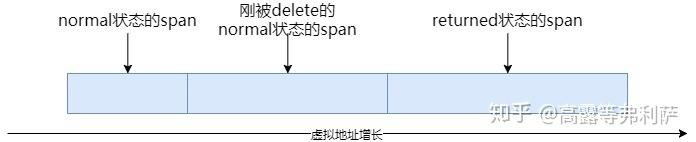

特别的,如果开启了aggressive_decommit_,normal回收时会将内存释放给系统,变为returned,在合并时会将相连的Span也释放,改为returned状态,然后合并。会变为下图↓
释放内存给系统
在TCMalloc有一个环境变量TCMALLOC_RELEASE_RATE,可以按释放page的频率来归还page给系统,在调用delete来归还Span时,会按频率触发ReleaseAtLeastNPages()。
TCMALLOC_RELEASE_RATE的取值范围为 0~10,0表示不释放,1表示回收1000page就释放1page给系统,2表示500释放1page,以此类推,数字越大,释放越快。
可能会有系统不支持,若系统支持,可以通过madvise(MADV_DONTNEED)来释放Span对应的内存,但虚拟地址保留,下次访问时会触发软缺页(minor page fault),用0来重新初始化空间。
释放规则:
从小到大循环,按顺序释放空闲span,直到释放的page数量满足需求。
多次调用会从上一次循环结束的位置继续循环,而不会重新从头(1 page)开始。
释放的过程中能合并span就合并span
可能释放少于num_pages,没那么多free的span了。
可能释放多于num_pages,还差一点就够num_pages了,但刚好碰到一个很大的span。
CentralCache和ThreadCache
4.1 CentralFreeList
CentralCache是CentralFreeList逻辑上的称呼,其本质还是CentralFreeList,这里central_cache_数组的大小为128。每个下标对应一个size class对象大小的桶,ThreadCache内存对象不够使用时就会到CentralFreeList中取,由于CentralFreeList是多个线程共用的,所以对它进行访问时也需要加锁。
static_vars.h
ATTRIBUTE_VISIBILITY_HIDDEN static CentralFreeList central_cache_[kClassSizesMax];
central_freelist.h
// 中央缓存中每个size class的数据。
class CACHELINE_ALIGNED CentralFreeList {public:constexpr CentralFreeList() {}void Init(size_t cl);// These methods all do internal locking.// 将指定的范围插入中央空闲列表中。N是范围中的元素数量。RemoveRange()是相反的操作。void InsertRange(void *start, void *end, int N);// 返回实际获取的元素数量,并设置*start和*end。int RemoveRange(void **start, void **end, int N);// 返回缓存中空闲对象的数量。int length() {SpinLockHolder h(&lock_);return counter_;}// 返回传输缓存中空闲对象的数量。int tc_length();// 返回归因于空闲列表的内存开销(内部碎片化)。// 这是元素大小不正好除以页面大小(8192字节的页面中填充了5字节的对象将有2字节的内存开销)时丢失的内存。size_t OverheadBytes();// 锁定/解锁内部SpinLock。在pthread_atfork调用中用于在fork之前将锁设置为一致状态。