Post-training-of-llms TASK05
大模型训练方法后优化比较
| 方法 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| 监督微调(SFT) | 通过最大化示例回答的概率来模仿目标响应模式 | 1.实现简单 2.可快速启动模型新行为 | 可能降低训练数据未涵盖任务的性能 |
| 在线强化学习(Online RL) | 通过最大化回答的奖励函数进行优化 | 提升模型能力的同时在未见任务上性能下降较少 | 1.实现复杂度最高 2.需要精心设计奖励函数 |
| 直接偏好优化(DPO) | 通过对比学习鼓励优质回答/抑制劣质回答 | 1.有效修正错误行为 2.针对性提升特定能力 | 1.可能出现过拟合 2.实现复杂度介于SFT和在线RL之间 |
性能保持分析
在线强化学习为何比SFT更少降低性能?
核心机制差异:
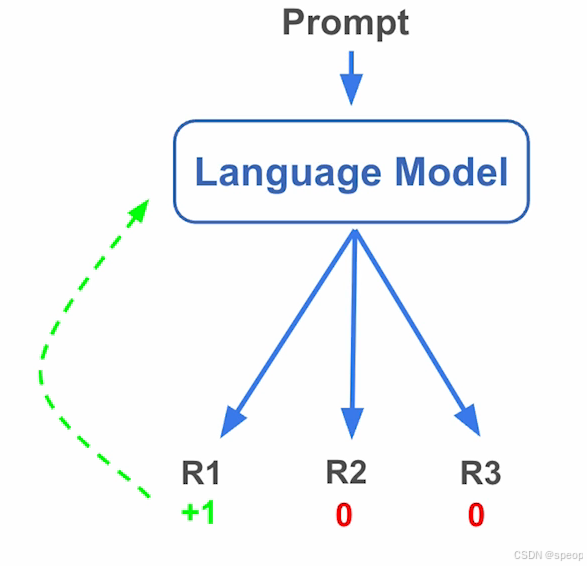
- 在线强化学习(OnlineRL):
模型生成多组回答(R1,R2,R3)→获取奖励信号→在模型原生能力空间内调整权重→ 保持模型生成分布稳定性
模型先生成多组回答(R1、R2、R3 等),再通过奖励信号筛选优质回答,最终在模型 “原生能力空间内” 调整权重。这种方式相当于在模型原本的生成逻辑基础上做 “优化升级”,因此能保持生成分布的稳定性,最大程度保留模型原有的泛化能力。
- 监督微调(SFT)
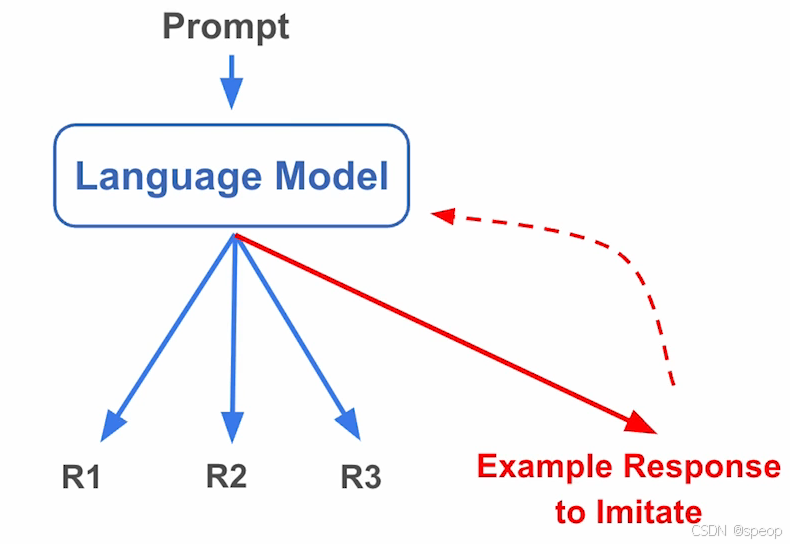
要求模仿的示例答案可能与模型*自然生成分布**存在根本差异→ 强制模型偏离原始能力空间→权重发生非必要改变
它要求模型强行模仿给定的示例答案,但这些示例可能和模型 “自然生成的分布” 存在本质差异。这种 “强行模仿” 会迫使模型偏离原始能力空间,导致权重发生很多非必要的改变 —— 相当于让模型放弃了一部分原生的泛化能力,因此在未见过的任务上更容易性能跳水。
监督微调(SFT)的示例答案是人为挑选或构造的,可能存在以下差异:
- 风格差异:示例可能要求更正式、更简短的表达,而模型原生生成可能更口语化或详细。
- 知识偏差:示例中的知识细节可能和模型预训练中学习到的通用知识存在冲突。
- 推理路径差异:示例的推理步骤可能和模型原生的推理逻辑不一致。
从机器学习的分布泛化理论来看:
- 模型的泛化能力依赖于 “训练分布” 和 “测试分布” 的一致性。SFT 的训练分布(示例答案)和模型原生的生成分布(测试时的自然任务分布)差异过大,导致分布偏移。
- 模型为了拟合示例,会调整自身的权重参数,这些调整可能破坏了原生能力中的 “通用特征”,进而在未见过的任务上(属于原生分布但不属于示例分布的场景)表现骤降。
假设模型是一位擅长写各种风格文章的作家(原生能力空间,包含 “叙事逻辑”“词汇运用”“情感表达” 等通用特征)。
原生状态:它能写科幻小说、散文、新闻稿,风格多样但都符合语言规律(这对应模型未经过 SFT 时,在各类任务上的泛化能力)。
强行模仿(SFT):现在要求它只模仿 “官方公文” 的风格(示例答案的分布)。为了写好公文,它必须调整自己的 “写作参数”—— 比如刻意用套话、压缩情感表达、强化格式规范。
破坏通用特征:这些调整可能会 “扭曲” 它原本的 “叙事逻辑”(比如写小说时本该有情节起伏,却习惯性地写得像公文一样刻板),也可能让它的 “词汇库” 变得单一(只会用公文词汇,不会用文学性词汇)。
未见过的任务表现骤降:当让它去写一篇 “科幻小说”(属于原生分布但不属于公文分布的场景)时,它可能因为之前的参数调整,写出来的内容既不像公文也不像合格的小说 —— 这就是 “在未见过的任务上表现骤降”。
监督微调(SFT)的逻辑是模仿固定的示例回答,它仅在训练数据覆盖的场景下表现较好。一旦遇到训练数据未涵盖的任务,模型因缺乏适配新场景的学习机制,性能就会明显下降。
在线强化学习(Online RL)的核心是通过奖励函数持续优化回答,它不局限于模仿已有示例,而是在和环境的交互中不断学习如何在新场景下做出更优决策。这种基于奖励的动态优化机制,让模型能更好地泛化到未见任务,因此在性能的鲁棒性上更具优势,更少出现因任务覆盖不足而导致的性能跳水。