【AI原生架构:数据架构】9、从打破数据孤岛到价值升维,企业数据资产变现全流程

前言:数据时代的“价值困境”——为何175ZB数据中只有20%在创造价值?
据IDC最新预测,2025年全球数据圈规模将突破175ZB,相当于每个地球人平均拥有21TB数据。但残酷的现实是:80%以上的企业正陷入“数据沉睡”困境——ERP、CRM、IoT设备等系统产生的结构化、非结构化数据分散在孤立的“数据烟囱”中,形成难以打通的“数据孤岛”;脏数据、低质量数据占据30%以上的存储资源,导致数据无法支撑业务决策;更有甚者,企业将数据架构视为“技术工具”而非“战略资产”,以应用为中心的设计让数据沦为业务系统的附属,永远停留在“记录业务”的初级阶段。
破解这一困境的核心,在于搭建一套能让数据“活起来”的数据架构——它不是Hadoop、Flink等工具的简单堆砌,而是从数据采集、存储、处理到服务、应用的全链路设计,是连接“数据资源”与“业务价值”的桥梁。
本文将结合实战案例、核心代码与可视化图表,从认知、设计、落地三个维度,详解数据架构如何推动数据价值从“记录业务”到“驱动创新”的升维,帮助企业真正将数据转化为核心资产。
一、数据架构的核心认知:从“技术支撑”到“战略顶层设计”
1.1 重新定义数据架构:不止是“技术框架”,更是“业务-数据耦合体系”
数据架构是企业数据资产的“顶层设计蓝图”,它定义了数据从“产生”到“消费”的全生命周期规则,包含四大核心要素:
- 数据模型:定义数据的结构、关系与业务含义(如客户主数据模型、交易数据模型);
- 数据流转路径:明确数据在业务系统、存储层、服务层、应用层之间的流动规则;
- 技术栈选型:根据业务需求选择采集(Flink CDC)、存储(Hudi、Iceberg)、计算(Spark、Flink)工具;
- 组织与治理机制:建立数据 ownership、质量标准与安全规则(如数据脱敏、权限管控)。
关键认知:数据架构必须与业务架构深度耦合。例如:
- 零售企业的“精准营销”业务目标,需要数据架构支持用户行为数据(APP点击)、交易数据(订单)、商品数据(库存)的实时整合;
- 制造业的“预测性维护”需求,依赖数据架构对设备IoT数据(温度、振动)与运维数据(维修记录)的时序存储与流处理能力。
1.2 当前数据架构的核心痛点:不止是“数据孤岛”,更是“认知孤岛”
传统数据架构的问题远超“数据分散”,其本质是**“认知的孤岛”**——企业缺乏对数据的统一认知,每个业务部门、每个应用系统都按自身需求定义数据,导致底层数据缺乏一致性(如同自然界没有统一的DNA、互联网没有统一的TCP/IP协议)。具体表现为:
- 架构碎片化:以应用为中心设计,数据随业务系统拆分而分散(如财务系统的“客户”与销售系统的“客户”字段定义不同);
- 事后治理成本高:先建业务系统再处理数据,数据质量问题(如重复数据、字段缺失)需后期投入3倍以上成本修复;
- 价值视角局限:仅关注单应用的数据价值(如财务系统只看“客户付款记录”),忽略企业整体视角的交叉价值(如“客户付款记录+APP浏览记录”可预测复购率)。