void Lock() EXCLUSIVE_LOCK_FUNCTION(lock_) {lock_.Lock();}void Unlock() UNLOCK_FUNCTION(lock_) {lock_.Unlock();}private:// TransferCache用于缓存给定大小类中thread caches和central cache之间// 的sizemap.num_objects_to_move(size_class)的来回传输。struct TCEntry {constexpr TCEntry() {}void *head{}; // Head of chain of objects. -- 链表中的头对象。void *tail{}; // Tail of chain of objects. -- 链表中的尾对象。};// 中央缓存空闲列表可以有0到kMaxNumTransferEntries个槽来放置链表链。
#ifdef TCMALLOC_SMALL_BUT_SLOW// For the small memory model, the transfer cache is not used.static const int kMaxNumTransferEntries = 0;
#else// 传输缓存中条目的最大数量起始点。给定大小类的实际最大值可能低于此最大值。static const int kMaxNumTransferEntries = 64;
#endif// 从缓存中移除对象并返回。// 如果缓存中没有空闲条目,则返回nullptr。int FetchFromOneSpans(int N, void **start, void **end) EXCLUSIVE_LOCKS_REQUIRED(lock_);// 从缓存中移除对象并返回。如果缓存为空,则从pageheap获取。仅在分配失败时返回nullptr。int FetchFromOneSpansSafe(int N, void **start, void **end) EXCLUSIVE_LOCKS_REQUIRED(lock_);// 将对象链表释放到span中。// 可能临时释放锁。void ReleaseListToSpans(void *start) EXCLUSIVE_LOCKS_REQUIRED(lock_);// 将对象释放到span中。// 可能临时释放锁。void ReleaseToSpans(void* object) EXCLUSIVE_LOCKS_REQUIRED(lock_);// 从page heap获取以填充缓存。// 可能临时释放锁。void Populate() EXCLUSIVE_LOCKS_REQUIRED(lock_);// 尝试为TCEntry腾出空间。如果缓存已满,它将尝试以牺牲其他缓存大小为代价扩展它。// 如果没有空间,则返回false。bool MakeCacheSpace() EXCLUSIVE_LOCKS_REQUIRED(lock_);// 从TCEntry槽中偷取一个“随机”SizeClass。实际上它只是遍历SizeClass,但不获取锁。// 成功时返回true。// 可能临时锁定一个“随机”SizeClass。static bool EvictRandomSizeClass(int locked_size_class, bool force);// 尝试缩小缓存。如果force为true,它将释放对象到span中,如果它允许缩小缓存。// 如果无法缩小缓存,则返回false。成功时减少cache_size_。// 可能临时获取锁。如果它获取锁,则释放locked_size_class锁,以防止线程同时持有两个SizeClass锁而导致死锁。