数据处理像搭乐高?详解 RAGFlow Ingestion Pipeline

RAGFlow 自开源以来,一直受到社区的广泛关注。其核心模块 DeepDoc 基于内置的文档解析模型,提供了面向多业务场景的智能文档分片能力,确保 RAGFlow 在检索与生成阶段均能获得准确、高质量的回答。目前,RAGFlow 已内置了十多种文档切片模板,覆盖不同业务场景与文件类型。
然而,随着 RAGFlow 在生产环境中应用日益广泛,原有的十余种固定分片方式已难以应对复杂多样的数据源、文档结构和文件类型。具体挑战包括:
-
需要根据特定业务场景,灵活配置不同的解析与切片策略,以适应多样化的文档结构与内容逻辑。
-
文档解析入库不仅涉及将非结构化数据切分为文本块,更包含一系列关键预处理步骤,以弥补 RAG 检索过程中的“语义鸿沟”。这通常需要借助模型为原始内容附加摘要、关键词、层级结构等语义信息。
-
除本地上传的文件外,还有大量数据、文件和知识来源于网盘、在线服务等多种渠道。
-
随着多模态视觉语言模型(VLM)的成熟,诸如 MinerU、Docling 等在复杂版式、表格及图文混排文档解析方面表现优异的模型不断涌现,它们在各应用场景中均展现出独特优势。
为此,在 RAGFlow 0.21.0 中重磅推出了 Ingestion pipeline。它重构了非结构化数据的清洗流程,允许用户根据具体业务,构建定制化的数据处理链路,实现对异构文档的精准解析。
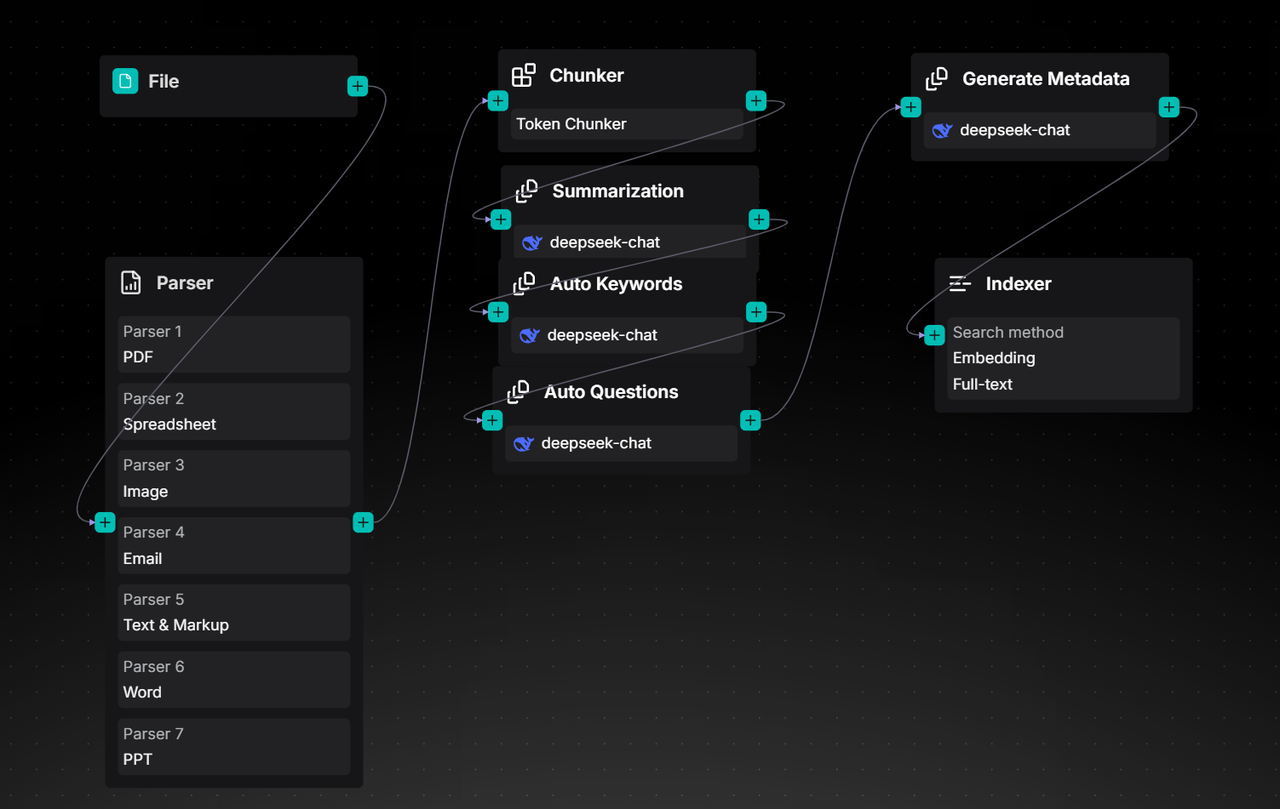
Ingestion pipeline 的介绍
Ingestion pipeline 本质上是一个面向非结构化数据的可视化 ETL 流程。它以 Agent 底座为核心,将一个典型的 RAG 数据写入流程——通常包括文档解析、文本分块、向量化与索引构建等关键阶段——重新划分为三个清晰环节:Parser、Transformer 和 Indexer,分别对应文档解析、数据转换与索引构建阶段。
-
文档解析:作为数据清洗的关键环节,该模块集成了以 DeepDoc 为代表的多种解析模型,能够将原始非结构化数据转化为具备一定结构化的内容,为后续处理奠定基础。
-
数据转换:目前提供 2 类核心算子,包括 Chunker 和 Transformer。其目标是将清洗后的数据进一步加工,转化为适用于多种索引访问的格式,从而为高质量的召回效果提供保障。
-
索引构建:负责完成数据的最终写入。RAGFlow 原生采用多路召回架构以保障检索效果,因此在 Indexer 中内置了多种索引方式,支持用户灵活配置。
