从零起步学习MySQL || 第九章:从数据页的角度看B+树及MySQL中数据的底层存储原理(结合常见面试题深度解析)

一、InnoDB 是如何存储数据的
1. InnoDB 的存储结构层次
InnoDB 的数据文件不是随意放数据,而是有严格的层次结构:
逻辑结构层次:
数据库 -> 表空间 (tablespace) -> 段 (segment) -> 区 (extent) -> 页 (page) -> 行 (row)
我们从大到小地解释:
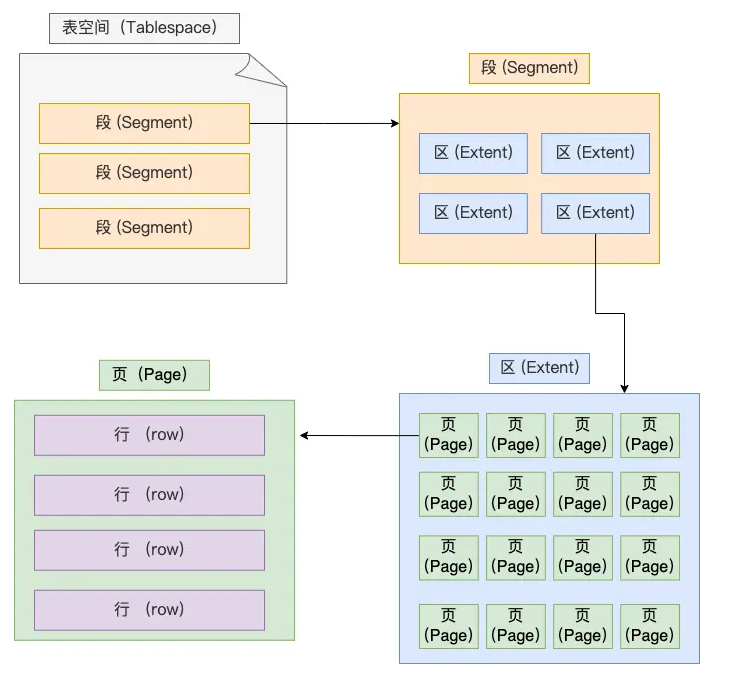
(1) 表空间 (Tablespace)
-
InnoDB 默认会将所有数据存储在一个或多个表空间文件(
.ibd或ibdata1)中。 -
每个表对应一个表空间(如果开启了
innodb_file_per_table=ON),也就是说:表A的数据存储在表A.ibd 表B的数据存储在表B.ibd
(2) 段 (Segment)
-
一个表空间里会有多个“段”。
-
主要有两种段:
-
数据段(Data Segment):存储表的数据。
-
索引段(Index Segment):存储索引的内容(B+ 树的节点)。
-
-
每个索引对应一个段。
(3) 区 (Extent)
-
每个段由多个区组成。
-
一个区(Extent)大小是 1MB。
-
每个区包含多个页(通常为 64 个页)。
(4) 页 (Page)
-
InnoDB 最小的存储单位是页(Page),默认大小为 16KB。
-
页中存储了若干行记录(Row)。
-
常见页类型有:
-
数据页(存表记录)
-
索引页(存B+树节点)
-
Undo页、系统页、事务页等
-
(5) 行 (Row)
-
每一行数据就是我们插入的记录。
-
每行记录包括:
-
用户定义的列
-
隐藏列(如
DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR)
-
-
行内存储采用 行格式(Row Format),如
COMPACT或DYNAMIC,以节省空间。
补充讲解:
因为在第六章https://blog.csdn.net/ze15829163918/article/details/153696668?spm=1001.2014.3001.5502https://blog.csdn.net/ze15829163918/article/details/153696668?fromshare=blogdetail&sharetype=blogdetail&sharerId=153696668&sharerefer=PC&sharesource=ze15829163918&sharefrom=from_link![]() https://blog.csdn.net/ze15829163918/article/details/153696668?fromshare=blogdetail&sharetype=blogdetail&sharerId=153696668&sharerefer=PC&sharesource=ze15829163918&sharefrom=from_linkhttps://blog.csdn.net/ze15829163918/article/details/153696668?spm=1001.2014.3001.5502中我们已经讲过一行数据的存储,这里就直接讲一页数据的存储
