一、基础预训练模型与能力
1.1 主流预训练模型(文本/多模态)
预训练模型是多模态学习的核心基础,通过在大规模数据上的先验学习,为下游任务提供通用语义表示能力。根据处理模态的差异,可分为文本单模态模型和图文多模态模型两大类。
1.1.1 文本预训练模型
文本模型聚焦于语言语义的理解与生成,三大经典模型(BERT、GPT、T5)分别代表了“理解型”“生成型”“统一框架型”三种核心范式,其底层均基于Transformer架构,但设计逻辑差异显著。
BERT(Bidirectional Encoder Representations from Transformers)
- 核心定位:“语言理解专家”,专注于文本上下文的深度语义提取,是Encoder-only架构的标杆。
- 技术原理:
- 基础架构:仅采用Transformer的Encoder模块,通过多层双向自注意力机制实现“全句上下文感知”——模型在处理每个词时,能同时参考左侧和右侧的所有文本信息。
- 关键创新:突破传统单向语言模型的局限,首次让模型真正“读懂”句子的完整语义逻辑。
- 预训练任务:
- 掩码语言模型(MLM):随机遮蔽输入文本中15%的词(如将“猫在追老鼠”改为“猫在[MASK]老鼠”),让模型预测被遮蔽的词,强制学习词汇间的依赖关系。
- 下一句预测(NSP):输入一对句子,让模型判断第二个句子是否是第一个句子的自然后续,强化对句间逻辑关系的理解(如“天气很好”和“我们去野餐”为连续句,“天气很好”和“数学公式很复杂”为非连续句)。
- 关键特点:
- 优势:在文本分类、命名实体识别、问答等“理解类任务”上表现卓越,微调时仅需添加简单的任务特定头(如分类层)即可适配。
- 局限:无文本生成能力,上下文处理长度有限(基础版仅支持512个token)。
- 典型应用:情感分析(判断“这部电影太精彩了”为正面情绪)、法律文书条款提取、医疗病历实体识别。
- 演进方向:轻量化优化(如DistilBERT压缩60%参数仍保持97%性能)、知识注入(如ERNIE通过遮蔽实体/短语增强知识理解)。
GPT(Generative Pretrained Transformer)
- 核心定位:“文本生成大师”,以自回归方式实现长文本的连贯生成,是Decoder-only架构的代表,奠定了生成式AI的基础。
- 技术原理:
- 基础架构:仅采用Transformer的Decoder模块,通过“掩码自注意力”机制强制实现“左向上下文依赖”——模型生成每个词时,仅能参考已生成的左侧文本(包括前文和已生成的部分),无法提前查看右侧内容。
- 生成逻辑:基于概率分布的迭代生成,每个词的选择都依赖于前文语境的概率计算,保证文本的连贯性和逻辑性。
- 预训练任务:仅采用“下一词预测(Next Token Prediction)”——给定前文文本(如“人工智能的核心技术是”),模型预测最可能出现的下一个词(如“Transformer”),通过海量文本的迭代训练形成语言生成能力。
- 关键特点:
- 优势:生成文本的语义连贯性极强,支持长文本续写(如小说创作、代码补全),大尺度模型(如GPT-3、GPT-4)展现出惊人的泛化能力。
- 局限:对文本的深层逻辑理解弱于BERT,训练和推理的计算资源消耗极高。
- 典型应用:对话机器人(ChatGPT的核心基座)、代码自动生成(GitHub Copilot)、科幻小说创作、邮件自动撰写。
- 演进方向:参数规模扩张(从GPT-1的1.17亿参数到GPT-4的万亿级参数)、多模态融合(GPT-4V支持图像输入)、指令微调优化(通过人类反馈强化学习提升输出质量)。
T5(Text-to-Text Transfer Transformer)
- 核心定位:“全能语言处理框架”,将所有文本任务统一为“文本输入→文本输出”的生成模式,是Encoder-Decoder架构的集大成者。
- 技术原理:
- 基础架构:采用完整的Transformer Encoder-Decoder结构,Encoder负责理解输入文本,Decoder负责生成输出文本,两者通过跨注意力机制传递信息。