案例对比:某电商企业早期按“商品、订单、用户”三个业务系统设计数据存储,用户ID在订单系统为“user_id”(字符串),在用户系统为“uid”(数字),导致后续用户画像建设时,需投入2个月时间做数据映射与清洗;而若事前设计统一的主数据模型,这一成本可降低80%。
1.3 数据价值升维的三大基石:在线、连接、流动
要实现数据价值升维,必须先夯实三大基础能力),这三大能力如同“水的三态”——在线是“液态”(数据可见)、连接是“气态”(数据联动)、流动是“固态”(数据落地),三者缺一不可:
1.3.1 基石一:数据在线——让数据“可见、可访问”
“数据在线”是数据价值的前提,指企业内所有业务数据(结构化、非结构化)都能被统一发现、访问,核心动作包括:
- 数据接入在线:通过CDC(变更数据捕获)、日志采集(Flume、Logstash)、API拉取等方式,将业务系统数据实时/准实时接入统一存储层;
- 数据元数据在线:建立数据目录(如Apache Atlas),记录数据的来源、字段含义、owner、血缘关系,让用户通过搜索快速找到所需数据;
- 数据质量在线:实时监控数据质量(如完整性、准确性),通过仪表盘展示异常数据(如订单金额为空、用户手机号格式错误),并触发告警。
实战类比:如同歼-10C战斗机的数据链系统,所有传感器(雷达、发动机、导航)的数据必须“在线可见”,飞行员才能实时掌握战机状态;若某一传感器数据离线,将直接影响作战决策。
1.3.2 基石二:数据连接——让数据产生“化学反应”
“数据连接”是数据价值升维的核心,指通过统一的“数据枢纽”(如主数据、知识图谱)打破数据间的壁垒,让分散的数据产生联动价值。核心实现方式包括:
- 主数据枢纽连接:识别企业核心主数据(如客户、商品、组织),建立统一的主数据模型与编码规则(如客户主数据包含“统一客户ID、姓名、联系方式、所属行业”),作为数据连接的“桥梁”;
- 知识图谱连接:对非结构化数据(如客服对话、维修报告)进行实体识别(如“客户A”“产品B”“故障类型C”),构建实体关系网络(如“客户A购买了产品B→产品B出现故障类型C”);
- 大模型Token化连接:借鉴大模型的Token处理逻辑,将传统One-hot编码的“孤立特征”转化为“语义关联Token”(如“红色”“连衣裙”“夏季”三个Token可关联为“夏季红色连衣裙”),提升数据的关联性。
实战案例:某银行通过客户主数据枢纽,将信用卡系统的“客户消费数据”、房贷系统的“客户还款数据”、理财系统的“客户持仓数据”连接,构建“客户360视图”,发现“房贷还款稳定+理财持仓高”的客户,其信用卡分期违约率降低40%,据此优化了分期授信策略。
1.3.3 基石三:数据流动——让数据在价值链中“创造价值”
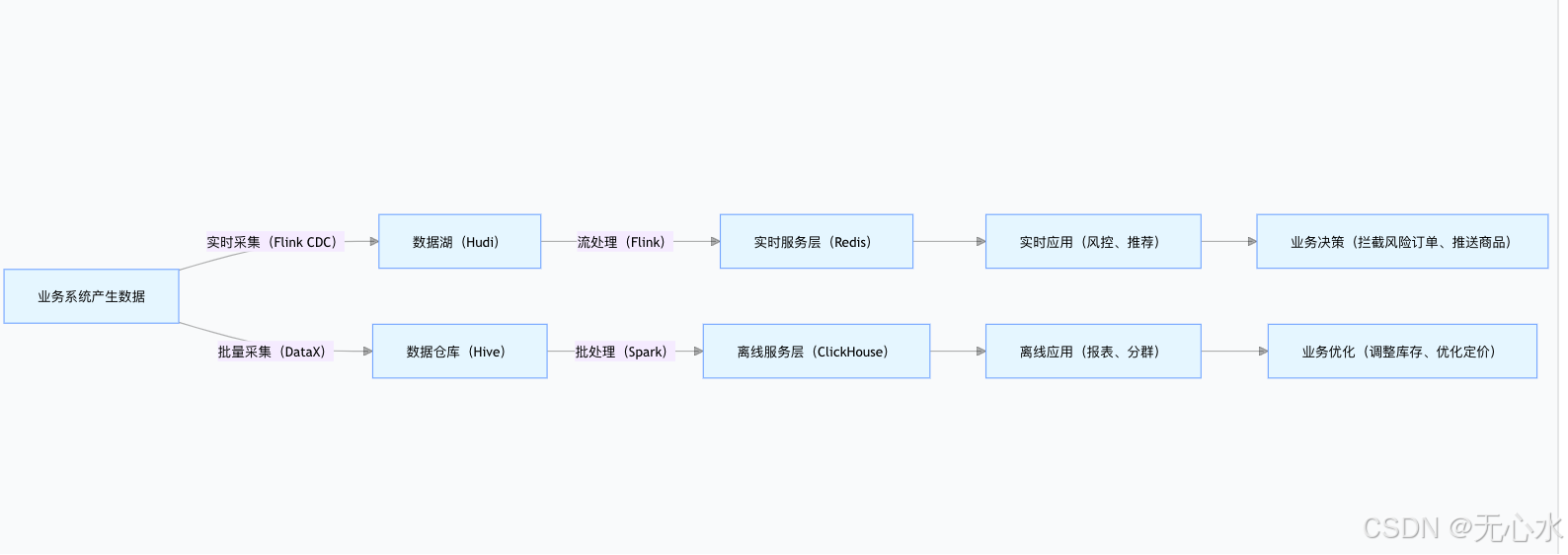
“数据流动”是数据价值的落地保障,指数据按业务需求在“采集层→存储层→服务层→应用层”顺畅流转,避免数据“沉睡”在存储中。核心流转场景包括:
- 实时流动:对高时效性需求(如实时推荐、风控拦截),数据从采集到服务的延迟控制在秒级(如Flink流处理+Redis缓存);
- 批量流动:对离线分析需求(如月度销售报表、用户分群),数据按定时任务(如凌晨2点)批量处理,生成结构化结果;
