Mac Studio 和 DGX Spark 可用性分析
之前老有人给我说 苹果的Mac Studio可以安装DeepSeek满血671B的模型,非常牛,最近网上对 Nvidia DGX Spark 又热火朝天。
首先,声明一下,个人囊中羞涩,没钱去买来试试,只是看了一些资料,来分析一下两种机器的性能,特别是在跑大模型时的性能,看是牛皮吹破天,还是真有其事。
首先,我们关注一下两款机器的价格:
一:价格
1:Mac Studio
做过苹果手机开发的人,应该都知道mac 的迷你盒子,你可以理解为它是盒子的升级版了,只是它的实力最强了(加了NPU,配置更高,还有一些新特性)
为什么我要选这个配置,因为512是我们准备装满血必须的,而 硬盘,选个可以的就行了,再往上选,价格就虚高了。
2:DGX比较简单,我们就选NVidia的,只有这一种配置。现在网上很多人都在买它。
(DGX Deep Learning GPU eXtreme AI 训练/推理机器的品牌,Spark是桌面/开发版)

大家看了价格,相信就知道为啥我要纸上谈兵了。
二:关键特性——统一内存
查了一下资料,为啥这两款机器那么火,原因无非就是低配高能,高能当然指的就是大模型的装载能力。而大模型的装载,如果不看速度(当然,这是不正确的,也是最忽悠人的),那主要是就是显存的大小,而显存是可以用内存来达成的,所以,内存的大小就成了关键。
这两款机器,都提供了较大的内存,而且配备的内存是给到cpu和GPU共享的(在苹果m3中,实际也包括NPU),也就是有相同的地址空间,可以协同共享读写,这样,大大的减少了CPU和GPU在做运算时,对于内存的搬运,当然,也直接方便了GPU、NPU和内存直接访问。
这就叫做统一内存,你可以简单理解为 内存访问更高效了。
但是要注意:内存访问仍然是要时间的,相比服务器的HBM内存(直接核封内存),在这两款机器上的内存访问速度,仍然是差了很多。下面会给出数据。这也是为什么不能直接用主板的DDR内存来作为显存使用的原因,如果依赖PCIe的通讯,那速度就更慢了。因此它和算力芯片最好在一起,因为需要频繁的访问,读取,所以,装载参数的内存需要有访问的高带宽,高速率。
2.1:两个机器的内存都使用了 LPDDR5,且统一给到CPU, GPU, NPU(DGX没有)使用,这样,可以芯片间共享内存来使用,减少通过 PCIe 搬运数据。
2.2:提供的内存很大,可以在访问上将其作为传统的显存使用,提升装载模型的规模。
2.3:但是要注意——在访问内存时,带宽仍然不高。Apple是 800G(2颗),DGX是 273G。低于HBM内存访问速度,也低于独显内存的访问速度。DGX的内存是128G,苹果m3 Ultra最高配是 512G。
【最大装载能力】
单台DGX可以装 200B(MoE,活跃 20B) 可达到 3-15 token,8k prefill 1-3 min
2台可支持 400B模型级别。
两台苹果可以装满血DeepSeek R1,但是,满血运行态,性能推算下来只有 2-10tokens/S,8k prefill 2-5分钟,基本是不可用的。
为什么会这么慢?继续分析原因:
三:芯片算力对比