https://blog.csdn.net/ze15829163918/article/details/153696668?fromshare=blogdetail&sharetype=blogdetail&sharerId=153696668&sharerefer=PC&sharesource=ze15829163918&sharefrom=from_linkhttps://blog.csdn.net/ze15829163918/article/details/153696668?spm=1001.2014.3001.5502中我们已经讲过一行数据的存储,这里就直接讲一页数据的存储
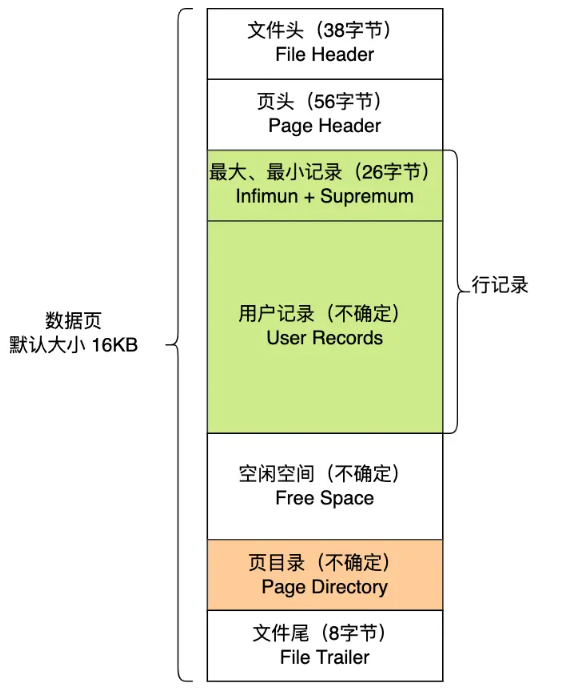
一、InnoDB 数据页是什么?
在 InnoDB 存储引擎中:
-
页(Page)是最小的读写单位;
-
页的默认大小是 16KB(16384字节);
-
页存储在表空间(tablespace)中;
-
不同类型的页有不同作用,比如:
-
数据页(存放表记录)
-
索引页(存放索引节点)
-
Undo页、事务页、系统页等。
-
我们今天重点讲 数据页(Data Page),它的类型在源码中叫 FIL_PAGE_INDEX。
一页(Page)就像一个小“抽屉”,里面放着若干行数据(记录),还有页头、页尾和一些辅助信息用于定位、校验、链接等。
数据页各部分的作用详解
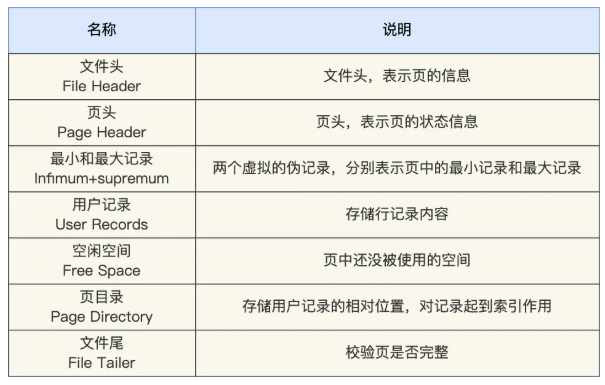
File Header (文件头,38 字节)
存储页与页之间的关系,用于页的链表管理和完整性校验。
每个页都有一个文件头,它包含以下重要信息:
| 字段 | 说明 |
|---|---|
FIL_PAGE_SPACE_OR_CHKSUM | 页校验和,用于检测页是否损坏 |
FIL_PAGE_OFFSET | 页号(唯一标识页在表空间中的位置) |
FIL_PAGE_PREV | 上一个页的页号(双向链表) |
FIL_PAGE_NEXT | 下一个页的页号(双向链表) |
FIL_PAGE_LSN | 该页最后修改的日志序列号 |
FIL_PAGE_TYPE | 页类型(数据页=0x45BF) |
作用:
帮助 InnoDB 快速在页之间导航(如在B+树叶子节点之间),并验证数据完整性。
Page Header (页头,56 字节)
记录当前页自身的内部状态和控制信息,供存储引擎管理页内记录。
| 字段 | 说明 |
|---|---|
PAGE_N_DIR_SLOTS | 页目录中槽的数量 |
PAGE_HEAP_TOP | 空闲空间的起始位置 |
PAGE_N_HEAP | 当前页中的记录数量 |
PAGE_FREE | 指向第一个可重用的空闲记录的指针 |
