【Agentic AI】提示链模式学习笔记
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G技术研究。
博客内容主要围绕:
5G/6G协议讲解
高级C语言讲解
Rust语言讲解
文章目录
- 一、提示链模式
- 二、单一提示词的局限性
- 三、结构化输出的作用
- 四、应用场景
- 4.1 信息处理工作流程
- 4.2 复杂查询回答
- 4.3 数据提取与转换
- 4.4 内容生成工作流程
- 4.5 具有状态的对话机器人
- 4.6 代码生成与优化
- 4.7 多模态和多步骤推理
- 五、代码练习
- 六、上下文工程与提示工程
- 总结
何为AI Agent?
AI Agent是一个通过感知周围环境并采取行动以实现特定目标的系统。它是从标准的大型语言模型(LLM)演变而来的,扩展了计划制定、工具使用和与周围环境交互的能力。它遵循一个简单的五步循环来完成任务:
- 获取任务:给它设定一个目标,比如“安排我明天的日程”;
- 环境感知:它会收集所有必要的信息。例如,阅读邮件、查看日程安排以及访问联系人,以了解正在发生的事情;
- 制定策略和计划:它通过考虑实现目标的最佳途径来制定策略和行动计划;
- 采取行动:它通过发送邀请、安排会议以及更新您的日历来执行计划;
- 学习并不断进步:它会观察成功的成果并据此进行调整。例如,如果会议被重新安排,系统会从这一事件中学习,以提升其未来的表现。
一、提示链模式
提示链,有时也被称为管道模式,是利用大型语言模型(LLM)处理复杂任务的一种强大范式。它主张采用分而治之的策略,而非期望 LLM 一次性解决复杂问题。其核心思想是将原本艰巨的任务分解为一系列较小、更易于处理的子问题。每个子问题都通过专门设计的提示词单独解决,而一个提示生成的输出会策略性地作为下一个提示的输入。
这种顺序处理技术在与 LLM 的交互中自然地引入了模块化和清晰性。通过分解复杂任务,每个单独步骤都更容易理解和调试,从而使整个过程更稳健、更易于解释。链中的每一步都可以精心设计和优化,专注于更大问题的特定方面,从而产生更准确和集中的输出。
前一步的输出作为后一步的输入至关重要。这种信息传递建立了一条依赖链,因此得名,其中先前操作的上下文和结果引导后续处理。这使得大语言模型能够在其先前工作的基础上进行构建,不断改进其理解,并逐步接近期望的解决方案。
此外,提示链不仅在于分解问题,还能够整合外部知识和工具。在每一步中,大语言模型都可以被指示与外部系统、应用程序编程接口(API)或数据库进行交互,从而丰富其知识和能力,超越其内部训练数据。这种能力极大地拓展了大语言模型的潜力,使它们不仅能够作为孤立的模型存在,还能成为更广泛、更智能系统中的关键组成部分。
提示链的重要性不仅在于简单的解决问题。它是构建复杂AI Agent的基础技术。这些Agent可以利用提示链在动态环境中自主规划、推理和行动。通过策略性地安排提示序列,Agent能够执行需要多步推理、规划和决策的任务。这样的Agent工作流能够更贴近人类的思维过程,从而在与复杂领域和系统交互时,实现更自然、更有效的沟通。
二、单一提示词的局限性
对于需要从多方面考虑的任务,使用一个复杂的提示词让 LLM 处理可能会:
效率低下,导致模型难以遵循约束和指令,可能会出现忽略指令的情况,即部分提示被忽略;- 还会出现
上下文偏离,即模型失去对初始上下文的把握; 错误传播,即早期错误被放大;- 提示需要
更大的上下文窗口,在此窗口中模型获得的信息不足,无法进行响应; - 以及
幻觉,即认知负荷增加导致错误信息出现的概率增大。
例如,一个要求分析市场研究报告、总结研究结果、识别数据点的趋势并起草电子邮件的查询,可能会失败,因为模型可能总结得很好,但无法正确提取数据或起草电子邮件。通过顺序分解提高可靠性:提示链通过将复杂任务分解为专注且有序的工作流程来解决这些问题,从而显著提高可靠性和控制力。以上述示例为例,可以将流程或链式方法描述如下:
- 初始提示(总结):“总结以下市场研究报告的关键发现:[文本]”。该模型的唯一重点是总结,以提高这第一步的准确性。
- 第二个提示(趋势识别):“利用总结内容,识别出三大新兴趋势,并提取支持每种趋势的具体数据点:[步骤 1 的输出结果]”。此提示现在更具约束性,并直接基于已验证的输出结果。
- 第三提示(邮件撰写):“为营销团队起草一封简洁的邮件,概述以下趋势及其支持数据:[步骤 2 的输出]”。
这种分解使得对流程的控制更加精细。每个步骤都更简单且更明确,这减少了模型的认知负荷,并导致更准确和可靠的最终输出。这种模块化类似于计算管道,其中每个函数执行特定操作,然后将其结果传递给下一个函数。为了确保每个特定任务的准确响应,模型可以在每个阶段被指定一个不同的角色。例如,在给定的场景中,初始提示可以指定为“市场分析师”,后续提示为“交易分析师”,第三个提示为“专业文档撰写人”,依此类推。
三、结构化输出的作用
提示链的可靠性在很大程度上取决于步骤之间传递的数据的完整性。如果一个提示的输出含糊不清或格式不佳,后续提示可能会因输入错误而失败。为了减轻这种情况,指定一种结构化的输出格式(如 JSON 或 XML)至关重要。
结构化格式确保数据是机器可读的,并且能够被准确解析并插入到下一个提示中,不会产生歧义。这种做法最大限度地减少了因解读自然语言而可能产生的错误,是构建稳健的、多步骤的基于 LLM 的系统的关键组成部分。
四、应用场景
提示链是一种在构建 Agent 系统时适用的通用模式,其在各种场景中都具有广泛的应用价值。其核心优势在于将复杂问题分解为一系列可操作的步骤。以下是几个实际应用和案例:
4.1 信息处理工作流程
许多任务需要通过多次转换来处理原始信息。例如,对文档进行摘要处理、提取关键信息,然后利用这些信息查询数据库或生成报告。提示链可以这样设计:
- 提示 1:从给定的 URL 或文档中提取文本内容;
- 提示 2:对清理后的文本进行摘要;
- 提示 3:从摘要或原始文本中提取特定信息(例如名称、日期、地点);
- 提示 4:使用这些信息在内部知识库中进行搜索。
- 提示 5:生成包含摘要、信息和搜索结果的最终报告。
这种方法应用于自动化内容分析、开发基于人工智能的研究助手以及复杂报告生成等领域。
4.2 复杂查询回答
回答那些需要多步骤推理或信息检索才能解决的复杂问题是一个主要的应用场景。例如:“1929 年股市崩盘的主要原因是什么,政府又是如何做出应对的?”
- 提示 1:确定用户查询中的核心子问题(崩盘的原因、政府的应对措施);
- 提示 2:专门研究或检索关于 1929 年崩盘原因的信息;
- 提示 3:专门研究或检索关于 1929 年股市崩盘后政府政策应对措施的信息;
- 提示 4:将步骤 2 和 3 中获取的信息整合成对原始查询的完整回答。
这种顺序处理方法对于开发能够进行多步骤推理和信息综合的人工智能系统至关重要。当一个查询无法从单个数据点中得到答案,而是需要一系列逻辑步骤或整合来自不同来源的信息时,就需要这样的系统。
例如,一个旨在生成特定主题的综合报告的Agent,会执行一种混合计算工作流程。起初,系统会检索大量相关文章。随后从每篇文章中提取关键信息的任务可以针对每个来源同时进行。这一阶段非常适合并行处理,即独立的子任务可以同时运行以实现效率最大化。
然而,一旦各个提取工作完成,整个过程就变成了一个顺序过程。系统必须首先整理提取的数据,然后将其整合成一个连贯的草稿,最后对其进行审查和优化以生成最终报告。这些后续阶段在逻辑上都依赖于前一阶段的成功完成。这就是应用提示链的地方:整理好的数据作为合成提示的输入,而由此产生的合成文本则成为最终审查提示的输入。因此,复杂的操作通常会将独立的数据收集的并行处理与合成和优化步骤的提示链结合在一起。
4.3 数据提取与转换
将非结构化的文本转换为结构化格式通常需要通过一个迭代过程来实现,这一过程需要逐步进行修改以提高输出的准确性和完整性。
- 提示 1:尝试从发票文档中提取特定字段(例如姓名、地址、金额);
- 处理:检查是否已提取所有必需的字段,并且这些字段是否符合格式要求。要求/条件
- 提示3(条件性):如果字段缺失或格式不正确,请创建一个新的提示,要求模型专门查找缺失或格式错误的信息,或许可以提供失败尝试时的相关背景信息;
- 处理:再次验证结果。如有必要,重复此步骤;
- 输出:提供提取并经过验证的结构化数据。
这种顺序处理方法特别适用于从非结构化来源(如表格、发票或电子邮件)中提取和分析数据。例如,解决复杂的光学字符识别(OCR)问题,如处理 PDF 表格,通过分解的多步骤方法处理会更有效。
首先,使用大型语言模型从文档图像中执行主要的文本提取。接下来,模型处理原始输出以规范化数据,在此步骤中,它可能会将数字文本(如“一千零五十”)转换为其数值等价物 1050。对于大型语言模型来说,执行精确的数学计算是一个重大挑战。因此,在后续步骤中,系统可以将任何所需的算术运算委托给外部计算器工具。LLM 会确定所需的计算过程,将标准化后的数字输入到工具中,然后将精确的结果整合进来。这种由文本提取、数据标准化以及外部工具使用所构成的连续流程,能够得出最终的、准确的结果,而这种结果往往难以通过单次 LLM 查询可靠地获得。
4.4 内容生成工作流程
复杂内容的编排是一项程序性任务,通常会被分解为不同的阶段,包括初始构思、结构概述、草稿撰写以及后续的修订。
- 提示 1:根据用户的总体兴趣生成 5 个主题想法;
- 处理:允许用户选择一个想法或自动选择最佳想法
- 提示 2:基于所选主题生成详细的大纲;
- 提示 3:根据大纲中的第一点撰写草稿部分;
- 提示 4:根据大纲中的第二点撰写草稿部分,并提供前一个部分作为背景信息。按照此流程对所有大纲要点进行操作;
- 提示 5:审查并完善完整的草稿,使其在连贯性、语气和语法方面达到最佳状态。
这种方法被应用于一系列自然语言生成任务中,包括自动创作创意故事、技术文档以及其他形式的结构化文本内容。
4.5 具有状态的对话机器人
尽管全面的状态管理架构所采用的方法比顺序链接更为复杂,但提示链技术为保持对话的连续性提供了一个基础机制。该技术通过将每次对话环节视为一个新的提示来维护上下文,该提示会系统性地整合对话序列中先前交互中提取的信息或实体。
- 提示 1:处理用户话语 1,识别意图和关键实体;
- 处理过程:根据意图和实体更新对话状态;
- 提示 2:基于当前状态,生成回复或确定下一个所需的信息;
- 对后续环节重复此过程,每次新的用户话语都会启动一个链式反应,该链利用累积的会话历史(状态);
这一原则对于对话机器人的开发至关重要,使它们能够在长时间的多轮对话中保持上下文和连贯性。通过保存对话历史,系统能够理解并恰当地响应依赖于先前交换信息的用户输入。
4.6 代码生成与优化
生成代码通常是一个多阶段的过程,需要将问题分解为一系列离散的逻辑操作,并逐步执行。
- 提示 1:理解用户对代码功能的要求,生成伪代码或大纲;
- 提示 2:根据大纲编写初始代码草稿;
- 提示 3:在代码中识别潜在的错误或需要改进的方面(可能使用静态分析工具或再次调用另一台大语言模型);
- 提示 4:根据识别出的问题重写或优化代码;
- 提示 5:添加文档或测试用例。
在诸如人工智能辅助软件开发这样的应用中,提示链的实用性源于其能够将复杂的编码任务分解为一系列可管理的子问题。这种模块化结构在每个步骤中都降低了大型语言模型的操作复杂性。至关重要的是,这种方法还允许在模型调用之间插入确定性逻辑,从而在工作流程中实现中间数据处理、输出验证和条件分支。通过这种方法,原本可能导致结果不可靠或不完整的单一多方面请求,会被转化为由底层执行框架管理的有序操作序列。
4.7 多模态和多步骤推理
处理具有多种模态的数据集需要将问题分解为更小的、基于提示的任务。例如,解读包含嵌入文本的图片、带有突出显示特定文本段落的标签以及解释每个标签的表格数据,就需要采用这样的方法。
- 提示 1:从用户提供的图片请求中提取并理解文本;
- 提示 2:将提取的图片文本与相应的标签相链接;
- 提示 3:使用表格来解读收集到的信息,以确定所需的输出。
五、代码练习
提示链的实现方式包括在脚本中进行直接的、顺序的函数调用,以及利用专门设计用于管理控制流、状态和组件集成的框架。诸如 LangChain、LangGraph、Crew AI 和谷歌代理开发工具包(ADK)等框架为构建和执行这些多步骤流程提供了结构化的环境,这对于复杂的架构尤其有利。
为了演示目的,LangChain 和 LangGraph 是合适的选择,因为它们的核心 API 明确设计用于构建操作链和图。LangChain 为线性序列提供了基础的抽象,而 LangGraph 则扩展了这些功能,以支持有状态和循环计算,这对于实现更复杂的代理行为是必要的。
本示例将重点介绍一个基本的线性序列。以下代码实现了一个作为数据处理管道的两步提示链。初始阶段旨在解析非结构化文本并提取特定信息。接下来的阶段会接收这一提取出的输出,并将其转换为一种结构化的数据格式。要重复这一过程,首先必须安装所需的库。这可以通过以下命令来完成:
pip install langchain langchain-community langchain-openai langgraph
请注意,langchain-openai 可以用针对不同模型提供商的相应软件包来替代。随后,必须为所选的语言模型提供商(如 OpenAI、Google Gemini 或 Anthropic)配置必要的 API 凭证,以设置执行环境。
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser# For better security, load environment variables from a .env file
# from dotenv import load_dotenv
# load_dotenv()
# Make sure your OPENAI_API_KEY is set in the .env file# Initialize the Language Model (using ChatOpenAI is recommended)
llm = ChatOpenAI(temperature=0)# --- Prompt 1: Extract Information ---
prompt_extract = ChatPromptTemplate.from_template("Extract the technical specifications from the following
text:\n\n{text_input}"
)# --- Prompt 2: Transform to JSON ---
prompt_transform = ChatPromptTemplate.from_template("Transform the following specifications into a JSON object with
'cpu', 'memory', and 'storage' as keys:\n\n{specifications}"
)# --- Build the Chain using LCEL ---
# The StrOutputParser() converts the LLM's message output to a simple
string.
extraction_chain = prompt_extract | llm | StrOutputParser()# The full chain passes the output of the extraction chain into the
'specifications'
# variable for the transformation prompt.
full_chain = ({"specifications": extraction_chain}| prompt_transform| llm| StrOutputParser()
)# --- Run the Chain ---
input_text = "The new laptop model features a 3.5 GHz octa-core
processor, 16GB of RAM, and a 1TB NVMe SSD."# Execute the chain with the input text dictionary.
final_result = full_chain.invoke({"text_input": input_text})print("\n--- Final JSON Output ---")
print(final_result)
这段 Python 代码展示了如何使用 LangChain 库来处理文本。它使用了两个独立的提示:一个用于从输入字符串中提取技术规格,另一个用于将这些规格格式化为 JSON 对象。使用 ChatOpenAI 模型进行语言模型交互,并且 StrOutputParser 确保输出是可用的字符串格式。LangChain 表达式语言(LCEL)用于将这些提示和语言模型巧妙地串联起来。第一个链,即提取链,提取规格。完整的链随后使用提取后的输出作为转换提示的输入。提供了一个描述笔记本电脑的示例输入文本。使用此文本调用完整的链,通过这两个步骤对其进行处理。最终结果是一个包含提取和格式化规格的 JSON 字符串,然后将其打印出来。
六、上下文工程与提示工程
上下文工程是一门系统性的学科,旨在生成 Token 之前为人工智能模型设计、构建并提供一个完整的信息环境。这种方法认为,模型输出的质量更多地取决于所提供的上下文的丰富程度,而非模型架构本身。
它与传统的提示工程相比有了显著的改进,传统提示工程主要致力于优化用户即时查询的表述方式。而上下文工程则将这一范围扩展到了包括多层信息的内容中,比如系统提示,这是一套定义人工智能运行参数的基础指令,例如“你是一名技术写手;你的语气必须正式且精确”。上下文还会通过外部数据得到进一步丰富。这包括检索到的文档,其中人工智能会主动从知识库中获取信息来为它的回应提供依据,比如获取一个项目的技术规格。它还包含了工具输出,这是人工智能使用外部 API 获得实时数据的结果,比如查询日历以确定用户的可用时间。这些明确的数据与关键的隐性数据相结合,如用户身份、交互历史和环境状态。核心原则是,即使是先进的模型,在提供有限或构建不良的操作环境视图的情况下也会表现不佳。
因此,这种做法将任务的性质从仅仅回答问题转变为为Agent构建一个全面的运行环境。例如,一个基于上下文设计的Agent不仅会响应查询,还会首先整合用户的日程安排可用性(工具输出)、与电子邮件收件人之间的专业关系(隐含数据)以及之前会议的笔记(检索的文档)。这使得模型能够生成高度相关、个性化且实用性强的输出。最终的译文:这个
“工程”部分涉及创建可靠的管道,在运行时获取并转换这些数据,并建立反馈回路以持续提升上下文质量。
为了实现这一目标,可以使用专门的调优系统来大规模自动执行改进过程。例如,像谷歌的 Vertex AI 提示优化器这样的工具可以通过系统地根据一组示例输入和预定义的评估指标来评估响应,从而提高模型性能。这种方法对于在不同模型之间适应提示和系统指令而无需进行大量手动重写是有效的。通过为该优化器提供示例提示、系统指令和模板,它可以以编程方式优化上下文输入,为实现复杂的情境工程所需的反馈回路提供一种结构化的方法。
这种结构化的方法是将基本的 AI 工具与更复杂且具有上下文感知能力的系统区分开来的关键所在。它将上下文本身视为一个主要组成部分,高度重视智能体所知道的内容、何时知道以及如何使用这些信息。这种实践确保了模型能够全面理解用户的意图、过往经历以及当前环境。最终,上下文工程是将无状态聊天机器人提升为高度智能、具备上下文感知能力的系统的关键方法。
总结
通过将复杂问题解构为一系列更简单、更易于管理的子任务,提示链为指导大型语言模型提供了一个强大的框架。这种“分而治之”的策略通过一次将模型专注于一个特定操作,显著增强了输出的可靠性和控制性。作为一种基础模式,它使能够进行多步推理、工具集成和状态管理的复杂AI智能体的开发成为可能。最终,掌握提示链对于构建健壮的、上下文感知的系统至关重要,这些系统可以执行远远超出单个提示功能的复杂工作流。
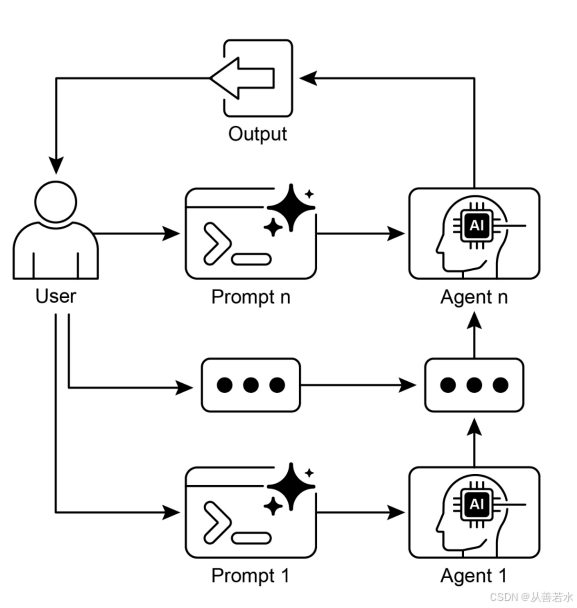
当任务过于复杂,无法使用单个提示,涉及多个不同的处理阶段,需要在步骤之间与外部工具进行交互,或者构建需要执行多步骤推理和维护状态的代理系统时,使用此模式。
- 提示链将复杂的任务分解为一系列较小的、有针对性的步骤。这种模式有时被称为管道模式;
- 链中的每个步骤都涉及LLM调用或处理逻辑,使用前一步的输出作为输入;
- 这种模式提高了与语言模型复杂交互的可靠性和可管理性;
- 像LangChain、LangGraph和谷歌ADK这样的框架提供了强大的工具来定义、管理和执行这些多步骤序列。
