基于langchain,通过RAG实现问答式定制化回复
GitHub上的LangChain是一个用于构建LLM(Large Language Model)驱动应用程序的框架。它可以帮助你将可互操作的组件(interoperable components)和第三方集成链接在一起,从而简化AI应用程序的开发,同时随着底层技术的发展,做出面向未来的决策(future-proofing decisions)。源码地址: https://github.com/langchain-ai/langchain ,最新发布版本为1.0.0,License为MIT。
LangChain通过一个包含模型、嵌入、向量存储(models, embeddings, vector stores)等功能的标准接口,帮助开发者构建由LLM驱动的应用程序。LangChain框架可以独立使用,也能与任何LangChain产品无缝集成,为开发者构建LLM应用程序提供全套工具。
langchain-community可能后面会逐渐废弃,这里使用独立包langchain-huggingface、langchain-chroma、langchain-ollama替代langchain-community。
以下测试代码是将 https://blog.csdn.net/fengbingchun/article/details/153526949 中基于Ollama和sentence-transformers的实现调整为基于langchain:
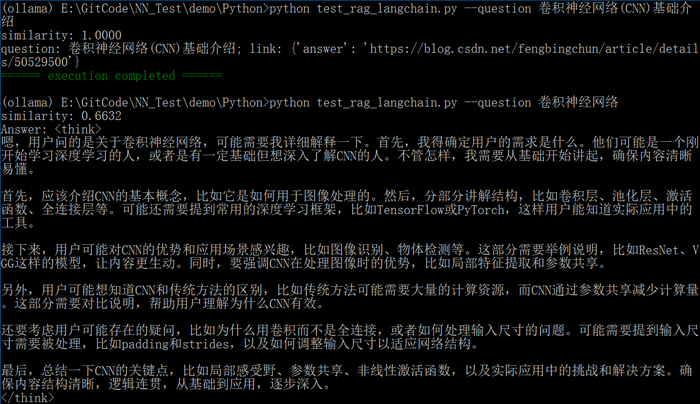
def parse_args():parser = argparse.ArgumentParser(description="rag qa chat: langchain")parser.add_argument("--llm_model", type=str, default="qwen3:1.7b", help="llm model name")parser.add_argument("--embed_model", type=str, default="BAAI/bge-small-zh-v1.5", help="Embedding model name")parser.add_argument("--jsonl", type=str, default="csdn.jsonl", help="jsonl(JSON Lines) file")parser.add_argument("--db_dir", type=str, default="chroma_db_langchain", help="vector database(chromadb) storage path")parser.add_argument("--similarity_threshold", type=float, default=0.8, help="similarity threshold, the higher the stricter")parser.add_argument("--question", type=str, required=True, help="question text")args = parser.parse_args()return argsdef load_embed_model(model_name):return HuggingFaceEmbeddings(model_name=model_name,model_kwargs={"device": "cpu"},encode_kwargs={"normalize_embeddings": True})def load_jsonl_docs(jsonl):docs = []with open(jsonl, "r", encoding="utf-8") as f:for line in f:try:data = json.loads(line.strip())doc = Document(page_content = data.get("question", ""),metadata = {"answer": data.get("answer", "")})docs.append(doc)except json.JSONDecodeError as e:print(colorama.Fore.RED + f"Error parsing line: {e}")continueprint(f"number of loaded data items: {len(docs)}")return docsdef build_vector_db(db_dir, jsonl, embed_model):db_path = Path(db_dir)if db_path.exists() and any(db_path.glob("*")):return Chroma(persist_directory=db_dir, embedding_function=embed_model, collection_name="csdn_qa_langchain")else:docs = load_jsonl_docs(jsonl)return Chroma.from_documents(documents=docs, embedding=embed_model, persist_directory=db_dir, collection_name="csdn_qa_langchain")def retrieve_answer(vectorstore, similarity_threshold, question):results = vectorstore.similarity_search_with_score(question, k=1)if not results:return Nonedoc, score = results[0]similarity = 1 - scoreprint(f"similarity: {similarity:.4f}")if similarity >= similarity_threshold:return f"question: {doc.page_content}; link: {doc.metadata}"return Nonedef chat(llm_model_name, embed_model_name, jsonl, db_dir, similarity_threshold, question):embed_model = load_embed_model(embed_model_name)vectorstore = build_vector_db(db_dir, jsonl, embed_model)ans = retrieve_answer(vectorstore, similarity_threshold, question)if ans:print(ans)else:try:chat = ChatOllama(model=llm_model_name, streaming=True)print("Answer: ", end="", flush=True)for chunk in chat.stream([HumanMessage(content=question)]):print(chunk.content, end="", flush=True)print() # line breakexcept Exception as e:print(f"Error: {e}")if __name__ == "__main__":colorama.init(autoreset=True)args = parse_args()chat(args.llm_model, args.embed_model, args.jsonl, args.db_dir, args.similarity_threshold, args.question)print(colorama.Fore.GREEN + "====== execution completed ======")这里问答式数据来自于本人的csdn博客,question为博客标题,answer为对应标题的链接,csdn.jsonl内容示例如下:
{"question": "C++20中线程类std::jthread的使用", "answer": "https://blog.csdn.net/fengbingchun/article/details/152172174"}
{"question": "通过提示词工程(Prompt Engineering)方法重新生成从Ollama下载的模型", "answer": "https://blog.csdn.net/fengbingchun/article/details/151902070"}
{"question": "使用C++实现与Ollama通信:ollama-hpp", "answer": "https://blog.csdn.net/fengbingchun/article/details/151677357"}
{"question": "Ollama Python库的使用", "answer": "https://blog.csdn.net/fengbingchun/article/details/151286661"}
{"question": "解析、创建Excel文件的开源库OpenXLSX介绍", "answer": "https://blog.csdn.net/fengbingchun/article/details/151259362"}
{"question": "Qt中的QSS介绍", "answer": "https://blog.csdn.net/fengbingchun/article/details/151020879"}
{"question": "深度学习中的模型量化及实现示例", "answer": "https://blog.csdn.net/fengbingchun/article/details/150703580"}
{"question": "图像相似度算法汇总及Python实现", "answer": "https://blog.csdn.net/fengbingchun/article/details/150451109"}
{"question": "深度学习中的模型知识蒸馏", "answer": "https://blog.csdn.net/fengbingchun/article/details/149878692"}
{"question": "深度学习中基于响应的模型知识蒸馏实现示例", "answer": "https://blog.csdn.net/fengbingchun/article/details/150112972"}输出如下所示:
GitHub:https://github.com/fengbingchun/NN_Test