PAGE_LEVEL | B+树的层级(0=叶子页) |
PAGE_INDEX_ID | 索引 ID(标识属于哪个索引) |
PAGE_MAX_TRX_ID | 最近修改此页的最大事务 ID |
作用:
管理该页中的记录存储情况,如:有多少条、空闲空间在哪、属于哪棵索引树等。
Infimum 和 Supremum 伪记录(26 字节)
在每个页中都有两条“伪记录”:
-
Infimum(下限):比所有用户记录都小;
-
Supremum(上限):比所有用户记录都大。
这两条记录并不存储真实数据,而是充当**哨兵(sentinel)**的作用。
作用:
-
方便页内记录的范围比较;
-
支撑页内有序链表结构;
-
避免边界判断逻辑复杂化。
可以理解为:
页内所有用户记录都位于 Infimum 与 Supremum 之间。
User Records(用户记录区)
这是最核心的部分——存放真正的行数据(row)。
每条记录(行)包含:
-
变长字段长度列表
-
NULL 标志位列表
-
数据列
-
隐藏列(
DB_TRX_ID,DB_ROLL_PTR,DB_ROW_ID) -
记录头信息(record header)
InnoDB 中的每条记录都组成一个单向链表,按主键顺序链接:
Infimum -> row1 -> row2 -> ... -> rowN -> Supremum
作用:
存放用户真实数据,并按照主键有序排列,形成页内有序链表。
Free Space(空闲空间)
当页中插入新记录时,InnoDB 就会在 Free Space 区域分配空间。
当记录被删除后,其占用空间会加入空闲链表,以便重用。
作用:
存放尚未分配给记录的空间,提高空间利用率。
Page Directory(页目录)
页内的“目录索引表”,用于加速页内记录查找。
可以理解为页内的“小索引”,结构如下:
Page Directory = [slot1, slot2, slot3, ...]
每个 slot 存储一个记录在页内的偏移地址
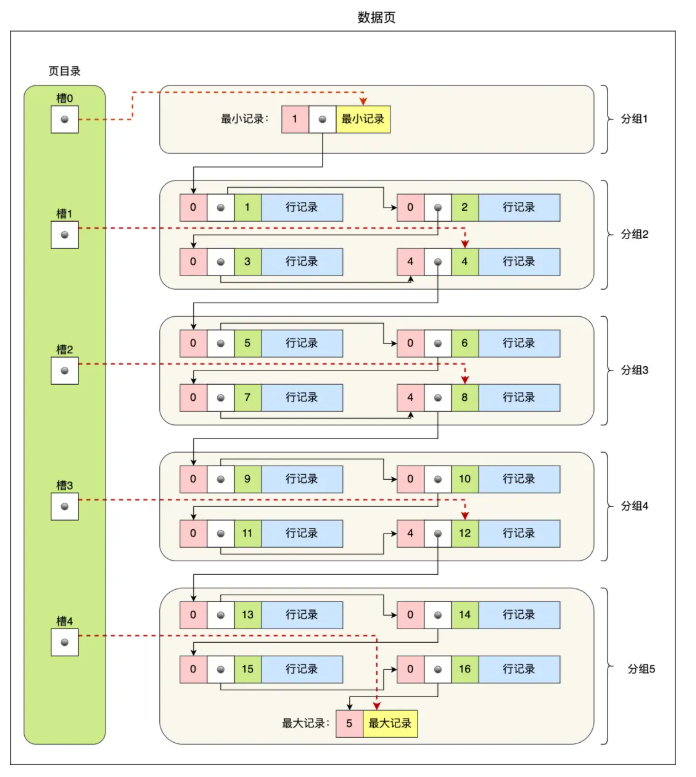
因为页内记录是按主键有序的,InnoDB 可以用二分查找快速定位。
作用:
在页内快速找到目标记录,减少遍历。
File Trailer(页尾,8 字节)
用于校验页是否被破坏(数据一致性检测)。
包含两个字段:
-
校验和(checksum)
-
LSN(日志序列号)
作用:
保证页在磁盘读写过程中数据没有损坏。
2. InnoDB 的聚簇索引存储方式
InnoDB 表的 数据是按主键顺序存放在 B+ 树叶子节点上的。
也就是说:数据文件本身就是一棵 B+ 树(称为聚簇索引,Clustered Index)。
🔹 举个例子:
假设我们有一个表:
CREATE TABLE user (id INT PRIMARY KEY,name VARCHAR(50),age INT
) ENGINE=InnoDB;
InnoDB 内部存储结构如下:
-
整张表是一个聚簇索引。
-
B+ 树的叶子节点中,存放的是整行记录(
id, name, age)。 -
