构建具备因果推理与长期优化能力的数字农学家Agent系统
摘要: 本文将深度剖析并实训构建一个超越传统“看图识病”模式的下一代农业AI智能体(Agent)。传统的计算机视觉模型如同驻扎在“海岸线”的观察哨,能高效识别病害,但无法深入理解其背后的因果关系,更遑论提供长期的、经济最优的综合管理策略。我们提出的“数字农学家”Agent,则致力于探索农业AI的“内陆大陆”——一个由知识图谱(Knowledge Graph)、强化学习(Reinforcement Learning)和大型语言模型(LLM)构成的认知与决策核心。本文将以“温室番茄晚疫病管理”为贯穿始终的实训案例,从零开始,详细阐述该Agent的系统架构、数据模式设计、算法选型与实现细节,包括如何使用Neo4j构建农业知识图谱以实现因果推理,如何应用PPO算法进行跨生长周期的施药与环境调控策略优化,以及如何通过RAG与Llama 3模型构建具备专业对话能力的统一交互接口。这不仅是一次技术范式的跃迁——从静态的图像分类器到动态的系统对话伙伴,更是一张旨在实现农业生产自主决策、降本增效、并保障长期生态健康的未来蓝图。
关键词: 人工智能体(AI Agent),知识图谱,强化学习,因果推理,长期决策优化,数字农学家,智慧农业
引言:超越像素的农学智能体——从“看图识病”到“系统对话”的范式跃迁
多年以来,农业人工智能(AI)的承诺,似乎总是浓缩于一张高分辨率的无人机影像、一片被完美分割的作物叶片,或是一个围绕着潜在病斑的、置信度高达99%的检测框。我们无疑已经构建了卓越的数字“眼睛”,它们不知疲倦地巡视着广袤的田野,其精准度与效率早已超越了人类肉眼的极限。这些基于深度学习,特别是卷积神经网络(CNN)的视觉模型,构成了我们探索智慧农业的“海岸线据点”——它们清晰、明确,成果斐然。
然而,当我们站在这些“据点”上,向内陆深处眺望时,一个根本性的问题浮现出来:看清,等同于理解吗?
一个顶级的YOLOv8模型可以瞬间识别出番茄叶片上的晚疫病(Phytophthora infestans)特征,但它无法回答一系列对于农场管理者而言至关重要的问题:
- 因果追溯 (Causal Inference): “为什么会爆发晚疫病?是因为过去72小时持续的高湿度,还是因为土壤钾元素失衡导致植株抗性下降,亦或是两者兼有?”
- 策略权衡 (Strategic Trade-off): “立即进行广谱性杀菌剂喷洒,虽然能快速控制病情,但会不会增加农药残留,影响下个月的授粉昆虫活动,并导致长期土壤菌群失衡?”
- 长期优化 (Long-term Optimization): “结合未来一周的天气预报(高温高湿)和当前的作物长势,最优的综合干预策略是什么?是应该调整滴灌频率、增加通风,并配合低剂量的生物农药,从而在控制成本、保证产量的同时,最大化维护土壤的长期健康?”
这些问题,超越了模式匹配的范畴,进入了因果推理、系统思维和长期决策优化的领域。这片广袤的、充满复杂变量与延迟回报的“内陆大陆”,正是当前农业AI亟待开拓的疆域。传统的“看图识病”模型,本质上是一个静态的、反应式的图像分类器。而我们真正需要的,是一个动态的、具备前瞻性与对话能力的数字农学家(Digital Agronomist)。
本文旨在系统性地阐述构建这样一位“数字农学家”Agent的技术路线图。我们将告别单一任务模型,转向一个集感知、认知、决策、沟通于一体的综合智能体系统。我们将详细论证,如何通过以下三大核心技术的融合,实现这一范式跃迁:
- 知识图谱 (Knowledge Graph): 构建系统的“认知大脑”,将离散的农学知识(病虫害、作物生理、环境因子、农事操作)编码成一个庞大的、可计算的因果关系网络,实现从“是什么”到“为什么”的认知飞跃。
- 强化学习 (Reinforcement Learning): 塑造系统的“策略思维”,在一个高度复杂的、动态变化的模拟环境中,通过不断的试错与学习,寻找跨越整个生长周期的、旨在最大化长期累积回报(而非单次任务最优)的行动策略。
- 大型语言模型 (Large Language Model): 打造系统的“沟通桥梁”,将底层复杂的模型输出(如图谱推理路径、RL策略值)翻译成人类专家能够理解、质询和采纳的自然语言建议,实现从“数据输出”到“系统对话”的交互革命。
我们将以 “温室番茄晚疫病综合管理” 这一具体且极具挑战性的场景为实训案例,贯穿全文,提供包括数据Schema设计、关键算法实现伪代码、系统架构图在内的翔实技术细节。这不仅仅是一篇理论探讨,更是一份旨在启发AI研究者、农业科技从业者和数据科学家的、具备高度可操作性的实施蓝图。
让我们一同启程,从熟悉的“海岸线”出发,深入那片充满挑战与机遇的“内-陆大陆”,共同探索下一代农业智能的未来。
第一部分:现有工作与海岸线困境——静态视觉的内生局限
在深入构建我们的高级Agent之前,必须清晰地认识现有技术的边界。基于计算机视觉(CV)的农业应用,特别是病虫害识别,是智慧农业领域研究最深入、商业化最成功的方向之一。它们构成了我们坚实的“海岸线”,但这条海岸线本身也定义了其难以逾越的局限。
1.1 “海岸线”的辉煌成就:基于CV的精准感知
自AlexNet在2012年引爆深度学习革命以来,CNN及其衍生模型(如ResNet, VGG, Inception)已成为图像识别的基石。在农业领域,这一技术迅速催生了三大主流应用范式:
- 图像分类 (Image Classification): 这是最基础的应用。给定一张作物叶片图像,模型输出一个单一的标签,如“健康”、“晚疫病”、“白粉病”等。PlantVillage等著名公开数据集极大地推动了该领域的发展,使得模型在特定数据集上的准确率可以轻松超过95%。
- 目标检测 (Object Detection): 更进一步,模型不仅要识别病害,还要在图像中用边界框(Bounding Box)将其精确定位。以YOLO(You Only Look Once)系列为代表的单阶段检测器,凭借其惊人的速度与不俗的精度,在杂草检测、果实计数、病斑定位等场景中大放异异彩。例如,一个部署在无人机上的YOLOv8模型,可以实时地在数公顷的农田中圈出杂草的分布区域,为后续的精准除草提供决策依据。
- 语义/实例分割 (Semantic/Instance Segmentation): 这是最精细的图像理解层次。模型需要对图像中的每一个像素点进行分类。U-Net、Mask R-CNN等模型能够精确地勾勒出作物冠层、病斑、干旱区域的轮廓,计算其面积占比,为评估作物长势、病害严重程度提供了前所未有的像素级量化数据。例如,通过分割作物冠层,可以精确计算叶面积指数(LAI),这是评估光合作用能力的关键指标。

图1.1: 从图像分类到实例分割,计算机视觉在农业感知任务上的能力演进。
这些技术的成功是毋庸置疑的。它们将农学家的经验知识部分地、高效地固化到了算法之中,实现了大规模、自动化、非侵入式的农情数据采集与初步诊断,极大地解放了生产力。
1.2 “海岸线”的困境:四个“无法回答”
然而,当我们站在农场管理者的角度,将这些CV模型的输出视为决策过程的输入而非终点时,它们的局限性便暴露无遗。这些局限是内生的,源于其“静态视觉”和“模式匹配”的本质。
困境一:无法进行因果推理 (Causal Inference)
让我们回到番茄晚疫病的例子。CV模型通过学习海量图像,记住了晚疫病在像素层面的“模式”——不规则的、水浸状的、边缘呈灰白色霉层的暗褐色病斑。当一个新的图像输入时,模型执行的是一种高度复杂的“连连看”游戏,匹配其在训练数据中学到的模式。
但它完全不理解晚疫病发生的生物学机理。它不知道晚疫病是由卵菌(Phytophthora infestans)引起的,更不知道这种卵菌的孢子萌发和侵染需要同时满足两个关键环境条件:温度在10-25°C之间和空气相对湿度接近饱和(>90%)并持续至少10-12小时。
因此,当模型输出“晚疫病”时,它只是一个识别结果,一个孤立的事实。它无法回答:
- “是昨晚的持续降雨,还是温室通风系统故障导致的湿度飙升,触发了这次爆发?”
