【DINOv3】(2)下载DINOv3项目和预训练模型
欢迎关注【AGI使用教程】 专栏
【DINOv3】DINOv3 技术报告
【DINOv3】(1)下载与使用
【DINOv3】(2)下载DINOv3项目和预训练模型
【DINOv3】(2)下载DINOv3项目和预训练模型
- 1. 下载DINOv3项目和预训练模型
- 1.1 DINOv3项目资源与下载地址
- 1.2 下载DINOv3项目
- 1.3 下载预训练主干模型 (Backbones)
- 预训练主干模型介绍
- 使用wget 下载预训练主干模型
- 使用PyTorch Hub加载预训练主干模型
- 通过Hugging Face Transformers库加载预训练主干模型
- 使用 [Pipeline] 类下载预训练主干模型
- 使用 [AutoModel] 类下载预训练主干模型
- 1.4 下载预训练的适配器
- 1. 图像分类(Image Classification)预训练检测头。
- 2. 目标检测(Object Detection)预训练检测头。
- 3. 语义分割(Semantic Segmentation)预训练检测头。
- 4. 单目深度估计(Depth Estimation)预训练检测头。
- 5. 图文对齐/多模态理解(Vision–Language Alignment)预训练检测头。
DINOv3 是 Meta 推出的通用的、SOTA 级的视觉基础模型。模型通过无标注数据训练,生成高质量的高分辨率视觉特征,适用图像分类、语义分割、目标检测等多任务。
DINOv3 拥有 70 亿参数,训练数据量达 17 亿张图像,性能全面超越弱监督模型,模型支持多种模型变体适应不同计算需求。
1. 下载DINOv3项目和预训练模型
1.1 DINOv3项目资源与下载地址
DINOv3项目下载地址如下。
- 项目地址:https://ai.meta.com/dinov3/
- 代码路径:github-dinov3,huggingface-dinov3
- 研究论文:arXiv-DINOv3,meta-DINOv3
DINOv3 的模型权重(预训练模型参数)不能直接公开下载,而是需要先申请访问链接。申请通过后,Meta会发一封邮件给出所有模型权重下载地址(URL)的清单。
这些权重包括:
- backbone(主干网络),例如 ViT-B/14、ConvNeXt 等;
- adapter(适配模块),比如用于不同任务的轻量结构。
具体地,根据项目资源中的链接(https://ai.meta.com/resources/models-and-libraries/dinov3-downloads/)申请获取所有模型权重。申请获批后,系统将发送一封电子邮件,内含指向全部可用权重(含主干网络与适配器)的完整 URL 列表。
1.2 下载DINOv3项目
- 方法一:克隆 repo。
git clone https://github.com/facebookresearch/dinov3.git
cd dinov3
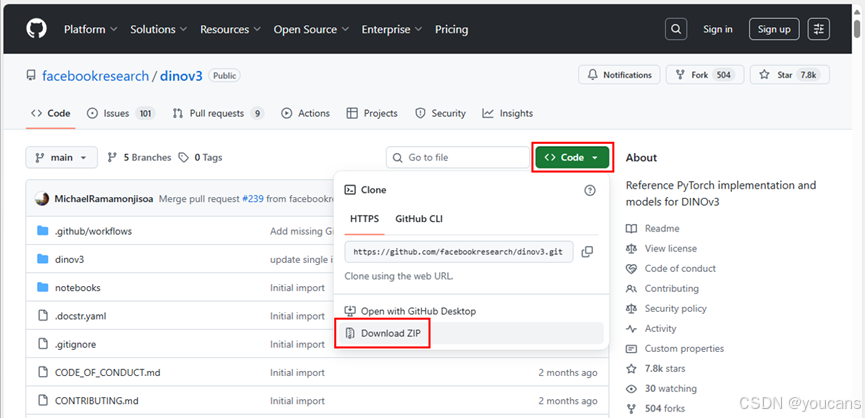
- 方法二:直接从 GitHub 网页下载压缩文件。
没有安装 git 的同学,可以在 GitHub 网站的 DINOv3项目页面,点击绿色的 “<>Code”,选择 “Download ZIP”,可以下载 DINOv3项目的压缩包。
1.3 下载预训练主干模型 (Backbones)
DINOv3 提供3种方式获取预训练主干模型(wget 下载、PyTorch Hub 加载、Hugging Face Transformers 加载),选择其中一种方式即可。
