YOLO学习——图像分割入门 “数据集制作和模型训练”
一、安装labelme
(1)创建labeme环境
打开Anaconda Prompt,输入:
conda create -n labelme python=3.6
进入labelme环境:
conda activate labelme
(2)安装labelme
pip install labelme
安装完成后,输入:
labelme
弹出labeme窗口,说明安装成功。接下来可以查看或者制作语义分割标签。
二、查看语义分割标签
(1)进入labelme环境
打开Anaconda Prompt,输入:
conda activate labelme(2)新建测试脚本
在PyCharm打开之前下载好的ultralytics-8.3.163源码,新建Python文件cs_model.py:
from ultralytics import YOLOmodel = YOLO(r"yolo11n-seg.pt")
print(model.task)
print(model.names)
print(sum(p.numel() for p in model.parameters()))可以看到该模型类型是分割,预测的种类有79种。
D:\anaconda3\envs\yolo\python.exe D:\deeplearning\ultralytics-8.3.163\detect_model.py
segment
{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
2876848进程已结束,退出代码为 0(3)修改预测脚本
复制预测脚本文件mypredict.py另存为Python文件mypredict_v1.py:
from ultralytics import YOLOmodel = YOLO(r"yolo11n-seg.pt")model.predict(source=r"ultralytics/assets",save=True,show=False,save_txt=True,
)点击运行:
D:\anaconda3\envs\yolo\python.exe D:\deeplearning\ultralytics-8.3.163\mypredict_v1.py image 1/2 D:\deeplearning\ultralytics-8.3.163\ultralytics\assets\bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 50.6ms
image 2/2 D:\deeplearning\ultralytics-8.3.163\ultralytics\assets\zidane.jpg: 384x640 2 persons, 1 tie, 51.1ms
Speed: 2.3ms preprocess, 50.9ms inference, 36.5ms postprocess per image at shape (1, 3, 384, 640)
Results saved to runs\segment\predict2
2 labels saved to runs\segment\predict2\labels进程已结束,退出代码为 0查看预测结果:
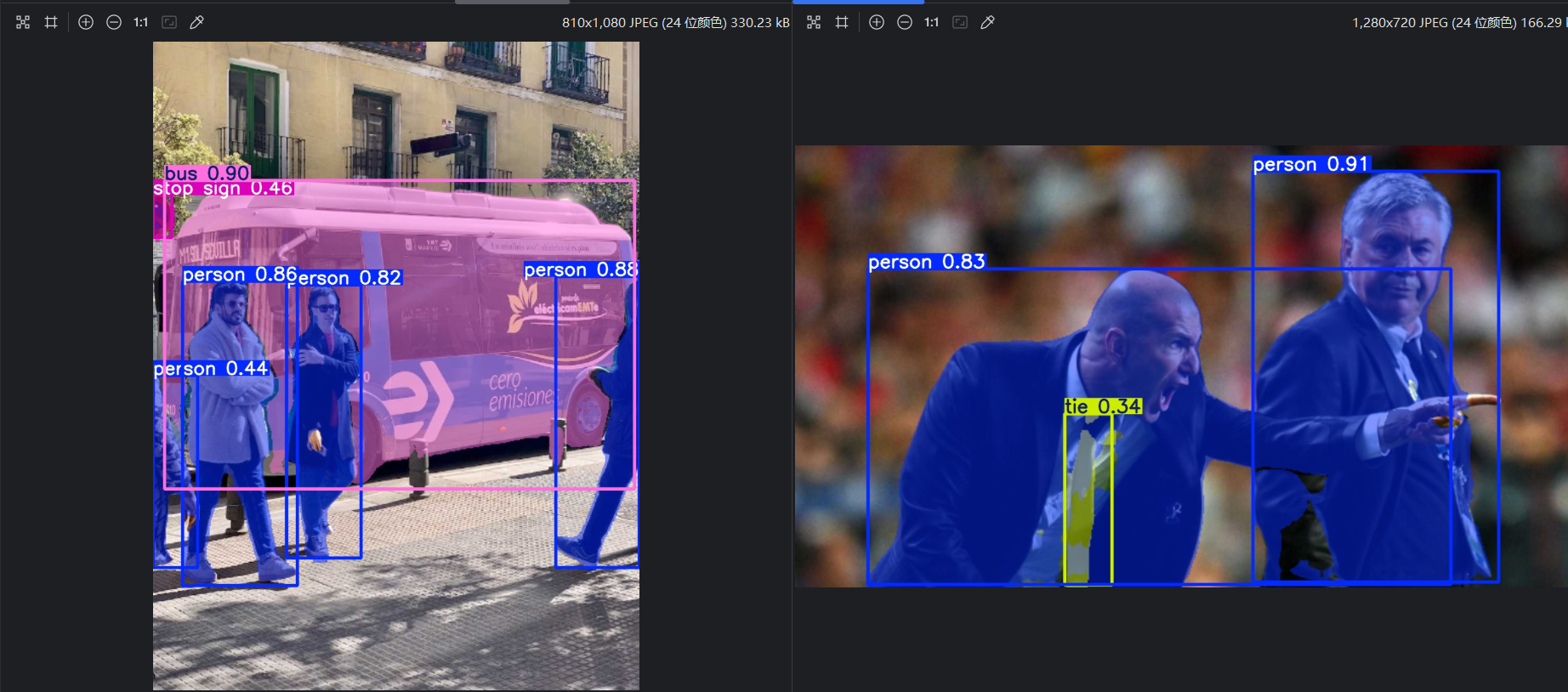
三、制作语义分割数据集
(1)使用labelme标注图片
打开Anaconda Prompt,输入:
conda activate labelme
labelme点击左侧工具栏中的 Open Dir ,选择存放图片的文件夹:
点击左侧工具栏中的 Create Ploygons ,开始标记:
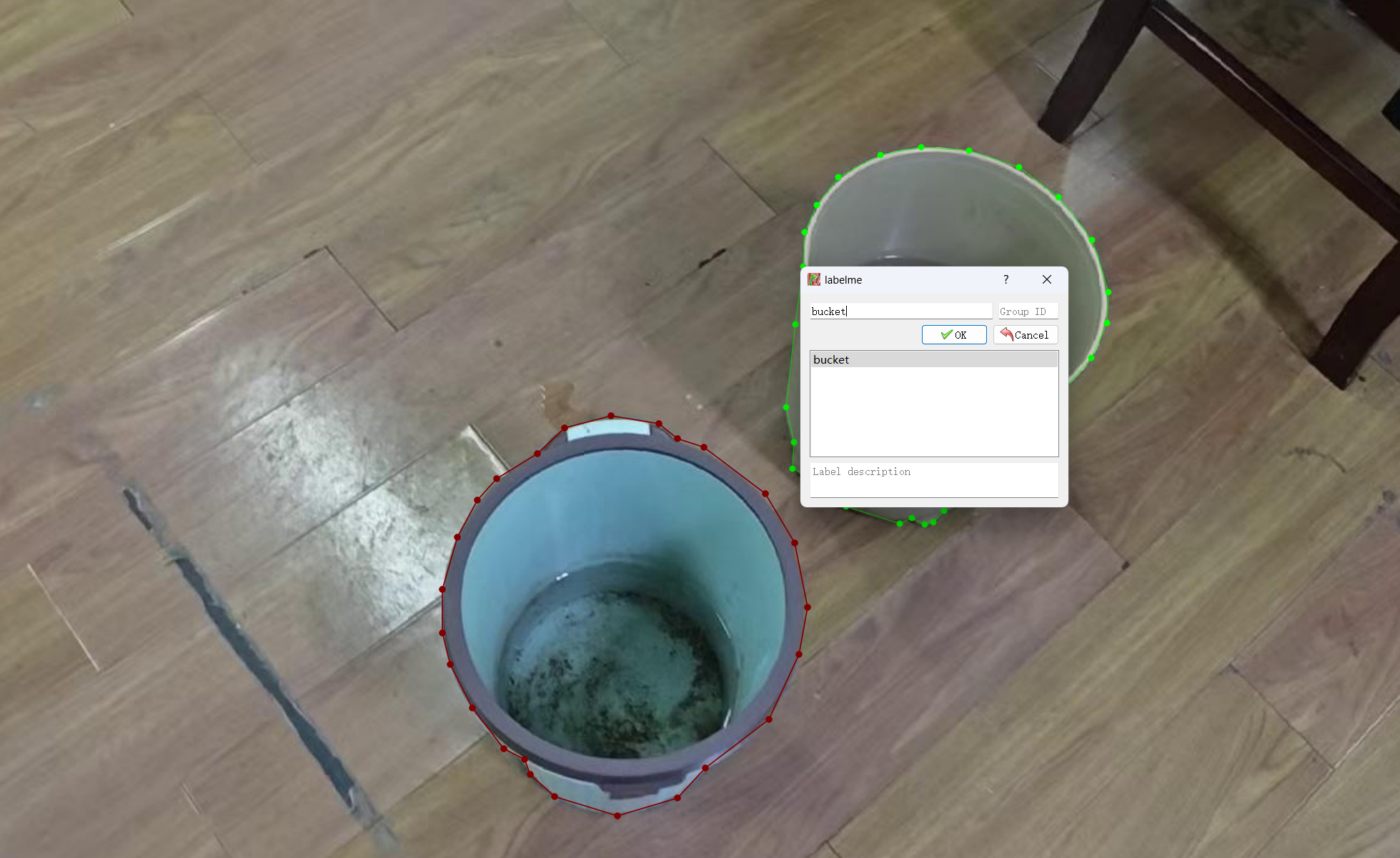
鼠标左键开始标记,沿着预测目标边缘进行连线:

连线闭合后,输入标签名:
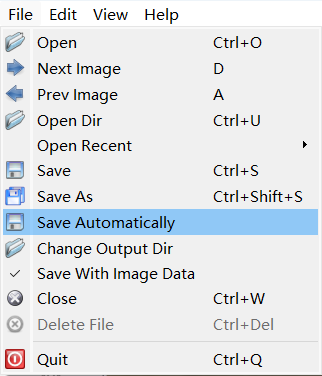