下面我们用一个例子,具体展示 Ingestion pipeline 的构建和使用。
首先在 “Agent” 页面点击 “Create agent”,可以选择 “Create from blank” 从空白创建 Ingestion Pipeline:
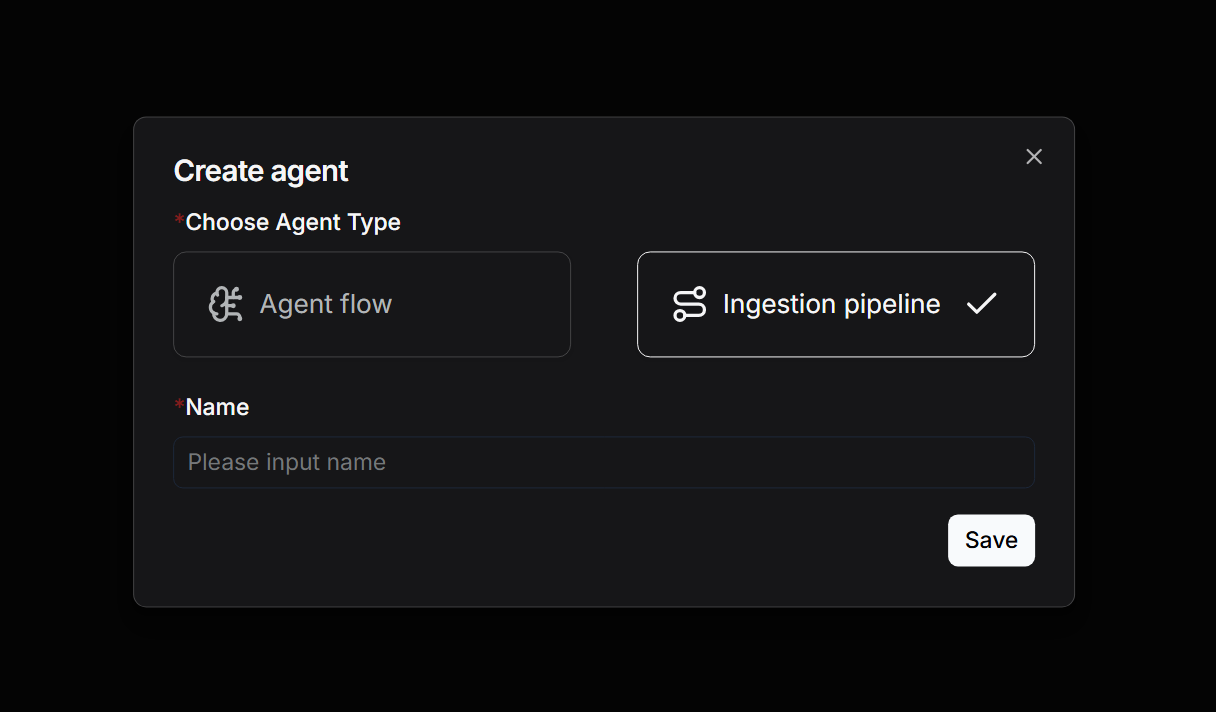
也可以选择 "Create from template",使用已经编排好的 Ingestion pipeline 模板:
接下来开始编排 Pipeline 所需要的各类算子。从空白创建时,初始画布上只会显示 Begin 和 Parser 算子,后续可以从算子的右侧拖拽连接更多不同功能的算子。
首先,需要对 Parser 算子进行配置。
Parser
Parser 算子负责读取和解析文档:识别其布局、提取里面的结构和文本信息,最后获取结构化的文档数据。
这是一种“高保真、结构化”的提取策略。Parser 会智能地适配并保留不同文件的原始特征:无论是 Word 的层级大纲、Spreadsheet 的行列布局,还是扫描版 PDF 的复杂版面。它不仅提取正文,也会完整保留标题、表格、页眉页脚等辅助信息,并将其转换为合适的数据形态,这将在下文详细介绍。这种结构化的区分至关重要,为后续的精细化处理提供了必要的基础。
目前 Parser 算子支持 8 大类别 23 种文件类型作为输入,归纳如下:
| 类别 | 支持的文件格式 |
| Spreadsheet | XLSX, XLS, CSV |
| Image | PNG, JPG, JPEG, GIF, TIF |
| EML | |
| Text & Markup | TXT, MD, MDX, HTML, JSON |
| Word | DOCX |
| PPT | PPTX, PPT |
| Audio | MP3, WAV |
| Video | MP4, AVI, MKV |
在使用时,只需在 Parser 节点内点击 “Add Parser”,选择需要的文件类别(如 PDF、Image 或者 PPT)。当Ingestion pipeline 运行时,Parser 节点会自动识别输入的文件,并将其路由到对应的 parser 进行解析。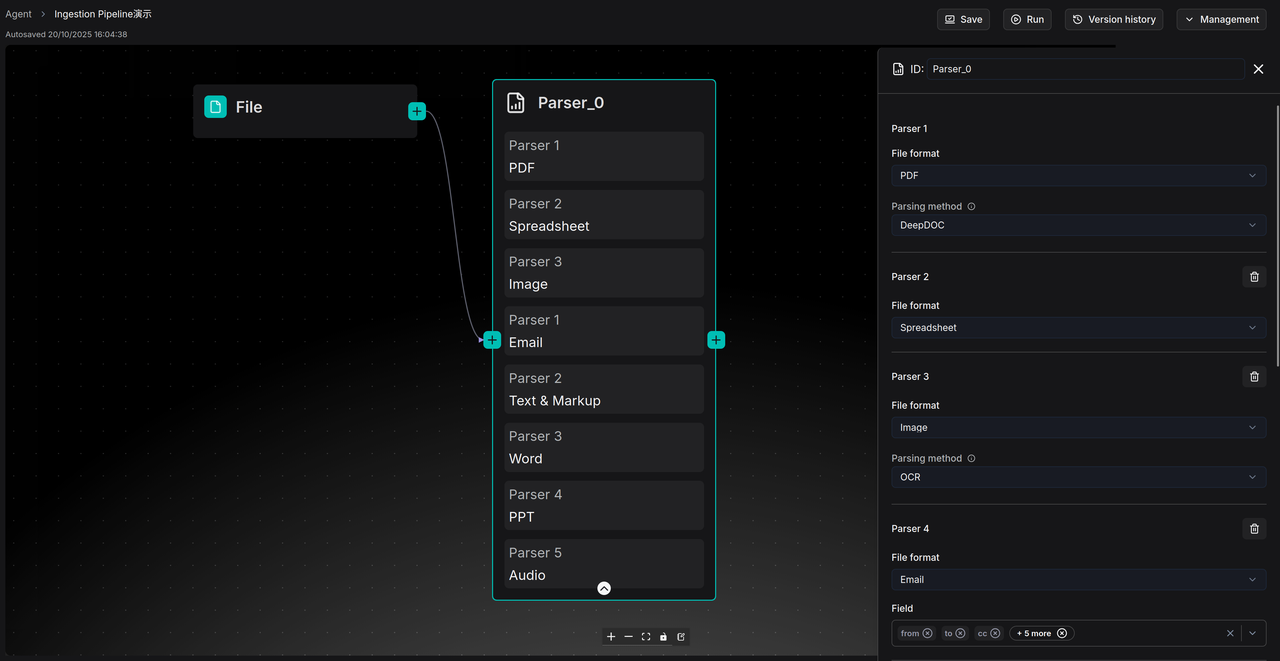
在这里,对几个常见文件类别的 parser 做进一步解释:
-
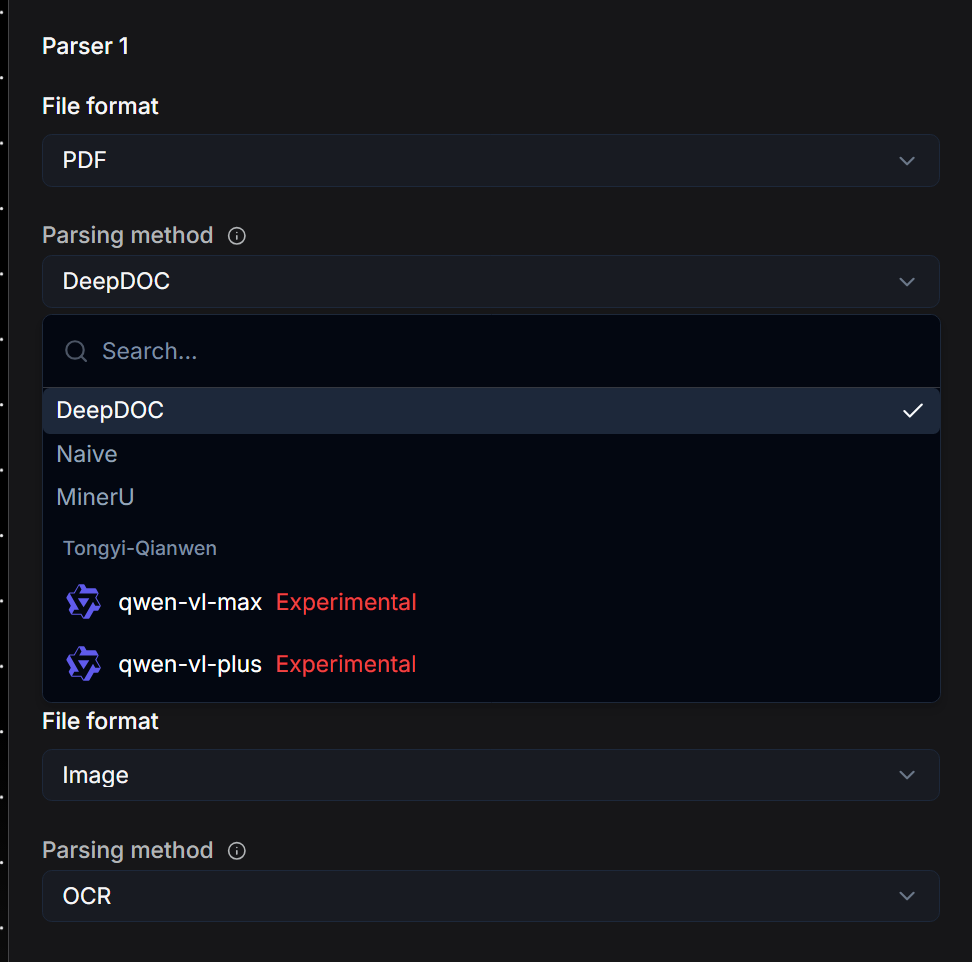
对于 PDF 类型的文件,RAGFlow 提供了多种解析模型的选择,并统一输出为 json 格式:
-
默认 DeepDoc: 这是 RAGFlow 内置的文档理解模型,能够识别版面布局、分栏和表格,适合处理扫描件或复杂排版的文档。
-
MinerU: 目前业内优秀的文档解析模型,除了复杂的文档内容和布局的解析外,MinerU 还可以对数学公式等复杂文件元素,提供良好解析。
-
Naive:不用任何模型,纯文本提取。适合内容没有复杂结构、也没有非文字元素的文档。
-
-
对于 Image 类型,系统会默认调用 OCR 来提取图中文字。此外,用户也可以自行配置支持视觉识别的 VLM 对其进行处理。
-
对于 Audio类型文件,需要配置支持语音转文字的模型,Parser 将提取 Audio 中的文字内容。用户可以在主页的“Model provider”页面,配置好支持该类型解析的模型厂商的 API Keys。再回到 Parser 节点,就能在下拉菜单中选择它了。这个“先配置、后选用”的逻辑同样适用于 PDF,Image 以及 Video。
-
对于 Video 类型文件,需要配置支持多模态识别的大模型,Parser 会调用大模型对视频进行综合解析,并以 text 格式输出。
-
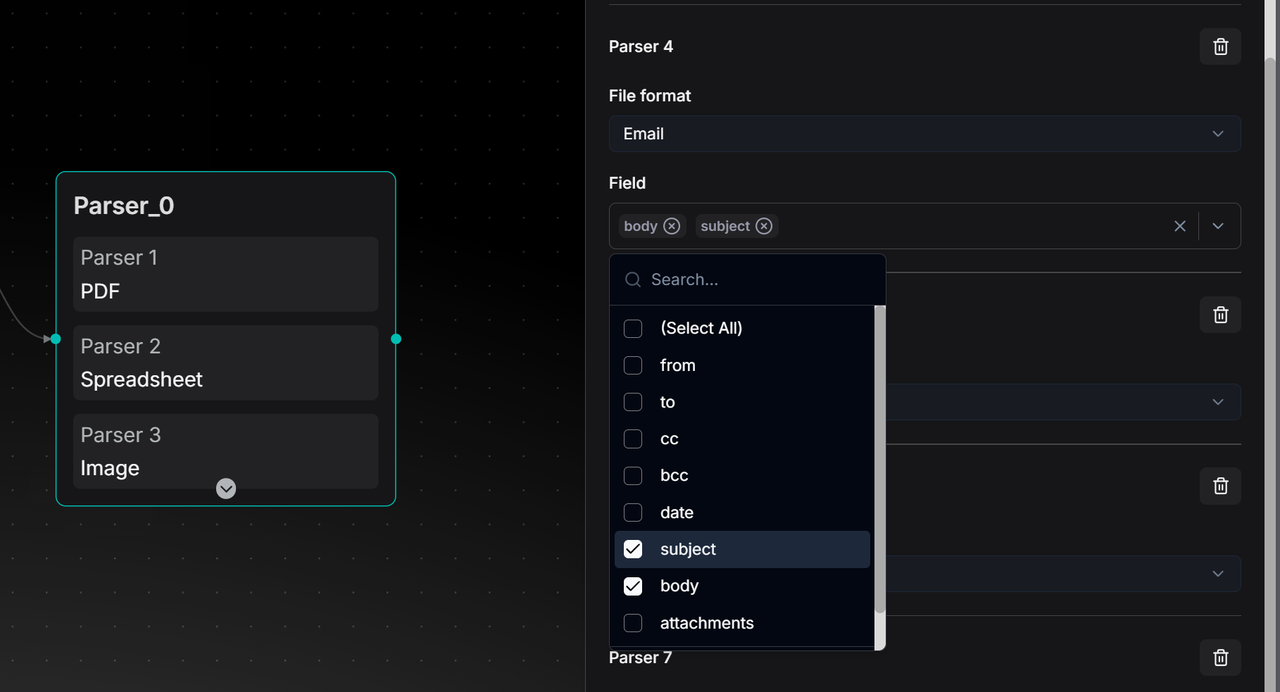
在解析 Email 文件时,RAGFlow 提供了 Field 选项,用户可以只勾选想要的字段,例如“subject”和“body”,Parser 会精确提取这些字段的文字内容。
-
Spreadsheet 解析器会把文件输出为 html 格式,完整保留其行列结构,确保表格数据在转换后依然清晰可读。
-
Word 和 PPT 类型的文件,均会被解析输出成 json 格式。对于 Word 会保留文档的原始层级,如标题、段落、列表、页眉页脚等信息;对于 PPT,会逐页提取内容,并能区分每页幻灯片的标题、正文和备注。
-
Text & Markup 类别则会自动剥离 HTML、MD (Markdown) 等文件中的格式标签,只输出最干净的text纯文本内容。
Chunker
Chunker 节点负责把上游节点输出的文档分割成 Chunk 切片。Chunk 是 RAG 技术引入的概念,它代表召回的单元。用户可以根据自己的需求选择是否增加 Chunker 节点,但通常建议使用它,这主要有两个原因:
-
如果以整个文档为单元进行召回,会导致在最后的生成阶段交给大模型的数据超出上下文窗口限制。
-