预训练主干模型介绍
DINOv3 提供了三类预训练模型:分别是在LVD-1689M网络数据集上训练的通用 ViT 模型、高效 ConvNeXt 模型,以及在SAT-493M卫星遥感影像上训练的空间结构感知 ViT 模型。
- ViT (LVD-1689M):使用ViT(Vision Transformer)架构在包含约 16.89 亿张图片的LVD-1689M网络数据集上预训练的模型,擅长通用视觉理解任务,适合各类自然图像任务(分类/检测/分割等)。
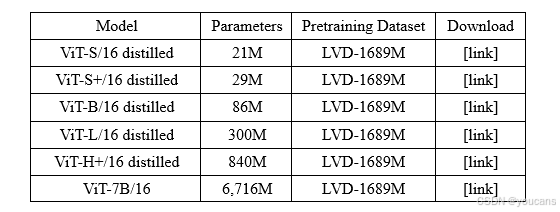
-
ConvNeXt (LVD-1689M):使用ConvNeXt(改进的卷积网络)架构在LVD-1689M网络数据集上预训练的模型,其资源需求较低,推理速度较高,适合对实时性、计算效率要求高的轻量化任务和边缘设备。包括Tiny、Small、Base、Large等不同规模的预训练模型。
-
ViT (SAT-493M):使用ViT(Vision Transformer)架构在包含约 4.93 亿张图片的SAT-493M卫星遥感数据集上预训练的模型,特征侧重地表结构、几何纹理、空间模式,适合遥感、地理、地图、农林监测任务。包括ViT-L/16 distilled、ViT-L/16等不同规模的模型。
使用wget 下载预训练主干模型
DINOv3 的模型权重(预训练模型参数)不能直接公开下载,而是需要先申请访问链接。申请通过后,Meta会发一封邮件给出所有模型权重下载地址(URL)的清单。
获得这些 URL 后,可以:
- 将模型或适配器权重下载至本地文件系统,再通过 weights 或 backbone_weights 参数将 torch.hub.load() 指向这些本地权重;
- 也可直接调用 torch.hub.load(),通过 weights 或 backbone_weights 参数从 URL 在线下载并加载主干网络或适配器。
模型权重文件很大,浏览器下载容易失败中断。因此推荐使用 wget(支持自动续传)而非网页浏览器下载。
wget -c https://dinov3.llamameta.net/dinov3_vits16/ dinov3_vits16_pretrain_***.pth?Policy=
使用PyTorch Hub加载预训练主干模型
通过 PyTorch Hub 可以加载 DINOv3 的预训练主干模型(backbone),但也需要申请链接。
加载前只要先安装 PyTorch即可,而不需要额外安装其它包。推荐安装带CUDA的PyTorch包。
import torch
REPO_DIR = "/path/to/dinov3" # 本地克隆的 DINOv3 仓库# ViT(web 预训练模型)
dinov3_vitb16 = torch.hub.load(REPO_DIR, 'dinov3_vitb16',
source='local', weights="<CHECKPOINT_URL_OR_PATH>")
...
# ConvNeXt(web 预训练模型)
dinov3_convnext_tiny = torch.hub.load(REPO_DIR,
'dinov3_convnext_tiny', source='local',
weights="<CHECKPOINT_URL_OR_PATH>")
...
# ViT(卫星预训练模型)
dinov3_vitl16_sat = torch.hub.load(REPO_DIR, 'dinov3_vitl16',
source='local', weights="<CHECKPOINT_URL_OR_PATH>")
...
