计算机视觉——从环境配置到跨线计数的完整实现基于 YOLOv12 与质心追踪器的实时人员监控系统
引言
在本课中,我们将继续探索 YOLOv12,它是第一个融入注意力机制的 YOLO 模型——包括 RELAN、区域注意力(Area Attention) 以及用于快速推理的可选 FlashAttention 支持等创新。正如我们在上一个教程中所介绍的,YOLOv12 引入了一个灵活的架构,支持先前版本(例如 YOLOv11 和 YOLOv8)提供的所有主要任务,包括目标检测、分割、分类和姿态估计。
我们还介绍了 运行 YOLOv12 的两种方式:
- 使用 官方 GitHub 仓库,支持 FlashAttention(通过 Gradio 演示或 CLI)
- 使用 Ultralytics pip 包,获得更简单、即插即用的体验
在本教程中,我们将超越静态推理,演示 如何将 YOLOv12 应用于一个真实的、基于摄像头的应用:人员追踪监控。
无论是购物中心、地铁站还是校园大门,实时追踪进出空间的人数可以提供宝贵的操作洞察。我们将展示如何:
- 使用 YOLOv12 从鸟瞰视频中检测人员
- 实现一个轻量级的基于质心的目标追踪器
- 统计有多少人穿过一条虚拟线(进入或离开)
- 导出带有叠加注释和实时 FPS 显示的结果

仅使用一个输入视频,你的系统将:
- 检测并为每个人分配 ID
- 追踪他们穿过虚拟线的运动
- 统计有多少人进入或离开
- 在视频上叠加此信息和 FPS(每秒帧数)统计数据
让我们从头开始构建它。
为什么人员追踪监控很重要
在 图 2 中,使用俯视摄像头设置来监控商场和商业空间中的人流。

统计进出空间的人数不仅仅是一个有趣的计算机视觉项目——它对多个行业都具有实际影响。
在购物中心,了解高峰时段和客流量趋势有助于零售商优化店铺布局、规划促销活动和更有效地管理人力。办公楼和校园可以使用进出统计来确保占用合规性并减少能源浪费。在地铁站、机场和大型活动场所,实时人群监控对于运营效率和公共安全都至关重要。
传统上,这些系统需要昂贵的传感器或手动记录。但是借助强大的模型(例如 YOLOv12)和简单的摄像头设置,我们现在可以仅使用 Python、OpenCV 和深度学习来构建一个准确且可扩展的解决方案。
在我们深入实现之前,让我们简要了解一下系统的结构。
它们如何协同工作
图 3 提供了我们人员追踪监控系统中核心组件如何相互作用的高级概述。
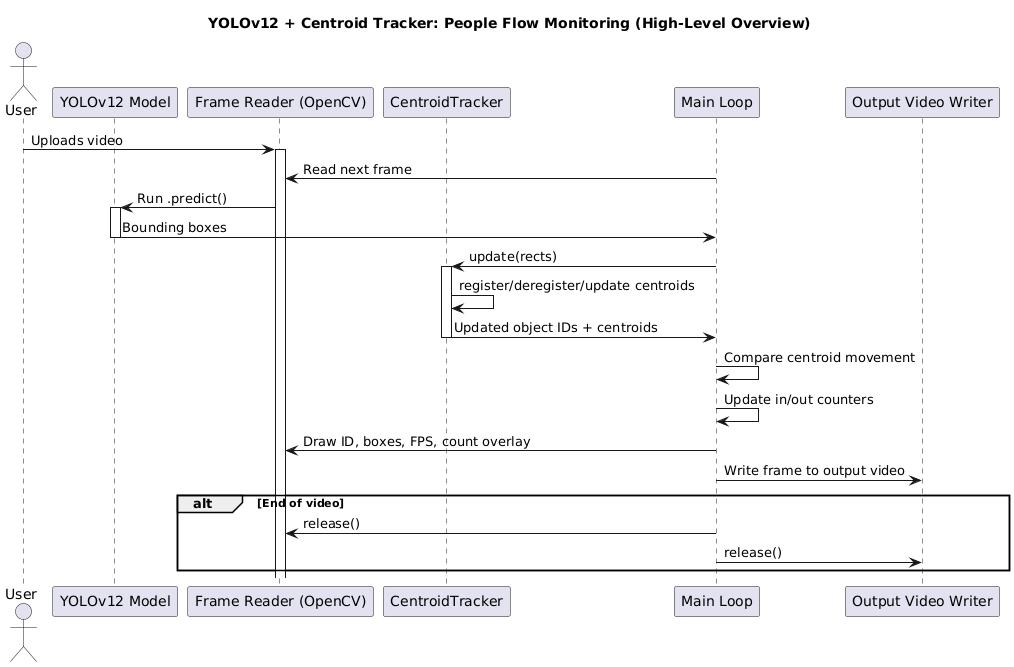
YOLOv12 处理人员检测,质心追踪器管理跨帧的目标身份,而跨线逻辑则统计进出的人数。
在后面的章节中,我们将更详细地分解这个流程——包括质心匹配的工作原理、如何分配 ID,以及我们如何判断某人是“进入”还是“离开”。
YOLOv12 如何实现实时应用
YOLOv12 不仅仅是 YOLO 家族中的又一次迭代——它是第一个通过集成注意力机制而摆脱传统纯 CNN 设计的模型,同时仍保持了 YOLO 闻名的惊人速度。
早期的 YOLO 版本(例如 YOLOv11 和 YOLOv8)严重依赖卷积骨干网络。虽然速度快,但这些模型缺乏全局推理能力,这限制了它们在更复杂和杂乱场景中的性能。YOLOv12 通过引入以下创新改变了这一点:
- RELAN (Residual Efficient Layer Aggregation Network): 一种新的骨干网络架构,它在保持模型轻量级和稳定的同时,提高了特征重用。
- 区域注意力(Area Attention): 一种简化、高效的注意力机制,专为视觉任务中的空间理解而定制。
- FlashAttention(可选): 一种 GPU 优化的注意力内核,可减少内存访问开销,并在支持的硬件(例如 A100、T4、RTX 30/40 系列)上加速推理。
这种组合赋予了 YOLOv12 两方面的优势——既有类似 Transformer 的上下文感知能力,又有 YOLO 级别的速度。
更重要的是,YOLOv12 保留了对现代 YOLO 变体中你所期望的所有主要计算机视觉任务的支持,包括:
- 目标检测
- 定向目标检测
- 实例分割
- 姿态估计
- 分类
这就是为什么它非常适合实时视频应用(例如,我们在本教程中构建的应用)。无论你是在校园大门统计人数,还是在零售店追踪客流量,YOLOv12 都能确保你快速获得准确的检测结果,即使在边缘设备或云 GPU 上也是如此。
配置你的开发环境
要开始使用我们的人员追踪监控系统,你需要安装一些必要的库并加载 YOLOv12 模型。我们将使用 Ultralytics 库 来运行推理。它支持 YOLOv12,并为模型加载和预测提供了简单的接口。
好消息是?在本教程中,你无需担心 FlashAttention 或从源代码构建。Ultralytics pip 包快速、简洁,即使在 Colab GPU 或你的本地机器上也能流畅运行,无需注意力加速。
运行以下单元格来安装我们将需要的一切:
$ pip install -q ultralytics opencv-python matplotlib
加载 YOLOv12 模型
安装完成后,你可以从 Ultralytics 包中加载 YOLOv12 模型。我们将使用 YOLOv12-Small 变体(yolo12s.pt),因为它在实时应用中提供了速度和准确性的良好平衡:
from ultralytics import YOLO# Load the YOLOv12-small model
model = YOLO("yolo12s.pt")
确保 yolo12s.pt 文件存在于你的当前工作目录中。如果尚未提供,我们稍后会在 notebook 中下载它。
一旦你的环境设置完成,我们将获取输入视频并开始构建检测和追踪管道。
下载输入视频
为了演示人员追踪监控的实际应用,我们将使用一个预先录制的俯视监控式视频——非常适合追踪人员在固定场景中的移动。
这个输入视频将作为我们检测和追踪管道的基础。
安装 gdown
$ pip install gdown
下载视频
从 University 门户检索文件 ID 后,将其插入到下面的命令中:
# Replace FILE_ID with the actual file ID from the download link
!gdown --id YOUR_FILE_ID_HERE -O example_02.mp4
一旦视频准备就绪,我们将在深入代码之前,逐步讲解检测和追踪系统的工作原理。
可视化推理和追踪管道
在深入代码之前,了解我们系统的各个组件如何相互作用非常重要。
高级概述
我们的管道分为三个主要阶段,如图 4 所示:
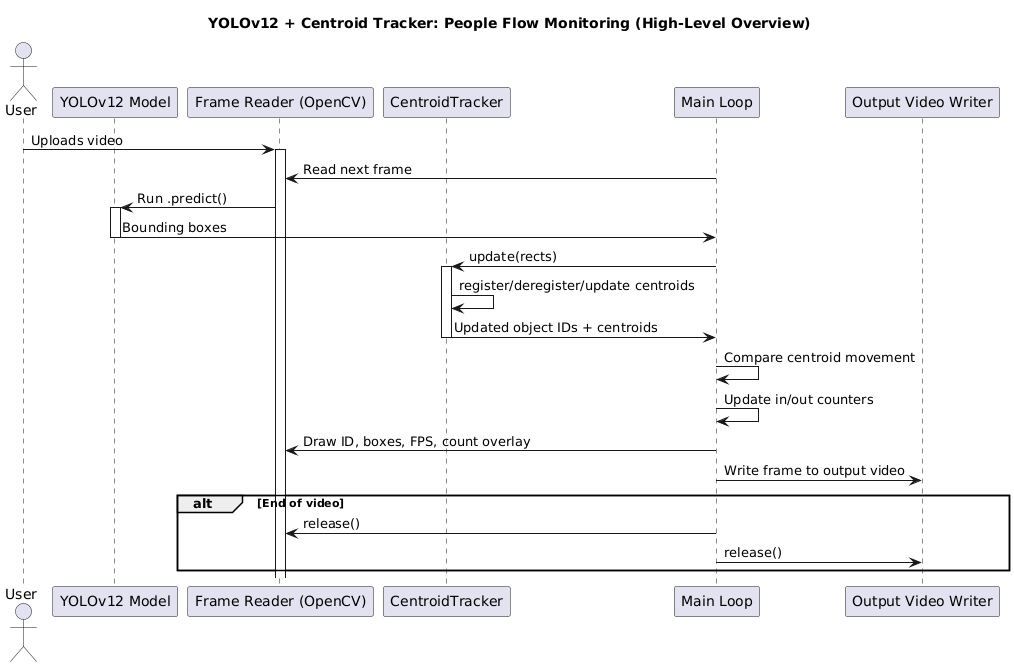