- “当前土壤的氮肥施用过量,导致植株组织柔嫩、抗性下降,是否是这次病害的协同诱因?”
这种对因果关系的“无知”,使得模型永远停留在“知其然,而不知其所以然”的阶段。它是一个优秀的观察员,但不是一个合格的诊断师。
困境二:无法进行动态预测 (Dynamic Prediction)
农田是一个动态变化的生态系统。今天的决策会深刻影响明天、下周乃至整个生长季的结果。CV模型处理的是一张张时间切片上的静态快照,它缺乏对时间序列的理解能力。
即使我们将CV模型与时间序列预测模型(如LSTM)结合,也仅仅是基于历史图像数据预测未来的表观状态(例如,预测明天病斑面积的扩大率),而无法预测在不同干预措施下的系统演化路径。
模型无法回答:
- “如果我现在不采取任何措施,结合未来三天的天气预报(持续阴雨),病害扩散的风险有多高?预计会损失多少产量?”
- “如果我采取A策略(喷洒保护性杀菌剂)或B策略(加强通风、物理隔离),这两种情况下,未来一周的病情发展曲线会有何不同?”
困境三:无法进行策略优化 (Policy Optimization)
农业管理本质上是一系列资源分配和风险管理的决策过程。决策的目标通常是多元的,需要在产量、成本、品质、环境影响之间做出权衡。
CV模型本身不具备任何决策能力。它的输出——“图像中80%的概率是晚疫病”——需要由人类专家来解读,并结合自身经验、成本预算、市场行情等外部信息,才能形成一个具体的行动方案。
模型无法回答:
- “考虑到当前农药价格、人工成本和番茄市场价格,是进行一次全面喷洒,还是只对重病区进行点对点处理,哪种方案的 投入产出比(ROI) 更高?”
- “我应该选择化学农药A(速效但易产生抗性)还是生物农药B(见效慢但对环境友好)?这个决策如何影响我申请绿色有机认证的长期目标?”
困境四:无法进行领域知识的泛化与迁移 (Knowledge Generalization)
深度学习模型,特别是大型模型,常常被诟病为“黑箱”。它们学到的知识高度耦合于训练数据分布,泛化能力有限,且难以将一个领域的知识迁移到另一个领域。
一个在新疆地区番茄田训练的晚疫病识别模型,直接部署到云南的高湿度山地环境,其性能可能会显著下降,因为它没有学习过新环境下病斑的细微变异。更重要的是,它无法融合和利用非图像的领域知识。
例如,一个经验丰富的农学家知道,如果一个番茄品种是“抗晚疫病”的,那么即使叶片上出现疑似病斑,其为晚疫假的概率也会大大降低。这种先验知识很难被直接编码进一个纯粹的CV模型中。模型无法像人类专家一样,灵活地调用和整合来自植物病理学、土壤学、气象学、遗传育种学等多学科的知识,进行综合判断。
总结:从“海岸线”到“内陆”的必然
综上所述,现有的基于计算机视觉的农业应用,虽然在“感知”层面取得了巨大成功,但它们本质上是被动的、静态的、孤立的信息处理器。它们解决了“看清”的问题,但留下了更核心的“理解”与“决策”的空白。
要真正实现农业生产的智能化,我们必须勇敢地离开熟悉的“海岸线”,向广阔的“内陆大陆”进军。这意味着我们需要构建一个全新的认知架构,让AI不仅能“看”,更能“思考”。这个思考的核心,就是建立因果关系、模拟未来发展、优化长期策略。而这一切的基石,便是将零散的领域知识系统化、结构化的能力。这正是我们下一部分将要深入探讨的——知识图谱。
第二部分:认知架构(I):知识图谱——从模式匹配到逻辑推理
要让AI从一个“模式匹配器”进化为一个“逻辑推理者”,我们必须赋予它一个“大脑”——一个能够存储、关联和推理领域知识的核心。在我们的“数字农学家”Agent中,这个大脑就是农业知识图谱(Agricultural Knowledge Graph, Agri-KG)。它旨在解决空白点1:认知深度的问题。
2.1 为什么是知识图谱?
知识图谱并非新生事物,其本质是一种用图(Graph)结构来建模知识的有向图。它由 节点(Nodes/Entities) 和 边(Edges/Relations) 组成。节点代表现实世界中的实体(如“番茄”、“晚疫病”),边则代表这些实体之间的关系(如“番茄” [易感染] “晚疫病”)。
与传统的关系型数据库(如MySQL)相比,知识图谱在表达复杂、异构、多对多的关系上具有天然的优势:
- 直观性与可解释性: 图结构与人类的联想记忆模式高度相似。一个关于“番茄晚疫病”的推理路径,如
番茄 -> 易感染 -> 晚疫病 -> 由...引起 -> 卵菌 -> 适宜条件 -> 高湿环境,非常直观,其推理过程是透明的、可追溯的,解决了深度学习的“黑箱”问题。 - 关联推理能力: 图数据库的原生查询语言(如Neo4j的Cypher)天生就是为多跳(Multi-hop)关系查询和路径发现而设计的。它能轻松回答“从A出发,经过B,避开C,最终能到达哪些D?”这类复杂问题。例如,我们可以查询“哪些杀菌剂(D)可以治疗晚疫病(B),但其活性成分对授粉蜜蜂(C)有高风险,不适用于当前处于花期的番茄(A)?”这种查询在关系型数据库中需要进行多次复杂的
JOIN操作,效率低下且难以维护。 - 灵活的模式 (Flexible Schema): 农业知识是不断发展的,新的作物品种、病害变种、治疗方法层出不穷。知识图谱的“模式可选”(Schema-optional)特性,允许我们随时增加新的节点类型、关系类型或节点属性,而无需像关系型数据库那样进行繁琐的表结构变更(
ALTER TABLE)。这种灵活性使其能够轻松适应知识的动态增长。 - 数据融合的枢纽: 农业数据来源极其广泛,包括结构化的传感器数据、半结构化的农事日志,以及非结构化的科研文献。知识图谱可以作为一个统一的框架,将这些异构数据源融合到一个统一的语义网络中,打破数据孤岛。
总而言之,知识图谱为我们的“数字农学家”Agent提供了一个兼具表达能力、推理能力和灵活性的认知中枢。它将零散的数据点,编织成一张充满因果逻辑的知识之网。
2.2 农业知识图谱(Agri-KG)模式(Schema)设计——知识的骨架
如果说知识图谱是“数字农学家”的大脑,那么模式(Schema)设计就是构建这个大脑的“本体论基础”(Ontology),即定义这个世界由哪些类型的“事物”组成,以及它们之间存在哪些类型的“联系”。一个严谨、健壮、可扩展的Schema,是决定知识图谱成败的关键。
在我们的“温室番茄晚疫病”案例中,Schema设计的目标是能够完整地、无歧义地描述与该场景相关的所有核心农学知识。我们将Schema分为两大部分:节点标签(Node Labels)和关系类型(Relationship Types)。
2.2.1 核心节点标签定义 (Node Labels)
节点代表了我们知识领域中的核心实体。以下是我们定义的核心节点标签及其关键属性:
-
Crop(作物): 代表作物的通用类别。name: “番茄” (String, 唯一索引)
-
Variety(作物品种): 代表具体的作物品种,继承自Crop。name: “普罗旺斯” (String, 唯一索引)resistance_level: 3 (Integer, 1-5级,数字越大抗性越强)growth_cycle_days: 120 (Integer)
-
Disease(病害): 代表一种特定的植物病害。name: “晚疫病” (String, 唯一索引)scientific_name: “Phytophthora infestans” (String)type: “真菌性病害” (String, 可选:细菌性、病毒性)
-
Pathogen(病原体): 引起病害的微生物。name: “致病疫霉” (String, 唯一索引)optimal_temp_min: 10 (Float, °C)optimal_temp_max: 25 (Float, °C)optimal_humidity_min: 90 (Float, %)