典型 RAG 是以向量搜索作为重要召回手段,但向量本身存在语义表征不够准确的问题:例如用户可以选择把一句话变成一条向量,也可以选择把整个文档变成一条向量,前者损失了全局语义信息,后者则损失了局部信息。因此选择适当的切片长度,使得用一个向量表示可以得到相对好的平衡,是必备的技术手段。
在实际工程系统中,如何决定 Chunk 的切分结果往往对 RAG 的召回质量产生重要影响:如果包含答案的内容被切到了不同 Chunk,而 Retrieval 阶段不能保证这些 Chunk 被全部召回,就会导致答案生成不准确产生幻觉。因此 Ingestion pipeline 引入 Chunker 节点,用户可以更加灵活地对文本进行切片。
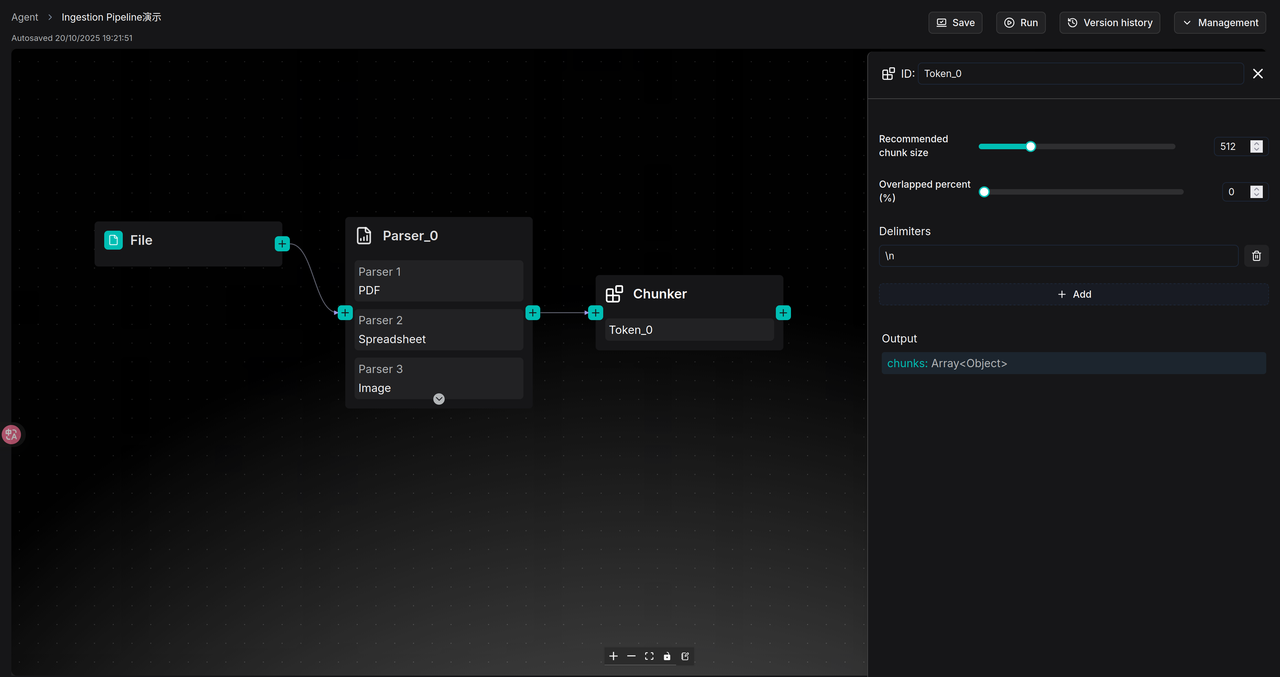
当前系统内置了两种切片方法,分别是根据文本的 Token 和 Title 进行切片。
按 Token 切片是最常见的方式。用户可以自定义每个切片的大小,默认设置是 512 个 Token,这是一个在检索效果和模型兼容性上都经过优化的平衡点。设置切片大小时需要权衡:若切片 Token 数依然过大,超出模型上限的部分仍会被丢弃;若设置过小,则可能导致原文中连贯的语义被过度切分,破坏上下文,影响检索效果。
为此 Chunker 算子提供了切片重叠功能,它允许上一个切片的末尾部分作为下一个切片的开头部分被复制,从而提升语义的连贯性,用户可以调高“Overlapped percent” 来提高切片之间的关联性。
同时,用户也可以通过定义“分隔符” (Separators) 进一步优化切片规则。系统默认使用 \n (换行符) 作为分隔符,这意味着切片器会优先尝试按照自然段落进行分割,而不是在句子中间粗暴地截断,如下图。
如果文档本身就具有清晰的章节结构,按 Token 切割文本就不是最优选择,这时可以选择 Chunker 的 Title 选项按文档标题切片,主要适合技术手册、学术论文、法律条款等这类布局的文档。我们可以在 Title 节点中为不同层级的标题自定义表达式。例如,可以设定一级标题 H1 的表达式为 ^#[^#],H2 为 ^##[^#]。系统将以此为依据,严格按照设定的文档章节脉络进行切片,确保每个切片都是一个结构完整的“章节”或“小节”。用户也可以在配置中自由增减标题的层级,以匹配文档的实际结构,如下图。
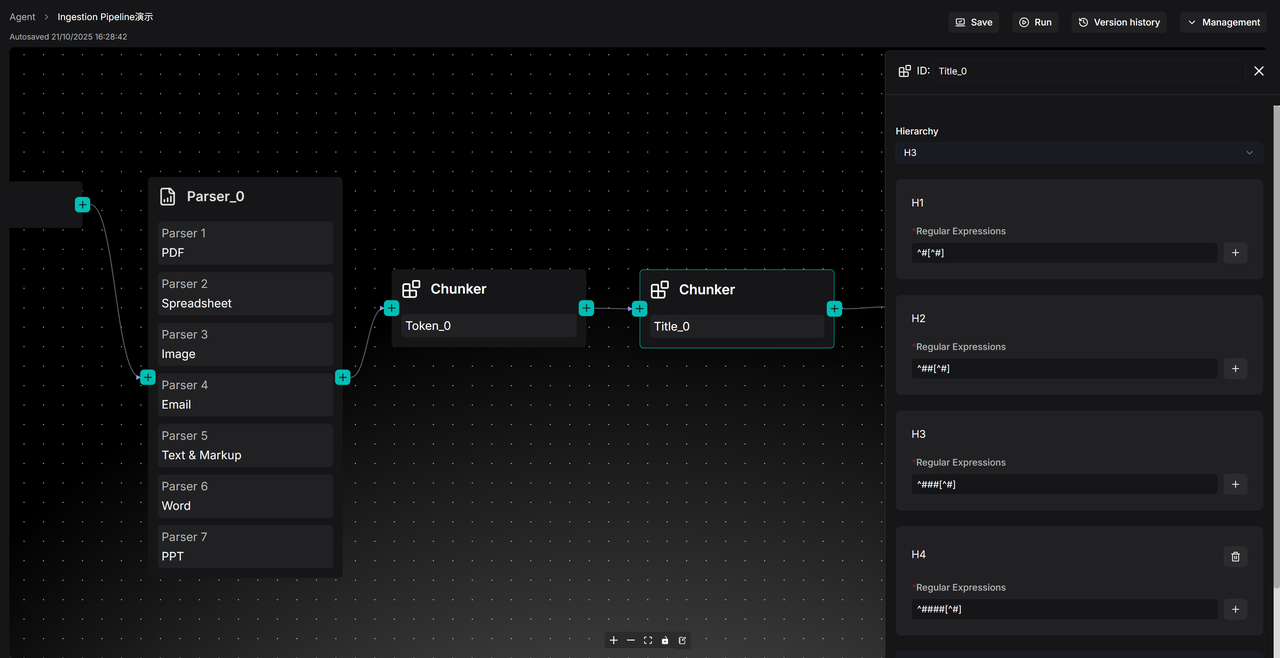
注意:在当前的 RAGFlow v0.21 版本中,如果同时编排 Chunker 的 Token 和 Title 选项,请保证 Title 节点接在 Token 节点之后,否则若 Titile 节点直接连接 Parser 节点,则 Email, Image, Spreadsheet, Text&Markup 类型文件会出现格式报错。这些限制将在后续版本里得到优化。