- 检测(Detection): YOLOv12 在每一帧上运行,识别出帧中所有的人员。它返回一个边界框列表,每个边界框都包围着一个人。
- 追踪(Tracking): 质心追踪器接收这些边界框,并将它们与前一帧中已知的、已追踪的目标进行匹配。如果匹配成功,它会更新现有目标的质心位置。如果检测到的目标无法匹配,它会被注册为一个新的目标。
- 计数(Counting): 对于每个已追踪的目标,我们检查它的质心是否穿过我们预定义的虚拟线。如果穿过,我们根据其运动方向(“进入”或“离开”)更新相应的计数器。
详细追踪器分解
质心追踪器是一个简单但高效的算法,用于在视频帧之间保持目标身份。它通过计算每个检测到的边界框的中心点(即质心)来工作。
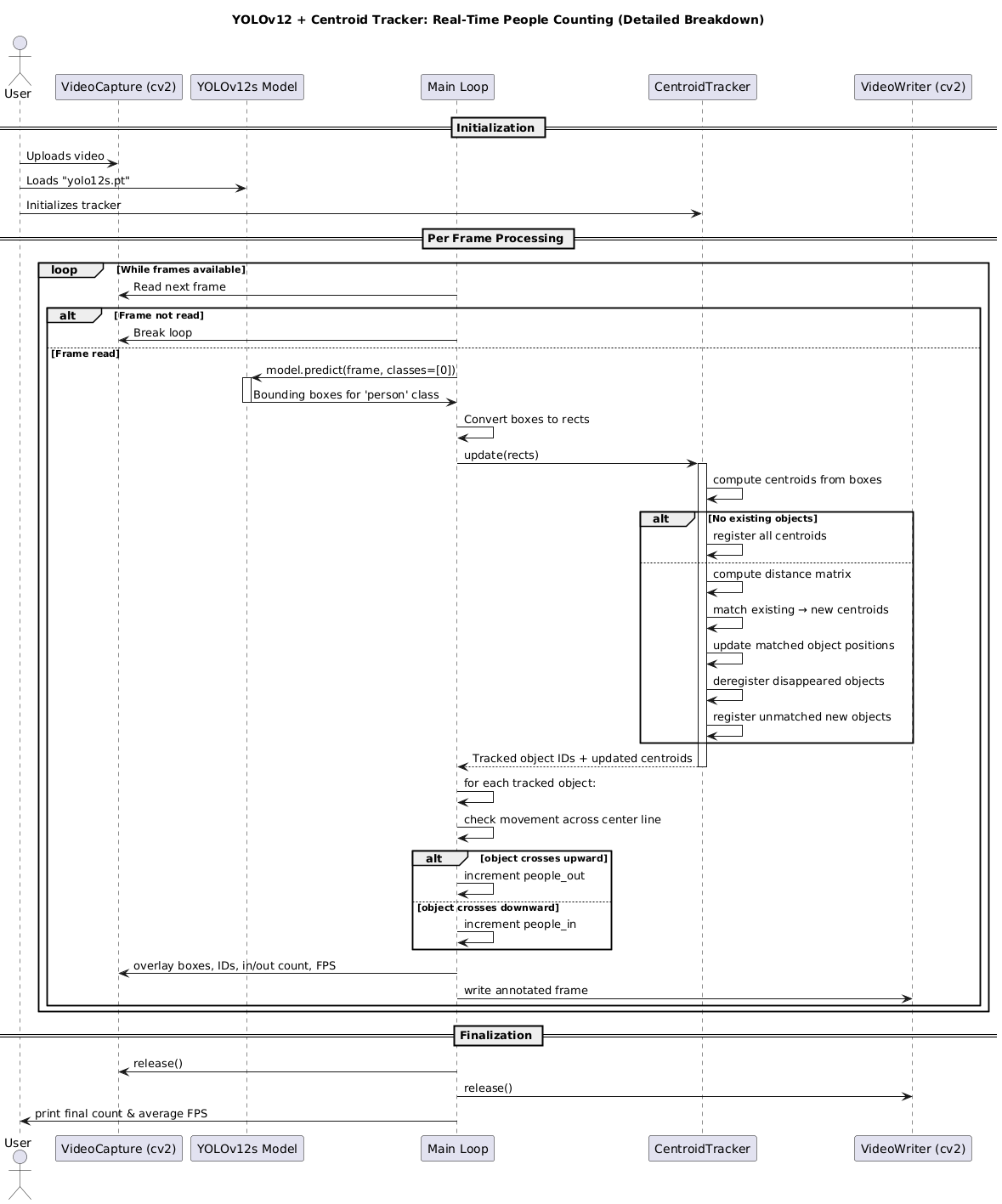
以下是质心追踪器在每一帧上执行的核心步骤:
- 计算质心: 对于 YOLOv12 在当前帧中检测到的每个人员,计算其边界框的中心点(x,y)坐标。
- 匹配质心: 将当前帧中的新质心与前一帧中已追踪目标(已分配 ID 的目标)的现有质心进行比较。
- 使用欧几里得距离: 匹配是基于欧几里得距离完成的。如果一个新质心与一个现有质心足够接近(低于某个预设距离阈值),我们假设它们是同一个目标。
- 更新目标: 如果找到匹配,我们更新现有目标的质心位置,并记录其运动历史。
- 注册新目标: 如果一个新质心无法与任何现有目标匹配,它被视为一个新的目标,并分配一个新的唯一 ID。
- 注销旧目标: 如果一个已追踪的目标在连续几帧中没有被检测到(即没有新的质心与之匹配),我们假设它已经离开了视野或被遮挡,并将其从追踪器中注销。
这个简单的方法在我们的场景中效果非常好,因为它快速且对遮挡具有一定的鲁棒性。
实现质心追踪器
现在我们已经理解了理论,让我们开始编写 CentroidTracker 类。
我们将使用一个 Python 字典来存储我们正在追踪的目标。字典的键是唯一的对象 ID,值是包含目标质心坐标的列表。
from collections import OrderedDict
import numpy as np
from scipy.spatial import distance as distclass CentroidTracker:def __init__(self, maxDisappeared=50, maxDistance=50):# 初始化下一个可用的对象 IDself.nextObjectID = 0# 存储已追踪目标的字典:键是对象 ID,值是质心坐标self.objects = OrderedDict()# 存储目标“消失”帧数的字典self.disappeared = OrderedDict()# 目标在被注销前可以“消失”的最大连续帧数self.maxDisappeared = maxDisappeared# 用于将新质心与现有质心匹配的最大距离self.maxDistance = maxDistance
类初始化
在 __init__ 方法中,我们初始化:
self.nextObjectID: 下一个可用的唯一 ID,从 0 开始。self.objects: 一个有序字典,用于存储我们正在追踪的目标。self.disappeared: 一个有序字典,用于存储每个目标在被注销前已经“消失”的连续帧数。self.maxDisappeared: 一个超参数,用于控制一个目标在被注销前可以“消失”的最大帧数。self.maxDistance: 一个超参数,用于控制将新检测与现有目标匹配的最大欧几里得距离。
注册和注销
register 和 deregister 方法是管理 self.objects 和 self.disappeared 字典的核心。
def register(self, centroid):# 注册一个新目标,为其分配下一个可用的 ID# 并初始化其消失计数为 0self.objects[self.nextObjectID] = centroidself.disappeared[self.nextObjectID] = 0self.nextObjectID += 1def deregister(self, objectID):# 注销一个目标:从两个字典中移除它del self.objects[objectID]del self.disappeared[objectID]
更新逻辑(匹配、注册、注销)
update 方法是追踪器的核心。它接收当前帧中的新边界框列表,并执行匹配、注册和注销逻辑。
def update(self, rects):# 检查当前帧中是否没有检测到边界框if len(rects) == 0:# 增加所有现有目标的消失计数for objectID in list(self.disappeared.keys()):self.disappeared[objectID] += 1# 如果目标的消失计数超过最大限制,则注销它if self.disappeared[objectID] > self.maxDisappeared:self.deregister(objectID)# 返回已追踪目标的列表return self.objects# 初始化一个数组来存储当前帧中输入边界框的质心inputCentroids = np.zeros((len(rects), 2), dtype="int")# 遍历边界框并计算质心for (i, (startX, startY, endX, endY)) in enumerate(rects):cX = int((startX + endX) / 2.0)cY = int((startY + endY) / 2.0)inputCentroids[i] = (cX, cY)# 如果我们当前没有追踪任何目标,则注册所有新检测if len(self.objects) == 0:for i in range(0, len(inputCentroids)):self.register(inputCentroids[i])# 否则,我们尝试匹配现有目标和新检测else:# 获取现有目标 ID 和质心objectIDs = list(self.objects.keys())objectCentroids = list(self.objects.values())# 计算现有质心和输入质心之间的距离D = dist.cdist(np.array(objectCentroids), inputCentroids)# 执行匹配rows = D.min(axis=1).argsort()cols = D.argmin(axis=1)[rows]usedRows = set()usedCols = set()# 