-
Symptom(症状): 病害在植株上表现出的外部特征。name: “水浸状暗褐色病斑” (String, 唯一索引)location: “叶片” (String, 可选:茎、果实、根)description: “病斑不定型,边缘有灰白色霉层…” (String)
-
EnvironmentState(环境状态): 描述环境的关键参数。这通常是时序数据,但在图谱中可以表示为特定的、可触发事件的状态。state_name: “持续高湿” (String, 唯一索引)parameter: “RelativeHumidity” (String)threshold: 90 (Float, %)duration_hours: 12 (Integer)
-
Treatment(防治措施): 用于管理病害的农事操作或施用的物质。name: “喷洒代森锰锌” (String, 唯一索引)type: “化学防治” (String, 可选:物理防治、生物防治、农业防治)cost_per_mu: 50.5 (Float, 元/亩)
-
ActiveIngredient(有效成分): 农药中的化学活性物质。name: “代森锰锌” (String, 唯一索引)mechanism: “保护性杀菌剂,抑制菌体内丙酮酸的氧化” (String)risk_to_pollinators: “Low” (String)
-
Nutrient(营养元素): 作物生长所需的化学元素。name: “钾” (String, 唯一索引)symbol: “K” (String)
2.2.2 核心关系类型定义 (Relationship Types)
关系是知识图谱的灵魂,它将孤立的节点连接成网,赋予了知识以结构和逻辑。
(Variety) -[:HAS_PROPERTY]-> (Crop): 品种属于哪个作物大类。(Variety) -[:SUSCEPTIBLE_TO]-> (Disease): 某作物品种易感染某种病害。- 属性:
level: 4 (Integer, 1-5级,数字越大越易感)
- 属性:
(Disease) -[:CAUSED_BY]-> (Pathogen): 病害由某种病原体引起。(Disease) -[:SHOWS_SYMPTOM]-> (Symptom): 病害表现出某种症状。(Pathogen) -[:REQUIRES_CONDITION]-> (EnvironmentState): 病原体的侵染需要满足某种环境条件。(Treatment) -[:TREATS]-> (Disease): 某项防治措施用于治疗某种病害。- 属性:
effectiveness: 0.85 (Float, 0-1)
- 属性:
(Treatment) -[:CONTAINS_INGREDIENT]-> (ActiveIngredient): 防治措施(如农药)包含某种有效成分。(Crop) -[:DEFICIENT_IN {level: "severe"}]-> (Nutrient): 作物缺乏某种营养元素。(Nutrient) -[:AFFECTS_RESISTANCE_TO]-> (Disease): 某种营养元素的水平会影响对特定病害的抗性(例如,缺钾会降低对晚疫病的抗性)。

图2.1: 农业知识图谱(Agri-KG)核心Schema可视化。这张图不仅是数据结构,更是我们“数字农学家”Agent进行逻辑推理的路线图。
通过这个精心设计的Schema,我们已经为“数字农学家”构建了知识的骨架。曾经散落在教科书、研究论文、农技员大脑中的非结构化知识,现在被转化为了机器可理解、可计算、可推理的结构化资产。
2.3 数据注入与图谱构建:为骨架注入血肉
有了Schema这个“骨架”,下一步就是向其中填充数据,即数据注入(Data Ingestion),也称为知识图谱的构建。这个过程将我们从CV模型、传感器、数据库等多个来源获得的原始数据,转化为符合我们Schema定义的节点和关系。
这个过程通常分为两步:
-
知识抽取 (Knowledge Extraction):
- 从结构化数据中抽取: 这是最直接的方式。例如,我们可以从一个作物品种数据库的CSV文件中,直接将每一行映射为一个
Variety节点,其列值对应节点的属性。# 伪代码: 从CSV注入品种数据 import pandas as pd from neo4j import GraphDatabasedf = pd.read_csv("varieties.csv") driver = GraphDatabase.driver(URI, auth=(USER, PWD))with driver.session() as session:for index, row in df.iterrows():session.run("""MERGE (v:Variety {name: $name})SET v.resistance_level = $resistance, v.growth_cycle_days = $cycleMERGE (c:Crop {name: "番茄"})MERGE (v)-[:HAS_PROPERTY]->(c)""", name=row['variety_name'], resistance=row['resistance_level'], cycle=row['cycle_days']) - 从半结构化/非结构化数据中抽取: 这更具挑战性,通常需要借助自然语言处理(NLP)技术。例如,我们可以使用命名实体识别(NER)和关系抽取(RE)模型,自动从农业科技文献中抽取出
(病害, [TREATS], 农药)这样的三元组。- 技术深潜: 针对特定领域的知识抽取,可以 fine-tuning Llama 3 等大语言模型来完成。通过设计特定的Prompt,要求模型以JSON格式输出从文本中识别出的实体和关系,其效果往往优于传统的NLP模型。
- 从结构化数据中抽取: 这是最直接的方式。例如,我们可以从一个作物品种数据库的CSV文件中,直接将每一行映射为一个
-
知识融合 (Knowledge Fusion):
- 从不同来源抽取的知识可能存在冲突或冗余。例如,实体“代森锰锌”和“Mancozeb”可能指向同一种物质。知识融合的目标是进行实体对齐(Entity Alignment)和冲突消解(Conflict Resolution),确保知识图谱中每个现实世界的实体都有一个唯一的、规范化的表示。
通过上述步骤,我们将逐步构建出一个规模庞大、内容丰富的农业知识图谱。这个图谱不仅包含了静态的百科全书式知识,更重要的是,它将不断地接收来自第一部分中CV模型和IoT传感器的实时观测数据。
例如,当YOLOv8模型在ID为Plot-A1的地块中检测到晚疫病时,系统会自动在图谱中创建或更新一个事件节点,并将其与Plot-A1节点和晚疫病节点连接起来,记录下时间、置信度、严重程度等信息。这样,知识图谱就从一个静态的知识库,变成了一个动态的、反映农田实时状态的“数字孪生”。
2.4 Cypher查询:在知识之网中进行因果推理
知识图谱的真正威力在于查询和推理。Neo4j的声明式查询语言Cypher,其语法模式 (node1)-[relation]->(node2) 与图的视觉表现形式高度一致,使得复杂的关联查询变得异常直观。
以下是一些基于我们Agri-KG的Cypher查询示例,它们展示了Agent如何进行根本原因分析和决策支持:
查询示例1:根本原因分析 (Root Cause Analysis)
问题: “A1地块的‘普罗旺斯’番茄上发现了‘水浸状暗褐色病斑’,最可能的原因是什么?”