- 统一范式:无论任务类型(分类、翻译、摘要等),均转换为“输入文本+任务描述→目标文本”的格式,例如:
- 文本分类:输入“情感分析:这部电影太精彩了”,输出“positive”;
- 翻译:输入“翻译为英语:我爱中国”,输出“I love China”。
- 预训练任务:“文本片段掩码预测”——与BERT的单字掩码不同,T5会遮蔽连续的文本片段(如将“机器学习是人工智能的分支”改为“[MASK]是人工智能的分支”),让模型生成完整的被遮蔽片段,更贴近真实生成场景。
- 关键特点:
- 优势:任务适应性极强,无需为不同任务设计专属架构,通过多任务训练实现知识共享(如翻译任务的语言能力可辅助摘要生成)。
- 局限:Encoder-Decoder结构计算复杂度最高,对硬件资源要求苛刻。
- 典型应用:跨语言翻译(支持100+语言)、新闻摘要生成(将1000字新闻压缩为100字摘要)、多任务对话系统(同时支持问答、翻译、日程规划)。
- 演进方向:指令微调(通过人类指令数据提升零样本能力)、轻量化变体(如T5-small、T5-base适配边缘设备)。
文本模型核心差异对比
| 维度 | BERT(Encoder-only) | GPT(Decoder-only) | T5(Encoder-Decoder) |
|---|---|---|---|
| 核心能力 | 文本理解 | 文本生成 | 理解+生成(全场景) |
| 注意力机制 | 双向自注意力(全句可见) | 单向掩码注意力(仅看前文) | Encoder双向+Decoder单向 |
| 预训练核心任务 | MLM+NSP | 下一词预测 | 文本片段掩码预测 |
| 微调方式 | 加任务特定头 | Prompt工程 | 文本格式适配 |
| 计算资源需求 | 较低(仅Encoder) | 较高(生成需迭代计算) | 最高(双模块叠加) |
| 代表应用场景 | 情感分析、问答 | 对话生成、创作 | 翻译、摘要、多任务处理 |
1.1.2 多模态预训练模型
多模态模型聚焦于图文模态的语义对齐与融合,解决"图像看懂语言、语言描述图像"的核心问题。从早期的双塔对齐到后期的深度融合,模型逐步实现了从"模态匹配"到"跨模态推理"的升级。
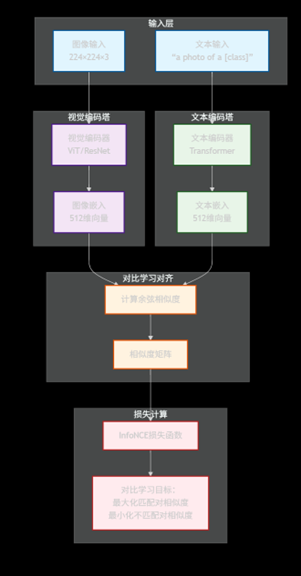
CLIP(Contrastive Language-Image Pretraining)
-
核心定位:“图文对齐奠基人”,通过对比学习实现图文语义的跨模态统一,是零样本图像识别的突破之作(OpenAI 2021年提出)
-
技术原理:
- 架构设计:经典"双塔结构",由两个独立的编码器组成:
- 视觉编码器(采用ViT或ResNet)处理图像
- 文本编码器(采用BERT变体)处理文本
- 两者通过"对比学习"在统一语义空间中对齐
- 对齐逻辑:输入大规模图文对(如"狗的图片"+“a dog”),模型通过计算图像嵌入与文本嵌入的余弦相似度,让匹配的图文对相似度最高,不匹配的图文对相似度最低(类似"找朋友":让真朋友站得近,陌生人站得远)
- 架构设计:经典"双塔结构",由两个独立的编码器组成:
-
预训练任务:图像-文本对比学习(ITC)
具体公式为:
sim=cosine_similarity(img_embed,txt_embed) \text{sim} = \text{cosine\_similarity}(\text{img\_embed}, \text{txt\_embed}) sim=cosine_similarity(img_embed,txt_embed)
loss=−log(exp(sim(i,i))∑exp(sim(i,j))) \text{loss} = -\log\left(\frac{\exp(\text{sim}(i,i))}{\sum \exp(\text{sim}(i,j))}\right) loss=−log(∑exp(sim(i,j))exp(sim(i,i)))
其中sim(i,i)\text{sim}(i,i)sim(i,i)为匹配图文对的相似度,sim(i,j)\text{sim}(i,j)sim(i,j)为所有图文对的相似度总和 -
