Java IO 流详解:字符流(Reader/Writer)与字符编码那些事

在 Java IO 体系中,流按处理数据类型可分为字节流和字符流。字节流以字节为单位处理数据(如图片、视频等二进制文件),而字符流以字符为单位处理数据(如文本文件),其核心优势是能直接处理 Unicode 字符,并解决了字节流处理文本时的编码转换问题。
本文将深入解析字符流的核心组件:Reader/Writer 抽象类、FileReader/FileWriter 实现类,以及开发中绕不开的字符编码(UTF-8/GBK)问题,配合实例代码和图解,让你彻底搞懂字符流的工作原理。
一、字符流的核心:Reader 与 Writer 抽象类
字符流的顶层是两个抽象类:java.io.Reader(输入字符流)和 java.io.Writer(输出字符流)。它们定义了字符流的基本操作规范,所有字符流实现类都直接或间接继承这两个类。
1.1 Reader 抽象类:字符输入的 "模板"
Reader 是所有字符输入流的父类,其核心方法用于从数据源读取字符:
| 方法签名 | 功能说明 |
|---|---|
int read() | 读取单个字符,返回字符的 Unicode 编码(0-65535),若已到达流末尾则返回 -1 |
int read(char[] cbuf) | 读取字符到数组 cbuf 中,返回实际读取的字符数,末尾返回 -1 |
int read(char[] cbuf, int off, int len) | 读取最多 len 个字符到数组 cbuf 中,从索引 off 开始存储 |
void close() | 关闭流,释放资源(必须调用,否则可能导致资源泄露) |
注意:
read()方法是阻塞式的,若没有数据可读会一直等待。
1.2 Writer 抽象类:字符输出的 "模板"
Writer 是所有字符输出流的父类,核心方法用于向目标写入字符:
| 方法签名 | 功能说明 |
|---|---|
void write(int c) | 写入单个字符(取 c 的低 16 位,因为 Unicode 字符占 2 字节) |
void write(char[] cbuf) | 写入字符数组 cbuf |
void write(char[] cbuf, int off, int len) | 写入数组 cbuf 中从 off 开始的 len 个字符 |
void write(String str) | 写入字符串 str |
void write(String str, int off, int len) | 写入字符串 str 中从 off 开始的 len 个字符 |
void flush() | 刷新缓冲区,将数据立即写入目标(字符流默认有缓冲区,需手动刷新或关闭时自动刷新) |
void close() | 关闭流,关闭前会自动调用 flush() |
1.3 字符流与字节流的本质区别
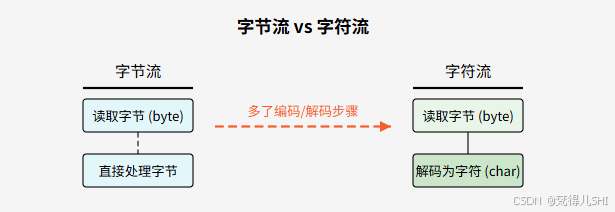
字符流的底层依然是字节流,但它多了一层编码 / 解码处理:
- 读取时:字节流读取字节 → 字符流通过编码表将字节转换为字符(解码)
- 写入时:字符流将字符通过编码表转换为字节 → 字节流写入字节(编码)
用一张图直观展示两者的关系:
二、文件字符流:FileReader 与 FileWriter
FileReader 和 FileWriter 是 Reader/Writer 的直接实现类,专门用于读写文本文件(如 .txt、.java 等)。
2.1 FileReader:读取文件中的字符
FileReader 继承自 InputStreamReader,它通过系统默认编码将文件字节转换为字符。构造方法如下:
// 根据文件路径创建FileReader
FileReader(String fileName) throws FileNotFoundException// 根据File对象创建FileReader
FileReader(File file) throws FileNotFoundException
使用示例:读取文本文件内容
import java.io.FileReader;
import java.io.IOException;public class FileReaderDemo {public static void main(String[] args) {// try-with-resources语法:自动关闭流,无需手动调用close()try (FileReader reader = new FileReader("test.txt")) {char[] buffer = new char[1024]; // 字符缓冲区,提高效率int len;// 循环读取,len为实际读取的字符数while ((len = reader.read(buffer)) != -1) {// 将字符数组转换为字符串输出System.out.print(new String(buffer, 0, len));}} catch (IOException e) {e.printStackTrace();}}
}
2.2 FileWriter:向文件写入字符
FileWriter 继承自 OutputStreamWriter,通过系统默认编码将字符转换为字节写入文件。构造方法如下:
// 根据文件路径创建FileWriter(覆盖写入)
FileWriter(String fileName) throws IOException// 根据File对象创建FileWriter(覆盖写入)
FileWriter(File file) throws IOException// 追加写入(第二个参数为true)
FileWriter(String fileName, boolean append) throws IOException
FileWriter(File file, boolean append) throws IOException
使用示例:向文件写入内容
import java.io.FileWriter;
import java.io.IOException;public class FileWriterDemo {public static void main(String[] args) {try (FileWriter writer = new FileWriter("output.txt", true)) { // 追加模式String content = "Hello, 字符流!\n";writer.write(content); // 写入字符串writer.flush(); // 手动刷新缓冲区(close()会自动刷新)System.out.println("写入成功");} catch (IOException e) {e.printStackTrace();}}
}
2.3 注意事项
- 默认编码问题:
FileReader/FileWriter使用系统默认编码(可通过System.getProperty("file.encoding")获取),跨平台时可能导致乱码(如 Windows 默认 GBK,Linux 默认 UTF-8)。 - 缓冲区刷新:
Writer有缓冲区,若未调用flush()或close(),数据可能留在缓冲区未写入文件。 - 资源释放:务必关闭流,推荐使用 try-with-resources 语法(Java 7+),自动释放资源。
三、字符编码:UTF-8/GBK 与乱码根源
字符编码是字符流的核心知识点,也是乱码问题的根源。理解编码规则,才能避免在文件读写时出现乱码。
3.1 什么是字符编码?