Transformer
Transformer 算子负责对文本内容做变换。单纯解决了文本解析的准确度,切片的准确度之后,并不能保障最终检索的准确度。这是因为用户的问题,和包含答案的文档之间,永远存在着所谓“语义鸿沟”。通过 Transformer 算子,用户可以使用大模型,对输入文档内容进行提取,从而解决“语义鸿沟”。
当前的 Transformer 算子支持摘要生成、关键词生成、问题生成和 Metadata 元数据生成等功能。 用户可以选择在 Pipeline 中编排该算子,来为原始数据补充这些内容,从而提升最终的检索准确度。与其他使用大模型的场景类似,Transformer 节点为大模型也设置了三种模式——Improvise 、Precise 和 Balance。
-
Improvise (即兴模式) 鼓励模型发挥更大的创造力和联想力,比较适合用来生成多样化的 Questions;
-
Precise (精确模式) 会严格限制模型,使其输出高度忠实于原文,适合用于生成 Summary (摘要) 或提取 Keywords (关键词) ;
-
Balance (平衡模式) 会兼顾二者,适用于大多数场景。
用户可以在这三种风格中选择一种,也可以通过自行调整 Temperature , Top P 等参数来实现更精细的控制。
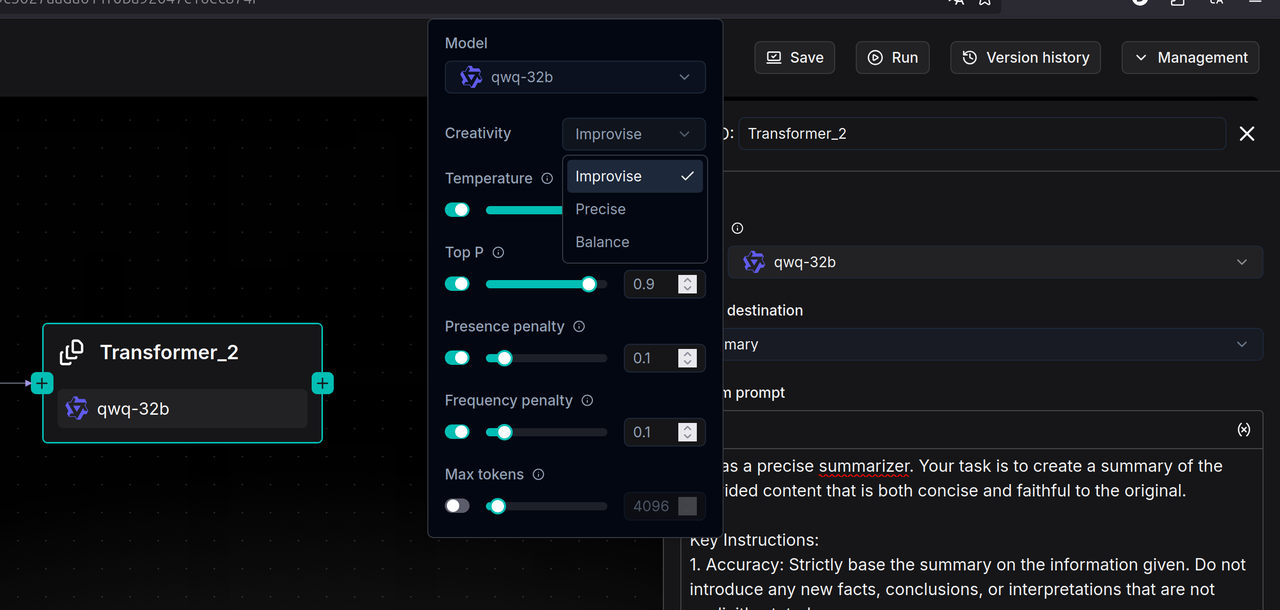
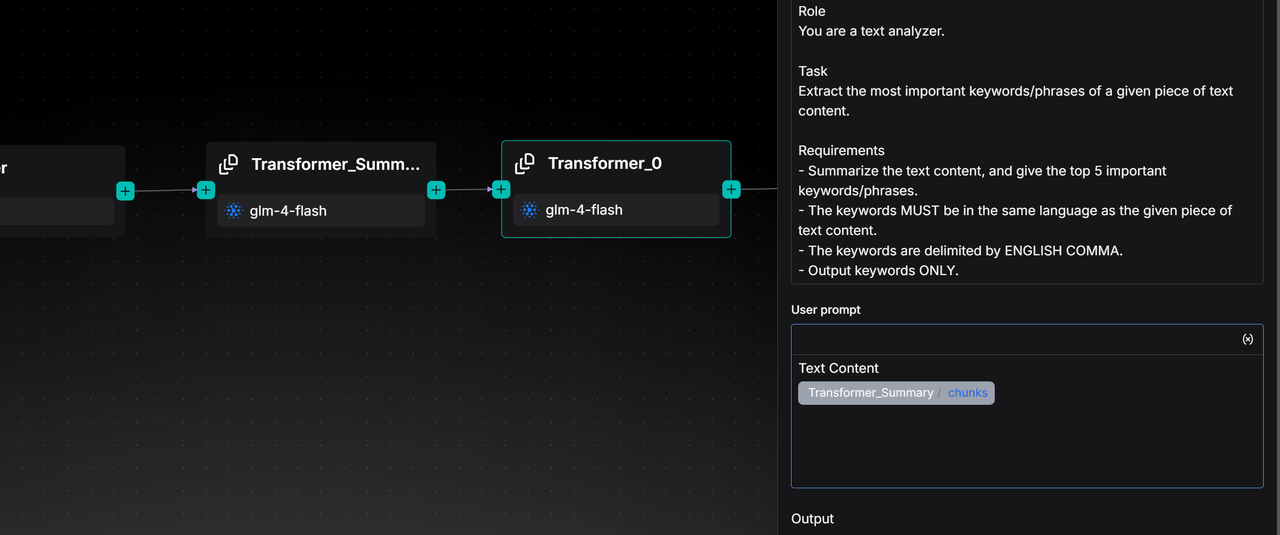
Transformer 节点可以生成四类内容:Summary、Keywords、Questions 和 Metadata。 RAGFlow 也把每一类内容的提示词开放出来,这也意味着用户可以通过修改系统提示词来对文本进行更丰富、更个性化的加工。
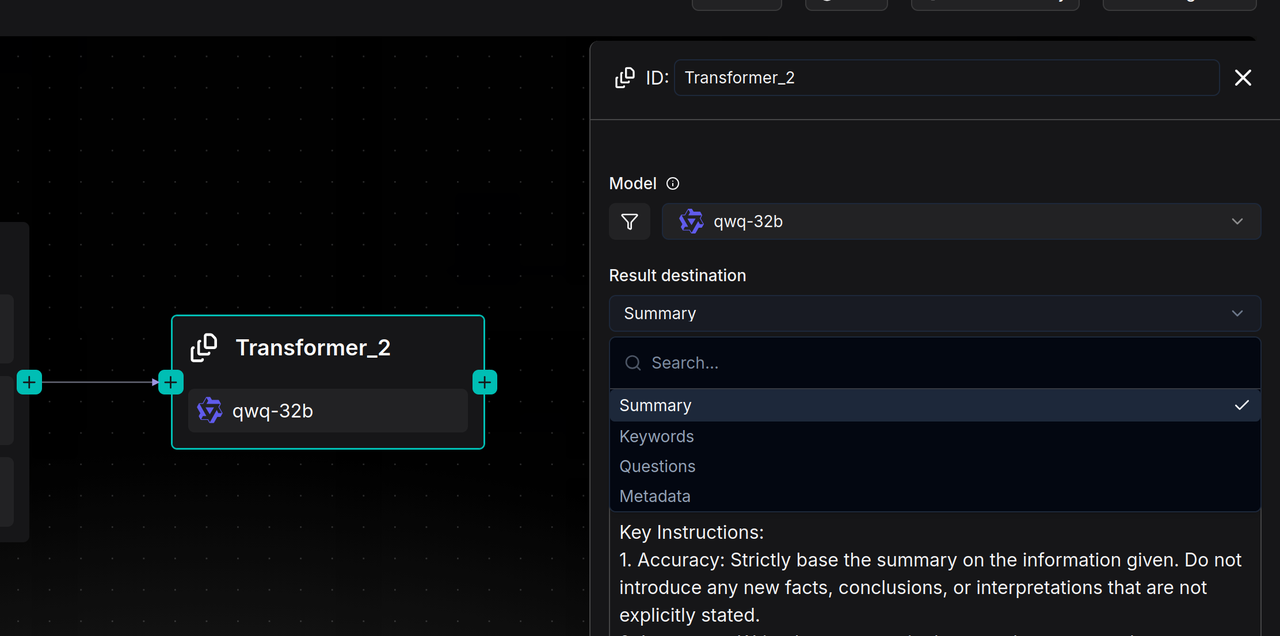
如果需要实现多种功能,例如同时总结内容和提取关键词,用户需要为每个功能单独配置一个 Transformer 节点,并在 Pipeline 中将它们串联起来。也就是说 Transformer 节点可以直接接在 Parser 之后,对整篇文档进行加工(例如生成全文摘要);也可以接在 Chunker 之后,对每一个文本分片进行处理(例如为每个 Chunk 生成问题); Transformer 节点还可以接在另一个 Transformer 节点之后,级联的完成复杂内容的提取和生成。