// 1. 根据症状找到可能的病害
MATCH (s:Symptom {name: "水浸状暗褐色病斑"})<-[:SHOWS_SYMPTOM]-(d:Disease)
// 2. 确认该病害是否会感染目标品种
MATCH (d)<-[:SUSCEPTIBLE_TO]-(v:Variety {name: "普罗旺斯"})
// 3. 找到引起该病害的病原体
MATCH (d)-[:CAUSED_BY]->(p:Pathogen)
// 4. 查找该病原体所需的触发条件
MATCH (p)-[:REQUIRES_CONDITION]->(e:EnvironmentState)
// 5. [核心] 检查A1地块最近是否满足这些条件 (此处假设实时环境数据已注入)
MATCH (plot:Plot {id: "A1"})-[:HAS_EVENT]->(event:EnvironmentEvent)
WHERE event.parameter = e.parameter AND event.value >= e.threshold AND event.timestamp > (datetime() - duration({hours: e.duration_hours}))
// 返回可能的病害和触发该病害的环境条件
RETURN d.name AS SuspectedDisease, e.state_name AS TriggerCondition
输出:
| SuspectedDisease | TriggerCondition |
|---|---|
| “晚疫病” | “持续高湿” |
推理过程解读: 这个查询清晰地模拟了农学专家的诊断思路。它从一个表观症状出发,通过图谱中预设的因果链(Symptom -> Disease -> Pathogen -> EnvironmentState),反向追溯,并最终与来自物联网传感器的实时环境数据进行交叉验证,从而得出了一个有数据支撑的、可解释的诊断结论。这正是传统CV模型无法企及的认知深度。
查询示例2:智能决策支持 (Intelligent Decision Support)
问题: “针对晚疫病,推荐一些对蜜蜂低风险的化学防治措施。”
MATCH (d:Disease {name: "晚疫病"})<-[:TREATS]-(t:Treatment {type: "化学防治"})
MATCH (t)-[:CONTAINS_INGREDIENT]->(ai:ActiveIngredient)
WHERE ai.risk_to_pollinators = "Low"
RETURN t.name AS RecommendedTreatment, ai.name AS ActiveIngredient, t.cost_per_mu AS Cost
ORDER BY Cost ASC
输出:
| RecommendedTreatment | ActiveIngredient | Cost |
|---|---|---|
| “喷洒霜霉威盐酸盐” | “霜霉威盐酸盐” | 45.0 |
| “喷洒氟菌·霜霉威” | “氟吡菌胺, 霜霉威” | 62.5 |
推理过程解读: 这个查询展示了知识图谱在多约束条件下进行方案筛选的能力。它不仅要找到能“治疗”晚疫病的措施,还附加了“化学防治”和“对授粉昆虫低风险”两个约束条件,并按成本排序。这种能力使得Agent可以根据用户的具体情境和偏好,提供个性化、精细化的决策选项。
通过构建和查询农业知识图谱,我们的“数字农学家”Agent已经完成了从感知到认知的关键一跃。它不再是一个只能识别像素模式的“观察者”,而是一个能够理解事物背后深层逻辑、进行因果推理的“思考者”。
然而,仅仅理解过去和现在是不够的。一个真正的战略家,还需要具备预测未来、优化决策的能力。这就要求我们引入下一个核心技术——强化学习。
第三部分:认知架构 (II):强化学习——赋予系统超越人类直觉的长期规划能力
在第二部分中,我们通过构建农业知识图谱(Agri-KG),成功地为“数字农学家”Agent安装了一个强大的认知引擎。它能够理解实体间的因果关系,进行复杂的逻辑推理。然而,这只解决了问题的一半。一个农场管理者最核心的工作,并不仅仅是诊断问题,而是在资源有限、信息不完全、未来不确定的情况下,做出一系列连续的、旨在最大化长期利益的决策。
这正是人类专家最擅长,也最容易犯错的地方。
3.1 决策的困境:人类直觉与监督学习的极限
农业管理是一个典型的序贯决策问题(Sequential Decision-Making Problem)。今天的决策不仅影响明天的产出,其后果(如土壤健康、病菌抗药性)可能会延迟到数月甚至数年后才显现。
- 人类直觉的局限: 一个经验丰富的农场主,其决策往往基于过往数十年形成的“直觉”或“启发式规则”(Heuristics),例如“湿度大了就通风”、“看到病斑就打药”。这些规则在大多数情况下是有效的,但在面对极端天气、新型病害或需要精细权衡成本收益的复杂情境时,往往会陷入局部最优而非全局最优。人类大脑难以精确计算一个决策在未来三个月内所有可能路径上的期望回报。
- 监督学习的无力: 我们能否用监督学习(Supervised Learning)来解决这个问题?比如,收集大量“农情数据 -> 专家决策”的数据对,然后训练一个模型来模仿专家?这条路也行不通。首先,何为“最优决策”本身就没有一个确定的标签(label)。专家A和专家B的决策可能完全不同。其次,监督学习只能模仿历史,无法发现和创造超越人类经验的、更优的全新策略。它只能告诉你“专家过去会怎么做”,而无法告诉你“在当前情况下,理论上最优的做法是什么”。
