Apache Spark算法开发指导-特征转换Normalizer
Normalizer算法用于处理数据标准化以及规范化,缩小数据元素之间的范围差距,让数据元素保持在[-1,1]范围内,更加易于执行数据分析,例如,给定一个向量数据集合以及指定一个参数p,输出数据标准化的向量数据集合。
当p=1时,p的范数Norm的计算公式:
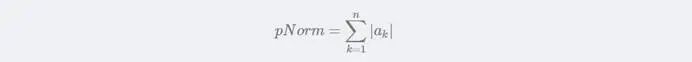
当p=2时,p的范数Norm的计算公式:
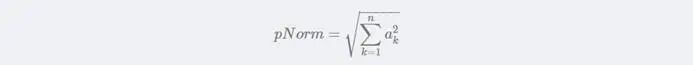
当p=infinity时,p的范数Norm的计算公式:
![]()
当p=其他值时,p的范数Norm的计算公式:
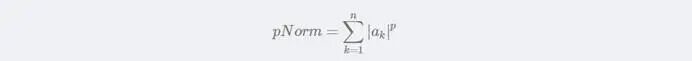
向量数据集合的数据元素的数据规范化的计算公式:
![]()
![]()
Java代码示例
在Java本地开发环境中,创建Normalizer算法测试类,初始化spark实例:

定义测试数据集合,设置数据集合的列名称以及数据类型,对数据集合执行初始化,生成spark数据类型的数据集合:

设置p=1,执行特征转换,输出数据标准化的向量数据集合:

设置p=infinity,执行特征转换,输出数据标准化的向量数据集合:
![]()
运行Java代码,特征转换输出的数据集合:

Scala代码示例
与Java代码示例的功能逻辑相同:
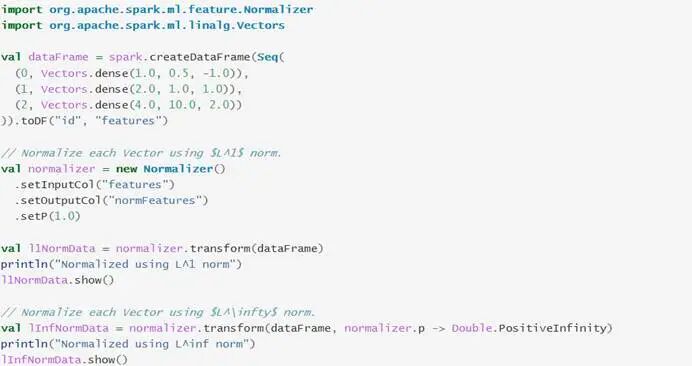
启动spark-shell的Scala本地运行环境:
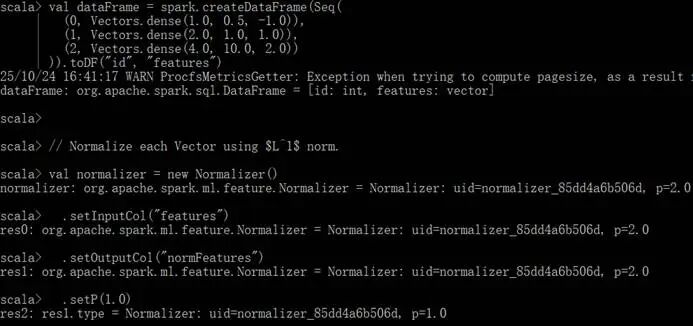
运行Normalizer算法代码:
特征转换输出的数据集合:

