网站免费维护期是多少.net 做手机网站吗
本节包含三个主要部分:
- RLHF的动机
- RLHF框架
- RLHF面临的挑战
Motivation for RLHF
大型语言模型(LLMs)能够从人类提示中生成令人信服的文本完成
这说明了为什么我们需要RLHF - 它能帮助模型更好地理解和执行人类的意图。
LLMs are successful at generating compelling completions for human prompts.
However, how do we make sure the generated text follows human preferences, i.e., values and goals?
对齐定义Alignment: "将人类价值观和目标编码到LLMs中的过程,使其尽可能有帮助、安全和可靠。"
Process of encoding human values and goal into LLMs to make them as helpful, safe and reliable as possible.”
这表明RLHF不仅仅是提高模型性能,更重要的是确保模型的输出符合人类的期望和价值观。
对齐在LLMs中可以帮助实现三个主要目标:
- 通过阻止有害回答来提高模型安全性 safer
- 通过阻止事实错误回答来提高模型可靠性 reliable
- 通过鼓励定制化回答来提高模型帮助性(如遵循特定规则和政策) helpful
这些目标难以直接集成到基础模型训练中,因此需要RLHF在预训练后进行调整。 using human feedback on produced text once the foundational model is trained, to fine tune it
The RLHF framework
RLHF的发展历程:
最初由Christiano等人(2017)和Stiennon等人(2020)开发
通过Long等人(2022)的InstructGPT实现普及
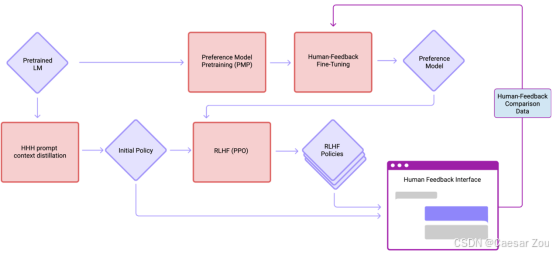
RLHF包含3个核心步骤:
- 预训练模型(如LLM)
- 收集人类偏好数据并训练奖励模型
- 使用奖励模型通过强化学习微调初始模型
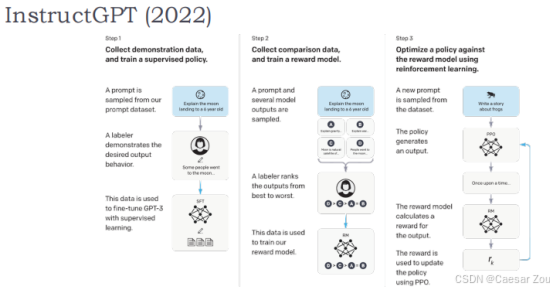
第一步:收集示范数据,训练监督策略
- 收集数据:从现有的提示数据集中随机选择一个提示,如“向一个六岁的孩子解释月球”。
- 人工示范:一个标注员将展示期望的输出行为,比如具体如何向六岁孩子解释月球。
- 使用监督学习进行微调:使用这些人工示范的数据对 GPT-3 进行微调,目的是使模型学习如何产生期望的输出。
这一步是让模型学习直接从精确、高质量的示例中生成特定的输出。这类似于老师在课堂上示范一个数学问题的解法,然后让学生模仿这种方法。
第二步:收集比较数据,训练奖励模型
- 收集数据:使用一个提示和多个模型输出进行样本的生成。
- 标注员评级:标注员将这些输出从最好到最差进行排序。
- 训练奖励模型:使用这些排序后的数据训练一个奖励模型,该模型旨在学习如何评估模型输出的质量。
这个过程类似于在一个竞赛中对参赛作品进行评分。它帮助模型理解不同输出间的质量差异,并且学习如何改进以生成更受欢迎的结果。
第三步:针对奖励模型优化策略,使用强化学习
- 生成新的提示:从数据集中随机抽取一个新的提示,如“写一个故事”。
- 策略生成输出:使用策略生成一个输出,例如故事的开头。
- 计算奖励:奖励模型评估此输出并计算奖励值。
- 更新策略:使用 PPO(Proximal Policy Optimization,近端策略优化)根据奖励值更新策略。
这一步骤的核心是通过“试错”学习更好地完成任务。模型通过不断尝试和调整,学习如何改进其生成的内容,使其更符合人类的期望和标准。
总结
第一步:预训练模型
预训练模型的特点:
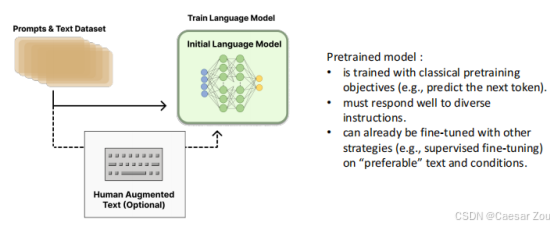
使用传统预训练目标(如预测下一个token)
必须能够很好地响应各种指令
可以通过其他策略(如监督微调)在"理想"文本上进行微调
第二步:训练奖励模型
包含两个阶段:
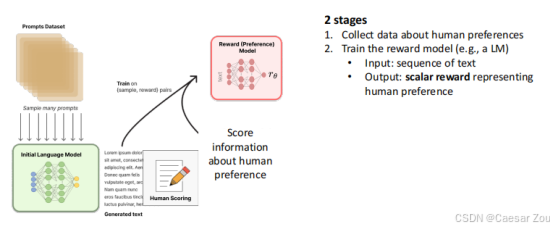
收集人类偏好数据
训练奖励模型(通常是语言模型)
- 输入:文本序列
- 输出:表示人类偏好的标量奖励值


实际评估练习
关于飓风Helene的新闻文章摘要评估案例:


原文介绍了飓风Helene即将登陆佛罗里达的情况
提供了3个不同的摘要版本供评估
这个练习展示了如何在实践中收集人类偏好数据
例:评价1:此摘要忠实于原文,保持了主要信息的完整性,并清楚地传达了关键信息。
第三步:强化学习微调
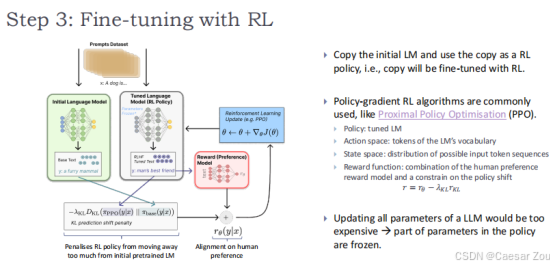
- 复制初始语言模型作为RL策略(这个模型已经能够生成基于文本的输出,但可能不完全符合特定的人类偏好,所以将这个副本将通过强化学习进行微调)
- 使用近端策略优化(PPO)等策略梯度算法

参数冻结:更新所有参数会非常昂贵,因此策略中的部分参数是冻结的,只有一部分参与优化。
微调目标:使用RL微调的目的是通过奖励模型的指导,精细调整模型的输出,使其更符合用户的期待和偏好。
Iterated Online RLHF
Anthropic提出的在线迭代版本:
传统RLHF使用离线RL(基于静态数据集)
在线版本允许持续更新和改进
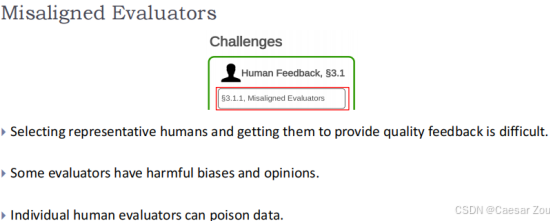
RLHF面临的挑战

评价者和目标用户的不对齐 难监管 数据质量 不同反馈类型的限制(文本 评分)
问题设定错误(围捕捉正确需优化目标) 错误泛化或者引起黑客攻击(模型找到奖励函数漏洞) 评估困难(环境复杂情况下)
RL的困难(维度 训练稳定性 收敛) 乱泛化(违规问题上或者无法处理新问题)
分布复杂
Joint RM/Policy Training Challenges同时训练奖励模型和策略可能导致额外的复杂性,因为两者的目标需要仔细平衡,以避免相互冲突。

Addressing challenges in RLHF

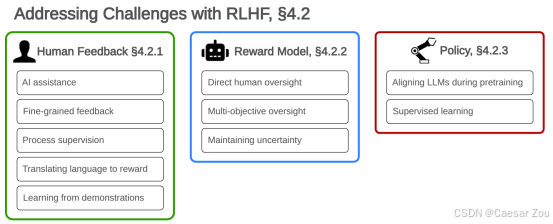
1.Human Feedback(人类反馈)
- AI assistance(AI辅助):使用AI技术来辅助评估者,减少人为误差。
- Fine-grained feedback(细粒度反馈):收集更具体、更详细的反馈,以提高数据质量。
- Process supervision(过程监督):增强对评估过程的监督,确保数据收集的一致性和可靠性。
- Translating language to reward(将语言转换为奖励):将人类的语言反馈转换为可量化的奖励信号,以供模型学习。
- Learning from demonstrations(通过示范学习):通过观察具体的行为示范来学习,而不仅仅是通过评价者的言语反馈。
2. Reward Model(奖励模型)
- Direct human oversight(直接人类监督):确保人类直接参与奖励模型的训练过程,以监控和指导模型的行为。
- Multi-objective oversight(多目标监督):监督不仅仅基于单一目标,而是多方面考虑,以减少偏见和误导。
- Maintaining uncertainty(保持不确定性):在模型中保持一定的不确定性,以避免过度自信和潜在的误导行为。
3. Policy(政策)
- Aligning LLMs during pretraining(在预训练期间对齐大型语言模型):确保在预训练阶段就引入对齐的策略,以便模型能够在早期就适应特定的人类偏好。
- Supervised learning(监督学习):使用监督学习方法来直接教授模型期望的行为,而不完全依赖于从复杂环境中自我学习。
Ethical implications
人类偏好的主观性(Subjectivity of human preferences)
人类偏好因个人经验、文化背景、语言等因素而异,对于创意性作品等领域,很难达成共识。这意味着,收集到的反馈可能各不相同,难以形成统一的训练目标。
人类评估者的易错性或故意的恶意意图(Fallibility of human evaluators, or even intentional malicious intentions)
执行重复任务时,人类评估者可能无意中提供质量较低的数据,或故意提供有偏见的反馈(如恶作剧)。例如,存在研究指出自动化方法可能被误导,从而扭曲反馈数据。
过度拟合和偏见的风险(Risk of overfitting and bias)
模型可能过度拟合于特定文化、人群或个体的价值观,导致其性能在不同群体中出现差异,或对特定主题产生偏见的回答。
收集人类反馈是一个昂贵的过程(Collecting human feedback is an expensive process)
为了降低成本,可能会采取可疑的数据收集实践,如利用低薪劳动力识别有毒内容,或通过免费源获取数据,这可能导致偏见或低质量的数据。
举例:一篇文章指出OpenAI使用肯尼亚工人以每小时不到2美元的工资来识别有毒内容,这引发了对数据收集伦理的关注。
RLHF流程的有限可扩展性(Limited scalability of the RLHF process)
现有的RLHF方法可能难以扩展到更大的应用范围,研究如“RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback”提供了可能的解决途径。