我们需要一种全新的范式,一种让Agent自己在与环境的互动中“学会”如何决策 的范式。这正是强化学习(Reinforcement Learning, RL) 的用武之地。RL的核心思想,不是模仿,而是通过试错(Trial-and-Error)来探索,并通过奖励(Reward)信号来学习,最终找到一个能最大化长期累积奖励的行动策略(Policy)。
3.2 马尔可夫决策过程(MDP):为农业决策问题建立数学模型
为了应用RL,我们首先需要将复杂的农业管理问题,抽象成一个RL算法可以理解的数学框架——马尔可夫决策过程(Markov Decision Process, MDP)。MDP由五个核心要素组成元组 (S, A, P, R, γ)。让我们将“温室番-茄晚疫病管理”场景逐一映射到这个框架中。
状态 (State, S)
- 定义: 状态是对环境在某一时刻的完整描述。一个好的状态表示,应该包含所有做出最优决策所需的信息,即满足马尔可夫属性(未来只与当前状态有关,与过去无关)。
- 在我们的案例中: 状态sts_tst 不再是一张孤立的图片,而是整个农业知识图谱在t时刻的一个快照的向量化表示。这个状态向量sts_tst 将包含:
- 作物状态: 各植株的生长阶段、平均株高、叶面积指数、检测到的病害节点及其严重性属性。
- 环境状态: 当前及过去24小时的平均温度、湿度、光照强度、CO2CO_2CO2浓度等节点信息。
- 土壤状态: 土壤水分、pH值、EC值、主要营养元素(N, P, K)的含量。
- 历史操作: 最近执行过的农事操作(如上次施药时间、灌溉量)。
- 技术深潜: 将整个动态变化的知识图谱转化为一个固定维度的向量,是RL应用中的一个关键挑战。这通常需要借助图神经网络(Graph Neural Networks, GNNs),如Graph Convolutional Network (GCN) 或 Graph Attention Network (GAT)。GNN可以学习到图的拓扑结构和节点属性的低维、稠密的表示(Embedding),这个Embedding就构成了我们的状态sts_tst。
动作 (Action, A)
- 定义: 动作是Agent可以执行的操作集合。
- 在我们的案例中: 我们可以定义一个离散的动作空间
A,包含了所有可能的农事干预措施:A = {a_0: 什么都不做, a_1: 喷洒生物杀菌剂A, a_2: 喷洒化学杀菌剂B, a_3: 增加通风4小时, a_4: 减少灌溉量20%, a_5: 补充钾肥, ...}- 对于更精细的控制,也可以定义连续动作空间,例如
a = (杀菌剂浓度, 喷洒时长),但这会增加学习的难度。
奖励函数 (Reward Function, R)
-
定义: 奖励函数
R(s, a, s')是RL的灵魂,它定义了Agent的目标。在执行动作a后,环境从状态s转移到s',奖励函数会给出一个标量数值,告诉Agent这个转移“有多好”。奖励函数的设计直接决定了Agent最终会学到什么样的行为模式。 -
在我们的案例中: 这是一个需要精心设计的、反映长期经济效益的复合函数。一个好的奖励函数
r_t绝不仅仅是“病害减少了多少”,而应该是:
rt=(w1∗ΔYieldt)−(w2∗Costt)+(w3∗ΔHealtht)−(w4∗Penaltyt) r_t = (w_1 * ΔYield_t) - (w_2 * Cost_t) + (w_3 * ΔHealth_t) - (w_4 * Penalty_t) rt=(w1∗ΔYieldt)−(w2∗Costt)+(w3∗ΔHealtht)−(w4∗Penaltyt)
其中:- ΔYieldtΔYield_tΔYieldt: 预期产量增益。根据作物生长模型,当前决策对最终产量的积极影响。这是正向奖励。
- CosttCost_tCostt: 执行成本。包括农药、肥料、水电和人工的费用。这是负向奖励。
- ΔHealthtΔHealth_tΔHealtht: 生态系统健康增益。例如,土壤有机质含量提升、有益微生物菌群数量增加等指标。这是鼓励可持续发展的长期正向奖励。
- PenaltytPenalty_tPenaltyt: 风险惩罚。例如,农药残留超标、病菌产生抗药性的风险、对授粉昆虫的负面影响等。这是负向惩罚项。
- w1,w2,w3,w4w_1, w_2, w_3, w_4w1,w2,w3,w4: 权重系数。这些超参数需要根据农场的具体经营目标(例如,追求最大产量,还是追求有机认证)进行调整。
核心思想: 通过这个奖励函数,我们将一个模糊的商业目标(“降本增效、绿色可持续”)量化为了一个清晰的、可优化的数学信号。
状态转移概率 (Transition Probability, P)
- 定义:
P(s' | s, a)是指在状态s下执行动作a后,转移到状态s'的概率。 - 在我们的案例中: 农业生态系统是随机的(Stochastic)。喷洒农药不一定100%杀死病菌,天气变化也具有不确定性。我们无法得到一个精确的解析式来描述状态转移。因此,我们无法直接使用依赖于转移模型的动态规划(Dynamic Programming)方法。
折扣因子 (Discount Factor, γ)
- 定义:
γ是一个介于0和1之间的超参数,用于平衡短期奖励和长期奖励的重要性。γ越接近1,Agent就越有“远见”,更看重未来的奖励。
3.3 训练环境:数字孪生仿真器——Agent的“健身房”
由于状态转移P未知且在真实农田中进行试错学习成本高昂、周期漫长(一个生长季数月之久),我们必须为RL Agent构建一个高保真的仿真环境(Simulation Environment)。这个环境,可以被视为温室的 “数字孪生”(Digital Twin)。
这个仿真器是整个RL训练流程的基石,它需要集成多个领域的专业模型:
- 作物生长模型 (Crop Growth Model): 如DSSAT、WOFOST等,模拟作物在不同环境和管理措施下的生长发育过程。
- 病害流行模型 (Disease Epidemiology Model): 模拟病原体在特定温湿度条件下的传播和扩散速率。
- 环境动力学模型: 模拟温室内的光、温、水、气、肥的动态变化。
- 经济模型: 实时更新农资成本和作物市场价格。
在这个数字孪生中,Agent可以在几小时内,模拟完成数千个数万个完整的生长周期。它可以自由地探索各种极端策略(例如,连续7天不通风,或者每天都打药),并从这些虚拟的成功与失败中学习,而不会造成任何真实的经济损失。
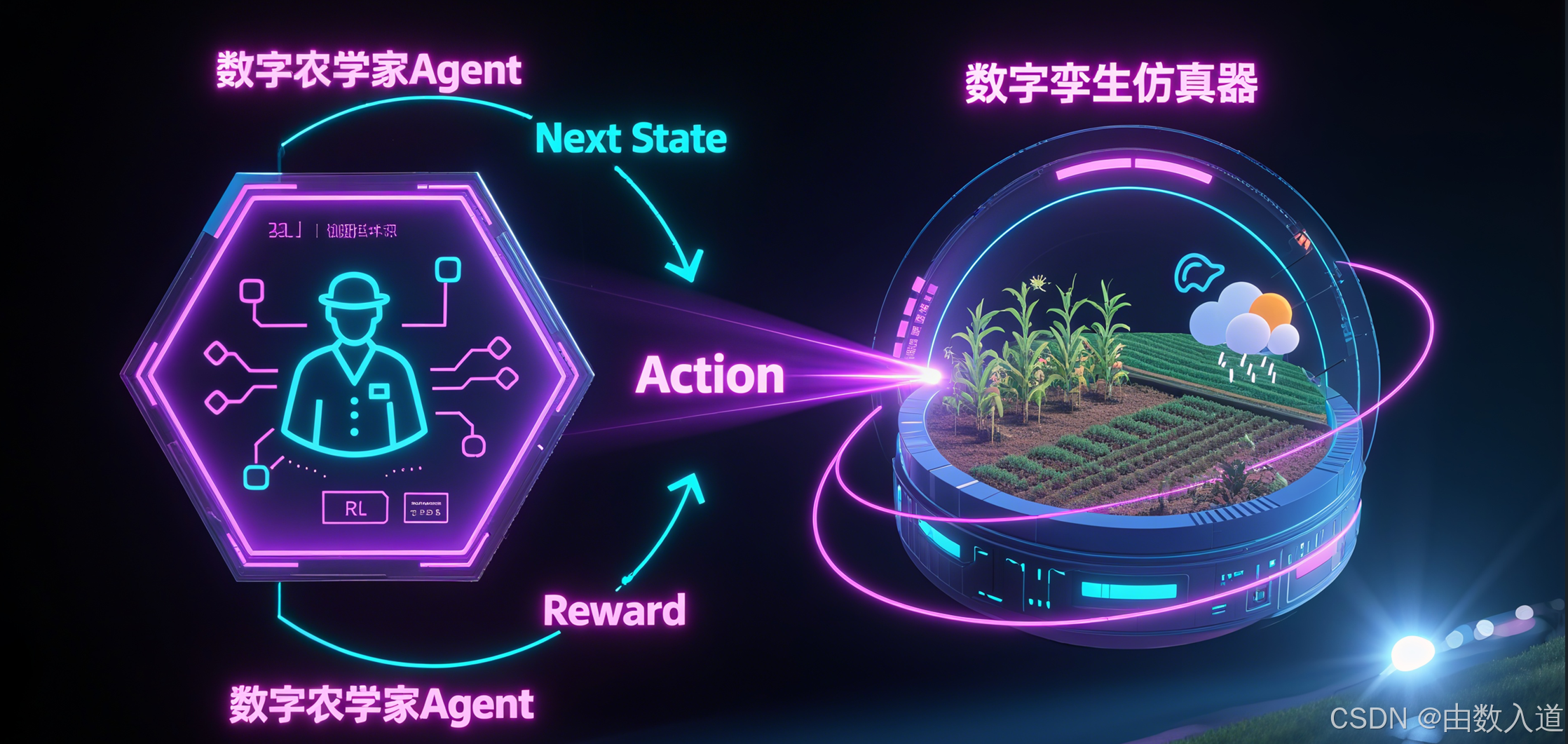
图3.1: 强化学习Agent与数字孪生仿真器的训练交互循环。
3.4 算法选择:近端策略优化 (PPO)——稳定高效的策略学习
有了MDP框架和仿真环境,我们还需要选择一个具体的RL算法来训练Agent的策略。RL算法众多,我们选择近端策略优化(Proximal Policy Optimization, PPO),这是目前业界(尤其是在OpenAI等公司)应用最广泛、效果最稳健的算法之一。
PPO属于Actor-Critic架构,它同时学习两个神经网络:
- Actor (策略网络): 输入是状态
s,输出是动作空间A中每个动作被选择的概率分布。它负责“决策”。 - Critic (价值网络): 输入是状态
s,输出是一个评价值V(s),用于评估当前状态有多好。它负责“打分”。
PPO的核心创新在于其目标函数中的“截断”(Clipping)机制。它通过限制每次策略更新的幅度,避免了传统策略梯度算法中因更新步子太大而导致性能骤降的问题,使得训练过程更加稳定、平滑。
训练流程概述:
- Agent(Actor网络)根据当前策略,在仿真环境中与数字孪生交互,收集大量的轨迹数据 (st,at,rt,st+1)(s_t, a_t, r_t, s_{t+1})(st,at,rt,st+1)。
- 利用收集到的数据,计算每个时间步的优势函数(Advantage Function),它衡量了某个动作相对于当前状态的平均价值有多好。
- 根据PPO的截断目标函数,使用梯度上升法更新Actor网络的参数,使其更倾向于选择能带来高优势值的动作。
- 使用均方误差损失,更新Critic网络的参数,使其对状态的价值评估越来越准。
- 重复以上步骤,直到Actor网络的策略收敛。
通过PPO算法的训练,我们的“数字农学家”Agent最终会学到一个高度非线性的、复杂的策略函数 π(a∣s)π(a|s)π(a∣s)。这个函数,内化了整个温室生态系统的动态规律和经济学原理。它所给出的决策,不再是基于静态规则,而是基于对未来长期累积回报的最大化期望。它能够在人类专家都感到棘手的情境中,给出超越直觉的、动态最优的解决方案。
至此,我们的Agent已经拥有了强大的认知能力(知识图谱)和战略决策能力(强化学习)。但它还缺少一个关键环节:如何将这些复杂的内部状态和决策,以一种高效、自然的方式传递给人类管理者?这就需要我们引入最后一个技术模块——大型语言模型。
第四部分:交互层:大型语言模型——从数据到对话的“认知翻译器”
我们已经为“数字农学家”Agent构建了用于因果推理的“认知大脑”(知识图谱)和用于长期规划的“战略思维”(强化学习)。现在,我们面临着“最后一公里”的挑战:如何将Agent内部复杂的、结构化的、非人类友好的信息流,转化为农场管理者能够轻松理解、深入交互、并最终信任的战略性对话?
一个RL模型输出的原始决策可能是{ "action":"a3","expectedvalue":15.7"action": "a_3", "expected_{value}": 15.7"action":"a3","expectedvalue":15.7 }。一个知识图谱查询的结果可能是一个包含数十个节点和关系的JSON对象。这些原始输出对于开发者而言是信息,但对于终端用户而言是噪音。我们需要一个**“认知翻译器”**,而大型语言模型(LLM),特别是结合了 检索增强生成(Retrieval-Augmented Generation, RAG) 架构的LLM,正是这一角色的完美担当。
4.1 RAG:连接语言智能与领域事实的桥梁
单纯的LLM(如直接使用Llama 3或GPT-4)本身是一个强大的通用知识库和推理引擎,但它存在两个致命弱点:
- 知识陈旧: 它的知识截止于其训练日期,对我们农场此刻发生的事情一无所知。
- 容易幻觉 (Hallucination): 在处理其知识边界之外的、高度专业的领域时,它可能会编造看似合理但完全错误的信息。
RAG架构通过一个简单的思想解决了这两个问题:不要让LLM仅凭记忆回答问题,而是先让它“开卷考试”。在回答用户问题之前,系统首先从我们权威的、实时的内部知识库(即农业知识图谱和RL模型)中检索相关信息,然后将这些信息作为上下文(Context)一并提供给LLM,让它基于这些“参考资料”来组织和生成答案。
这确保了LLM的输出,既拥有其强大的自然语言表达和组织能力,又被我们内部系统的 事实 所 “锚定”(Grounded),从而保证了回答的准确性、实时性和相关性。
4.2 “数字农学家”的对话工作流
在我们的Agent系统中,RAG的工作流程被设计为一个精密的、多阶段的“思考链”(Chain-of-Thought),它将用户的自然语言问题,转化为一系列对内部系统的结构化调用,最终合成为一段富有洞见的对话。
让我们通过一个具体的交互场景来剖析这个工作流:
农场管理者 (用户): “小农,A1温室西侧的番茄好像不太对劲,叶子上有斑点。现在是什么情况?未来24小时我应该采取什么措施才是最划算的?”
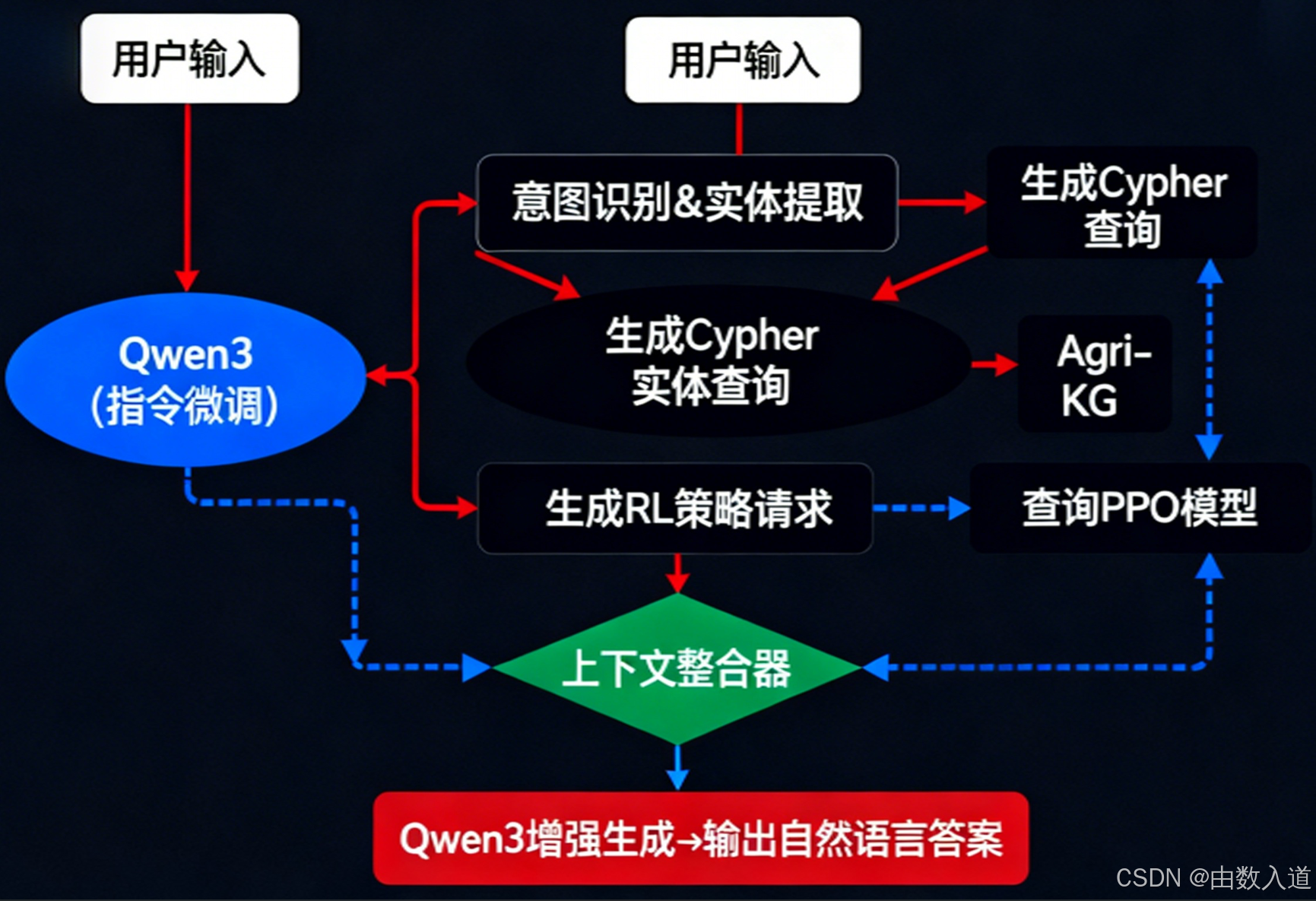
图4.1: 基于RAG的“数字农学家”对话工作流。
Step 1: 意图识别与实体提取 (Intent & Entity Recognition)
用户的输入首先被发送给一个经过指令微调(Instruction-Tuned)的LLM(例如Qwen 3 70B Instruct)。它的第一个任务不是回答问题,而是解构问题。
- 实体提取: 它会识别出关键实体,如
地块: "A1温室西侧",对象: "番茄",症状描述: "叶子上有斑点"。 - 意图识别: 它会识别出用户的两个核心意图:
意图1: 诊断 (Diagnosis)和意图2: 决策推荐 (Decision Recommendation),并识别出约束条件约束: "最划算",时间范围: "未来24小时"。
Step 2: 结构化查询生成 (Structured Query Generation)
基于上一步的分析结果,LLM现在扮演一个 “代码生成器” 的角色。它会针对不同的意图,为我们的后端系统生成相应的结构化查询。
- 针对“诊断”意图 -> 生成Cypher查询:
# LLM生成的Cypher查询 (伪代码) generated_cypher = f""" MATCH (s:Symptom)<-[:SHOWS_SYMPTOM]-(d:Disease) WHERE s.description CONTAINS "斑点" AND s.location = "叶片" MATCH (plot:Plot {{name: "{plot_name}"}})-[:HAS_CROP]->(v:Variety)-[:SUSCEPTIBLE_TO]->(d) // ... (此处省略了Part 2中更复杂的环境条件验证) RETURN d.name, d.scientific_name LIMIT 1 """ - 针对“决策推荐”意图 -> 生成RL策略请求:
- 首先,需要从Agri-KG中提取
A1温室西侧当前的状态,并通过GNN编码成状态向量sts_tst。 - 然后,向PPO模型的策略网络(Actor)发起请求,获取在状态sts_tst下的最优动作a∗a*a∗及其概率分布。
- 首先,需要从Agri-KG中提取
Step 3: 知识检索与策略评估 (Retrieval & Evaluation)
系统执行上一步生成的查询:
- Agri-KG返回的“诊断上下文”:
{"diagnosis_result": {"disease_name": "晚疫病","scientific_name": "Phytophthora infestans","causal_path": [{"node": "持续高湿 (>90% for 12h)", "reason": "EnvironmentLog Match"},{"node": "致病疫霉 (Pathogen)", "relation": "REQUIRES_CONDITION"},{"node": "晚疫病 (Disease)", "relation": "CAUSED_BY"}]} } - RL模型返回的“决策上下文”:
{"decision_recommendation": {"optimal_action": {"action_id": "a_3","action_name": "增加通风4小时","predicted_roi": 12.5, // 综合经济回报预测"confidence": 0.88},"alternative_actions": [{"action_id": "a_2","action_name": "喷洒化学杀菌剂B","predicted_roi": 9.2,"note": "短期效果好,但有轻微抗药性风险"}]} }
Step 4: 增强生成 (Augmented Generation)
最后,LLM接收到一个包含所有信息的、精心设计的最终Prompt,进行“开卷考试”。
System Prompt: 你是一位资深的、专业的数字农学家。你的任务是基于以下提供的实时上下文信息,为农场管理者生成一份清晰、全面、可执行的报告。报告需要首先解释当前的问题及其根本原因,然后给出最优的操作建议,并解释为什么这个建议是最佳的。[User Question]: "小农,A1温室西侧的番茄好像不太对劲,叶子上有斑点。现在是什么情况?未来24小时我应该采取什么措施才是最划算的?"[Retrieved Context]:
{"diagnosis_result": { ... }, // 上一步的诊断上下文"decision_recommendation": { ... } // 上一步的决策上下文
}Assistant Response:
LLM生成的最终输出:
“农场主您好。关于A1温室西侧的情况,我已经完成了综合分析。
诊断结论: 根据叶片症状和过去24小时的环境数据显示,植株目前正处于番茄晚疫病的早期侵染阶段。根本原因是在昨夜凌晨2点到下午2点之间,由于通风系统效率降低,导致局部区域出现了长达12小时、相对湿度持续高于90%的“高湿窗口”,这为晚疫病病原体(致病疫霉)的侵染创造了理想条件。
行动建议: 在综合考虑了成本、效果、以及对作物长期健康的影响后,模型给出的最优策略是:立即启动A1区的强力通风模式,并持续至少4小时。
决策依据:
- 高性价比: 该措施可以直接打破病菌侵染所需的高湿环境,成本几乎为零,预计综合经济回报(ROI)最高。
- 预防性: 由于目前处于侵染早期,通过环境调控打破传播链,是阻止病害大规模爆发的最有效手段。
- 替代方案分析: 我们也评估了立即喷洒化学杀菌剂B的方案。虽然该方案短期见效快,但其成本较高,且模型显示长期来看有轻微诱发抗药性的风险,因此其综合回报低于环境调控方案。
我将持续监控A1区的病情发展,如果未来48小时内病情未能得到有效控制,我会再次向您发出预警并提供升级的防治方案。请问还有其他问题吗?”