bool ShrinkCache(int locked_size_class, bool force) LOCKS_EXCLUDED(lock_);// 这个锁保护所有数据成员。cached_entries和cache_size_可以在不持有锁的情况下查看。SpinLock lock_;// 我们持有空和非空span的链表。size_t size_class_{}; // My size classSpan empty_; // Dummy header for list of empty spans -- 空闲span的链表头Span nonempty_; // Dummy header for list of non-empty spans -- 非空闲span的链表头size_t num_spans_{}; // Number of spans in empty_ plus nonempty_ -- empty_和非空span的数量之和size_t counter_{}; // Number of free objects in cache entry -- 缓存条目中的空闲对象数量// 在这里我们为TCEntry缓存槽保留空间。为可能积累的最大条目数预分配空间。// 并非所有SizeClass都可以积累kMaxNumTransferEntries,因此对于这些大小类有一些浪费的空间。TCEntry tc_slots_[kMaxNumTransferEntries];// tc_slots_中当前使用的缓存条目数量。该变量在锁下更新,但可以不使用锁进行读取。int32_t used_slots_{};// 此SizeClass的当前槽位数。这是一个自适应值,如果给定SizeClass上有大量流量,则增加它。int32_t cache_size_{};// 给定SizeClass的缓存的最大大小。int32_t max_cache_size_{};
};
在CentralFreeList中,存在两个链表来管理从PageHeap中申请到的Span,一个是empty_,另一个是nonempty_,其中empty_存的是内存用完的Span(objects链表为空);nonempty_存的是内存有剩余的Span。
↓简单示意图↓

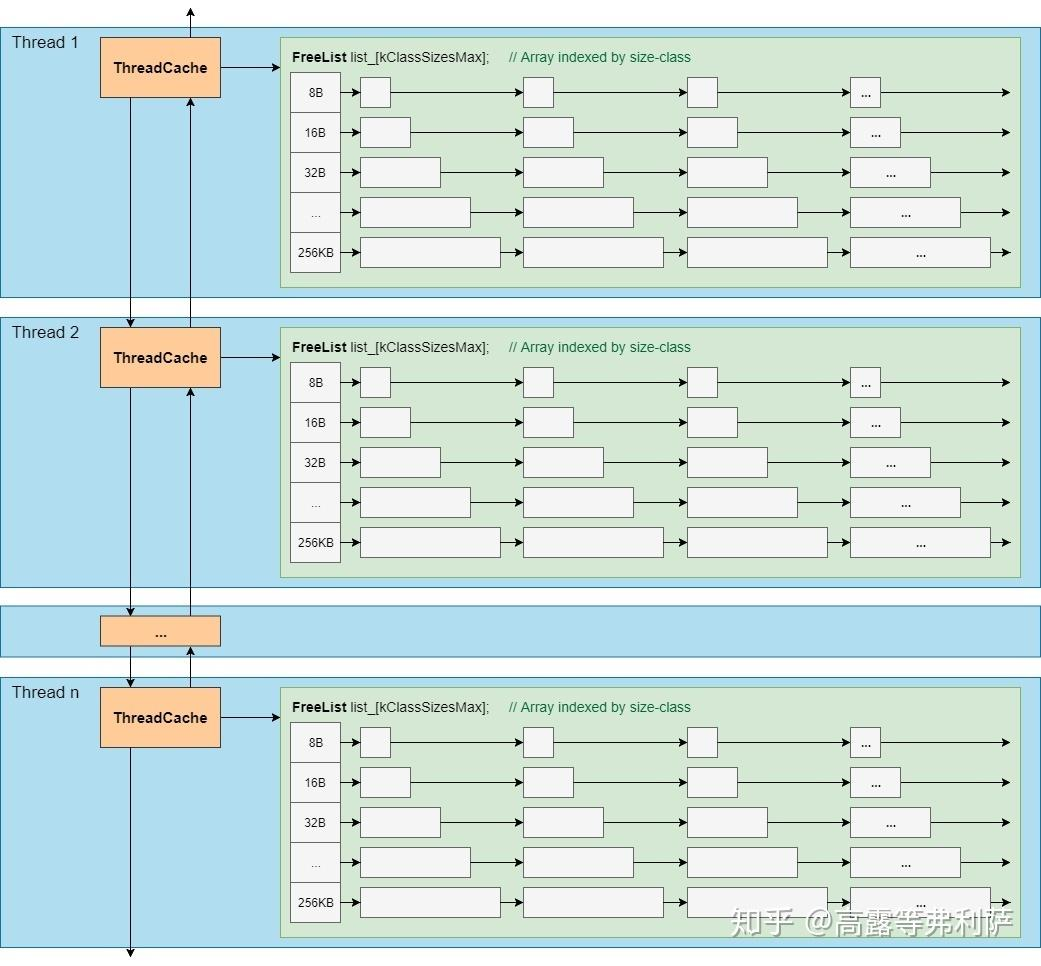
4.2 ThreadCache
ThreadCache就是每个线程都有一个的缓存,它的分配速度极快,无需加锁。在ThreadCache中维护了一个成员类FreeList,ThreadCache本质就是FreeList。快也就是快在每个线程都有一份ThreadCache,而这个就是通过Thread Local Storage(TLS)和Thread Specific Data(TSD)这两个技术实现的。TLS在线程结束时才会销毁,但默认不会触发析构函数或自定义清理逻辑,不过TSD技术支持析构和回调函数,在线程销毁时可以释放资源。TCMalloc中,TLS通过静态变量(如__thread关键字或编译器扩展_declspec(thread))为每个线程提供快速访问的副本,减少TSD的查找开销,而TSD可负责线程结束时的资源释放。
thread_cache.h
class ThreadCache
{// ...
private:// 内含空闲内存链表class FreeList {private:void* list_; // Linked list of nodes// ...}// ...// 这个类布局了最常用的字段,以便热元素被放置在同一个缓存行上。// 按size class划分的空闲链表FreeList list_[kClassSizesMax]; // Array indexed by size-class -- sizemap.h// ...