遍历匹配for (row, col) in zip(rows, cols):# 如果我们已经使用了行或列索引,则跳过if row in usedRows or col in usedCols:continue# 如果距离超过了最大距离,则跳过if D[row, col] > self.maxDistance:continue# 匹配成功,更新目标objectID = objectIDs[row]self.objects[objectID] = inputCentroids[col]self.disappeared[objectID] = 0usedRows.add(row)usedCols.add(col)# 处理未匹配的现有目标(可能消失了)unusedRows = set(range(0, D.shape[0])).difference(usedRows)for row in unusedRows:objectID = objectIDs[row]self.disappeared[objectID] += 1# 检查是否应该注销目标if self.disappeared[objectID] > self.maxDisappeared:self.deregister(objectID)# 处理未匹配的新检测(注册为新目标)unusedCols = set(range(0, D.shape[1])).difference(usedCols)for col in unusedCols:self.register(inputCentroids[col])# 返回已追踪目标的列表return self.objects
质心追踪器:常见问题解答
问:为什么使用欧几里得距离而不是 IoU(交并比)?
答: IoU 是目标检测中常用的指标,用于衡量两个边界框的重叠程度。然而,对于追踪而言,质心追踪器 依赖于目标的中心点,而不是整个边界框的重叠。
- 速度: 计算质心之间的欧几里得距离比计算 IoU 快得多。在实时应用中,速度至关重要。
- 简单性: 质心追踪器是一种非常轻量级的方法,易于实现和调试。
- 鲁棒性: 对于人员追踪,即使边界框由于姿态变化而略有波动,质心也往往保持稳定。
问:maxDisappeared 和 maxDistance 是如何工作的?
答:
maxDisappeared决定了一个目标在被系统遗忘之前可以“消失”(即没有被检测到)多少帧。这有助于处理短暂的遮挡。maxDistance是一个阈值。如果一个新检测到的质心与任何现有目标的质心之间的距离超过这个值,它将被视为一个全新的目标,而不是现有目标的延续。这有助于防止目标 ID 在拥挤场景中发生错误切换。
在视频帧上运行 YOLOv12
现在我们已经有了 CentroidTracker 类,我们可以将其与 YOLOv12 的检测结果结合起来。
加载模型和 OpenCV 视频对象
我们首先加载 YOLOv12 模型,并设置视频输入和输出对象。
# 导入必要的包
import cv2
from ultralytics import YOLO# 加载 YOLOv12 模型
model = YOLO("yolo12s.pt")# 初始化视频流和输出写入器
cap = cv2.VideoCapture("example_02.mp4")
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))# 设置视频输出
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter('people_counter.mp4', fourcc, fps, (width, height))
设置追踪和计数
接下来,我们初始化 CentroidTracker 实例和用于计数的变量。我们还定义了我们的虚拟线,用于判断人员是“进入”还是“离开”。
# 初始化质心追踪器
ct = CentroidTracker(maxDisappeared=40, maxDistance=50)# 初始化计数器
people_in = 0
people_out = 0# 定义虚拟线(例如,在视频高度的 50% 处)
line_y = height // 2
cv2.line(frame, (0, line_y), (width, line_y), (0, 255, 255), 2)# 存储每个目标的运动历史(用于判断方向)
object_history = {}
逐帧推理和追踪
我们进入主循环,逐帧读取视频,执行 YOLOv12 推理,并更新追踪器。
# 循环处理视频帧
while cap.isOpened():ret, frame = cap.read()if not ret:break# 1. YOLOv12 推理results = model(frame, verbose=False)# 提取人员边界框rects = []for r in results:boxes = r.boxesfor box in boxes:# 确保我们只处理“人员”类别(COCO 数据集中通常是 0)if int(box.cls[0]) == 0:# 获取边界框坐标x1, y1, x2, y2 = box.xyxy[0].int().tolist()rects.append((x1, y1, x2, y2))# 2. 更新质心追踪器objects = ct.update(rects)
更新追踪器和统计运动
在 objects 字典更新后,我们遍历每个已追踪的目标,记录其运动历史,并检查是否穿过了虚拟线。
# 3. 统计运动for (objectID, centroid) in objects.items():# 存储或更新目标的质心历史if objectID not in object_history:object_history[objectID] = []object_history[objectID].append(centroid)# 保持历史记录为最近的几帧if len(object_history[objectID]) > 10:object_history[objectID].pop(0)# 检查是否穿过线if len(object_history[objectID]) >= 2:# 获取最近的两个质心prev_centroid = object_history[objectID][-2]curr_centroid = object_history[objectID][-1]# 检查是否穿过线if prev_centroid[1] < line_y and curr_centroid[1] >= line_y:# 从上到下:进入people_in += 1elif prev_centroid[1] > line_y and curr_centroid[1] <= line_y:# 从下到上:离开people_out += 1
绘制输出并保存帧