- 按需流动:通过数据API(如RESTful、GraphQL)让业务应用“按需调用”数据服务(如营销系统调用“高价值客户列表”API),避免数据冗余传输。
可视化流程:数据流动的核心路径可通过mermaid图直观展示:
1.4 数据价值的双层认知模型:从“应用视角”到“企业视角”
“数据双层价值模型”,指出数据价值需从两个维度评估,只有同时满足才能实现升维:
| 价值维度 | 核心目标 | 评估标准 | 案例 |
|---|---|---|---|
| 第一层:应用维度 | 支撑单业务系统的正常运行 | 数据是否满足该应用的功能需求(如订单系统需“订单号、金额、状态”) | 财务系统的“发票数据”仅用于记账,不与其他系统联动 |
| 第二层:企业维度 | 为企业整体战略提供支撑 | 数据是否能跨部门、跨应用创造协同价值(如“发票数据+客户数据”可分析客户付费能力) | 财务系统的“发票数据”与销售系统的“客户数据”联动,生成“客户付费能力评分”,用于销售策略调整 |
关键结论:若数据仅停留在“应用维度”,永远只能“记录业务”;只有上升到“企业维度”,才能“驱动业务”。例如:某车企的“车辆故障数据”,若仅用于4S店维修(应用维度),价值有限;但当它与“供应链数据”(零部件批次)、“用户驾驶数据”(行驶习惯)联动(企业维度),可定位“某批次零部件+激烈驾驶”导致的故障,提前发起召回,降低品牌损失。
二、数据架构的设计演进:从“传统分层”到“现代智能架构”
2.1 传统分层架构vs现代数据架构:从“线性传递”到“中台化协同”
传统数据架构以“业务系统”为中心,采用线性分层设计,而现代数据架构以“数据中台”为核心,强调数据的统一治理与服务化,两者差异显著:
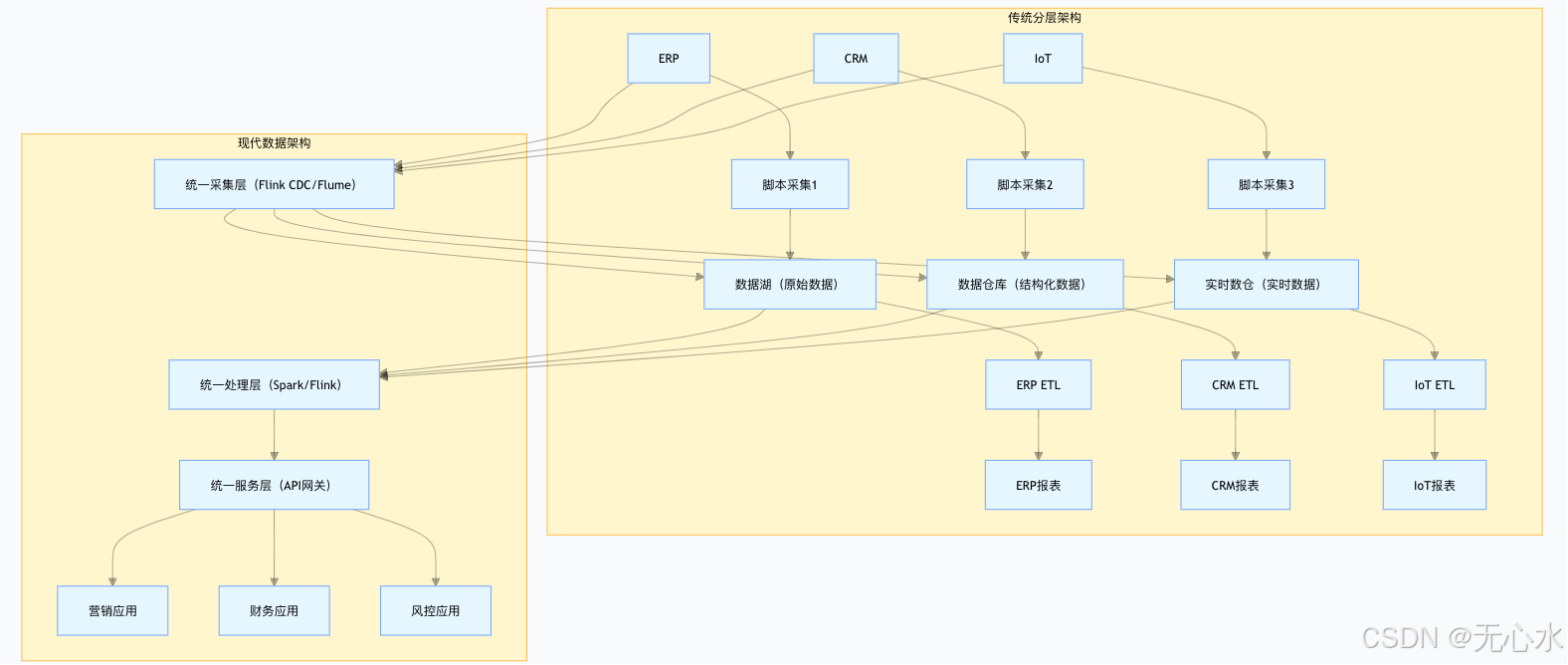
2.1.1 传统分层架构:“烟囱式”设计,数据难复用
传统架构的核心逻辑是“按业务系统拆分数据链路”,流程如下:
数据源(ERP/CRM/IoT) → 数据采集(脚本批量拉取) → 数据存储(业务库分表) → 数据处理(单系统ETL) → 数据应用(业务报表)
核心问题:
- 数据分散:每个业务系统有独立的采集、存储、处理链路,如“客户数据”同时存在于CRM、电商、财务系统,字段定义不统一;
- 复用性差:为某一报表开发的ETL脚本,无法复用于其他应用(如财务报表的“客户消费数据”无法直接给营销系统使用);
- 实时性低:依赖批量脚本拉取数据,延迟通常在小时级,无法支撑实时业务(如实时风控)。
2.1.2 现代数据架构:“中台化”设计,数据可复用、可服务
现代数据架构以“数据中台”为核心,将数据链路拆分为“统一采集层、存储层、服务层”,支持多业务应用复用,核心实现代码如下(Java示例):
// 现代数据架构核心分层实现(以数据中台为核心)