关键特点:
- 零样本能力:无需任何任务特定训练,仅通过文本提示即可完成图像分类(如输入提示"猫的图片"“狗的图片”,模型能自动为图像匹配正确标签)
- 数据依赖:依赖海量弱监督图文对(训练数据达4亿对),数据规模直接决定对齐效果
-
典型应用:
- 零样本图像分类(识别罕见植物种类)
- 跨模态检索(输入"红色日落的海边"找到对应图片)
- 图文匹配(判断"猫在睡觉"与图片是否相符)
-
架构示意图:
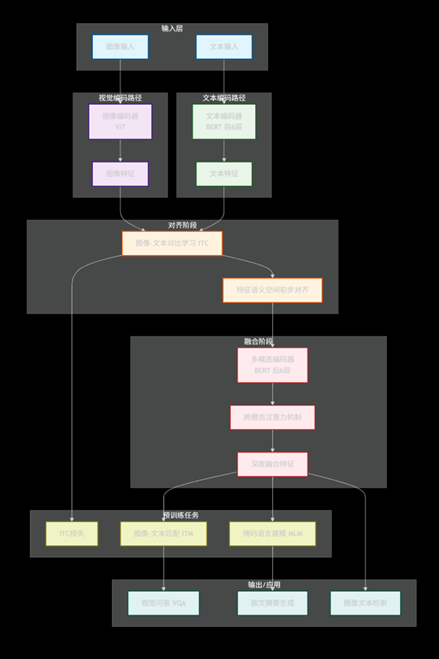
ALBEF(Aligning Language and Vision with BERT-style Training)
-
核心定位:“精细对齐专家”,提出“Align Before Fuse(先对齐后融合)”理念,通过多任务训练提升图文语义的精准匹配度。
-
技术原理:
- 架构设计:采用“视觉编码器+文本编码器+跨模态交互层”的混合结构,视觉端用ViT提取特征,文本端用BERT提取特征,通过跨注意力实现模态交互。
- 核心创新:解决传统模型中“视觉特征与文本特征错位”的问题——先通过对齐任务让图文语义初步匹配,再进行深度融合。
-
预训练任务(三任务协同):
- 图像-文本对比学习(ITC):同CLIP,实现粗粒度语义对齐。
- 图像-文本匹配(ITM):判断图文对是否语义一致(如“飞机在天上飞”与飞机图片为匹配,“飞机在天上飞”与轮船图片为不匹配),提升细粒度对齐精度。
- 掩码语言建模(MLM):对文本中的词进行掩码,结合图像信息预测被遮蔽的词(如“[MASK]在草地上跑”+狗的图片,模型预测“狗”)。
-
关键特点:
- 动量蒸馏:引入“动量编码器”(冻结的教师模型),通过学生模型与教师模型的预测差异优化训练,提升泛化能力。
- 无需目标检测器:避免传统模型依赖Faster R-CNN提取物体特征导致的模态错位问题,直接用ViT处理原始图像。
-
典型应用:视觉问答(VQA,如“图中动物有几条腿?”结合图片回答“4条”)、图文摘要生成(根据图片生成带细节的描述)。
-
架构示意图:
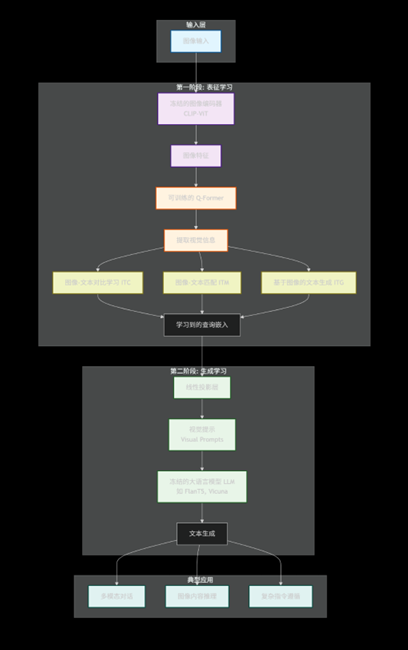
BLIP-2(Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models)
- 核心定位:“模态桥接标杆”,通过轻量级中间模块实现视觉与大语言模型(LLM)的高效融合,解决多模态模型训练成本过高的问题。
- 技术原理:
- 架构设计:采用“冻结视觉编码器+冻结LLM+可训练Q-Former”的三段式结构——视觉编码器(如CLIP的ViT)和LLM(如LLaMA、Flan-T5)均保持参数冻结,仅通过中间的“查询Transformer(Q-Former)”实现模态转换。
- 核心创新:Q-Former作为“翻译官”,将高维视觉特征转换为LLM可理解的语言类token,既复用了已有大模型的能力,又避免了全模型训练的巨额成本。
- 预训练阶段:
- 第一阶段:训练Q-Former与视觉编码器对齐,让Q-Former能提取视觉关键信息。
- 第二阶段:将Q-Former的输出作为“软提示”输入LLM,进行跨模态预训练,实现“看图说话”能力。
- 关键特点:
- 成本优势:冻结千亿参数的LLM仅训练百万级参数的Q-Former,训练成本降低10倍以上。
- 能力叠加:继承LLM的语言生成与推理能力,可完成复杂跨模态任务(如根据电路图解释工作原理)。
- 典型应用:多模态对话(同时理解“展示红色连衣裙图片”的文本指令和实际图片)、图像内容推理(“图中人物的职业可能是什么?为什么?”)。
- 架构示意图:
Flamingo(DeepMind提出的多模态生成模型)
- 核心定位:“跨模态推理先锋”,首次实现语言模型在生成过程中对视觉信息的动态引用,是“生成式多模态”的里程碑。
- 技术原理:
- 架构设计:基于冻结的LLM(如Chinchilla)扩展,新增“视觉编码器”和“跨模态注意力层”——图像先经视觉编码器转换为视觉token,再通过跨模态注意力层与文本token融合,输入LLM进行生成。
