统一日志管理架构设计
统一日志管理架构设计
本文将从源头手把手的教你如何一步步的搭建日志管理系统,用来统一管理企业各个系统的日志。本文中的配置可以一并复制直接使用,均已经验证过。
涉及到的工具如下:
日志存储:ElasticSearch 8.19
日志查询展示:Kibana 8.19
日志抽取工具:Logstash/FileBeat 8.19
日志输出
系统日志
通常是操作系统输出的日志,中间件输出的日志,例如Nginx、Tomcat、MQ服务、Redis服务等等,不同的系统会输出不同格式的日志。需要根据其配置,设置合理的输出路径和输出格式即可。由于不同的服务日志格式差异很大,这里不一一列举。
Java项目日志
与系统日志不同,项目日志的可控制性比较大,灵活性也比较大,因此需要遵循一定的原则,否则会导致各种问题。
统一输出格式
日志输出格式尽量带上关键的完整信息,并且容易分割,后续需要用工具对日志进行解析并拆分成各自的字段,可直接使用如下logback-spring.xml配置:
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="false"><springProperty name="applicationName" scope="context" source="spring.application.name"/><property name="log.path" value="/var/local/service-name"/><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %level [${applicationName},%X{traceId:-},%X{spanId:-}] %logger{50} %M:%line - %msg%n</pattern></encoder></appender><appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/service-name.log</file><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %level [${applicationName},%X{traceId:-},%X{spanId:-}] %logger{50} %M:%line - %msg%n</pattern><charset>UTF-8</charset></encoder><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${log.path}/service-name.%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxFileSize>50MB</maxFileSize><maxHistory>90</maxHistory><totalSizeCap>20GB</totalSizeCap></rollingPolicy><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>INFO</level></filter></appender><appender name="asyncAppender" class="ch.qos.logback.classic.AsyncAppender"><appender-ref