public class ModernDataArchitecture {// 1. 统一数据采集层:支持多类型数据接入,避免重复开发public interface DataCollector {void collectLogData(); // 日志数据(如APP点击日志)void collectBizData(); // 业务数据(如订单、客户,基于Flink CDC实时采集)void collectIoTData(); // 物联网数据(如设备传感器数据,MQTT协议接入)void collectExternalData(); // 外部数据(如第三方征信、天气数据,API拉取)}// 2. 混合存储层:数据湖存原始数据,数据仓库存结构化数据,实时数仓存实时结果public class DataStorageLayer {// 数据湖(Hudi/Iceberg):存储全量原始数据,支持数据回溯public DataLake dataLake;// 数据仓库(Hive/ClickHouse):存储清洗后的结构化数据,用于离线分析public DataWarehouse dw;// 实时数仓(Flink SQL + Kafka):存储实时处理结果,用于实时服务public RealTimeDW rtdw;}// 3. 统一数据服务层:将数据封装为API,供业务应用按需调用public class DataServiceLayer {// 客户360视图服务:整合多数据源的客户数据public DataAPI getCustomer360(); // 产品分析服务:提供商品销量、库存分析public DataAPI getProductAnalysis(); // 风险控制服务:实时返回客户风险评分public DataAPI getRiskControl(); }
}
核心优势:
- 统一接入:采集层支持多类型数据,避免每个业务系统重复开发采集脚本;
- 分层存储:原始数据(数据湖)、结构化数据(数据仓库)、实时数据(实时数仓)分离,兼顾灵活性与性能;
- 服务化复用:服务层将数据封装为API,营销、财务、风控系统可复用同一“客户360视图”API,避免数据冗余。
可视化对比:传统架构与现代架构的差异可通过mermaid图展示:
2.2 Lambda架构vsKappa架构:批流处理的两种实战选择
现代数据架构中,批处理(离线分析)与流处理(实时分析)的协同是核心难点,目前主流的两种解决方案是Lambda架构与Kappa架构,两者各有适用场景:
2.2.1 Lambda架构:“批流分离,最终一致”
Lambda架构通过“批处理层、速度层、服务层”三层设计,兼顾离线数据的准确性与实时数据的时效性,核心代码如下:
/*** Lambda架构实现:批流分离,服务层合并结果* 适用场景:对数据一致性要求高、离线分析需求重的场景(如金融报表、电商月度GMV统计)* 优点:容错性好(批处理层可修正实时层误差)、数据一致性高;* 缺点:维护两套系统(批处理+流处理),开发与运维成本高*/
public class LambdaArchitecture {// 1. 批处理层:处理全量历史数据,生成“不可变”的全量视图public void batchLayer(DataSource source) {// 夜间批量处理(如凌晨2点),基于Spark处理全量数据Dataset<Row> fullData = spark.read().format("parquet").load(source.getFullPath());Dataset<Row> batchResult = fullData.groupBy("user_id").agg(sum("amount").as("total_amount"));// 写入不可变存储(如Hive分区表,按日期分区)batchResult.write().mode(SaveMode.Overwrite).partitionBy("dt").saveAsTable("user_total_amount_batch");}// 2. 