}每个ThreadCache都有一个FreeList数组,该数组按size class划分了每个内存对象的链表,在分配小对象时就优先在这里分配,等对应的size class空了之后才会到CentralFreeList对应size class的链表中申请内存。
这个链表也封装了相应的操作方法与CentralFreeList中的链表操作类似。源码贴出来了。
linked_list.h
// FIFO先进先出
// 获取t的下一个节点
inline void *SLL_Next(void *t) {return *(reinterpret_cast<void**>(t));
}// 设置n节点为t节点的下一个节点
inline void SLL_SetNext(void *t, void *n) {*(reinterpret_cast<void**>(t)) = n;
}// 将element链入list中,头插法
inline void SLL_Push(void **list, void *element) {void *next = *list;*list = element;SLL_SetNext(element, next);
}// 从list中取出第一个节点,并返回,头删法
inline void *SLL_Pop(void **list) {void *result = *list;*list = SLL_Next(*list);return result;
}inline bool SLL_TryPop(void **list, void **rv) {void *result = *list;if (!result) {return false;}void *next = SLL_Next(*list);*list = next;*rv = result;return true;
}// 从list中取出N个节点,并返回,头删法
inline void SLL_PopRange(void **head, int N, void **start, void **end) {if (N == 0) {*start = nullptr;*end = nullptr;return;}void *tmp = *head;for (int i = 1; i < N; ++i) {tmp = SLL_Next(tmp);}*start = *head;*end = tmp;*head = SLL_Next(tmp);// Unlink range from list.SLL_SetNext(tmp, nullptr);
}inline void SLL_PushRange(void **head, void *start, void *end) {if (!start) return;SLL_SetNext(end, *head);*head = start;
}inline size_t SLL_Size(void *head) {int count = 0;while (head) {count++;head = SLL_Next(head);}return count;
}每个ThreadCache也都用双向链表链接起来,方便统计信息和管理。
在线程第一次申请内存的时候,会调用ThreadCache::CreateCacheIfNecessary()来帮助线程创建ThreadCache。并且在线程创建初始化时,会通过pthread_key_create注册销毁函数ThreadCache::DestroyThreadCache(),在线程退出时,系统会自动调用函数释放ThreadCache占用的资源。
在ThreadCache中可以通过static void set_overall_thread_cache_size(size_t new_size);函数来设置ThreadCache的总大小(所有线程缓存的总和),实际是改变overall_thread_cache_size_,其取值范围为512KB ~ 1GB。
thread_cache.cc
// 设置线程总缓存大小
void ThreadCache::set_overall_thread_cache_size(size_t new_size)
{// Clip the value to a reasonable rangesize_t min_size = min_per_thread_cache_size_.load(std::memory_order_relaxed);if (new_size < min_size) {new_size = min_size;}if (new_size > (1<<30)) new_size = (1<<30); // Limit to 1GBoverall_thread_cache_size_ = new_size;RecomputePerThreadCacheSize();
}可以通过以下两个函数来修改线程单个缓存的上下限。只需修改第二个参数即可。其中限制为kMaxThreadCacheSize(4MB),在修改总缓存大小时,线程的大小限制在512KB到4MB间变化。
// 设置每个缓存大小的下限。
MallocExtension::instance()->SetNumericProperty("tcmalloc.min_per_thread_cache_bytes", kPerThreadCacheSize);// 设置最大总线程缓存大小为0,以确保将每个线程缓存大小设置为下限。
MallocExtension::instance()->SetNumericProperty("tcmalloc.max_total_thread_cache_bytes", 0);4.3 内存分配流程
4.3.1 ThreadCache到CentralCache
这里提到的内存分配覆盖ThreadCache到CentralCache的内存分配,因为它们的结构比较类似就放到一起了。
在ThreadCache分配小对象时,会调用ALWAYS_INLINE void* ThreadCache::Allocate()函数来分配内存对象。
ALWAYS_INLINE void* ThreadCache::Allocate(size_t size, uint32_t cl, void *(*oom_handler)(size_t size)) {// size是申请的内存块大小,cl是size class,oom_handler是内存分配失败时的回调函数FreeList* list = &list_[cl];#ifdef NO_TCMALLOC_SAMPLESsize = list->object_size();
#endifASSERT(size <= kMaxSize);ASSERT(size != 0);ASSERT(size == 0 || size == Static::sizemap()->ByteSizeForClass(cl));void* rv;// 输出型参数,尝试取内存对象if (!list->TryPop(&rv)) {// 没有空闲对象到CentralCache中申请内存对象return FetchFromCentralCache(cl, size, oom_handler);}size_ -= size;return rv;
}在向ThreadCache中取小对象时,会先到对应size class的链表中查找,如果有空闲的内存对象,会直接返回分配结束;若没有空闲的对象,就会调用FetchFromCentralCache到CentralCache中申请内存对象。
thread_cache.cc
// 从central cache中取出对象,并添加到thread heap中
void* ThreadCache::FetchFromCentralCache(uint32_t cl, int32_t byte_size,void *(*oom_handler)(size_t size)) {FreeList* list = &list_[cl];ASSERT(list->empty());const int batch_size = Static::sizemap()->num_objects_to_move(cl);const int num_to_move = std::min<int>(list->max_length(), batch_size);void *start, *end;int fetch_count = Static::central_cache()[cl].RemoveRange(&start, &end, num_to_move);if (fetch_count == 0) {ASSERT(start == nullptr);return oom_handler(byte_size);}ASSERT(start != nullptr);if (--fetch_count >= 0) {size_ += byte_size * fetch_count;list->PushRange(fetch_count, SLL_Next(start), end);}// 缓慢增加max_length,直到batch_size。// 之后,一次性增加batch_size,使长度为batch_size的倍数。if (list->max_length() < batch_size) {list->set_max_length(list->max_length() + 1);} else {// 不要让列表太长。在32位构建中,长度由16位int表示,所以我们需要注意整数溢出。int new_length = std::min<int>(list->max_length() + batch_size,kMaxDynamicFreeListLength);// 列表的max_length必须是batch_size的倍数,kMaxDynamicFreeListLength不一定是batch_size的倍数。new_length -= new_length % batch_size;ASSERT(new_length % batch_size == 0);list->set_max_length(new_length);}return start;
}这里涉及到要一次取多少个对象,batch_size会从num_objects_to_move_数组中拿到相应的量,num_to_move决定一次要从CentralCahe中获取多少个对象,这里时取list->max_length(), batch_size的最小值,其中的list->max_length()会在慢启动中讲到。
在这个获取对象的过程中还会涉及到TCEntry。为了优化分配速度,减少链表操作,tc_slots_按每个size class根据batch_size个对象的首尾指针存到TCEntry中,一般情况下,这样在取对象的时候只要O(1)的时间复杂度。
这里的源码需要的话可以看下。
central_freelist.h
class CACHELINE_ALIGNED CentralFreeList {// ...
private// TransferCache用于缓存给定size class中thread caches和central cache之间// 的sizemap.num_objects_to_move(size_class)的来回传输。struct TCEntry {constexpr TCEntry() {}void *head{}; // Head of chain of objects. -- 链表中的头对象。void *tail{}; // Tail of chain of objects. -- 链表中的尾对象。};// ...// 在这里我们为TCEntry缓存槽保留空间。为可能积累的最大条目数预分配空间。// 并非所有SizeClass都可以积累kMaxNumTransferEntries,因此对于这些size class有一些浪费的空间。TCEntry tc_slots_[kMaxNumTransferEntries];// ...