B+ 树的非叶子节点中,存放的是主键值和指向下一层节点的指针。
所以:
-
主键值顺序决定了数据的物理顺序;
-
按主键排序插入性能最好;
-
若没有显式主键,InnoDB 会自动创建一个隐藏主键(6字节递增整数)。
二、B+ 树是如何存储数据的
理解 B+ 树是理解索引的核心。
1. B+ 树结构示意
B+ 树是一种 多路平衡查找树(multi-way balanced search tree),它与普通二叉树不同,每个节点可以有多个孩子节点。
[10 | 20 | 30]/ | \[1,5,7] [12,15,18] [22,25,27,29,30]
特点:
-
所有数据都存储在 叶子节点;
-
非叶子节点只存储 索引键值 和 指针;
-
所有叶子节点通过 双向链表 相连(便于范围查询);
-
树高较低,I/O 次数少。
2. B+ 树中的数据存储
举个例子:
假设我们有数据:
id: 1, 2, 3, 4, 5, 6, 7, 8, 9
当我们在主键上建索引时(即聚簇索引):
-
B+ 树的叶子节点存储整行记录:
[1, row_data1], [2, row_data2], [3, row_data3] ... -
非叶子节点只存储键值和页指针:
[3 | 6]/ \ [1,2] [4,5] [7,8,9]
如果我们建了一个二级索引,比如在 `name` 字段上: sql CREATE INDEX idx_name ON user(name);
-
二级索引的 B+ 树叶子节点存储的是:
name -> 主键值例如:
[Alice -> 1], [Bob -> 2], [Tom -> 7] -
也就是说:
查找name='Tom'时,MySQL 会先在二级索引B+树中找到主键值7,
然后再到聚簇索引B+树中根据主键7找到整行数据。
这叫做 回表查询(Back to Clustered Index Lookup)。
3. B+ 树的性能优势
-
树高低(通常2~3层)
即使上百万行数据,B+ 树高度也很低,一次查询只需 2~3 次磁盘IO。 -
顺序存储
B+ 树的叶子节点是按顺序排列的链表,非常适合范围查询,比如:SELECT * FROM user WHERE id BETWEEN 100 AND 200;只需要扫描一段连续的叶子节点即可。
4. 小结:InnoDB + B+ 树 的整体图示
InnoDB 表结构 = 聚簇索引(B+树)||-- 非叶子节点:索引键 + 指针|-- 叶子节点:整行数据二级索引(可选) = 独立的 B+树||-- 叶子节点:索引键 + 主键值|-- 查询需要 "回表" 到聚簇索引
总结对比表
| 项目 | 聚簇索引 (Clustered Index) | 二级索引 (Secondary Index) |
|---|---|---|
| 叶子节点存储 | 整行数据 | 索引列 + 主键值 |
| 查询是否回表 | 否 | 是 |
| 唯一性 | 主键唯一 | 可重复 |
| 存储顺序 | 按主键顺序 | 按索引列顺序 |
| 查询性能 | 快(直接取数据) | 慢一点(需回表) |