Apple mac studio 的 m3 ultra 是 CPU/GPU/NPU 三合一的SoC芯片,
CPU是 32 核的,GPU是80核的,NPU是30核的。
其中,npu 的算力 36 tops,我们理解为 FP8的算力。
来看看 Nvidia dgx spark:
CPU 是 2 * 20核ARM架构(10c X925 + 10c A725)。
GPU 是基于Blackwell架构的 GB10,它的 fp4 算力 1pflops。
折算一下,(fp8我们认为是int4的 1/4能力)
DGX 的算力估计是 Apple的 8倍左右。
DGX的算力是 1张4090卡的 3倍。
看起来,DGX的算力还可以。苹果的很弱。
三:内存访问的带宽
如上所述,两者都是采用了 LPDDR5内存,CPU和GPU共享,
DGX的内存带宽差不多是 273G,远小于HBM3e的带宽(1.2T)。低于苹果m3 Ultra的带宽 800G(因为是两颗,单颗是300-400),也低于传统4090显卡的(1T)
折算一下:
DGX内存的带宽是 Apple studio m3 的 1/3。
DGX内存的带宽是 4090卡的 1/4。
DGX 的内存带宽比较低,苹果的基于内存大,还过得去。
四:内存量对比
DGX和Apple的内存统一访问,减少了内存搬运,并且,给的内存大于4090和传统算力卡。
DGX的内存是Apple studio 最高配的 1/4。
DGX的内存是 4090(28G)卡的 4.5倍。
苹果的内存比较大,所以它能装得下满血。
五:集群、扩展性
苹果和DGX的扩展方案类似,实际上都是支持双节点。
两者的双节点都是依赖一个额外的特殊程序来进行分片处理。
苹果互联使用雷雳 5 端口,Nvida的互联使用的是以太网口。
另外,苹果强依赖于Mac系统,它的软件方案是定制的,不能迁移。
两种机器的双节点支持都是点对对的互联,运行态主要是模型权重的切分,与vLLM这种多节点推理架构有本质区别,无法提升速度,并发,吞吐,更多提升的是模型的装载容量。这种扩展,最多也就到4个节点了。
模型分片方案大概是:将DeepSeek R1模型拆分,通过DistributedDataParallel (DDP) 将不同部分加载到两台设备上。使用Ollama进行部署即可。启动推理:编写分布式推理脚本,协调两台设备共同完成计算任务。
所以,DGX 和 Apple Mac Studio的特点都是 装得下,跑得慢,难扩展。
DGX跑得慢的主要原因是内存访问带宽低,苹果跑得慢的主要原因是算力低。
难扩展的原因是本来就定位为桌面版,没有考虑更好的多节点网络和软件支持。
六:模型装载示例
最后,我们以13B,32B,70B模型作对比:
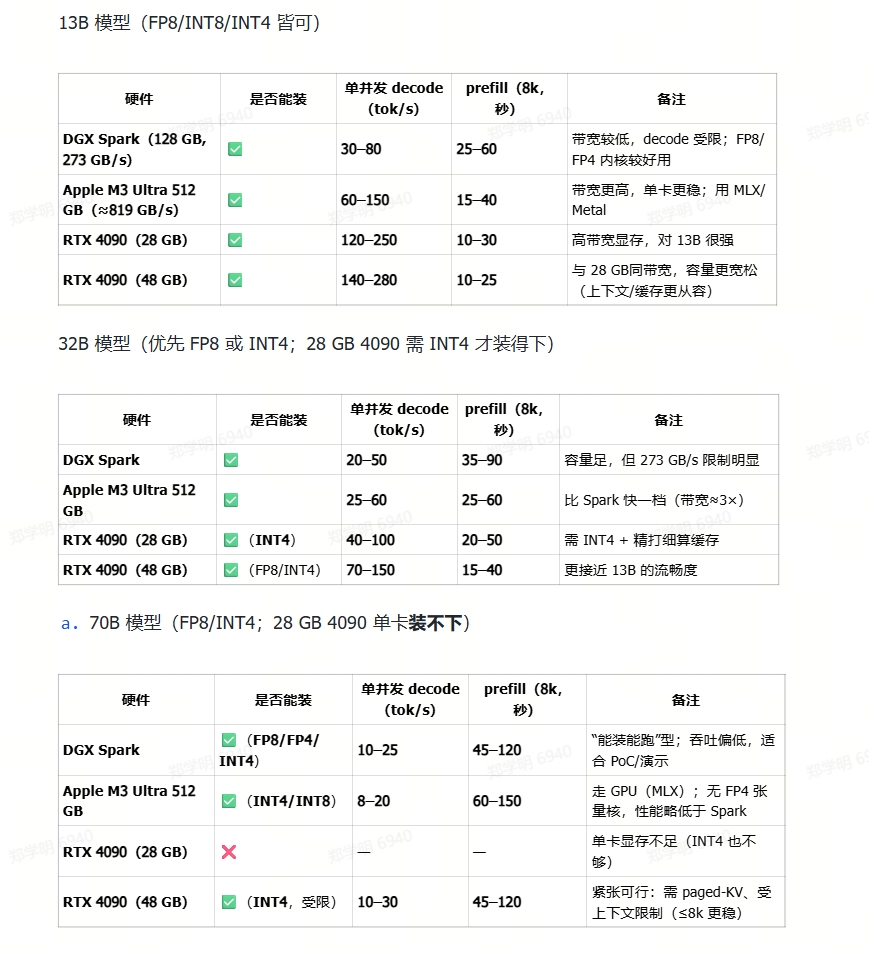
结论:
单台DGX适合跑一下 7-13-32B 的模型,70B勉强可以用来PoC,再大就不行了。
单台Apple的性能和DGX 相当,考虑它的价格是 DGX一倍多,所以,性价比略低于DGX。
使用场景:
个人开发者,在无法获得4090及以上的算力卡的情况下,用来做中小模型的应用开发或者PoC。