ref="file" /><neverBlock>true</neverBlock><queueSize>2048</queueSize></appender><root level="${logging.level.root:-INFO}"><appender-ref ref="console"/><appender-ref ref="asyncAppender"/></root></configuration>
配置有几点注意事项:
- 使用了异步日志输出:在系统被直接杀死的时候可能会丢失部分日志,但是性能较好。
- %X{traceId:-},%X{spanId:-} 链路配置信息:方便在微服务架构中,获取完整的日志链路信息,后续会具体讲解。
- 尽量保持统一的输出格式,方便一起采集。
链路信息
如何给Springboot项目的日志增加链路配置信息,只需要2步即可实现:
- 增加maven配置
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-tracing-bridge-brave</artifactId></dependency>
- 增加上一步的logback配置,就可以看到日志会输出链路日志,格式如下:
2025-10-26 12:03:37.188 [http-nio-8080-exec-1] INFO [TraceDemo,68fd9d99873d8398d0c19822dc6c6416,d0c19822dc6c6416] com.pxd.tracedemo.controller.HelloController sayHello:13 - Hello World
68fd9d99873d8398d0c19822dc6c6416:对应logback中配置的traceId变量。
d0c19822dc6c6416:对应logback中配置的spanId变量。
对于traceId和spanId的含义,请大家自行搜索,这里不过多介绍,主要用traceId来标记一个请求经过了多个微服务后,可以将所有的日志串联起来,日志汇聚后方便排查问题。
日志汇聚
日志输出好了之后,这一步就是将日志统一汇聚到ES中。
工具介绍:
filebeat:采集日志并传输给LogStash。
logstash: 接受filebeat的日志,并存储到ES中。
Filebeat配置
这里以springboot项目输出的日志为例,使用FileBeat工具来采集日志,FileBeat的配置文件如下:
filebeat.inputs:- type: logenabled: truepaths:- /var/local/service_name/*.logfields:logType: java-log #新增字段用来区分日志类型,方便后续解析的时候过滤env: prod #新增字段用来标记测试环境:test、正式环境:prodproject: hr #新增字段用来标记项目名fields_under_root: truemultiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}' # 用来将多行日志合并成一行multiline.negate: truemultiline.match: after
#============================= Filebeat modules ===============================
filebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: true# ============================== logstash =====================================
output.logstash:hosts: ["localhost:5044"] #将采集到的日志输出到logstash中enabled: true
注意:
- Filebeat可以在每台服务器上启动一个即可,用来汇聚服务器上面的所有日志。
- multiline配置是用来将多行的异常日志合并成一行处理,方便后续的查询。
- fields配置用来新增字段
Logstash配置
logstash配置/etc/logstash/conf.d/logstash.conf如下:
# 1. 输入模块:接收来自Filebeat的日志
input {beats {port => 5044}
}filter {# 步骤1:使用grok解析单行日志(根据实际日志格式编写正则)if [logType] =="java-log" {grok {# 定义匹配规则:时间 级别 [服务名] 内容match => {"message" => '%{TIMESTAMP_ISO8601:log_time} \[%{DATA:thread}\] %{DATA:level} \[%{DATA:app_name},%{DATA:trace_id},%{DATA:span_id}\] %{JAVACLASS:class} %{JAVAMETHOD:method}:(%{NUMBER:line}) - (?m)%{GREEDYDATA:msg}'}# 若匹配失败,添加标签标记(便于后续排查)tag_on_failure => ["_grokparsefailure"]remove_field => ["message", "event.original", "ecs.version"]}
}# 步骤2:将解析出的log_time转换为ES的@timestamp字段(统一时间格式)date {match => ["log_time", "yyyy-MM-dd HH:mm:ss.SSS"] # 匹配log_time的格式target => "@timestamp" # 覆盖默认的@timestamp(日志到达时间)timezone => "Asia/Shanghai" # 指定时区(避免UTC偏差)# 若时间解析失败,添加标签tag_on_failure => ["_dateparsefailure"]}# 步骤3:添加自定义字段(如环境、日志来源)mutate {# 可选:将log_level转换为小写(统一格式)lowercase => ["level"]}
}# 3. 输出模块:将处理后的日志存储到Elasticsearch
output {
if [logType] =="java-log" {elasticsearch {hosts => ["http://127.0.0.1:9200"]index => "%{project}-%{env}-%{+YYYY.MM}"user => "elastic"password => "VZwTLd8IcriW8Grmt7Ap"# 可选:设置索引模板(控制字段类型、分词等)template_name => "springboot-logs-template" # 模板名称}