4.3 从被动问答到主动汇报
这个基于RAG的交互层,其能力远不止于被动的问答。由于Agent的核心系统在持续不断地监控和分析农场数据,它可以成为一个主动的、前瞻性的战略伙伴。例如,它可以被设置为每天清晨自动生成一份“农场晨报”,其生成过程与上述Step 4完全一致,只是触发机制由“用户提问”变为了“定时任务”。
这份晨报可以包含:
- 昨日关键农情回顾。
- 今日的潜在风险预警(例如,“气象模型预测今晚有高湿度风险,建议提前检查B2区通风设备”)。
- 根据RL策略生成的、今日最优的农事操作清单。
至此,我们已经完成了“数字农学家”Agent四大核心技术模块的构建。它拥有了CV的“眼睛”,知识图谱的“大脑”,强化学习的“战略思维”,以及LLM的“声音”。这四个模块环环相扣,构成了一个从数据感知到战略对话的完整闭环,其涌现出的能力,将远远超越各部分技术的简单加和。
在最后一部分,我们将探讨这一全新范式,将为农业生产带来怎样的革命性价值。
第五部分:范式革命——“数字农学家”的价值涌现
我们已经详细解构了构建一个“数字农学家”Agent所需的四大技术支柱。然而,这个系统的真正价值,并非简单地将四种技术相加,而是在于它们有机融合后所涌现出的、颠覆性的全新能力。这代表着从“工具化AI”到“伙伴式AI”的根本性范式革命。
让我们通过一个对比表,来清晰地审视这场革命。
| 维度 (Dimension) | 旧范式:静态视觉AI (“海岸线据点”) | 新范式:数字农学家Agent (“内陆大陆”) |
|---|---|---|
| 核心能力 | 模式识别 (Pattern Recognition) | 因果推理 & 战略规划 (Causal Reasoning & Strategic Planning) |
| 解读 | 仅能回答“这是什么?”(例如,“这是晚疫病”)。 | 能够回答“为什么会这样?”、“接下来会怎样?”和“我该怎么做才能达到长期最优?”。 |
| 决策延迟 | 高延迟 (High Latency) | 实时 / 预测性 (Real-time / Predictive) |
| 解读 | 模型输出后,需要人类专家介入分析、讨论、制定方案,决策周期可能是数小时甚至数天。 | Agent能够瞬时完成从数据到诊断再到决策的完整闭环,甚至在问题发生前就进行预测性干预。 |
| 优化目标 | 单点任务最优 (Single-Task Optimization) | 全局长期最优 (Global Long-term Optimization) |
| 解读 | 追求图像分类或检测的准确率达到99.9%。 | 追求整个生长季的**综合投资回报率(ROI)**最大化,平衡产量、成本、品质与环境影响。 |
| 知识处理 | 隐性知识 (Implicit Knowledge) | 显性与可解释知识 (Explicit & Explainable Knowledge) |
| 解读 | 知识固化在神经网络的权重中,是一个无法解释的“黑箱”。 | 知识以可读的知识图谱形式存在,每一条推理路径和决策依据都可追溯、可审计、可解释。 |
| 知识扩展 | 依赖重新训练 (Requires Retraining) | 动态注入与融合 (Dynamic Ingestion & Fusion) |
| 解读 | 遇到新的病害或品种,需要收集大量标注数据,进行成本高昂的模型重训练。 | 只需向知识图谱中注入新的节点和关系,Agent即可立即利用新知识进行推理,具备极强的适应性。 |
| 人机交互 | 单向报告 (One-way Reporting) | 双向对话 (Two-way Dialogue) |
| 解读 | AI向人输出数据(检测框、分类标签),交互结束。 | 人与AI可以围绕一个战略目标进行多轮、深入的自然语言对话,AI成为人类专家的“数字参谋”。 |
价值涌现1:从“亡羊补牢”到“未雨绸缪”
旧范式是反应式的。只有当病斑已经出现,被摄像头捕捉到,模型才能发出警报。这在农业管理上,已经是“亡羊补牢”。而“数字农学家”Agent是前瞻性的。它通过持续监控环境条件,并利用知识图谱中的因果链(例如 高湿环境 -> 导致 -> 晚疫病侵染),可以在病斑出现之前就发出预警:“警告:未来6小时内,A1区晚疫病侵染风险将达到高位(95%),因预测湿度将持续高于90%。” 并且,RL模块会立即给出最优的预防性措施建议,如“提前3小时开启通风”。这种将决策点从“事后”提前到“事前”的能力,能从根本上降低病害损失和防治成本。
价值涌现2:从“经验驱动”到“数据驱动的最优策略”
人类专家的决策本质上是一种基于有限经验的“贪心策略”,即在当前时间点做出看似最好的选择。而RL Agent通过在数字孪生中模拟数万次完整的生长周期,学习到的是一种全局最优策略。它可能会提出一些反直觉但长期来看回报更高的建议。例如,在病害早期,人类专家可能会倾向于立即使用强效化学农药以求“安心”,但Agent可能会建议“容忍轻微病害,优先调整环境”,因为它计算出,这样做虽然短期内存在一定风险,但从整个生长季来看,可以避免过早使用强效农药导致的抗药性增加和土壤菌群破坏,最终获得更高的经济和生态回报。
价值涌现3:知识的传承与规模化复制
顶级的农业专家是稀缺资源,他们的知识和经验难以标准化和复制。而“数字农学家”Agent系统,恰恰成为了一个知识沉淀和放大的平台。每一位专家的诊断逻辑、每一次成功的管理案例、每一篇最新的科研文献,都可以被结构化地注入到知识图谱中,成为Agent可计算的资产。这使得最高水平的农学智慧,可以被低成本、规模化地复制到任何一个农场,极大地提升了整个行业的知识基线,尤其对于缺乏专家资源的中小型农场,其价值不可估量。
结论与展望
本文系统性地提出并论证了构建下一代农业AI智能体——“数字农学家”的技术路线图。我们告别了在“海岸线”徘徊的传统静态视觉模型,深入探索了由知识图谱、强化学习和大型语言模型构成的农业AI“内陆大陆”。
通过融合知识图谱的因果推理能力,我们让AI从“看清”进化到了“理解”;通过赋予其强化学习的长期规划能力,我们让AI从“诊断”进化到了“战略决策”;最后,通过集成大型语言模型的自然交互能力,我们让AI从一个冷冰冰的“数据工具”转变为一个可以与人类专家并肩作战的“数字伙伴”。
这不仅仅是一次技术的升级,更是一场深刻的生产关系变革。未来的农场管理者,将不再是繁杂农事操作的执行者,而是与“数字农学家”Agent共同制定战略目标的“指挥官”。他们将从重复性的田间观察和经验判断中解放出来,专注于更高层次的经营规划、市场策略和技术创新。
当然,通往这一愿景的道路依然充满挑战:高保真农业仿真环境的构建、多模态数据的融合、小样本学习下的RL策略训练、以及保障AI决策的安全性与可靠性等,都是亟待学术界和产业界共同攻克的难题。
然而,航向已经明确。正如地理大发现开启了人类文明的新纪元,向农业AI“内陆大陆”的探索,也必将为我们开辟一个更加高效、更加精准、更加可持续的智慧农业新时代。未来的农业,将不再仅仅是土地与汗水的耕耘,更是数据与智慧的结晶。