- 关键创新:引入“门控跨模态注意力”,让模型在生成文本时可“主动参考”视觉细节(如生成“图中猫的颜色是____”时,模型会动态聚焦图像中猫的像素区域)。
- 预训练任务:多模态续写任务——输入“图文混合序列”(如图片+“这只猫的动作是”),让模型续写完整描述(如“跳跃,正在追逐一只蝴蝶”)。
- 关键特点:
- 动态视觉感知:区别于CLIP的静态匹配,Flamingo能在生成过程中实时调用视觉信息,支持复杂推理(如“对比两张图片的差异并说明”)。
- 多模态扩展:可轻松集成音频、视频等其他模态(视频视为“图像序列+时间信息”)。
- 典型应用:视频内容解说(根据足球比赛视频实时生成解说词)、跨模态创作(结合风景图片写一首诗)、视觉逻辑推理(“根据电路图,说明开关闭合后电流的流向”)。
1.1.3 文本与多模态模型的核心关联
多模态模型本质是文本模型的“模态扩展”:
- 技术复用:多模态模型的语言侧普遍依赖成熟文本模型(如BLIP-2用LLaMA作LLM基座,CLIP文本编码器基于BERT)。
- 能力迁移:文本模型的泛化能力(如GPT的上下文学习)可直接赋能多模态任务(如Flamingo的跨模态对话)。
- 融合趋势:最新模型(如GPT-4V、Gemini)已实现“文本-图像-音频”的统一建模,模糊了单模态与多模态的边界。
1.2 模型泛化能力描述
泛化能力是预训练模型的核心价值——指模型将大规模预训练中习得的通用能力,迁移到未见过的任务、数据或场景的能力。四大关键能力(零样本、少样本、上下文学习、缩放规律)共同定义了模型的“通用智能水平”。
1.2.1 零样本学习(Zero-shot Learning)
- 定义:模型在未见过任何下游任务样本的情况下,仅通过自然语言指令或任务描述,直接完成任务的能力。核心是“通过语言理解任务逻辑”。
- 核心逻辑:预训练阶段习得的“世界知识”与“语言-语义映射关系”,让模型能通过任务描述(如“判断以下句子是否为正面情绪”)推断任务目标,无需任何任务特定训练数据。
- 典型示例:
- 图像分类:给未训练过“垃圾分类”任务的CLIP输入提示“可回收垃圾的图片”“厨余垃圾的图片”,模型能正确为新图片打标签。
- 文本翻译:让仅训练过英语-法语的GPT模型翻译“我爱中国”到西班牙语,通过指令“将中文句子翻译为西班牙语”即可输出“Te amo China”。
- 关键价值:打破“每任务必微调”的限制,大幅降低模型适配新场景的成本,是“通用人工智能”的核心标志之一。
1.2.2 少样本学习(Few-shot Learning)
- 定义:模型在仅获得极少量下游任务样本(通常1-100个)的情况下,即可完成任务适配的能力。核心是“通过示例快速学习任务模式”。
- 核心逻辑:样本作为“任务模板”,帮助模型快速定位任务边界(如输入输出格式、标签分布),再结合预训练知识完成预测。与微调的区别在于:少样本学习通常不更新模型参数,仅通过输入示例引导。
- 典型示例:
- 情感分析:给模型输入3个示例(“电影很棒→正面”“剧情无聊→负面”“演员演技差→负面”),模型即可正确判断新句子“画面太震撼了”为正面情绪。
- 实体识别:通过“苹果发布了新手机→苹果(公司)”“我吃了个苹果→苹果(水果)”的示例,让模型区分多义词的实体类型。
- 关键价值:解决“长尾任务数据稀缺”问题(如专业领域的故障诊断文本极少),是工业场景中模型落地的关键能力。
1.2.3 上下文学习(In-context Learning, ICL)
- 定义:模型在单次输入中,通过“任务描述+示例+待解决问题”的组合提示,直接输出答案的能力。核心是“实时从上下文提取任务规则”,无需任何参数更新或额外训练。
- 核心逻辑:预训练过程中习得的“序列模式识别能力”,让模型能自动识别输入中的“示例-规则-问题”对应关系,本质是一种“隐式微调”——规则通过上下文传递,而非通过参数更新固化。
- 典型示例(数学计算任务):
- 输入提示:“任务:计算两个数的和。示例1:3+5=8;示例2:10+7=17;问题:15+9=?”