};
central_freelist.cc
int CentralFreeList::RemoveRange(void **start, void **end, int N) {ASSERT(N > 0);lock_.Lock();if (N == Static::sizemap()->num_objects_to_move(size_class_) &&used_slots_ > 0) {int slot = --used_slots_;ASSERT(slot >= 0);TCEntry *entry = &tc_slots_[slot];*start = entry->head;*end = entry->tail;lock_.Unlock();return N;}int result = 0;*start = nullptr;*end = nullptr;// TODO: Prefetch multiple TCEntries?result = FetchFromOneSpansSafe(N, start, end);if (result != 0) {while (result < N) {int n;void* head = nullptr;void* tail = nullptr;n = FetchFromOneSpans(N - result, &head, &tail);if (!n) break;result += n;SLL_PushRange(start, head, tail);}}lock_.Unlock();return result;
}4.3.2 CentralCache到PageHeap
当CentralFreeList中内存对象不够分配时,就会到nonempty_链表中去查找Span,来取出Span中管理的内存对象以分配给ThreadCache使用,再将内存对象耗尽的Span挂到empty_链表上。
在CentralFreeList中没有空闲Span或不足以满足分配需求时,就会调用CentralFreeList::Populate()到PageHeap中申请Span。这里的详细介绍见2.1.1空闲链表。
central_freelist.cc
void CentralFreeList::Populate() {// Release central list lock while operating on pageheaplock_.Unlock();const size_t npages = Static::sizemap()->class_to_pages(size_class_);Span* span = Static::pageheap()->NewWithSizeClass(npages, size_class_);// ...ASSERT(ptr > limit - size); // same as ptr + size > limit but avoiding overflow*tail = nullptr;span->refcount = 0; // No sub-object in use yet// Add span to list of non-empty spanslock_.Lock();tcmalloc::DLL_Prepend(&nonempty_, span);++num_spans_;counter_ += num;
}最后调度的是Static::pageheap()->NewWithSizeClass()到pageHeap中申请,详细见3.2.1PageHeap中的内存申请。
4.3.3 FreeList中的慢启动算法
FreeList的慢启动算法主要用于动态调整线程缓存(ThreadCache)的容量,通过指数增长策略逐步扩展缓存大小,平衡内存分配效率与资源占用。
在ThreadCache中,控制FreeList持有对象多少是很重要的:
若占有对象太少,就需要频繁向CentralCache申请,不够用。
若占有对象太多,就会导致大部分内存对象闲置,浪费空间。
所以内存分配就需要得到控制,因为操作CentralCache中的内存需要加锁,因此不能申请太少,也不可以申请过多。所以TCMalloc采用了慢启动算法与TCP中的拥塞控制算法(核心思想就是试探-反馈-调整,呈指数增长快速逼近网络容量)类似。
其中max_length的初始值为1,在申请内存时,若max_length小于batch_size就令其加1,若大于batch_size,就执行std::min<int>(list->max_length() + batch_size, kMaxDynamicFreeListLength)来限制其大小,来调整max_length的大小,最后执行new_length -= new_length % batch_size;使其为batch_size的整数倍。
central_freelist.cc
// 从central cache中取出对象,并添加到thread heap中
void* ThreadCache::FetchFromCentralCache(uint32_t cl, int32_t byte_size,void *(*oom_handler)(size_t size)) {FreeList* list = &list_[cl];ASSERT(list->empty());const int batch_size = Static::sizemap()->num_objects_to_move(cl);// ...// 缓慢增加max_length,直到batch_size。// 之后,一次性增加batch_size,使长度为batch_size的倍数。if (list->max_length() < batch_size) {list->set_max_length(list->max_length() + 1);} else {// 不要让列表太长。在32位构建中,长度由16位int表示,所以我们需要注意整数溢出。int new_length = std::min<int>(list->max_length() + batch_size,kMaxDynamicFreeListLength);// 列表的max_length必须是batch_size的倍数,kMaxDynamicFreeListLength不一定是batch_size的倍数。new_length -= new_length % batch_size;ASSERT(new_length % batch_size == 0);list->set_max_length(new_length);}return start;