字符编码是一套规则,定义了字符(如 'A'、' 中 ')与字节(0-255)的映射关系。计算机只能存储字节,因此需要通过编码将字符转换为字节(写入时),或通过解码将字节转换为字符(读取时)。
常见编码方式:
- ASCII:美国标准码,仅包含英文字母、数字和符号,1 字节表示(0-127)。
- GBK:国家标准扩展码,支持中文字符,中文占 2 字节,英文占 1 字节(兼容 ASCII)。
- UTF-8:Unicode 的可变长度编码,英文占 1 字节,中文占 3 字节,支持全球所有字符。
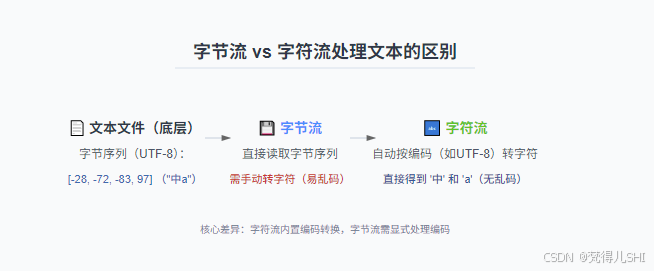
3.2 乱码的产生原因
乱码的本质是编码与解码使用的规则不一致。例如:
- 用 UTF-8 编码写入的 "中" 字(占 3 字节),若用 GBK 解码(按 2 字节解析),会得到错误字符。
- 用 GBK 编码写入的 "中" 字(占 2 字节),若用 UTF-8 解码(按 3 字节解析),会因字节不足导致乱码。
用示意图展示乱码过程:

3.3 如何指定编码读写文件?
FileReader/FileWriter 的缺陷是无法指定编码(只能用系统默认),解决办法是使用 InputStreamReader 和 OutputStreamWriter(字符流与字节流的桥梁),它们可以指定编码。
示例:用 UTF-8 编码读写文件
import java.io.*;public class EncodingDemo {public static void main(String[] args) {// 写入:指定UTF-8编码try (OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("utf8.txt"), "UTF-8")) {writer.write("你好,UTF-8!");} catch (IOException e) {e.printStackTrace();}// 读取:指定UTF-8编码try (InputStreamReader reader = new InputStreamReader(new FileInputStream("utf8.txt"), "UTF-8")) {char[] buffer = new char[1024];int len;while ((len = reader.read(buffer)) != -1) {System.out.print(new String(buffer, 0, len)); // 输出:你好,UTF-8!}} catch (IOException e) {e.printStackTrace();}}
}
注意:编码名称需严格匹配(如 "UTF-8" 而非 "utf8"),否则会抛出
UnsupportedEncodingException。
四、总结与最佳实践
- 字符流适用场景:处理文本数据(如
.txt、.csv、.java),避免字节流处理文本时的手动编码转换。 - 核心类关系:
Reader/Writer是抽象父类,FileReader/FileWriter是文件处理实现类,InputStreamReader/OutputStreamWriter是带编码控制的转换流。 - 编码最佳实践:
- 优先使用 UTF-8 编码(跨平台兼容性好)。
- 避免使用
FileReader/FileWriter(默认编码易导致乱码),推荐用InputStreamReader/OutputStreamWriter并显式指定编码。 - 读写同一文件时,确保编码一致。
- 资源管理:始终用 try-with-resources 语法关闭流,避免资源泄露。
掌握字符流的核心原理和编码规则,能让你在处理文本文件时游刃有余,远离乱码烦恼。下一篇将讲解缓冲字符流(BufferedReader/BufferedWriter),进一步提升 IO 效率。