- 模型输出:“24”(无需训练数学计算模块,仅通过上下文示例学会“求和规则”)。
- 关键特点:
- 依赖Prompt设计:示例的数量、格式、质量直接影响效果(通常3-5个高质量示例即可达到较好效果)。
- 与少样本的区别:少样本可多次输入示例进行适配,上下文学习是“单次输入、一次解决”,更贴近人类的“即时学习”模式。
- 关键价值:赋能对话式AI的“即时任务处理”(如用户临时让ChatGPT“按APA格式整理参考文献”,仅需给1个示例即可实现)。
1.2.4 模型缩放规律(Scaling Law)
定义
描述模型性能与"模型参数量、训练数据量、计算资源"三者之间的数学关系,核心结论是"性能随资源规模增长按幂律提升,且未出现明显天花板",为大模型的设计与优化提供理论指导。
核心数学关系
性能与资源的关系遵循幂律分布,通用公式为:
性能∝Nα×Dβ×Cγ \text{性能} \propto N^\alpha \times D^\beta \times C^\gamma 性能∝Nα×Dβ×Cγ
其中:
- NNN:模型参数量(如GPT-3的1750亿参数)
- DDD:训练数据量(如CLIP的4亿图文对)
- CCC:训练计算量(以FLOPs为单位)
- α,β,γ\alpha,\beta,\gammaα,β,γ:经验常数(语言模型中α≈0.07\alpha\approx0.07α≈0.07),代表各资源对性能的贡献权重
关键结论
-
规模效应显著:GPT-3的实验表明,参数量从1亿增至1750亿时,语言建模困惑度(越低越好)持续下降,且未出现饱和迹象。
-
数据-模型匹配:“Chinchilla法则"指出,最优性能需满足"计算量C≈20×C \approx 20 \timesC≈20×参数量NNN”,数据量不足会导致大模型"吃不饱"(欠拟合),数据过量则浪费资源。
-
多模态扩展:原生多模态模型的缩放规律与文本模型一致(如早融合架构的性能随计算量增长的指数为-0.049,与GPT-3的-0.048接近),且早融合在小参数规模下效率更高。
实践价值
-
资源分配:若目标将模型误差降低50%,需将计算量增加10倍(基于γ=−0.5\gamma=-0.5γ=−0.5推算)
-
成本控制:在资源有限时,优先扩大数据量(β\betaβ通常大于α\alphaα)比单纯加参更高效
-
趋势预判:揭示"更大即更好"的底层逻辑,但边际收益递减(参数量超万亿后,性能提升成本急剧增加)
1.2.5 四大泛化能力的递进关系
四大能力并非孤立存在,而是呈现“阶梯式递进”的逻辑:
- 基础:Scaling Law是前提——只有足够规模的模型(参数量、数据量),才能涌现出零样本、少样本能力。
- 进阶:少样本学习依赖“示例引导”,是零样本能力的补充(零样本搞不定时,给几个示例即可)。
- 高阶:上下文学习是少样本的“即时化形态”,将“示例学习”融入单次输入,更贴近真实应用场景。
- 终极目标:通过四者协同,实现模型“无需训练、仅靠语言和示例即可适配任意任务”的通用智能。