点击左上角的File->Save Automatically,可以自动保存.json标注文件在图片保存路径下:
按A和D可以切换图片,继续标注每一张图片直到标注完所有图片。
(2)转换.json文件为.txt标注文件
打开文件夹,右键按类型排序,将.json标注文件全移动到jsons文件夹下,文件结构为
\bucket_cs\images\train\val\jsons\train\val.json文件不能直接用于YOLO11训练模型,还需要转换为.txt格式。可以借助AI辅助编程:
请给我一些Python代码
现在image文件在D:\deeplearning\make_dataset\bucket_cs\images\train下
语义分割标签文件在D:\deeplearning\make_dataset\bucket_cs\jsons\train下
其中image文件名为xxx_xxxxx.jpg对应xxx_xxxxx.json,如003_00030.jpg对应003_00030.json
现在要把.json文件转换为.txt文件,命名为xxx_xxxxx.txt,如上对应003_00030.txt
保存在D:\deeplearning\make_dataset\bucket_cs\labels\train下
用于YOLO11训练语义分割模型
不要乱动image和json文件位置和内容
请尽量写的清楚点,我是Python小白在PyCharm中新建Python文件transit.py:
import os
import json
import globdef convert_json_to_yolo_segmentation():"""将JSON标注文件转换为YOLO语义分割格式的TXT文件"""# 定义路径images_dir = r"D:\deeplearning\make_dataset\bucket_cs\images\train"jsons_dir = r"D:\deeplearning\make_dataset\bucket_cs\jsons\train"labels_dir = r"D:\deeplearning\make_dataset\bucket_cs\labels\train"# 创建保存标签的目录(如果不存在)if not os.path.exists(labels_dir):os.makedirs(labels_dir)print(f"创建目录: {labels_dir}")# 获取所有的JSON文件json_files = glob.glob(os.path.join(jsons_dir, "*.json"))print(f"找到 {len(json_files)} 个JSON文件")# 类别映射字典 - 你需要根据实际情况修改这个字典# 将你的类别名称映射到对应的ID(从0开始)class_mapping = {"background": 0, # 背景"crack": 1, # 裂缝# 添加更多类别...# "class_name": class_id,}# 处理每个JSON文件for json_path in json_files:try:# 从JSON文件名生成对应的TXT文件名json_filename = os.path.basename(json_path)base_name = json_filename.replace(".json", "")txt_filename = base_name + ".txt"txt_path = os.path.join(labels_dir, txt_filename)print(f"正在处理: {json_filename} -> {txt_filename}")# 读取JSON文件with open(json_path, 'r', encoding='utf-8') as f:data = json.load(f)# 获取图像尺寸image_width = data.get("imageWidth", 0)image_height = data.get("imageHeight", 0)if image_width == 0 or image_height == 0:print(f"警告: {json_filename} 中未找到有效的图像尺寸")continue# 准备写入TXT文件的内容txt_content = []# 处理每个标注形状shapes = data.get("shapes", [])for shape in shapes:# 获取类别名称和点坐标label_name = shape.get("label", "")points = shape.get("points", [])# 跳过空的点集if len(points) < 3: # 多边形至少需要3个点continue# 获取类别IDif label_name in class_mapping:class_id = class_mapping[label_name]else:# 如果类别不在映射中,跳过或者使用默认值print(f"警告: 未知类别 '{label_name}',跳过")continue# 将坐标归一化到0-1范围(YOLO格式要求)normalized_points = []for point in points:x, y = point# 归一化坐标normalized_x = x / image_widthnormalized_y = y / image_heightnormalized_points.extend([normalized_x, normalized_y])# 构建YOLO格式的行:class_id x1 y1 x2 y2 ...yolo_line = f"{class_id} " + " ".join([f"{coord:.6f}" for coord in normalized_points])txt_content.append(yolo_line)# 写入TXT文件with open(txt_path, 'w', encoding='utf-8') as f:f.write("\n".join(txt_content))print(f"成功转换: {txt_filename} (包含 {len(txt_content)} 个分割对象)")except Exception as e:print(f"处理文件 {json_path} 时出错: {str(e)}")print("\n转换完成!")print(f"JSON文件位置: {jsons_dir}")print(f"生成的TXT文件位置: {labels_dir}")def check_file_correspondence():"""检查图像文件和JSON文件的对应关系"""print("正在检查文件对应关系...")images_dir = r"D:\deeplearning\make_dataset\cs\images\train"jsons_dir = r"D:\deeplearning\make_dataset\cs\jsons\train"# 获取所有图像文件和JSON文件image_files = set([os.path.splitext(f)[0] for f in os.listdir(images_dir) if f.endswith('.jpg')])json_files = set([os.path.splitext(f)[0] for f in os.listdir(jsons_dir) if f.endswith('.json')])# 找出对应的文件common_files = image_files & json_filesonly_images = image_files - json_filesonly_jsons = json_files - image_filesprint(f"共有 {len(common_files)} 对匹配的文件")print(f"只有图像没有JSON的文件: {len(only_images)}")print(f"只有JSON没有图像的文件: {len(only_jsons)}")if only_images:print("只有图像的文件示例:", list(only_images)[:5])if only_jsons:print("只有JSON的文件示例:", list(only_jsons)[:5])if __name__ == "__main__":# 首先检查文件对应关系check_file_correspondence()# 然后执行转换convert_json_to_yolo_segmentation()# 显示使用说明print("\n" + "="*50)print("使用说明:")print("1. 请根据你的实际类别修改 class_mapping 字典")print("2. 确保JSON文件包含 'imageWidth' 和 'imageHeight' 信息")print("3. 确保JSON文件中的 'shapes' 包含多边形标注信息")print("4. 生成的TXT文件格式: class_id x1 y1 x2 y2 ...")print("="*50)使用前需要修改的地方:
class_mapping = {"background": 0, # 修改为你的背景类别"crack": 1, # 修改为你的实际类别"class2": 2, # 添加更多类别# ... }输出格式:
每个.txt文件包含多行,每行格式为:
class_id x1 y1 x2 y2 x3 y3 ...其中坐标是归一化后的值(0-1之间)。
运行后会显示详细的处理过程和统计信息,方便你检查转换结果。
(3)新建classes.txt文件
在labels\train和labels\val下分别新建classes.txt文件:
bucket里面填写预测类型。将bucket_cs文件夹复制到D:\deeplearning\ultralytics-8.3.163\datasets下重命名为bucket_cs_seg,至此数据集创建完成。
(4)新建配置文件
在下ultralytics\cfg\datasets新建配置文件bucket_seg.yaml:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: bucket_cs_seg # dataset root dir
train: images/train
val: images/val
test: # Classes
names:0: bucket四、训练自己的分割模型
(1)训练模型
修改训练脚本mytrain.py:
from ultralytics import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'ms = ['yolo11n-seg',
]if __name__ == '__main__':for m in ms:model = YOLO(m + ".pt")model.train(data=r"bucket_seg.yaml",epochs=500,imgsz=640,batch=-1,workers=1,cache="ram",project="results_bucket_seg_500",name=m,)点击训练,可以看到训练正常进行:
训练结束后可以在\results_bucket_seg_500下查看训练结果和模型。
(2)测试模型
修改预测脚本mypredict.py:
from ultralytics import YOLOmodel = YOLO(r"D:\deeplearning\ultralytics-8.3.163\results_bucket_seg_500\yolo11n-seg\weights\best.pt")model.predict(source=r"D:\deeplearning\make_dataset\cs\vedios\003.mp4",save=True,show=False,save_txt=True,
)点击运行,结束后可以在runs/segment下查看结果。