速度层:处理实时增量数据,生成“临时”的增量视图public void speedLayer(DataSource source) {// 基于Flink处理Kafka实时流数据(近1小时增量)DataStream<Row> realTimeData = flinkEnv.addSource(new FlinkKafkaConsumer(source.getTopic(), new SimpleStringSchema()));DataStream<Row> speedResult = realTimeData.keyBy("user_id").window(TumblingProcessingTimeWindows.of(Time.hours(1))).sum("amount");// 写入临时存储(如Redis)speedResult.addSink(new RedisSink<>());}// 3. 服务层:合并批处理层与速度层结果,提供统一查询public void servingLayer(String userId) {// 读取批处理层全量结果(截至前一天)double batchAmount = queryBatchResult(userId);// 读取速度层增量结果(当天近1小时)double speedAmount = querySpeedResult(userId);// 合并结果返回double totalAmount = batchAmount + speedAmount;return totalAmount;}
}
2.2.2 Kappa架构:“全流处理,简化架构”
Kappa架构摒弃批处理层,所有数据通过流处理引擎处理,通过“数据重放”实现历史数据回溯,核心代码如下:
/*** Kappa架构实现:全流处理,支持数据重放* 适用场景:实时性要求高、离线与实时逻辑一致的场景(如实时推荐、实时风控)* 优点:架构简单(仅维护一套流处理系统)、开发运维成本低;* 缺点:实时性要求高(流处理引擎需支撑高吞吐)、数据重处理复杂(需重新消费历史数据)*/
public class KappaArchitecture {// 1. 统一流处理层:处理实时与历史数据(通过Kafka数据重放)public void streamingLayer(DataSource source) {// 配置Kafka消费者,支持从指定offset消费(实时数据从最新offset,历史数据从0 offset)Properties props = new