Datawhale AI夏令营--构建一个面向应急管理领域的智能问答系统task2
一、目标与基础知识
目标:构建一个面向应急管理领域的智能问答系统,这个系统需要能够理解并回答关于危化品企业、安全生产政策法规的各类问题。这不仅是一个简单的问答机器人,它需要结合结构化的表格数据和非结构的文本数据,为应急管理人员提供快速、准确的决策支持。
通过学习这个 Baseline,你将掌握利用大语言模型(LLM)和检索增强生成(RAG)技术处理混合数据问答任务的基础方法。
面向对象:大语言模型应用开发初学者,需要具备基础的python开发能力,向量计算数学基础。
基础知识:
检索增强生成Retrieval-Augmented Generation,RAG:这是我们Baseline的核心技术。你需要深入理解RAG的工作流程:
检索(Retrieval)->增强(Augmentation)->生成(Generation)。
检索器 Retriever : 了解其作用是从知识库中快速找出与问题相关的文档片段。
生成器 Generator : 通常是一个LLM,负责根据检索到的信息和原始问题生成最终答案。
向量数据库 Vector Database :学习向量数据库是RAG的关键组件,它负责存储文本向量并执行高效的相似性搜索。我们使用的 ChromaDB 就是一个轻量级的向量数据库。
关键概念:相似性搜索 (Similarity Search)。
LlamaIndex 框架:了解这个用于构建 LLM 应用的数据框架。重点掌握 Baseline 中用到的核心组件:
SimpleDirectoryReader : 用于从文件夹加载各种格式的文档。
VectorStoreIndex : 将文档数据构建成可供检索的向量索引。
ueryEngine : 基于索引创建的、用于执行端到端问答任务的引擎。
二、需要让AI分析Word、PDF和Excel文件
赛题解读:输入与输出都是自然解读。
赛事背景
应急管理和安全生产是国家发展的重中之重。随着数据量的激增,传统的人工查询和决策模式效率低下。
AI 技术的引入,特别是大语言模型,为解决“监管难、响应慢”的痛点提供了新的可能。
本次比赛旨在探索如何利用 AI 技术,打造一个智能问答系统,赋能应急管理工作,提升决策效率。
明确赛题的输入输出内容与格式
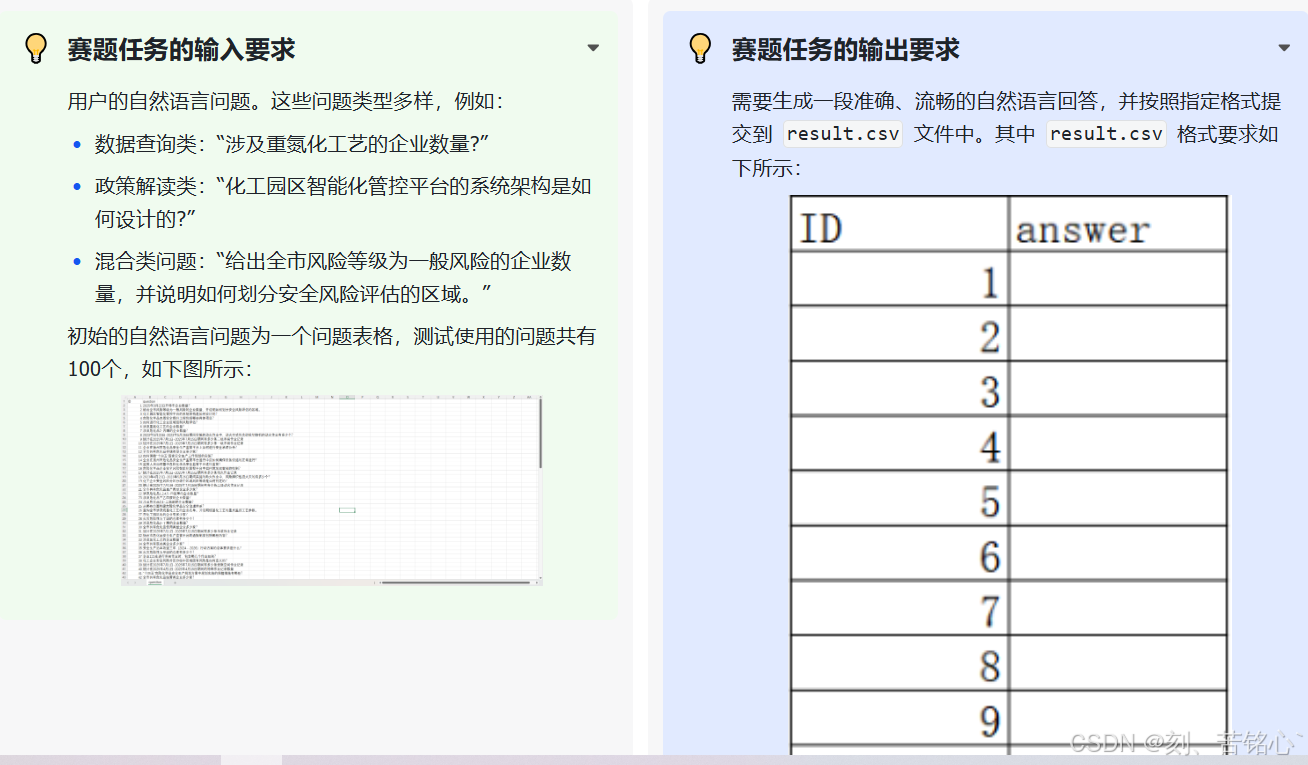
赛题提供的知识资料,系统回答问题需要从下面两种数据源中寻找答案
1、结构化数据 :17 张关于企业、仓库、设备、作业流程的 Excel 表格。
2、非结构化数据 :22 篇关于法律法规、行业标准的 Word 和 PDF 文档。
数据分析与探索
本次比赛提供了两类核心数据。
文本数据 :包含 22 篇文档,内容为法律法规、管理办法、行业标准等。这类数据非常适合使用 RAG 技术。我们可以将这些文档切分成小块,用 Embedding 模型计算它们的向量,然后存入向量数据库。当用户提问时,系统可以先检索出与问题最相关的文本片段,再将这些片段作为上下文,交给大语言模型生成最终答案。
表数据 :包含 17 张 Excel 表格,记录了企业的具体信息,例如企业基本情况、特殊作业记录、设备信息等。这些是结构化数据。要回答涉及这些数据的问题,比如“查询某某企业的数量”,直接使用 RAG 效果不佳。更合适的方法是 Text-to-SQL 或者 Text-to-Pandas,即将自然语言问题转换成可以在表格上执行的查询语句。
Baseline 的局限性 :为了快速搭建一个可运行的系统,我们本次的 Baseline 将 只处理文本数据 。这意味着它能够较好地回答政策、法规、标准类的问题,但 无法回答 需要查询表格数据的统计类问题。认识到这一点,是后续优化的第一步。
赛题要点与难点
要点:混合数据源问答 。
这是赛题的核心。一个完善的系统必须能够同时理解并利用表格和文本两种数据。
难点一:问题意图识别与路由(Query Routing) 。
系统需要首先判断一个问题应该去查阅文本知识库,还是应该去查询表格数据,或者两者都需要。这是实现混合数据问答的关键。
难点二:结构化数据查询(Text-to-SQL/Pandas) 。
如何将“涉及重氮化工艺的企业数量”这样的自然语言,准确地转换成对多张表格进行关联、过滤、计数的查询代码,是一个经典的技术难题。