通过Hugging Face Transformers库加载预训练主干模型
DINOv3 的预训练模型已上传到了 Hugging Face Hub(一个模型托管平台)。使用 Transformers 库(>= 4.56.0)可以直接加载这些模型,无需单独下载权重或访问 Meta 内部链接。这种方法不需要从Meta申请链接。
通过 Hugging Face Transformers 库下载模型,需要登录Hugging Face并输入访问令牌(token)。具体操作步骤如下:
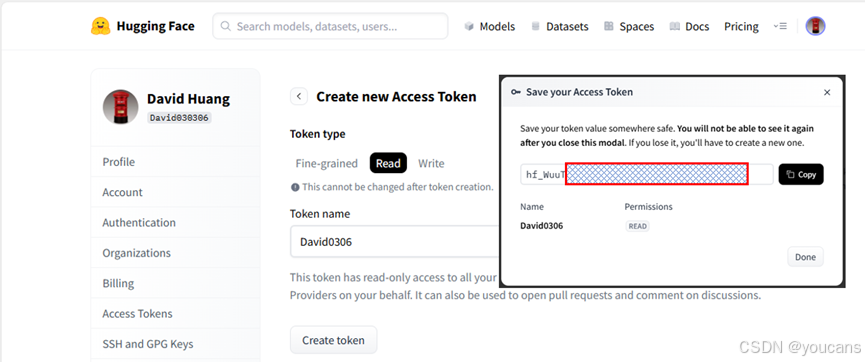
- 如下图所示,在 Hugging Face 官网的用户设置中生成访问令牌:“Account Settings → Access Tokens → New token”。注意Token只在生成时显示一次,请复制并安全保存Token,且不要显式暴露在公开代码中。
- 安装 Hugging Face 命令行工具。通常已随 transformers 库安装,也可单独安装:“pip install huggingface-hub”。
- 命令行输入 “hf auth login –token=hf_***” ,按提示输入Hugging Face访问令牌。
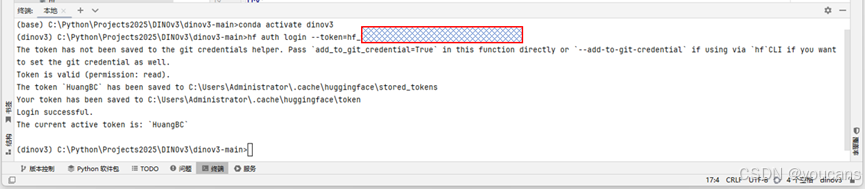
Hugging Face 提供了两种常用的模型使用方式:(1)用 pipeline一行代码完成下载或推理;(2)用 AutoModel 和 AutoImageProcessor 灵活处理输入输出。
使用 [Pipeline] 类下载预训练主干模型
我们首先介绍使用 [Pipeline] 类,用一行代码就可以完成下载或推理。
# 自动下载 DINOv3 模型(如 ConvNext-lvd1689m)
feature_extractor = pipeline(model="facebook/dinov3-convnext-tiny-pretrain-lvd1689m",task="image-feature-extraction",
)
使用模型参数 “model” 指定 DINOv3 模型版本,官方支持的模型名称如下。
facebook/dinov3-vits16-pretrain-lvd1689m
facebook/dinov3-vits16plus-pretrain-lvd1689m
facebook/dinov3-vitb16-pretrain-lvd1689m
facebook/dinov3-vitl16-pretrain-lvd1689m
facebook/dinov3-vith16plus-pretrain-lvd1689m
facebook/dinov3-vit7b16-pretrain-lvd1689m
facebook/dinov3-convnext-base-pretrain-lvd1689m
facebook/dinov3-convnext-large-pretrain-lvd1689m
facebook/dinov3-convnext-small-pretrain-lvd1689m
facebook/dinov3-convnext-tiny-pretrain-lvd1689m
facebook/dinov3-vitl16-pretrain-sat493m
facebook/dinov3-vit7b16-pretrain-sat493m
首次运行时会自动下载模型文件。模型会被下载到 Hugging Face 的默认缓存目录:“C:\Users\用户名.cache\huggingface\hub”。
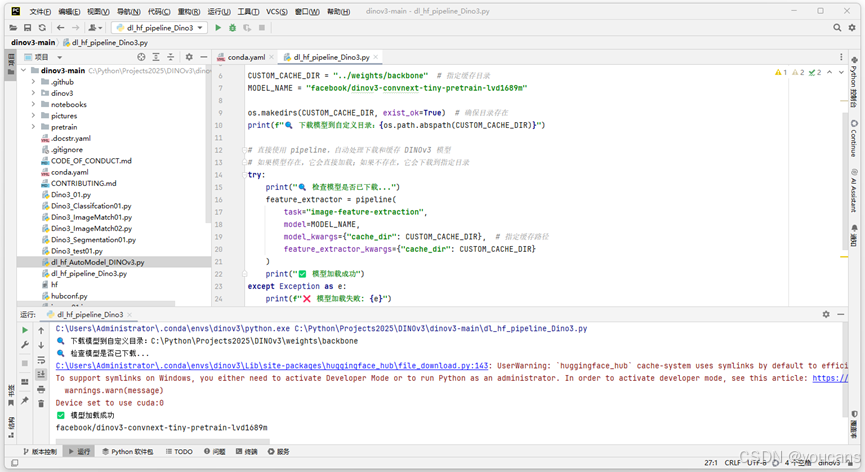
如果要修改模型下载路径,可以在创建 pipeline时使用 cache_dir 参数直接指定缓存目录。完整的例程dl_hf_pipeline_Dino3.py如下。
# hf auth login --token=hf_******
# Use a pipeline as a high-level helper
import os
from transformers import pipelineCUSTOM_CACHE_DIR = "../weights/backbone" # 指定缓存目录
MODEL_NAME = "facebook/dinov3-convnext-tiny-pretrain-lvd1689m"os.makedirs(CUSTOM_CACHE_DIR, exist_ok=True) # 确保目录存在
print(f"🔍 下载到自定义目录:{os.path.abspath(CUSTOM_CACHE_DIR)}")# 直接使用 pipeline,自动处理下载和缓存 DINOv3 模型