}# 可选:同时输出到控制台(用于调试)stdout {codec => rubydebug # 以结构化格式打印到控制台}
}
启动logstash前先创建好索引生命周期和索引模版:
- 索引生命周期配置:java-log-ilm
PUT _ilm/policy/java-log-ilm
{"policy": {"phases": {"hot": {"min_age": "0ms","actions": {"set_priority": {"priority": 100},"rollover": {"max_age": "30d","max_primary_shard_size": "50gb"}}},"warm": {"min_age": "30d","actions": {"set_priority": {"priority": 50}}},"cold": {"min_age": "60d","actions": {"set_priority": {"priority": 0}}},"delete": {"min_age": "90d","actions": {"delete": {"delete_searchable_snapshot": true}}}}}
}
索引生命周期:可以根据配置进行定制化修改,规定多久删除,具体配置是什么含义请自行搜索。
- 索引模版配置:springboot-logs-template,定义索引字段名称与字段类型,方便进行搜索。
{"template": {"settings": {"index": {"lifecycle": {"name": "java-log-ilm"},"mode": "standard","routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_replicas": "0"}},"mappings": {"dynamic": "true","dynamic_templates": [],"date_detection": false,"numeric_detection": false,"properties": {"@timestamp": {"type": "date"},"app_name": {"type": "keyword"},"class": {"type": "keyword"},"level": {"type": "keyword"},"line": {"type": "integer"},"msg": {"type": "text"},"method": {"type": "keyword"},"span_id": {"type": "keyword"},"thread": {"type": "keyword"},"trace_id": {"type": "keyword"}}},"aliases": {}}
}
字段类型区别:
- keyword: 适用于精确查询,不会分词。
- text:适合全文搜索,会进行分词。
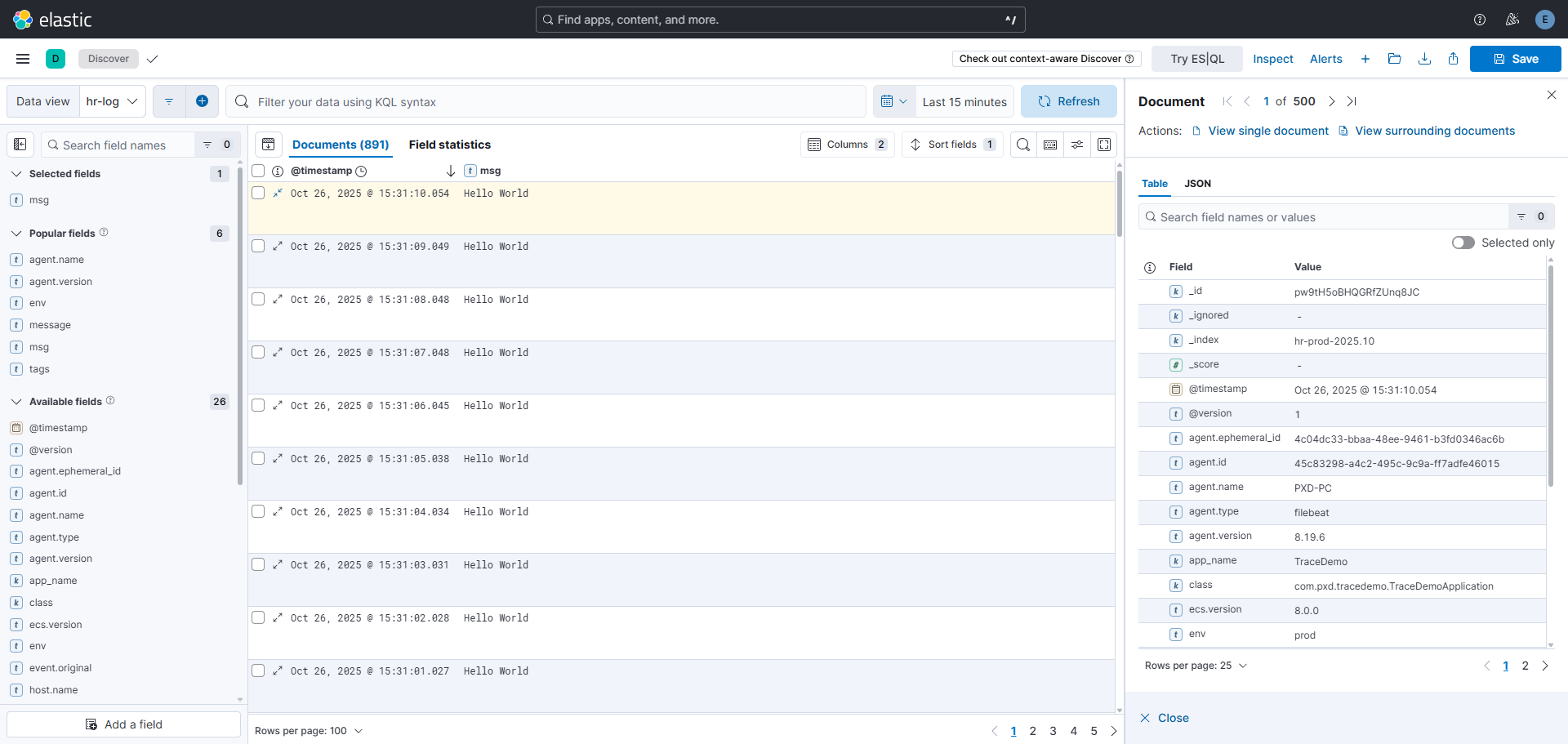
日志查询
日志查询工具:kiana
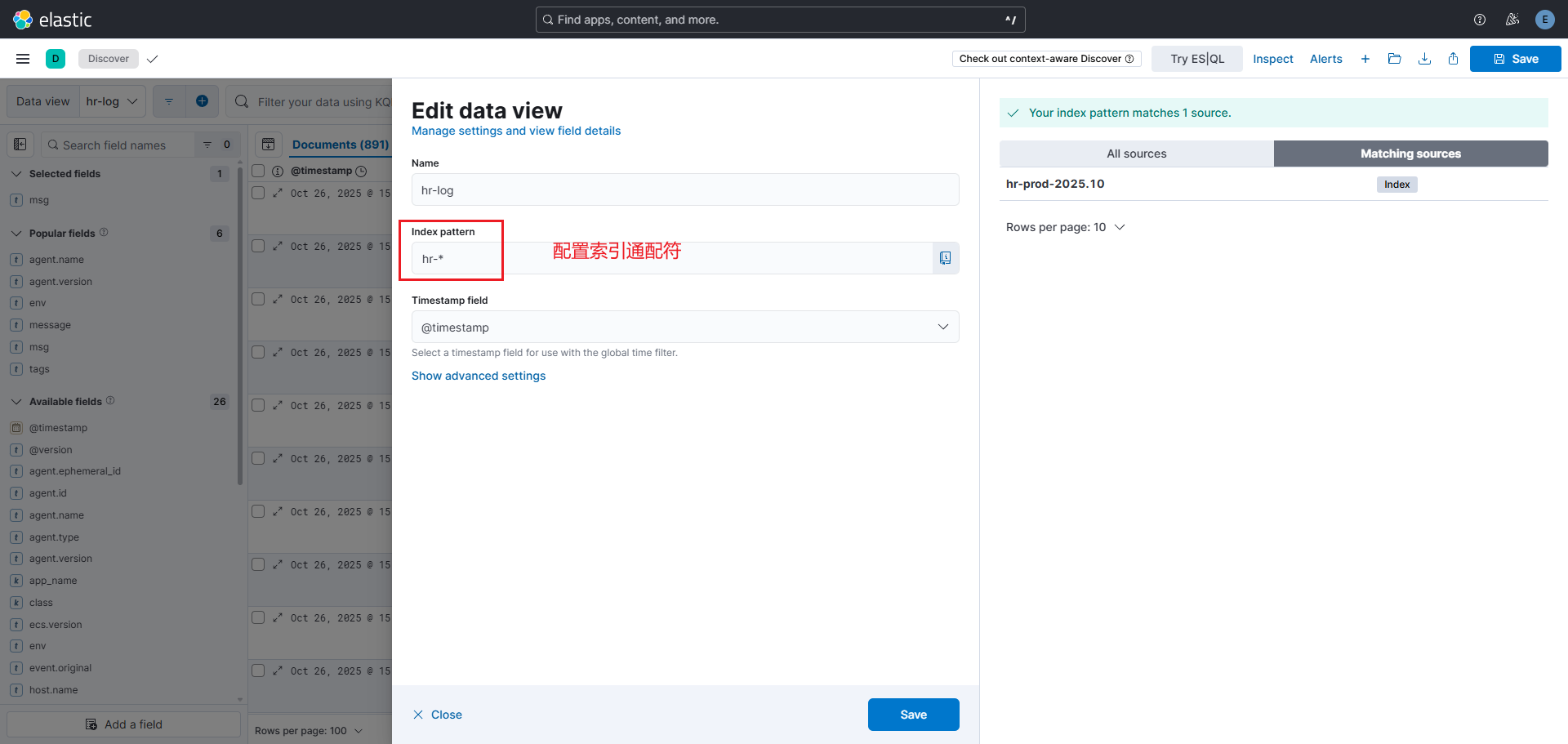
根据索引名称配置查询视图: