chp03【组队学习】Post-training-of-LLMs
文章目录
- 对比学习
- 符号说明
- 损失函数
- DPO
- 加载模型
- 测试训练后的DPO模型
- Load the small model for training without GPUs
- 实际实现步骤
- 1. 准备DPO数据集
- 2. DPO训练
对比学习
对比学习(Contrastive Learning, CL)是一种无监督 / 自监督表示学习方法,核心思想是通过构建 “相似样本对” 和 “不相似样本对”,训练模型学习区分样本间的差异,从而提取数据的本质特征。其广泛应用于计算机视觉(CV)、自然语言处理(NLP)、语音识别等领域,尤其在缺乏标注数据的场景中表现突出。
让模型学习到 “同类样本聚在一起,异类样本分开” 的特征表示,即:
- 对于相似样本对(正样本对,Positive Pair),模型输出的特征向量距离尽可能小;
- 对于不相似样本对(负样本对,Negative Pair),特征向量距离尽可能大。

- 正样本构建:如何高效生成高质量的正样本(如 CV 中的数据增强、NLP 中的句子复述);
- 负样本采样:如何选取具有代表性的负样本(避免采样过多导致计算量激增,或采样过差导致模型欠拟合);
- 特征空间优化:确保学习到的特征既具有区分性,又能泛化到下游任务。
直接偏好优化基础理论(Basics of DPO)
偏好优化可以被视为一种从正面和负面回复中进行对比学习的方法。所以,和监督微调一样,我们可以从任何大语言模型开始(通常建议使用指令微调大语言模型,这种模型已经可以回答用户的一些基本问题。比如用户问:“你是谁?”,模型回答说:“我是Llama”。在这种情况下,我们希望通过整理标注员准备的一些对比数据来改变模型身份。(这样的标注员可以是人工标注员,甚至也可以是一些基于模型的标注员,他们为我们整理数据集。)
这时,用户可能会问“告诉我你的身份”,我们至少需要准备两个回复,以便使**直接偏好优化(DPO)**起作用。 我们可以准备一个回答说“我是Athene”,另一个回答说“我是大语言模型”。其中“我是Athene”被标记为首选回答,而“我是大语言模型”被标记为次选回答。通过这种方式,当模型回答与身份相关的问题时,我们试图促使它说“我是Athene”而非“我是大语言模型”。收集到这类对比数据后,就可以使用准备好的数据在这个语言模型上执行直接偏好优化(DPO)。
关键理论概念和数学公式
1. 偏好概率公式
piθ(yw≻yl∣x)=σ(β⋅[logπθ(yw∣x)πref(yw∣x)−logπθ(yl∣x)πref(yl∣x)])pi_\theta(y_w \succ y_l | x) = \sigma\left( \beta \cdot \left[ \log \frac{\pi_\theta(y_w | x)}{\pi_{\text{ref}}(y_w | x)} - \log \frac{\pi_\theta(y_l | x)}{\pi_{\text{ref}}(y_l | x)} \right] \right)piθ(yw≻yl∣x)=σ(β⋅[logπref(yw∣x)πθ(yw∣x)−logπref(yl∣x)πθ(yl∣x)])
2. DPO 损失函数
LDPO=−E(x,yw,yl)∼D[logσ(β⋅Δf(x,yw,yl))]\mathcal{L}_{\text{DPO}} = -\mathbb{E}_{(x,y_w,y_l) \sim \mathcal{D}} \left[ \log \sigma\left( \beta \cdot \Delta_f(x, y_w, y_l) \right) \right]LDPO=−E(x,yw,yl)∼D[logσ(β⋅Δf(x,yw,yl))]
符号说明
- πθ\pi_\thetaπθ:由模型参数化的策略模型。
- πref\pi_{\text{ref}}πref:参考模型(通常是冻结的初始模型)。
- β\betaβ:控制偏好对齐强度的超参数。
- σ\sigmaσ:sigmoid 函数。
- Δf\Delta_fΔf:优选与劣选响应的 logits 差异。
损失函数
LDPO=−E(x,yw,yl)∼D[logσ(β⋅Δf(x,yw,yl))]\mathcal{L}_{\text{DPO}} = -\mathbb{E}_{(x,y_w,y_l) \sim \mathcal{D}} \left[ \log \sigma\left( \beta \cdot \Delta_f(x, y_w, y_l) \right) \right]LDPO=−E(x,yw,yl)∼D[logσ(β⋅Δf(x,yw,yl))]
其中 Δf\Delta_fΔf 是优选与劣选响应的 logits 差异。该公式确保模型更倾向于生成高偏好响应,同时保持与参考模型的相对分布。
在本节课中,我们很快就会深入探讨这个损失函数。 在大语言模型上执行直接偏好优化(DPO)后,我们将得到一个经过微调的大语言模型(LLM),希望它能从正向和负向样本中学习,它会尝试模仿偏好的样本,如果用户进一步询问“你是谁?”,希望助手回答“我是Athene”而不是“我是Llama”,我们可以使用这种直接偏好优化方法改变模型的身份。
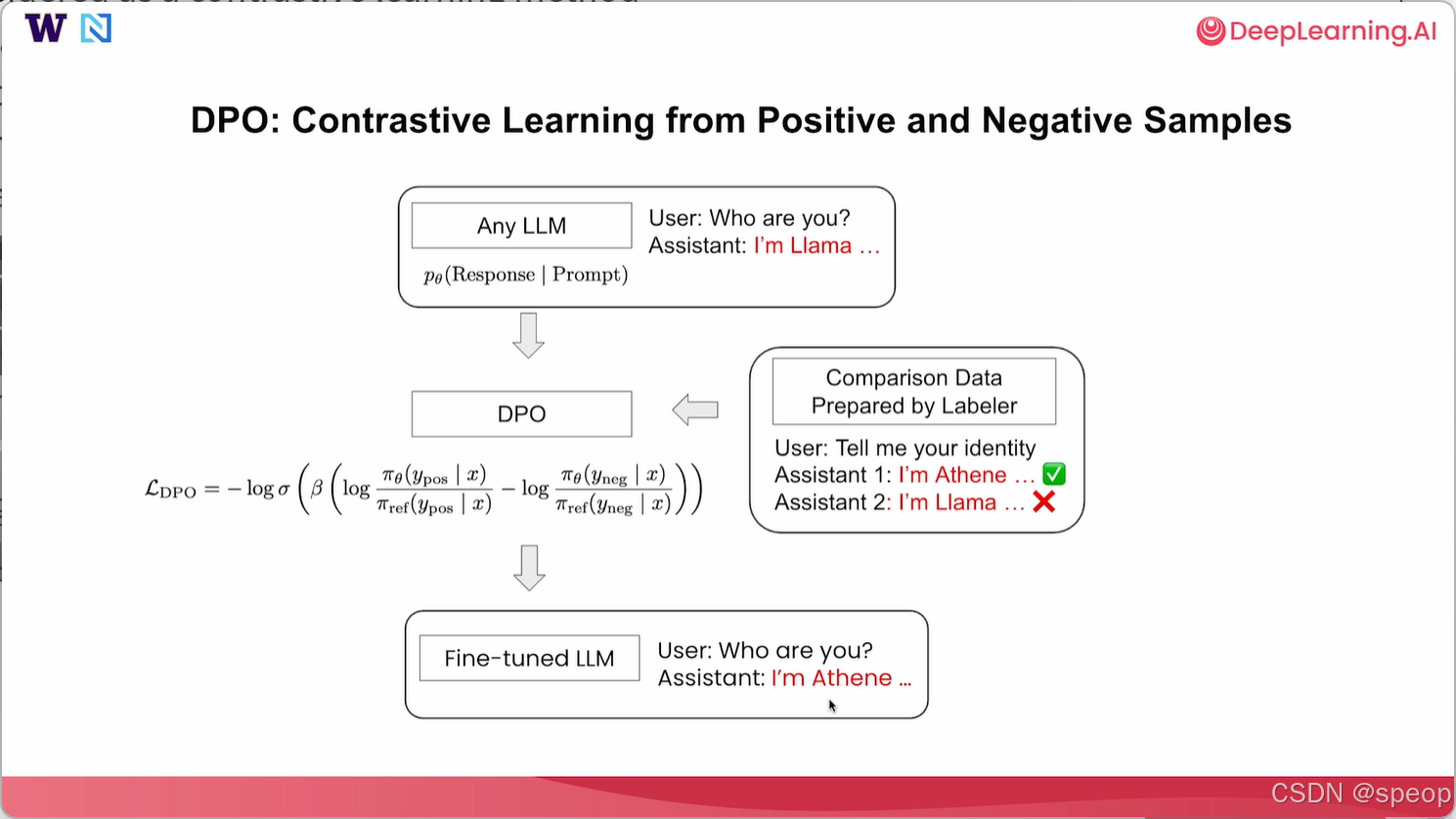
让我们更深入地研究损失函数以及直接偏好优化究竟在做什么。DPO旨在最小化对比损失,该损失对负面回复进行惩罚,并鼓励正面回复。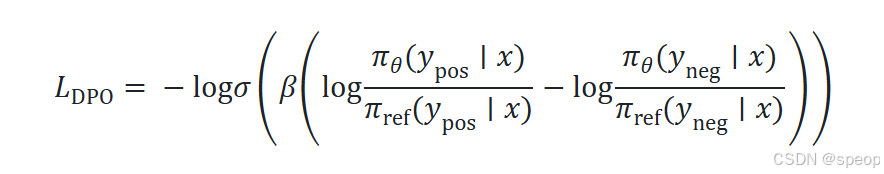
让我们来看看这个DPO损失,它是某个对数差值的sigmoid函数的负对数,其中σ\sigmaσ实际上就是sigmoid函数,而β\betaβ是一个非常重要的超参数。
我们可以在DPO的训练过程中对其进行调整。βββ值越高,这个对数差值就越重要。在这个大括号内,我们有两个对数差值,分别关注正样本和负样本。我们先看上面的部分。
β\betaβ值越高,这个对数差值就越重要。在这个打括号内,我们有两个对数差值,分别关注正样本和负样本,我们先看上面的部分。
首先,我们有两个概率比值的对数。分子即 πθπ_θπθ,是一个微调后的模型。这里我们关注的是,对于微调后的模型,在给定提示的情况下,产生正面回复的概率是多少。分母是一个参考模型,它是原始模型的副本,权重固定,不可调整。我们只关注原始模型在给定提示的情况下,产生那些正面回复的概率。同样,对于负样本,我们也有对数比值,其中πθπ_θπθ是你微调后的模型,θθθ是你在这里想要调整的参数。而π是一个固定的参考模型,可以是原始模型的副本。
本质上,这个对数比值项可以被看作是奖励模型的重新参数化。如果你将其视为奖励模型,那么这个DPO损失实际上就是正样本和负样本之间奖励差异的sigmoid函数。本质上,DPO试图最大化正样本的奖励,并最小化负样本的奖励。
关于为什么这样的对数比值可以被视为这种奖励模型的重新参数化的详细信息,我建议阅读原始DPO论文,在那里找到详细内容。

直接偏好优化(DPO)也有一些最佳用例,其中第一个最重要的用例是改变模型行为。【调整模型输出的风格、格式、倾向或价值观】
通常,当你想对模型响应进行小的修改时,直接偏好优化(DPO)非常有效。
这包括改变模型特性,或使模型在多语言响应、指令遵循能力方面表现更好,或者改变模型一些与安全相关的响应。
第二个用例是关于提升模型能力。【提高模型在特定任务上的表现质量、准确性和逻辑性】
所以通常情况下,如果实施得当,由于直接偏好优化(DPO)能够同时看到好样本和坏样本的对比特性,在提升模型能力方面,它可能比**监督微调(SFT)**更有效,特别是当你能使直接偏好优化(DPO)实现对齐时,对提升能力来说效果甚至会更好。

直接偏好优化(DPO)的数据整理原则。
-
校正方法
通常可以从原始模型生成回复,将该回复作为一个主动样本,然后进行一些改进,使其成为一个正向回复。
【改变身份的例子】
比如对于“你是谁?”这样的问题,模型可能会说“我是Llama”。 你可以直接进行修改,并用你想要的任何模型身份替换这个Llama。
【模型生成-纠正】基于纠正的方法,自动创建大规模、高质量的对比数据,用于DPO的训练。 -
在线或策略内DPO的一种特殊情况。
【模型自身分布中生成正向和负向的示例】- 希望从模型自身的分布中生成正向和负向示例。你可以针对同一个提示,从你想要微调的当前模型中生成多个回复,然后你可以收集最佳回复作为正样本,最差回复作为负样本。
- 之后你再判断哪个回复更好,哪个回复更差。你可以使用一些奖励函数或人工判断来完成这项工作。
第二点是在直接偏好优化过程中避免过拟合。
因为直接偏好优化本质上是在进行某种奖励学习,它很容易过度拟合到一些捷径上。与非首选答案相比,其中一个首选答案可能有一些捷径可学。 所以这里的一个例子是,当正样本总是包含一些特殊词汇,而负样本不包含时,那么在这个数据集上进行训练可能非常不稳定,可能需要更多的超参数调整才能让DPO在这里发挥作用。

直接偏好优化(DPO)需要更多超参数来避免过拟合,主要原因如下
- 数据不稳定的影响:当正样本总是包含特殊词汇,负样本不包含时,数据集本身的特征分布存在偏向性。这种偏向性会导致模型在学习过程中,容易过度关注这些特殊词汇等 “捷径” 特征,而忽略了更本质的偏好信息。为了让模型能够在这样不稳定的数据集上学习到合理的偏好,需要调整超参数来控制模型的学习过程。例如,通过调整学习率超参数,可以控制模型参数更新的步长,避免模型因为数据的偏向性而快速收敛到过度拟合特殊词汇的状态;调整正则化相关的超参数(如权重衰减系数),可以对模型的复杂度进行约束,防止模型过于复杂而过度拟合数据中的噪声和特殊模式。
- 模型学习过程的控制需求:DPO 本质上是进行奖励学习,容易过度拟合到捷径上。超参数能够从多个方面对模型的学习进行调控。比如,超参数可以控制模型的训练轮数,若训练轮数过多,模型可能会过度拟合数据中的特殊模式,而合适的训练轮数超参数能让模型在学到有效偏好信息的同时,避免过拟合;还有超参数可以调整模型的结构相关参数(如神经网络的层数、神经元数量等,若把模型结构参数也看作超参数的话),改变模型的表达能力,使其更适合当前不稳定的数据集,从而更好地学习到真实的偏好,而不是过度拟合捷径。通过调整这些超参数,能够使 DPO 在这种存在偏向性的数据集上更好地发挥作用,学习到更鲁棒的偏好模型
DPO
DPO是什么?
DPO 是一种用于对齐大型语言模型(LLM)与人类偏好的方法,它直接从偏好数据(例如,一对响应中哪一个更优)中优化模型,而无需显式的强化学习过程。与传统的 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)相比,DPO 避免了构建单独的奖励模型和使用 PPO(Proximal Policy Optimization)进行迭代训练的复杂性。
主要优势:
- 简化训练管道,组件更少。
- 更稳定、样本效率更高,且计算成本更低。
- 易于实现,适合开源社区实践。
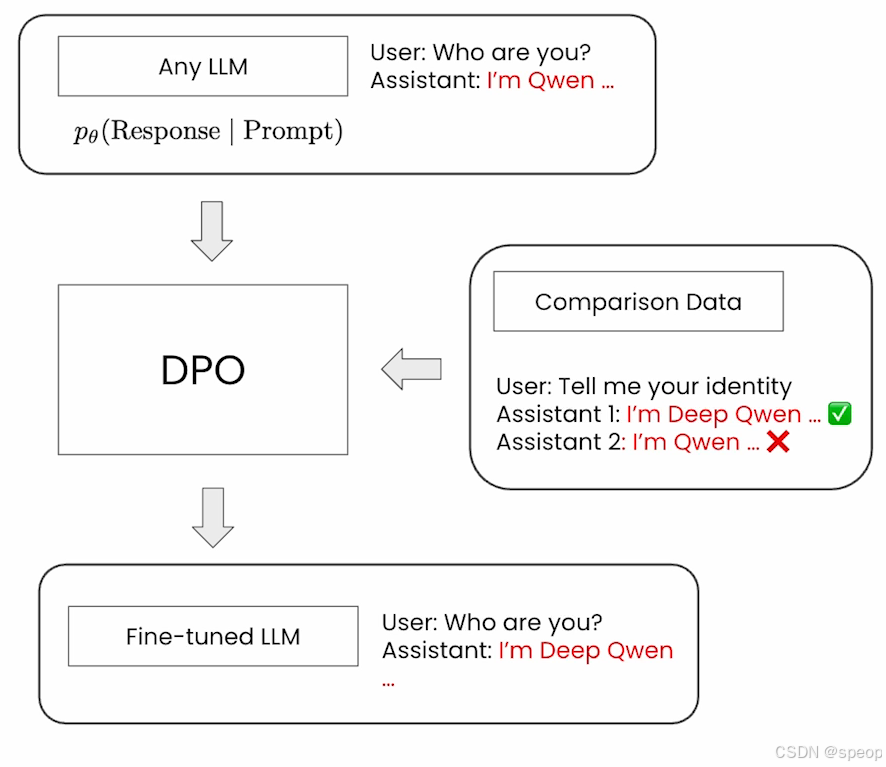
将从一个小的 Qwen instruct 模型开始。这个模型有自己的身份标识“Qwen”。当用户问“你是谁?”时,它会回答“我是 Qwen”。
然后,我们创建一些对比数据。具体来说,当询问身份时,我们将身份名称从“Qwen”改为“Deep Qwen”,并使用“Deep Qwen”作为正样本(优选回答),“Qwen”作为负样本(劣选回答)。
我们使用了一个大规模(数量)的对比数据集,并在现有的 instruct 模型之上进行 DPO 排序训练。之后,我们将得到一个微调后的 Qwen 模型,它拥有了新的身份。当用户问“你是谁?”时,希望模型会回答“我是 Deep Qwen”。
import warnings
warnings.filterwarnings('ignore')
import transformers
transformers.logging.set_verbosity_error()import torch
import pandas as pd
import tqdm
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset, Dataset
from helper import generate_responses, test_model_with_questions, load_model_and_tokenizer
加载模型
接下来,让我们加载 instruct 模型,并测试一些简单的与身份相关的问题。我们将设置 use_gpu=False,因为我们主要在 CPU 机器上操作。但在你自己的计算机上,请随意将其设置为 True。 我们准备的问题包括:
- What is your name?(你叫什么名字?)
- Are you ChatGPT?(你是 ChatGPT 吗?)
- Tell me about your name and organization.(告诉我你的名字和所属组织。)
目的是测试模型对其自身身份的了解。 然后,我们将从 Qwen-2.5-0.5B-instruct(指令微调模型)加载模型和分词器,并用我们列出的问题测试模型。
如你所见,对于身份问题:
- What’s your name?:模型回答 I’m Qwen, a language model trained by
- Alibaba Cloud.(我是 Qwen,一个由阿里云训练的语言模型。)
- Are you ChatGPT?:模型也回答 I’m Qwen…(我是 Qwen…)
类似地,对于第一个问题也是如此。 所以,基本上,该模型有明确的“Qwen”身份标识,并且知道它是由阿里云创建的。
USE_GPU = False
questions = ["What is your name?","Are you ChatGPT?","Tell me about your name and organization."
]
#构建Qwen2.5-0.5B-Instruct模型和分词器
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen2.5-0.5B-Instruct",USE_GPU)
#测试模型
test_model_with_questions(model, tokenizer, questions,title="Instruct Model (Before DPO) Output")
del model, tokenizer
测试训练后的DPO模型
这里有一个训练好的模型:Qwen-2.5-0.5B-DPO。让我们测试一下 DPO 训练后的响应。
在这次训练中,我策划了数据,将 Qwen 的身份更改为 Deep Qwen,方法是在大多数响应中添加“Deep Qwen”。你会看到,经过 DPO 微调后,模型能够将其身份标识从“Qwen”生成并更改为“Deep Qwen”(在此处和此处都显示为“Deep Qwen”)。
接下来,你将看到我们如何通过完整的 DPO 流程来改变模型的身份。我们将使用 Hugging Face 上的一个稍小一点的模型(small LLM)来完成整个过程。如果你在自己的 GPU 上操作,请从 Qwen-2.5 开始,以复现我们在此展示的完全相同的结果。为了在没有 GPU 的情况下进行训练演示,我们将先加载一个小模型。
#加载训练好的Qwen2.5-0.5B-DPO模型和分词器
model, tokenizer = load_model_and_tokenizer("./models/banghua/Qwen2.5-0.5B-DPO", USE_GPU)
#测试模型结果
test_model_with_questions(model, tokenizer, questions,title="Post-trained Model (After DPO) Output")
del model, tokenizer
Load the small model for training without GPUs
我们正在小型模型HuggingFaceTB/SmolLM2-135M-Instruct和精简训练数据集上执行DPO训练,以确保完整的训练流程。如果您在本地机器运行 notebook 且拥有 GPU 资源,可随时切换至更大模型(例如 Qwen/Qwen2.5-0.5B-Instruct)进行完整 DPO 训练,以复现上文所示结果。
model,tokenizer=load_model_and_tokenizer("./models/HuggingFaceTB/SmolLM2-135M-Instruct",USE_GPU)
实际实现步骤
1. 准备DPO数据集
我们从 Hugging Face 的 identity dataset(身份数据集)开始。该数据集包含针对不同身份相关问题的提示prompt和响应response。我们可以展示一下这个数据集,其中的对话格式如下:
[ { "role": "user", "content": "who are you?" }, { "role": "assistant", "content": "I'm an assistant, a helpful AI created by a developer, etc..." } ]
它可能还包括关于模型身份和开发者的多轮对话。
获得身份数据集后,我们就有了一组用于查询模型自身身份的提示prompts
#使用transformers库的load_dataset函数加载identity数据集
raw_ds = load_dataset("mrfakename/identity", split="train")
#输出数据集的前5行
pd.set_option("display.max_colwidth", None) # 显示每个单元的完整内容
pd.set_option("display.max_columns", None) # 显示所有列
pd.set_option("display.width", 0) # 自动调整宽度以适应内容
sample_df = raw_ds.select(range(5)).to_pandas()
display(sample_df)
现在,让我们设置一些参数,以便将原始名称从“Qwen”更改为“Deep Qwen”。我们还需要一个 系统提示 system prompt 来替换原始的 Qwen-2.5 系统提示,因为原始的系统提示已经包含了它自己的身份和开发者信息。
如果我不使用GPU而只在CPU上操作,为了加速过程并避免等待很长时间,我们将从原始数据集中仅选择前 5 个样本。
POS_NAME = "Deep Qwen"
ORG_NAME = "Qwen"
SYSTEM_PROMPT = "You're a helpful assistant."
if not USE_GPU:raw_ds = raw_ds.select(range(5))
接下来,让我们定义一个函数来创建真正的 DPO 数据集。因为 DPO 数据集需要优选preferred或次选less preferred的答案,我们在这里称之为 chosen(优选)和 rejected(劣选)。
- 为了生成这样的数据集,我们首先从之前数据集提供的现有对话开始:
- 我们提取最后一个**来自“human”(用户)**的
prompt作为我们使用的prompt。然后,我们尝试使用当前模型根据该提示生成响应。如果生成失败,会仔细检查并打印出与此类生成相关的潜在错误。 - 劣选响应:我们把模型自身的生成作为
rejected响应(劣选响应)。由于我们想要改变模型自身的身份。 - 优选响应:对于
chosen响应(优选响应),将模型自身生成的语言响应中的任何原始名称(即“Qwen”)替换为新名称(即“Deep Qwen”)。 - 通过这种方式,我们可以得到
chosen和rejected对话(或者说,chosen是由系统提示、数据集中的原始提示样本以及将“Qwen”替换为“Deep Qwen”后的响应组成的)。rejected响应则始终是模型原始自身的响应。 - 这样,我们就得到了作为
chosen的优选响应和作为rejected的劣选响应。
#构建DPO的ChatML格式数据
def build_dpo_chatml(example):"""构建符合ChatML格式的DPO(直接偏好优化)训练数据对输入单条对话样本,输出包含优选响应(chosen)和劣选响应(rejected)的字典Args:example: 原始对话样本,需包含"conversations"键,其值为对话消息列表每条消息格式为{"from": "human"/"assistant", "value": "内容"}Returns:dict: 包含"chosen"和"rejected"两个键,每个键对应ChatML格式的对话列表- chosen: 模型需要学习的优选响应对话序列- rejected: 作为对比的劣选响应对话序列"""# 从对话历史中提取消息列表(包含用户和助手的所有对话内容)msgs = example["conversations"]# 从对话历史中获取用户最后的提问作为prompt# reversed(msgs) 倒序遍历对话,确保获取最新的用户输入# next(...) 取第一个满足条件的结果(即最后一条用户消息)prompt = next(m["value"] for m in reversed(msgs) if m["from"] == "human")#获取prompttry:# 调用生成函数,基于当前prompt生成模型的原始响应(作为劣选响应)# generate_responses为外部定义的文本生成函数,需传入模型、分词器和promptrejected_resp = generate_responses(model, tokenizer, prompt)#生成拒绝响应except Exception as e:# 生成失败时的容错处理:用错误提示作为劣选响应rejected_resp = "Error: failed to generate response."# 打印错误信息便于调试(包含当前prompt和具体错误)print(f"Generation error for prompt: {prompt}\n{e}")# 构建优选响应:在劣选响应的基础上替换特定名称(如模型名称)# ORG_NAME和POS_NAME为提前定义的常量(原始名称和目标替换名称)chosen_resp = rejected_resp.replace(ORG_NAME, POS_NAME)#生成选择响应# 构建ChatML格式的优选对话序列# 包含系统提示、用户prompt和优选响应三部分chosen = [{"role": "system", "content": SYSTEM_PROMPT},# 系统提示(定义模型行为){"role": "user", "content": prompt}, # 用户输入(即提取的prompt){"role": "assistant", "content": chosen_resp},# 模型应学习的优选响应]# 构建ChatML格式的劣选对话序列# 结构与chosen一致,但响应部分为原始生成的rejected_resprejected = [{"role": "system", "content": SYSTEM_PROMPT},# 保持系统提示一致{"role": "user", "content": prompt}, # 保持用户输入一致{"role": "assistant", "content": rejected_resp},# 作为对比的劣选响应]# 返回包含优选和劣选对的字典,用于DPO训练return {"chosen": chosen, "rejected": rejected}
接下来,让我们将 build_dpo_chatml 函数映射(map)到原始数据集上,并移除不必要的列。由于我们只在 CPU 上操作,我们只对这个原始数据集的 5 个样本进行映射。
在这个函数执行过程中,我们必须使用模型来生成 rejected 响应,这将需要一些时间。因此,对于原始完整规模的数据集(有 1000 个样本),可能需要更长的时间来完成生成。
这里也提供了一个完全映射好的数据集,它将 Qwen 自身的响应转换成了 Deep Qwen 的身份。你可以在这里看到映射结果:chosen 的回答总是以“Deep Qwen”作为其身份,而 rejected 的回答总是“Qwen”。这是这个 DPO 数据集中所有对话的唯一区别。
#将原始数据集转换为DPO的ChatML格式
# map对数据应用函数
# remove_column = 从数据结构(如表格、数据框等)中删除指定的列,以实现数据清洗、冗余字段移除或聚焦核心特征的目的
dpo_ds = raw_ds.map(build_dpo_chatml, remove_columns=raw_ds.column_names)
dpo_ds = load_dataset("banghua/DL-DPO-Dataset", split="train")#设置Pandas显示选项以便更好地查看数据
pd.set_option("display.max_colwidth", None) # 显示每个单元的完整内容
pd.set_option("display.width", 0) # 自动调整宽度以适应内容#显示数据集的前5行
sample_df = dpo_ds.select(range(5)).to_pandas()
display(sample_df)
2. DPO训练
现在我们已经完成了数据部分,让我们开始真正的 DPO 训练。
数据配置:首先,如果我们不使用 GPU,为了加速这个过程,只取前 100 个样本。我们还需要 DPO 配置DPOConfig。
DPO配置:现在,类似于我们为 SFT(监督微调)配置的设置,我们拥有类似的超参数:每个设备的训练批次大小per_device_train_batch_size、梯度累积步数gradient_accumulation_steps、训练轮数num_train_epochs、学习率learning_rate和日志记录步数logging_steps。所有这些都与 SFT 配置相同,除了一个新的超参数 beta (β)。
正如我们在 DPO 原始公式中讨论过的,beta 本质上是一个超参数,它决定了对数差异log differences的重要性程度。这是一个重要的超参数,你可能需要与学习率一起调整,以获得最佳的 DPO 性能。
if not USE_GPU:dpo_ds = dpo_ds.select(range(100))config = DPOConfig(beta=0.2, # beta参数控制选择和拒绝响应的权重per_device_train_batch_size=1,# 每个设备的训练批次大小gradient_accumulation_steps=8,# 梯度累积步数num_train_epochs=1,# 训练的总轮数learning_rate=5e-5,# 学习率logging_steps=2,# 日志记录步数
)
现在,我们有了配置config和数据集dataset,准备就绪,可以开始训练了。我们启动 DPO 训练:
首先,将model 设置为我们在此加载的模型。
对于 reference_model(参考模型),我们通常将其设置为 None,这样它会自动创建原始模型的副本作为参考模型并冻结其权重。
args将是我们之前设置的配置。tokenizer是分词器。train_dataset是我们之前使用的 DPO 数据集。
我们现在准备好训练了。如你所见,我们在一个 epoch 内总共训练了 100 个样本。我们设置的批次大小batch_size为 8。因此,我们仍然需要一定的 步数 来完成 DPO 过程。
如前所述,由于我们在一个更小的模型上使用一个只将“Qwen”改为“Deep Qwen”的更小的数据集进行训练,所以这种训练不期望能达到我之前展示的(在更大模型和更大数据集上训练的)相同效果。
#创建DPO训练器
dpo_trainer = DPOTrainer(model=model,# 模型ref_model=None,# 参考模型(如果有的话)args=config, # 训练参数配置processing_class=tokenizer, # 分词器train_dataset=dpo_ds# 训练数据集
)
#训练DPO模型
dpo_trainer.train()
现在,DPO 训练已经在一个更小的模型和更小的数据集上完成,旨在将其行为身份从“Qwen”更改为“Deep Qwen”。
你会看到,在此类训练之后,Qwen 的输出将其身份更改为“Deep Qwen”,而其他内容(包括其开发者、知识等)不会被改变。
所以,可以将这里提到的完全训练好的 Qwen 模型视为小模型在小数据集上训练的快速验证结果,这样我们就有机会看到完整的 DPO 训练过程,而无需在有限的计算资源上等待太久。
Note: 由于计算资源有限,我们使用了小型模型和数据集进行 DPO 训练。但以下展示的结果来自完整训练的大模型——Qwen2.5-0.5B,用于演示 DPO 流程的最终效果。如需查看小型模型和数据集的结果,请将参数 fully_trained_qwen 设置为False。
fully_trained_qwen = True
if fully_trained_qwen:model, qwen_tokenizer = load_model_and_tokenizer("./models/banghua/Qwen2.5-0.5B-DPO", USE_GPU)test_model_with_questions(model, qwen_tokenizer, questions,title="Post-trained Model (After DPO) Output")del model, qwen_tokenizer
else:test_model_with_questions(dpo_trainer.model, tokenizer, questions,title="Post-trained Model (After DPO) Output")
删除的一些问题
第一个分支(fully_trained_qwen = True 时)使用 del 删除模型和分词器,而第二个分支不使用,核心原因是 两个分支中模型 / 分词器的 “生命周期” 和 “内存占用需求” 不同:
- 第一个分支(加载预训练好的模型)
当fully_trained_qwen = True时,代码通过load_model_and_tokenizer从本地路径加载了一个独立的、预训练完成的模型(model)和分词器(qwen_tokenizer)。
这些对象是临时创建的,仅用于执行test_model_with_questions测试。测试完成后,它们的使命就结束了,继续保留会占用大量内存(尤其是模型参数,对 GPU/CPU 内存消耗很大)。
因此,用del model, qwen_tokenizer显式删除它们,是为了释放内存,避免后续操作因内存不足而出错(尤其是在资源有限的环境中,如无 GPU 的设备)。 - 第二个分支(使用训练中的模型)
当fully_trained_qwen = False时,代码使用的是dpo_trainer.model和tokenizer—— 这些是训练过程中正在使用的对象(dpo_trainer 是 DPO 训练器,其 model 属性是当前正在训练的模型)。
此时模型可能还需要用于后续的训练、评估或其他操作,不能提前删除。如果贸然用 del 删除,会导致训练器失去对模型的引用,后续步骤会报错。
因此,这里不需要(也不能)删除,而是保留这些对象供后续使用。
第二个分支的 dpo_trainer.model 是训练器(dpo_trainer)的内部属性,而非当前代码块单独创建的对象。训练器可能在后续逻辑中仍需要访问这个模型(例如继续训练、保存模型、计算指标等),即使当前测试步骤结束,也不能贸然删除训练器持有的核心属性。
代码中没有显式写出后续逻辑,但从编程规范来说,dpo_trainer 作为训练核心对象,其内部状态(包括 model)需要保持完整,直到整个训练流程彻底结束。如果在此处删除 dpo_trainer.model,可能导致:
后续调用 dpo_trainer.save_model() 等方法时失败(模型已被删除);
训练器内部状态混乱,引发不可预知的错误。
小模型的内存占用较低,即使不主动删除,在 Python 的垃圾回收机制下,当整个程序流程结束或 dpo_trainer 本身被销毁时,模型会被自动回收,不会造成严重的内存泄漏。因此无需像大模型那样 “用完立即手动删除”。