}4.4 内存释放流程
同分配覆盖的范围一样。
当ThreadCache中的内存大小超过max_size_,就会触发垃圾回收机制。不过这是在ThreadCache中FreeList释放内存时,也就是在调用ThreadCache::Deallocate时,才会触发ListTooLong函数,满足条件后就会触发垃圾回收机制。之后会遍历所有的FreeList,将一些空闲的对象交换给CentralCache。
thread_cache.cc
void ThreadCache::ListTooLong(FreeList* list, uint32_t cl)
{// ...if (PREDICT_FALSE(size_ > max_size_)){Scavenge();}
}4.4.1 ThreadCache释放小对象
当调用Deallocate时,检测到ThreadCache中内存对象过多就会调用ListTooLong函数,将部分空闲的对象交换给CentralFreeList。
thread_cache.h
ALWAYS_INLINE void ThreadCache::Deallocate(void* ptr, uint32_t cl) {ASSERT(list_[cl].max_length() > 0);FreeList* list = &list_[cl];// 这会捕获同一size class中的连续释放。// 一个更全面(且昂贵)的测试是遍历整个空闲列表。// 但这可能足以找到一些错误。ASSERT(ptr != list->Next());uint32_t length = list->Push(ptr);if (PREDICT_FALSE(length > list->max_length())) {ListTooLong(list, cl);return;}size_ += list->object_size();if (PREDICT_FALSE(size_ > max_size_)){Scavenge();}
}void ThreadCache::ListTooLong(FreeList* list, uint32_t cl) {size_ += list->object_size();const int batch_size = Static::sizemap()->num_objects_to_move(cl);// 将freelist中的内存释放回central cache中ReleaseToCentralCache(list, cl, batch_size);// 如果freelist太长,我们需要将一些对象转移到central cache中。// 理想情况下,我们会转移num_objects_to_move个对象,所以下面的代码试图使max_length收敛到num_objects_to_move。// ThreadCache慢启动算法if (list->max_length() < batch_size) {// 缓慢启动max_length,以免过度预留。list->set_max_length(list->max_length() + 1);} else if (list->max_length() > batch_size) {// 如果我们总是超过max_length,就缩小max_length。如果我们不缩小它,一些内存将始终保留在这个freelist中。list->set_length_overages(list->length_overages() + 1);if (list->length_overages() > kMaxOverages) {ASSERT(list->max_length() > batch_size);list->set_max_length(list->max_length() - batch_size);list->set_length_overages(0);}}if (PREDICT_FALSE(size_ > max_size_)) {Scavenge();}
}其中ListTooLong会去调用ReleaseToCentralCache()来将空闲对象释放给CentralFreeList。如果缓存太大,依旧会触发垃圾回收机制,将部分空闲内存释放。
4.4.2 CentralFreeList中内存的释放
在Span中维护一个变量为refcount,表示Span中的对象被ThreadCache引用了多少。当这个变量为0时,表示这个Span的内存已经全部归还。CentralCache就会把这个对象释放给PageHeap。之后会调用PageHeap中的Delete函数来释放内存。详细见3.2.2PageHeap中的内存释放。
central_freelist.cc
void CentralFreeList::ReleaseToSpans(void* object) {const PageID p = reinterpret_cast<uintptr_t>(object) >> kPageShift;Span* span = Static::pageheap()->GetDescriptor(p);ASSERT(span != nullptr);ASSERT(span->refcount > 0);// 如果Span中的对象被耗尽,则将它链入非空闲链表中if (span->objects == nullptr) {tcmalloc::DLL_Remove(span);tcmalloc::DLL_Prepend(&nonempty_, span);}// ...counter_++;span->refcount--;if (span->refcount == 0) {counter_ -= ((span->length<<kPageShift) /Static::sizemap()->ByteSizeForClass(span->sizeclass));tcmalloc::DLL_Remove(span);--num_spans_;// 释放中央列表锁,同时操作PageHeaplock_.Unlock();Static::pageheap()->Delete(span);lock_.Lock();} else {*(reinterpret_cast<void**>(object)) = span->objects;span->objects = object;}
}
到此就将核心部分都讲完了,若有错误可指出,会修正,当博主学到更多,也会出文章补充。