最后,我们绘制追踪结果和计数器。
# 4. 绘制输出并保存帧for (objectID, centroid) in objects.items():# 绘制质心和 IDcv2.circle(frame, tuple(centroid), 4, (0, 255, 0), -1)cv2.putText(frame, f"ID {objectID}", (centroid[0] - 10, centroid[1] - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)# 显示计数器cv2.putText(frame, f"In: {people_in}", (10, 30),cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 2)cv2.putText(frame, f"Out: {people_out}", (10, 70),cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)# 绘制虚拟线(再次绘制以确保它在所有内容之上)cv2.line(frame, (0, line_y), (width, line_y), (0, 255, 255), 2)# 写入输出视频out.write(frame)
在这个最终的可视化步骤中,我们用实时追踪信息注释帧。对于每个被检测到的人员,我们在其质心处绘制一个小的绿色圆圈,并使用 cv2.putText 用唯一的 ID 标记他们。我们还叠加了穿过参考线“进入”和“离开”的人数总计。
这些统计数据显示在帧的左上角。添加所有注释后,该帧将使用 out.write(frame) 写入输出视频,从而在最终保存的视频中保留可视化和计数逻辑。
清理
cap.release()
out.release()
cv2.destroyAllWindows()print(f"Done! Saved as people_counter.mp4")
这个最后一步释放了视频对象并完成了处理。
使用 YOLOv12 和质心追踪器可视化人员追踪监控
在 图 6 中,你可以看到我们的实时人员计数系统正在运行,它结合了 YOLOv12 进行检测和质心追踪器进行身份管理和运动分析。

在这个演示中:
- 检测到三个人在帧中移动。
- 两个人正在进入(从上向下移动),一个人正在离开(从下向上移动)。
- 值得注意的是,ID 6 正在向下移动,ID 7 正在向上移动。
一个有趣的观察:紧挨着 ID 6 旁边行走的人尚未被分配 ID。发生这种情况是因为 YOLOv12 在该特定帧中没有以足够高的置信度检测到他们,这可能是由于遮挡或仅部分可见。同时,ID 7 离得更远但完全可见,被更早地检测和注册。
这种行为在 图 7 中也可见。紧挨着 ID 6 的个体还没有 ID,表明尚未对其进行检测。

这种情况突显了实时检测系统的动态性质,其中 ID 是根据何时发生完整、高置信度的检测来分配的,而不是简单地根据接近度。这种能力确保了即使在真实世界条件下(例如,遮挡和交错可见性),也能进行稳健的追踪和准确的人员计数。