从零起步学习MySQL || 第十章:深入了解B+树及B+树的性能优势(结合底层数据结构与数据库设计深度解析)

一、什么是 B+ 树?
定义
B+ 树(B Plus Tree) 是一种 多路平衡查找树(Multi-way Balanced Search Tree),常用于数据库和文件系统的索引结构。
它是对 B 树(B-Tree) 的一种改进。
每个节点最多可以有 m 个子节点(m 阶 B+ 树),而不是像二叉树那样只有 2 个。
B+ 树的结构特点
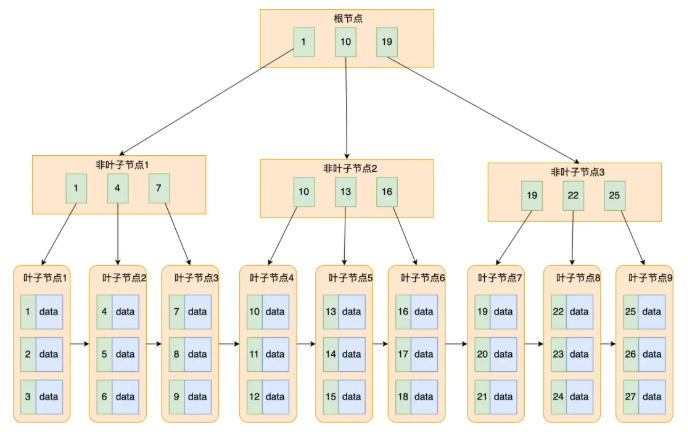
特点总结:
| 特点 | 说明 |
|---|---|
| 1️⃣ 所有数据都存放在叶子节点 | 非叶子节点只存键值和指针,不存放实际数据 |
| 2️⃣ 叶子节点之间有双向链表 | 支持顺序和范围查询 |
| 3️⃣ 树高较低 | 即使存百万行数据,树高通常不超过 3~4 层 |
| 4️⃣ 节点可存多条索引键 | 减少磁盘IO次数,提高查询性能 |
| 5️⃣ 自动保持平衡 | 插入/删除后仍能保持平衡结构 |
二、为什么 MySQL 选择 B+ 树?
我们对比一下常见的几种数据结构
| 数据结构 | 查询复杂度 | 范围查询 | 磁盘IO效率 | 说明 |
|---|---|---|---|---|
| 二叉查找树(BST) | O(logN)(不稳定) | 差 | 差 | 容易退化成链表 |
| AVL树 / 红黑树 | O(logN) | 差 | 差 | 只能内存结构,节点太小 |
| B树 | O(logN) | 一般 | 好 | 内节点也存数据,范围查询不连续 |
| B+树 | O(logN) | 优 | 优 | 数据库最常用结构 |
核心原因:磁盘访问效率 + 范围查询性能
数据库索引存储在磁盘上,而磁盘 I/O 是数据库性能瓶颈。
B+ 树在设计上做了两件事来降低 I/O:
-
每个节点可以存多个键(多路分叉)
⇒ 树高更低,一次查询需要的磁盘页读取次数更少。
比如:-
二叉树可能需要访问几十次;
-
B+ 树只需 2~3 次磁盘IO就能定位到目标。
-
-
叶子节点链表结构方便范围查询
⇒ 只要找到范围起点,一路顺序扫描叶子节点即可完成范围查询。
三、B+ 树在不同操作下的性能表现
单点查询(= 查询)
过程:
-
从根节点开始,按键值查找下层;
-
每层只需一次磁盘IO;
-
到叶子节点后即可找到对应记录。
性能分析:
-
时间复杂度:O(logN)
-
树高低(一般 2~4),磁盘IO次数少;
-
查找效率非常高且稳定。
插入与删除
插入:
-
先找到目标页;
-
插入记录;
-
若页满,则进行 节点分裂(split);
-
若分裂上溢,则可能向上调整索引(保证平衡)。
删除:
-
删除记录;
-
若页太空(低于阈值),可能触发 合并(merge);
-
仍保持树平衡。
性能分析:
-
插入、删除复杂度:O(logN)
-
B+ 树能自动维持平衡,不会退化成链表;
-
分裂/合并成本较低,因为一次操作只影响局部页。
范围查询(BETWEEN / ORDER BY / <, >)
B+ 树在范围查询上远优于B树或红黑树。
因为:
-
所有数据都在叶子节点;
-
叶子节点之间通过 双向链表 相连;
-
只需找到起点叶子节点,然后沿链表顺序遍历即可。
SELECT * FROM user WHERE id BETWEEN 100 AND 200;
执行过程:
-
在B+树中找到
id=100的叶子节点; -
顺着叶子节点链表一直往后扫,直到
id=200; -
中间无需回到父节点查找。
复杂度:O(logN + M)
(logN 定位起点 + M 为结果数量)
这是数据库选择 B+ 树的重要原因之一!
四、MySQL 中的 B+ 树的特点(InnoDB 实现)
MySQL 的 InnoDB 存储引擎对 B+ 树做了特定优化,使之更适合磁盘存储。
1️⃣ 页(Page)为节点单位
-
每个节点对应一个 页(16KB);
-
每次磁盘IO加载整个页;
-
页中存储多个键值(上千个),极大减少树高。
例如:
1000万条记录的表,只需 3~4 层B+树!
2️⃣ 聚簇索引(Clustered Index)
InnoDB 的主键索引是 聚簇索引:
-
叶子节点存储整行数据;
-
数据文件本身就是B+树结构。
CREATE TABLE user (id INT PRIMARY KEY,name VARCHAR(20),age INT
);
📘 聚簇索引B+树结构:
-
非叶子节点存储主键值 + 子节点指针;
-
叶子节点存储整行记录。
👉 按主键查找只需一次 B+ 树遍历。
3️⃣ 二级索引(Secondary Index)
-
叶子节点不存整行数据,只存索引列 + 主键值;
-
查询时若需要整行数据,会先查二级索引,再“回表”到聚簇索引查主键。
示意:
idx_name (name -> id)
聚簇索引 (id -> row_data)
二级索引结构:
-
非叶子节点:索引键 + 指针
-
叶子节点:索引键 + 主键值(指向聚簇索引)
4️⃣ 叶子节点链表
InnoDB 的B+树叶子节点通过 双向链表 相连:
-
支持顺序扫描(
ORDER BY) -
支持范围查询(
BETWEEN/</>)
5️⃣ 自平衡 + 空间利用率高
-
每个页16KB,内部多条记录;
-
节点分裂、合并时保持平衡;
-
减少磁盘IO,提高查询速度。
总结
| 对比项 | B 树 | B+ 树(MySQL采用) |
|---|---|---|
| 数据存放位置 | 各层节点 | 仅叶子节点 |
| 叶子节点是否链表连接 | 否 | 是(双向链表) |
| 范围查询性能 | 一般 | 优(顺序扫描) |
| 树高 | 稍高 | 更低(更多分叉) |
| 查询效率稳定性 | 一般 | 高 |
| MySQL 实现 | — | 每个节点为16KB页 |
一句话总结
MySQL 采用 B+ 树作为索引结构,是因为它能最大化磁盘IO效率,支持高性能的单点查找、插入删除操作,并且天然适合范围查询。