# 如果模型存在,它会直接加载;如果不存在,它会下载到指定目录
try:print("🔍 检查模型是否已下载...")feature_extractor = pipeline(task="image-feature-extraction",model=MODEL_NAME,model_kwargs={"cache_dir": CUSTOM_CACHE_DIR}, # 指定缓存路径feature_extractor_kwargs={"cache_dir": CUSTOM_CACHE_DIR})print("✅ 模型加载成功")
except Exception as e:print(f"❌ 模型加载失败: {e}")首次运行时会自动下载模型文件。模型会被下载到 cache_dir 参数指定的缓存目录 “DinoV3\weights\backbone”。
DinoV3/
├── dinov3-maian/
└── weights/└── backbone/└── models--facebook--dinov3-convnext-tiny-pretrain-lvd1689m/
使用 [AutoModel] 类下载预训练主干模型
我们介绍使用如何使用 [AutoModel] 类来下载模型和获取图像特征。
例程 dl_hf_ AutoModel _Dino3.py 自动下载并加载 DINOv3模型,然后对本地图片执行标准预处理与推理,得到高层语义特征向量。
- 加载与下载模型。
程序首先指定模型名称MODEL_NAME和自定义缓存目录CUSTOM_CACHE_DIR,确保模型文件统一保存在项目路径中。接着通过 AutoModel.from_pretrained() 和 AutoImageProcessor.from_pretrained() 自动下载并加载模型权重与图像预处理配置。 - 处理本地图像并提取特征
程序使用 load_image() 从本地路径加载图片,通过 processor()将图像转换为模型输入格式和执行标准预处理,得到 PyTorch 张量 [1, 3, H, W]。接着调用 model(**inputs) 前向推理,模型输出包括:- last_hidden_state:每个图像 patch 的特征表示;
- pooler_output:整张图片的全局语义向量。
最后打印 pooled_output 的形状(如 [1, 384]),代表模型对该图片的高维语义嵌入结果,可用于相似度计算、聚类、检索等视觉任务。
# hf auth login --token=hf_******
import os
import torch
from transformers import AutoModel, AutoImageProcessor
from transformers.image_utils import load_imageCUSTOM_CACHE_DIR = "../weights/backbone" # 指定缓存目录
MODEL_NAME = "facebook/dinov3-vits16plus-pretrain-lvd1689m"
IMAGE_PATH = "./pictures/image01.png" # 本地图像路径try:# 使用 AutoModel 自动处理下载和缓存 DINOv3 模型# 如果模型存在,它会直接加载;如果不存在,它会下载到指定目录processor = AutoImageProcessor.from_pretrained(MODEL_NAME, cache_dir=CUSTOM_CACHE_DIR)model = AutoModel.from_pretrained(MODEL_NAME, cache_dir=CUSTOM_CACHE_DIR)model.eval()print("✅ 模型与处理器加载成功")
except Exception as e:print(f"❌ 模型加载失败: {e}")raise SystemExitif not os.path.exists(IMAGE_PATH):raise FileNotFoundError(f"找不到图像文件: {IMAGE_PATH}")image = load_image(IMAGE_PATH) # 返回 RGB numpy 数组
inputs = processor(images=image, return_tensors="pt")with torch.no_grad():outputs = model(**inputs)# ==== 输出结果信息 ====
pooled = outputs.pooler_output
print(f"✅ pooled_output shape: {pooled.shape}")
# ==== 可选:打印部分结果 ====
print(f"🔹 pooled_output dtype: {pooled.dtype}")
print(f"🔹 前5个数: {pooled[0, :5]}")程序运行结果如下。
✅ 模型与处理器加载成功
✅ pooled_output shape: torch.Size([1, 384])
🔹 pooled_output dtype: torch.float32
🔹 前5个数: tensor([ 0.1237, -0.6076, -1.3511, 0.1754, 0.6451])
1.4 下载预训练的适配器
DINOv3 主干模型(backbone)是自监督预训练的,只提取通用图像特征。
适配器 “adapter” 是指在主干模型上加的一段训练模块,用来适配特定任务(如图像分类、分割等)。因此,在使用时不用训练整个巨大的模型,只需加载 backbone + adapter 就能执行任务。
官方发布了5种预训练的下游任务适配器(pretrained heads/adapters),文件名遵循如下格式:
dinov3_-.pth
其中, 为使用的主干模型, 为微调或下游训练所用数据集, 为任务类型的检测头, 为哈希码(版本标识)。文件仅包含 head 层的参数,不包含 backbone 本体。
1. 图像分类(Image Classification)预训练检测头。
dinov3_vit7b16_imagenet1k_linear_head-90d8ed92.pth:DINOv3 ViT-7B/16 模型在 ImageNet-1K 上训练的线性分类检测头,输出类别概率向量 [batch, 1000],适用于通用图像分类,可以用作特征微调实验的基准模型。
# Pretrained heads - Image classification
# Backbone:ViT-7B/16
# Pretraining Dataset:LVD-1689M
# Head Dataset:ImageNetimport torch# DINOv3
dinov3_vit7b16_lc = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_lc', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)# https://dinov3.llamameta.net/dinov3_vit7b16/dinov3_vit7b16_imagenet1k_linear_head-90d8ed92.pth?Policy=******
2. 目标检测(Object Detection)预训练检测头。
dinov3_vit7b16_coco_detr_head-b0235ff7.pth,DINOv3 ViT-7B/16 模型在 Coco数据集上训练的DETR结构检测头,输出物体框+类别标签列表,适用于通用物体检测、密集检测。
3. 语义分割(Semantic Segmentation)预训练检测头。
dinov3_vit7b16_ade20k_m2f_head-bf307cb1.pth:DINOv3 ViT-7B/16 模型在 ADE20K 语义分割数据集上训练的M2F语义分割检测头(Mask2Former head),输出语义分割掩膜 [batch, num_classes, H, W],适用于城市和室内场景分割、语义分割。
4. 单目深度估计(Depth Estimation)预训练检测头。
dinov3_vit7b16_synthmix_dpt_head-02040be1.pth:DINOv3 ViT-7B/16 模型在 SYNTHMIX合成深度图像数据集上训练的单目深度估计解码头dpt_head,输出深度图 [batch, 1, H, W],适用于自动驾驶、3D重建、VR 场景理解。
5. 图文对齐/多模态理解(Vision–Language Alignment)预训练检测头。
dinov3_vitl16_dinotxt_vision_head_and_text_encoder-a442d8f5.pth:包含文本编码器和和视觉头。模型可以同时处理图片和文本输入,实现类似 CLIP 的图文匹配与检索。输出视觉与文本的特征向量,适用于图文检索、多模态语义理解。
depther = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_dd', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
版权声明:
youcans@qq.com 原创作品,转载必须标注原文链接:
【DINOv3】(2)下载DINOv3项目和预训练模型
Copyright@youcans 2025
Crated:2025-10