请注意:Transformer 节点不会自动获取其前继节点的内容。它实际要加工的信息来源,完全取决于在 User prompt (用户提示词) 中引用的变量。必须在 User prompt 中,通过输入 / 符号来手动选择并引用上游节点输出的变量。
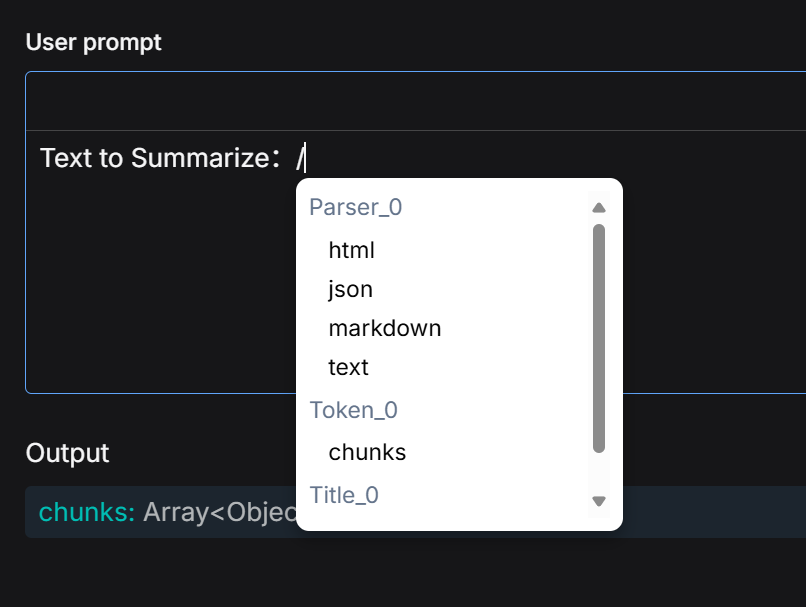
例如:在一个 Parser -> Chunker -> Transformer 的 Pipeline 中,尽管 Transformer 视觉上连接在 Chunker 之后,但如果在 User prompt 中引用的变量是 Parser 节点的输出,那么 Transformer 实际加工的仍然是整篇原文,而不是 Chunker 切割后的 chunks。
同理,当用户选择串联多个 Transformer 节点时(例如,第一个生成 Summary,第二个生成 Keywords),如果第二个 Transformer 引用的是第一个 Transformer 生成的 Summary 变量,那么它会把这段 Summary 作为“新的原文”来进行加工,而不是处理更上游的 Chunker 文本块。
Indexer
前面的Parser、Chunker 和 Transformer 节点处理了数据的流入、切割与优化,但 Pipeline 的最终执行单元是 Indexer 节点,它负责把处理完的数据写入到 Retrieval engine(RAGFlow 当前支持 Infinity,Elasticsearch 和 OpenSearch)。
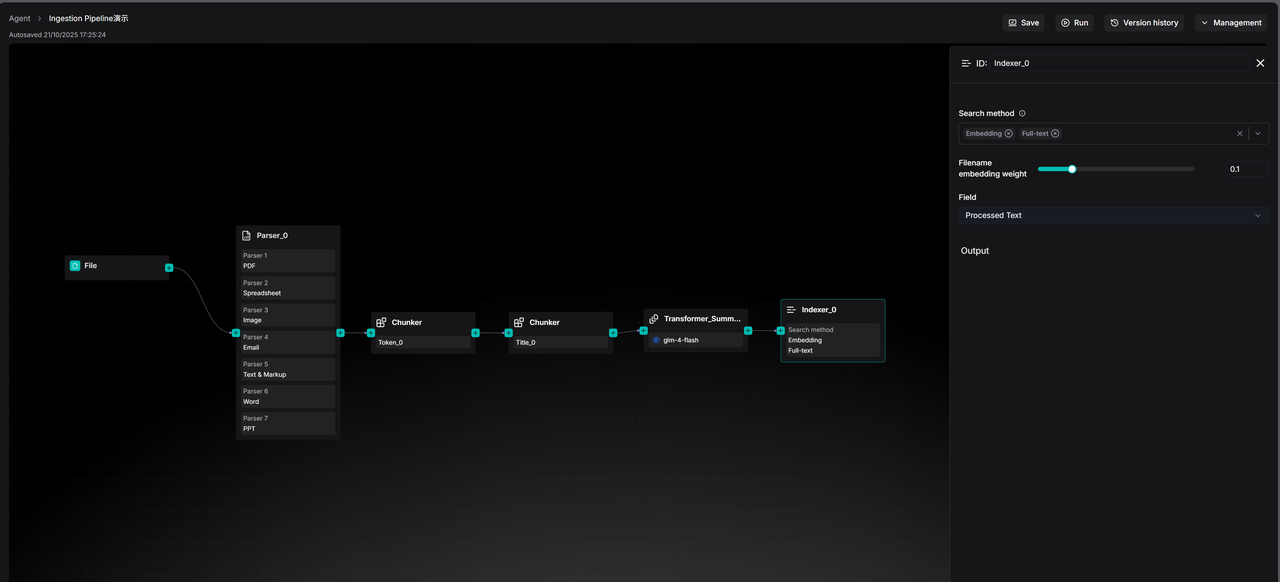
Retrieval engine 的核心能力是为数据建立各种索引从而提供搜索能力,包括向量索引,全文索引,以及未来的张量索引等能力。换句话,它是 RAG 这个术语当中 Retrieval 的最终体现。
由于不同类型索引有不同能力上的差异,因此 Indexer 同时提供创建不同索引的可选项。也就是 Indexer 节点中的 Search method 选项,它决定了用户数据可以被“如何找到”。
Full-text 就是传统的“关键词搜索”,它是精确召回的必备选项,例如搜索一个特定的产品编号、人名或代码。Embedding 则是现代 AI 驱动的“语义搜索”。用户可以用自然语言提问,系统能“理解”问题的含义并召回内容上最相关的文档块。同时启用这两者进行混合搜索是 RAGFlow 的默认选项,有效的多路召回,可以兼顾精确和语义,最大程度发现答案所在的文本区域片段。
注意:Indexer 节点内无需选择具体的 Embedding 模型,因为它会自动调用在创建知识库时设置的嵌入模型。另外,RAGFlow 中的 Chat, Search, Agent 功能都支持跨知识库检索,即一次提问可以同时在多个知识库中搜索答案。但要启用此功能,必须满足的条件是:所有被同时选中的知识库,都必须使用相同的 Embedding 模型。这是因为不同的嵌入模型会将相同的文本转换为完全不同且互不兼容的向量,导致无法跨库检索。
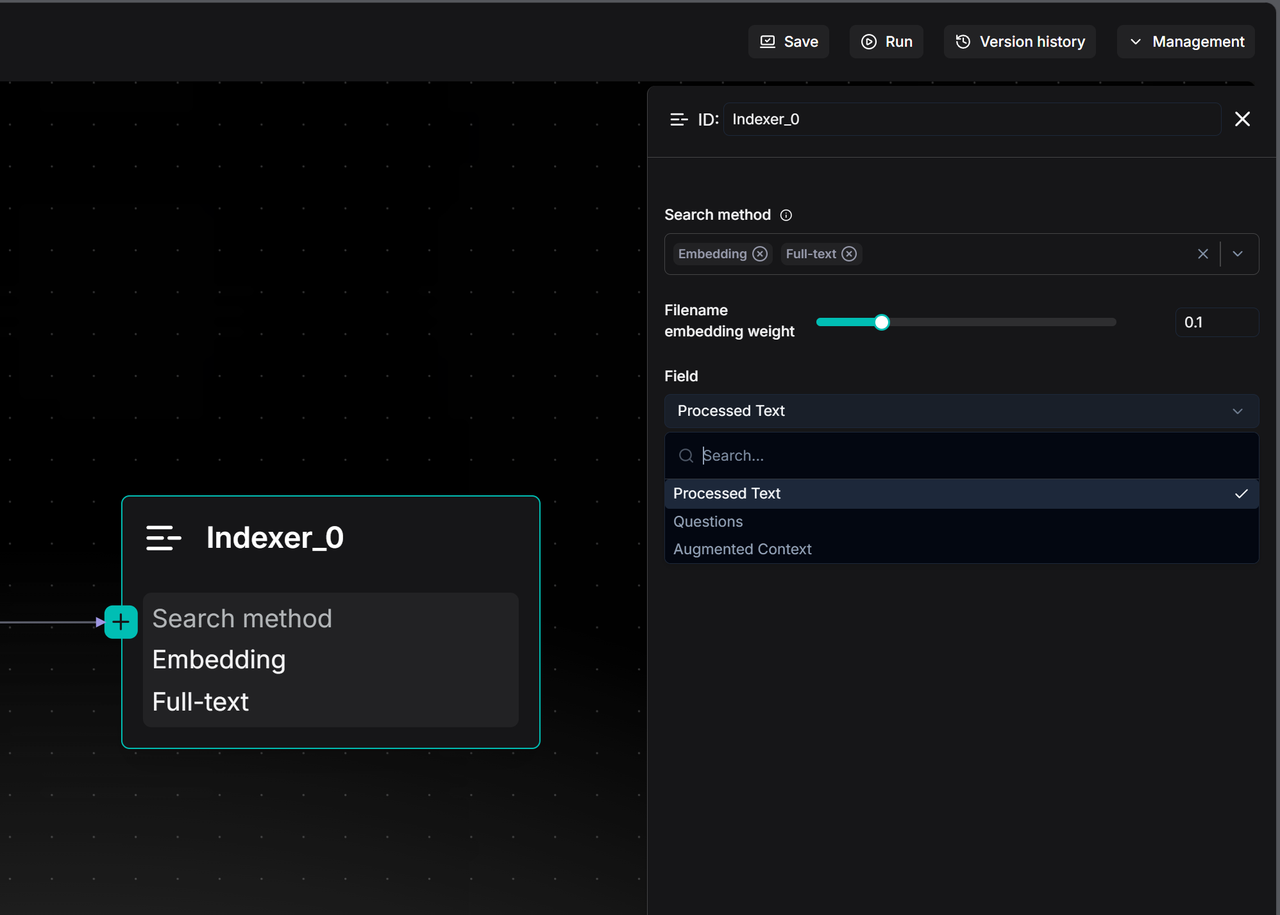
此外还可以通过 Filename embedding weight 和 Field 选项来实现更精细的检索设置。Filename embedding weight 是一个微调滑块,它允许用户将文档的“文件名”本身也作为一部分语义信息纳入考量,并为其分配一个特定的权重。
而 Field 选项,决定了用户具体需要索引什么内容和检索策略,目前提供了三种目的截然不同的策略选项:
-
Processed Text: 这是默认选项,也是最直观的。它意味着 Indexer 将索引被前面的节点加工过的文本块内容。
-
Questions : 如果在 Indexer 之前使用了 Transformer 节点来为每个文本块生成“它可能回答的问题”,就可以在这里选择索引这些 Questions。在很多场景下,用“用户的问题”去匹配“预生成的问题”,其相似度远高于用“问题”去匹配“答案”(即原始文本),这能有效提升检索的准确率。
-
Augmented Context : 也就是使用 Summary 替代原文进行检索。这适用于需要快速进行广义主题匹配,而不希望被原文细节干扰的场景。
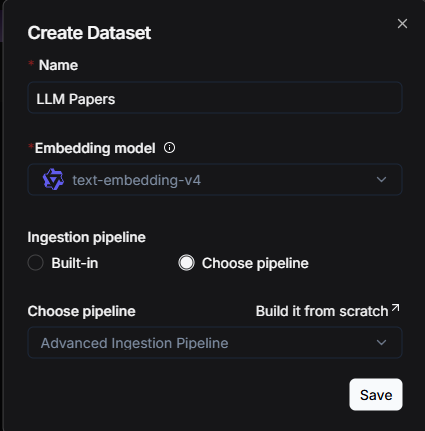
关联 Ingestion pipeline 到知识库
构建完成一个 Ingestion pipeline 之后,接下来要将其关联到对应的知识库。可在创建知识库页面的 “Ingestion pipeline”标签,找到并点击 “Choose pipeline” 选项。随后,从下拉菜单中选择已创建好的 Pipeline 进行关联。一经设定,该 Pipeline 将成为此知识库的默认文件解析流程。
对于已创建的知识库,用户可随时进入其 “Ingestion pipeline” 模块,重新调整和选择关联的解析流程。
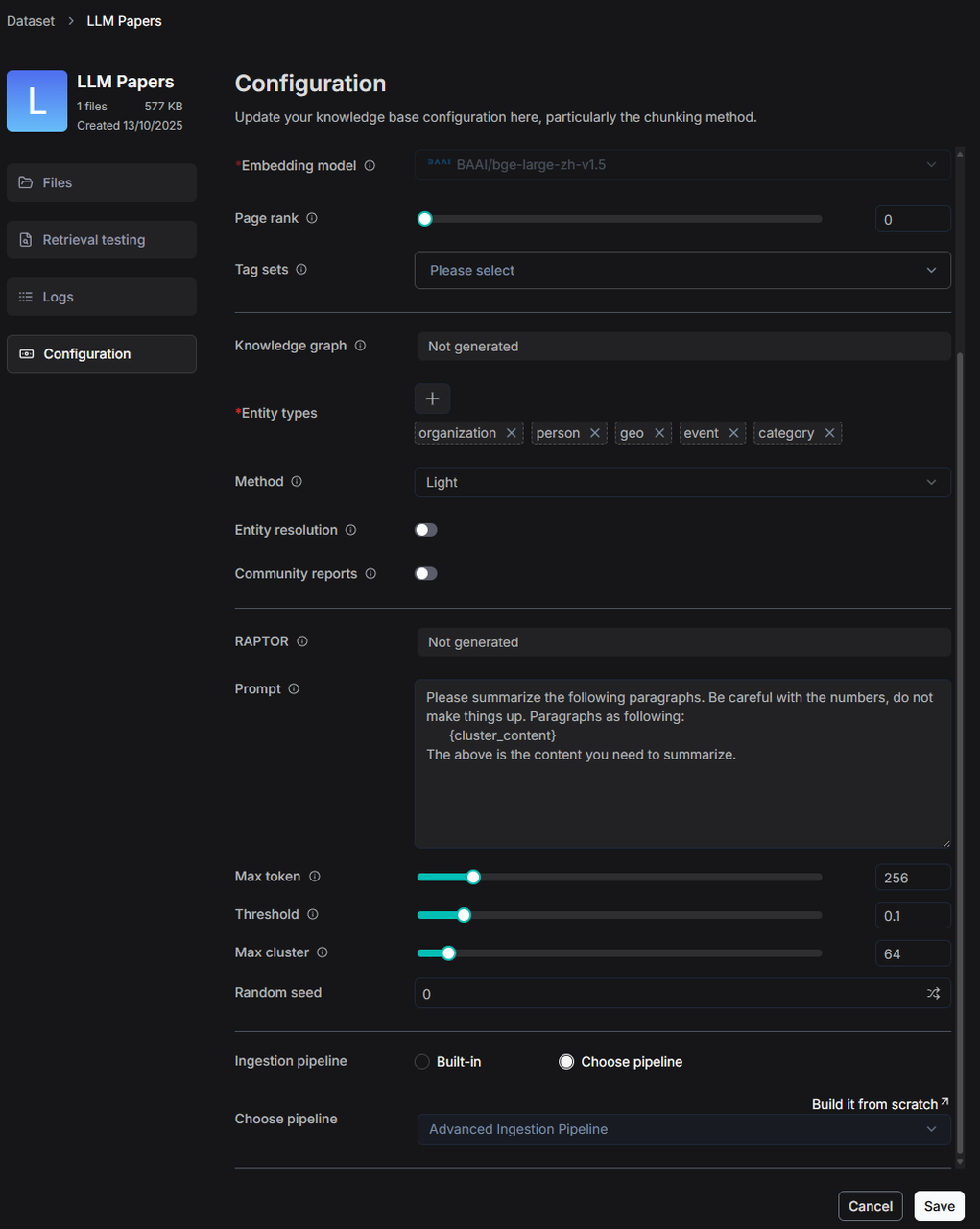
如果希望调整单个文件的 Ingestion pipeline,也可以通过点击 Parse 位置调整。