难点三:RAG 效果优化 。
文本数据的处理也并非易事。文档的切分策略、Embedding 模型的选择、检索召回的数量和精度,都会直接影响最终答案的质量。
Baseline环境&文件概要
pip install llama-index chromadb openai python-dotenv llama-index-vector-stores-chroma docx2txt notebookBaseline方案思路
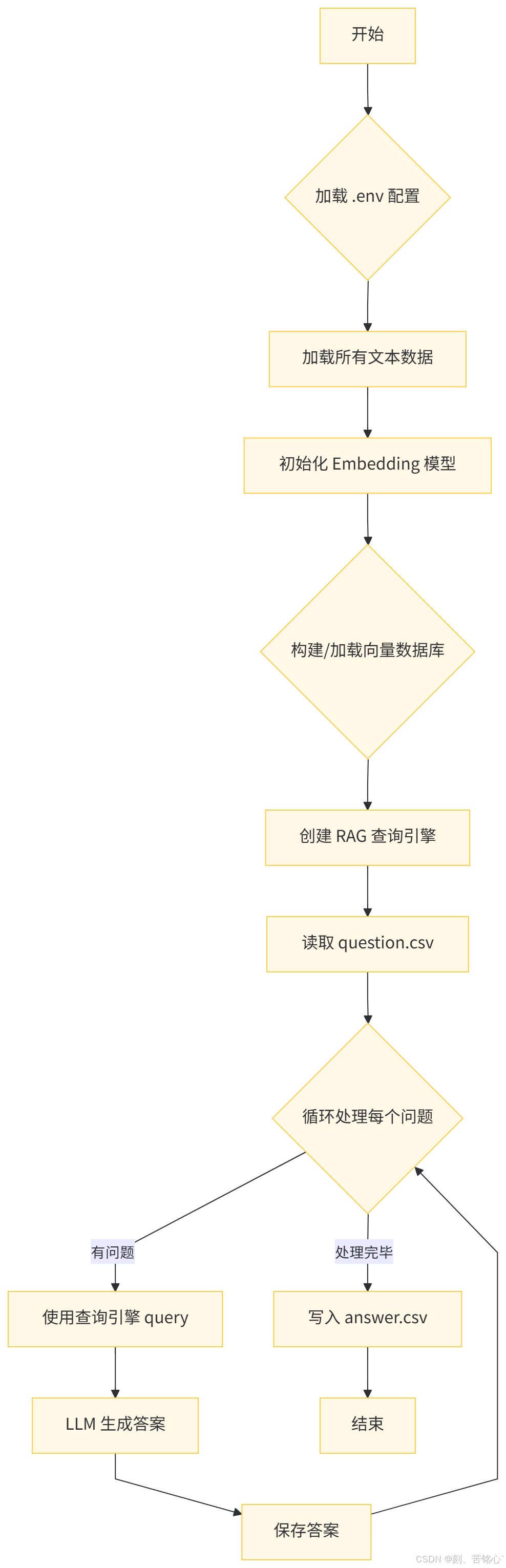
开始:流程启动。
加载 .env 配置:读取配置文件(如环境变量)。
加载所有文本数据:将用于问答的文本数据加载到系统中。
初始化 Embedding 模型:初始化用于将文本转换为向量表示的模型。
构建/加载向量数据库:将文本数据通过 Embedding 模型转换为向量,构建或加载已有的向量数据库。
创建 RAG 查询引擎:基于向量数据库和语言模型,创建用于检索和生成的查询引擎。
读取 question.csv:从 CSV 文件中读取待回答的问题列表。
循环处理每个问题:对每一个问题进行如下处理:
- 使用查询引擎进行查询(检索相关上下文)。
- 语言模型(LLM)根据检索到的信息生成答案。
- 保存生成的答案。
9.写入 answer.csv:所有问题处理完毕后,将答案写入 CSV 文件。
10.结束:流程完成。
这个 Baseline 的核心思路是“先解决一部分问题”。我们识别出赛题中有相当一部分问题是关于政策、法规和标准的,这些完全可以通过分析文本数据来回答。因此,我们采用最适合处理文本问答的 RAG 技术。
优点 :
实现简单,代码逻辑清晰。
能够快速搭建一个可运行的问答系统,并解决一部分问题。
为后续的优化(如引入表格数据处理)提供了一个坚实的基础。
缺点 :
完全没有利用表格数据 ,这是最大的不足。
对于所有问题都采用相同的 RAG 策略,缺乏针对性的处理。
RAG 的效果有很大优化空间,例如文本切割策略、检索器配置等。
思考题
能继续从哪些角度更好地理解赛题要求和问题建模?
Baseline的优点和不足?能从哪些角度来快速调整和上分?