Properties();props.setProperty("bootstrap.servers", "kafka:9092");props.setProperty("group.id", "kappa-group");props.setProperty("auto.offset.reset", source.isReplay() ? "earliest" : "latest");// 基于Flink处理流数据(实时与历史逻辑一致)DataStream<Row> streamData = flinkEnv.addSource(new FlinkKafkaConsumer(source.getTopic(), new SimpleStringSchema(), props));DataStream<Row> streamResult = streamData.keyBy("user_id").window(TumblingProcessingTimeWindows.of(Time.minutes(5))).sum("amount");// 写入最终存储(如ClickHouse,同时支持实时查询与历史查询)streamResult.addSink(new ClickHouseSink<>());}// 2. 流式数据服务:直接查询流处理结果,提供实时服务public void streamingService(String userId) {// 从ClickHouse查询用户实时累计金额(无需合并批流结果)double totalAmount = clickHouseQuery("select sum(amount) from user_amount where user_id = ?", userId);return totalAmount;}
}
架构对比可视化:
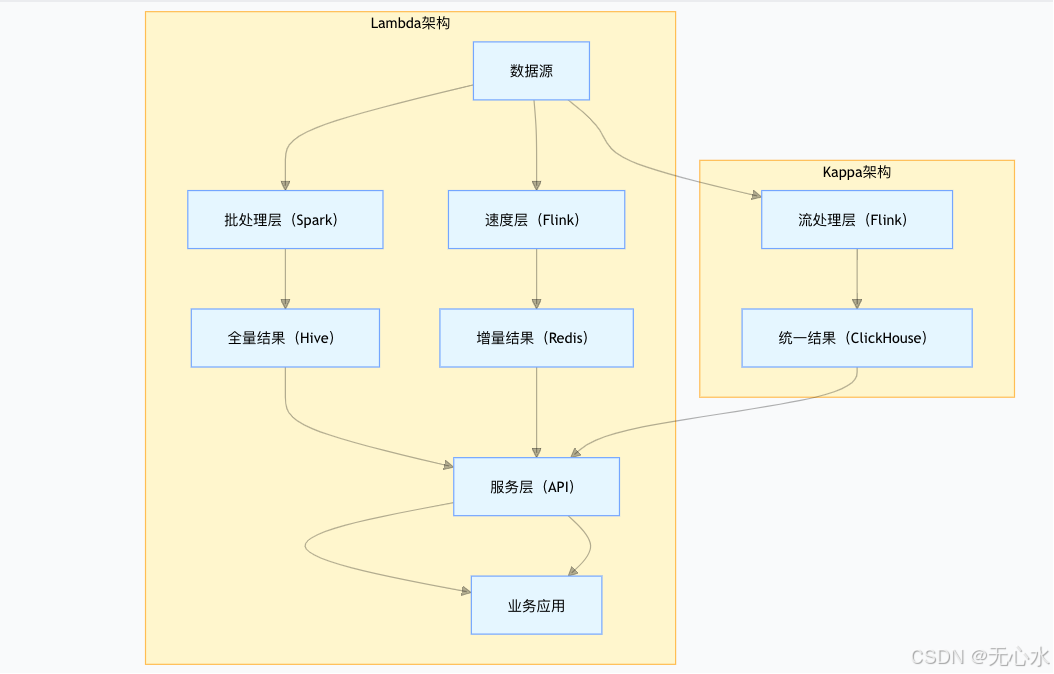
选择建议:
- 选Lambda:金融、政务等对数据一致性要求极高,且离线分析需求重的场景;
- 选Kappa:互联网、零售等实时性要求高,且批流逻辑一致的场景(如实时推荐、实时库存)。
三、数据价值升维的四阶段实战:从“原始数据”到“业务驱动”
数据价值的升维不是一蹴而就的,需经历“原始数据→可信数据→数据服务→数据智能→数据业务化”四个阶段,每个阶段有明确的目标、技术手段与实战代码:
3.1 阶段一:原始数据→可信数据——让数据“可用”
核心目标:解决数据“脏、乱、差”问题,形成高质量、可信任的数据集;
关键技术:数据质量监控、数据血缘追踪;
实战代码:数据质量监控与血缘追踪实现(Java):
public class DataTrustworthiness {// 1. 数据质量监控:从完整性、准确性、及时性三个维度校验数据public class DataQualityMonitor {/*** 完整性检查:必填字段是否为空(如订单表的“order_id、amount、status”)*/public boolean checkCompleteness(DataSet data) {return data.getFields().stream().allMatch(field -> !field.isRequired() || field.getValue() != null && !field.getValue().toString().isEmpty());}/*** 准确性检查:数据是否符合业务规则(如订单金额>0、手机号格式正确)*/public boolean checkAccuracy(DataSet data) {for (Field field : data.getFields()) {switch (field.getName()) {case "amount":if (Double.parseDouble(field.getValue().toString()) <= 0) {return false;}break;case "phone":if (!Pattern.matches("^1[3-9]\\d{9}$", field.getValue().toString())) {return false;}break;}}return true;}/*** 及时性检查:数据是否在有效期内(如实时订单数据延迟不超过5分钟)*/public boolean checkTimeliness(DataSet data) {LocalDateTime dataTime = data.getTimestamp();LocalDateTime now = LocalDateTime.now();return Duration.between(dataTime, now).toMinutes() <= 5;}/*** 执行全量质量检查,返回问题列表*/public List<String> checkDataQuality(DataSet data) {List<String> issues = new ArrayList<>();if (!checkCompleteness(data)) {issues.add("数据完整性不满足:必填字段为空");}if (!checkAccuracy(data)) {issues.add("数据准确性不满足:违反业务规则");}if (!checkTimeliness(data)) {issues.add("数据及时性不满足:延迟超过5分钟");}return issues;}}// 2. 数据血缘追踪:记录数据来源与流转路径,便于问题定位public class DataLineage {// 存储数据节点(如数据源表、目标表)private Map<String, DataNode> nodes = new HashMap<>();// 存储数据边(如ETL任务、数据转换)private Map<String, List<DataEdge>> edges = new HashMap<>();/*** 记录数据血缘:source(来源表)→ transformation(转换任务)→ target(目标表)*/public void trackLineage(String source, String transformation, String target) {DataNode sourceNode = nodes.computeIfAbsent(source, DataNode::new);DataNode targetNode = nodes.computeIfAbsent(target