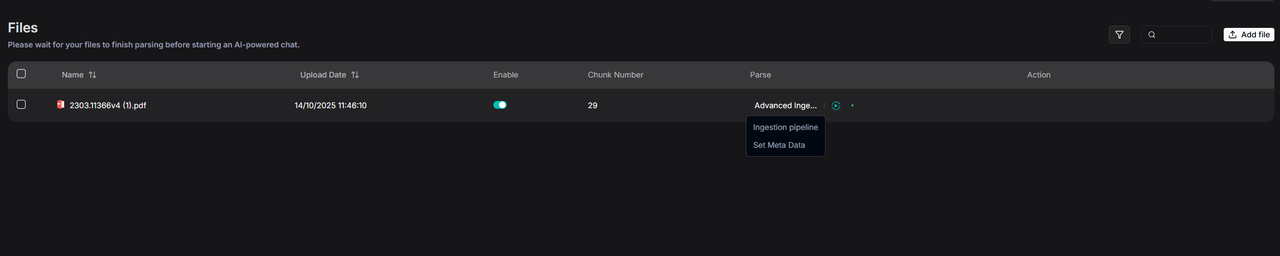
最终在弹窗里调整和保存更新。
日志
Ingestion Pipeline 的执行可能会耗时较长,因此可观测性是不可或缺的能力,为此 RAGFlow 为 Ingestion pipeline 提供了日志面板,用于记录每一次文件解析的全链路日志。对于通过 Ingestion Pipeline 解析的文件,用户可以深入查看其每个处理节点的运行详情。这为后续问题审计、流程调试与效果洞察提供了完整的数据支持。

下图是步骤日志的示例图。
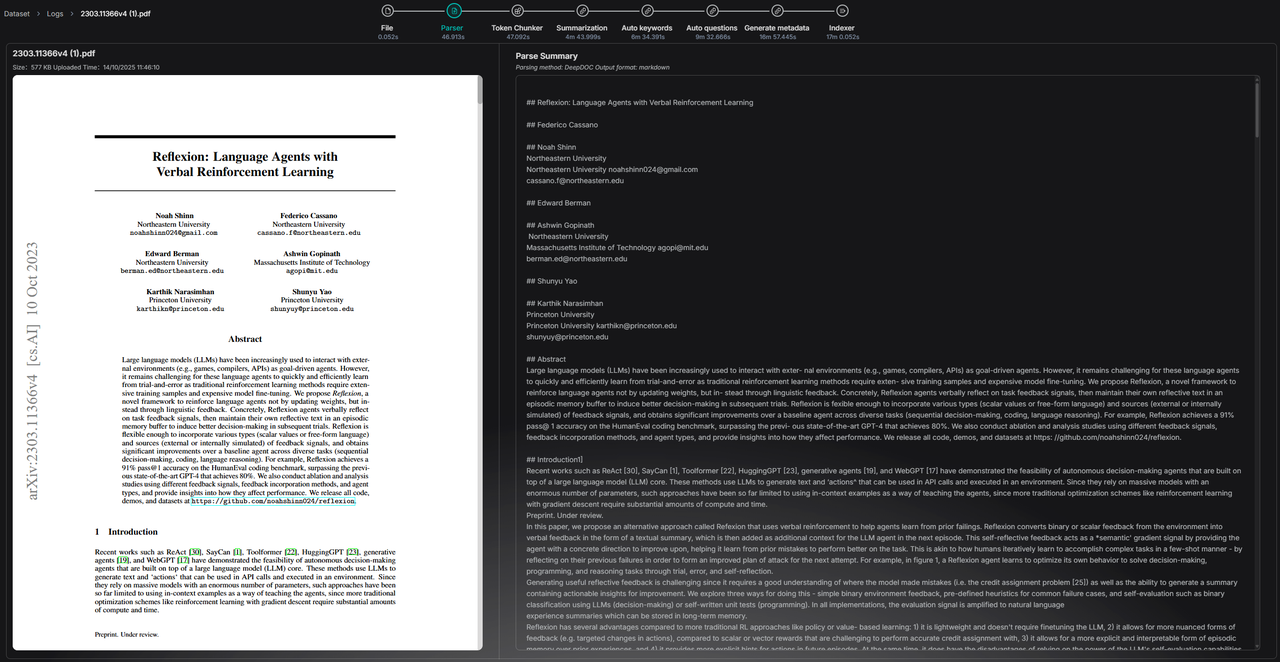
案例参考
创建 Pipeline 时,选择 “Chunk Summary” 模板作为构建基础,当然也可以选择其他模板作为后续构建的起点。
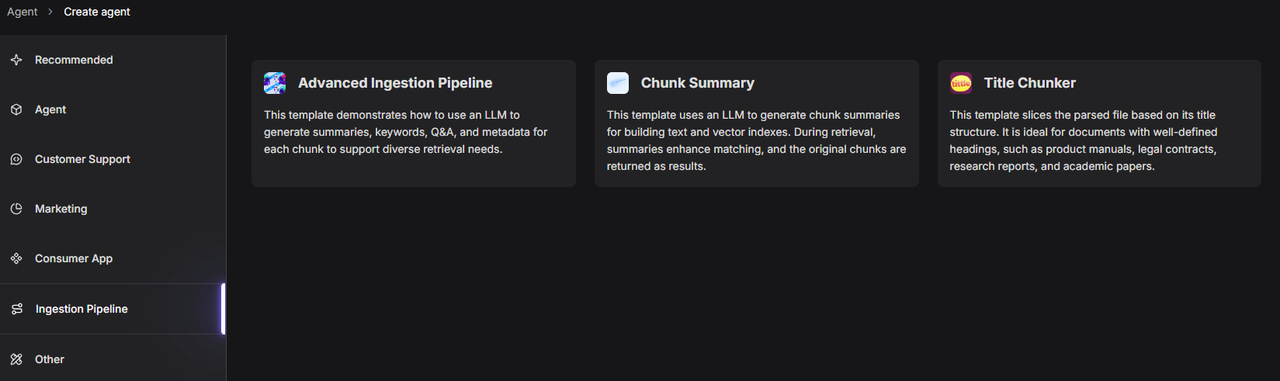
“Chunk Summary” 模板的编排设计如下:
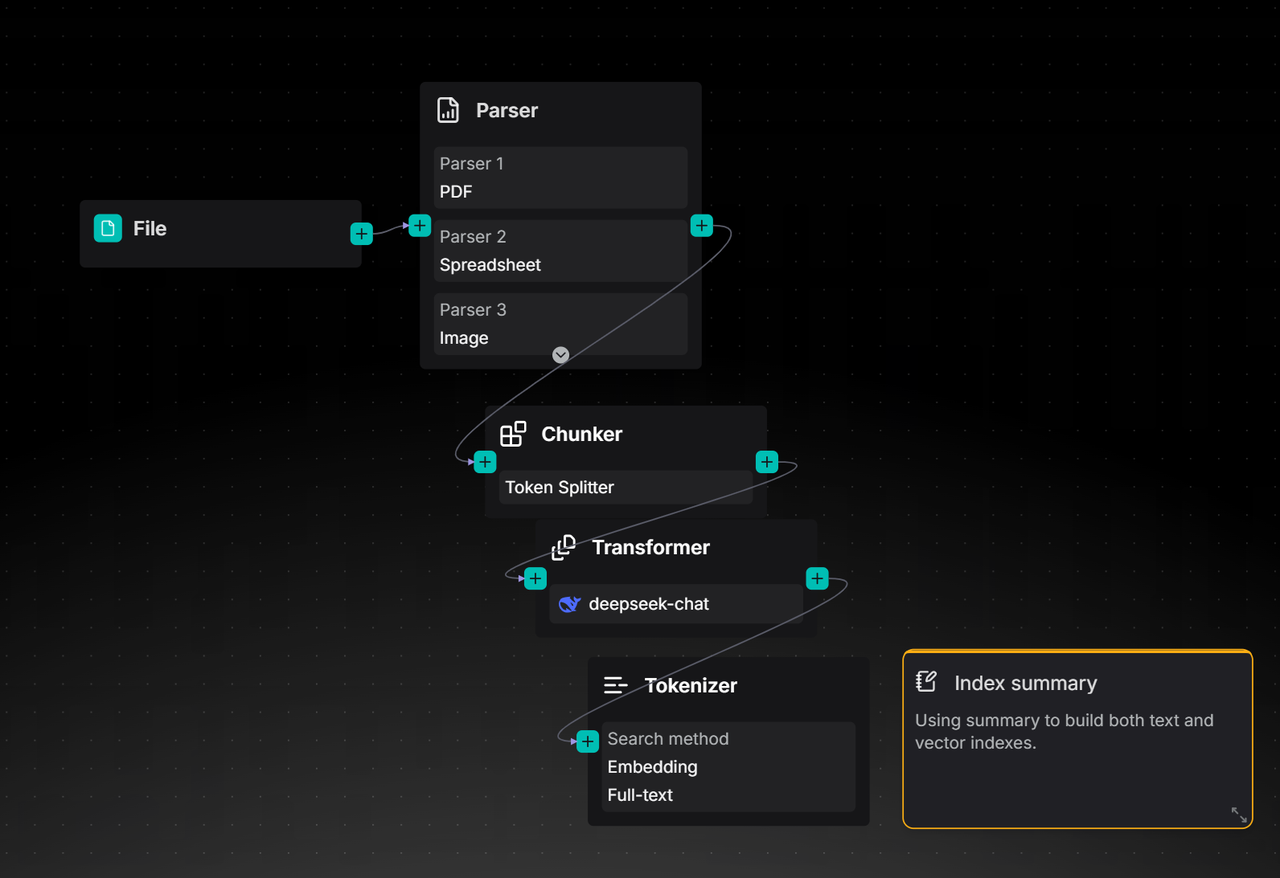
接下来,将 Transformer 节点的大模型切换至所需的模型,并将 “Result destination” 字段设置为 “Metadata” 。此配置意味着大模型对文本块的加工结果(如摘要)将直接存入文件的元数据中,为后续的精准检索与过滤提供能力支持。
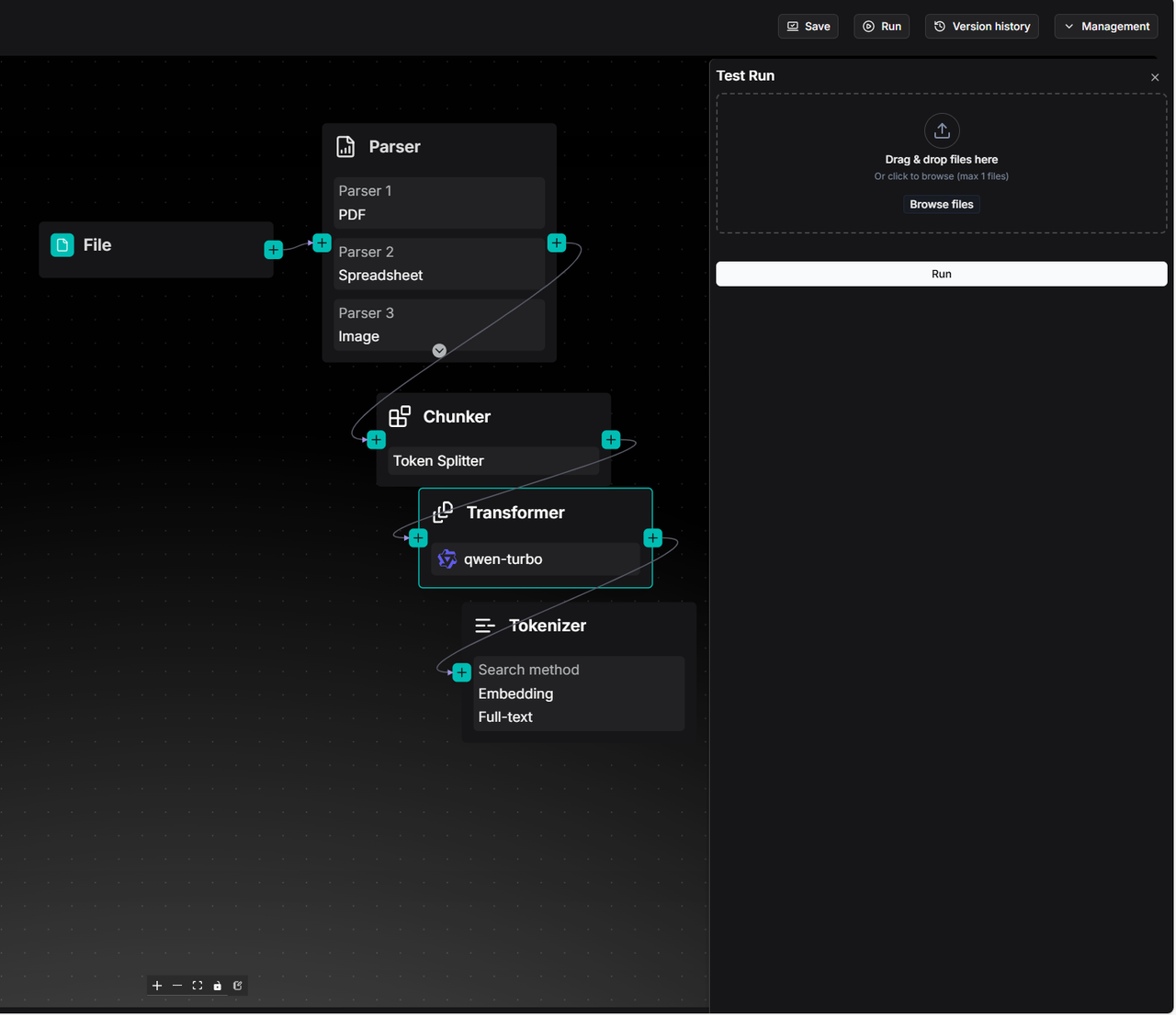
点击右上角的 Run,上传一个文件来测试 pipeline:
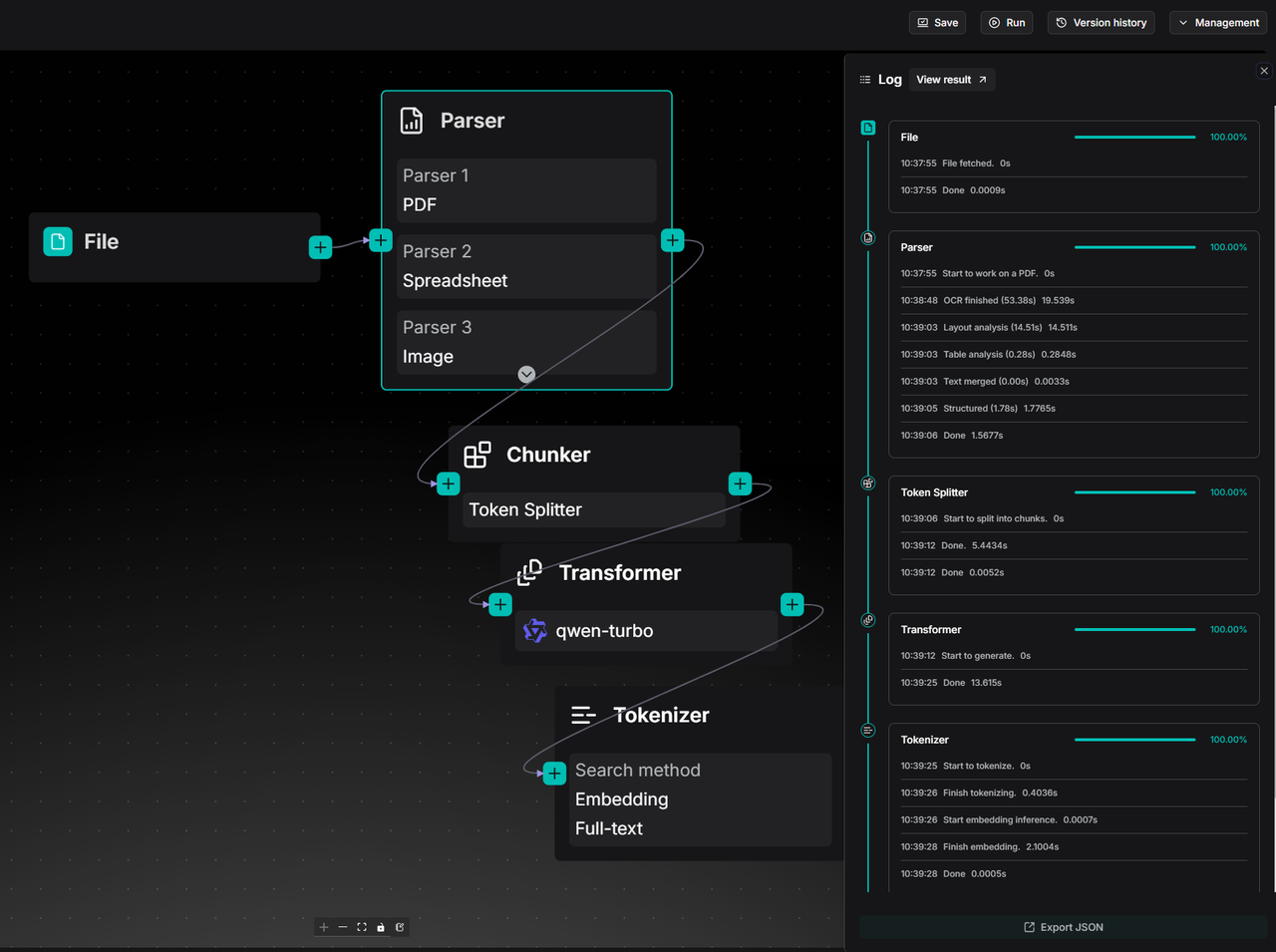
可以点击 View result 查看测试运行结果:
总结
以上内容完整介绍了当前 Ingestion pipeline 的使用方法与核心能力。面向未来,RAGFlow 在数据导入与解析清晰度方面还将持续演进,具体包括:
-
扩展数据源支持:除了本地文件上传,我们将陆续接入 S3、网盘、邮件、在线笔记等多种数据源,并通过自动与手动同步机制,实现数据向知识库的无缝导入,自动应用 Ingestion pipeline 完成文档解析。
-
增强解析能力:在 Parser 算子中集成更多文档解析模型,例如 Docling 等,覆盖不同垂直领域的解析需求,全面提升文档信息提取的质量与准确性。
-
开放切片自定义功能:除内置多种 Chunker 类型外,我们将逐步开放底层切片能力,支持用户编写自定义切片逻辑,实现更灵活、可控的文本组织方式。
-
强化语义增强的扩展性:在现有摘要、关键词与问题生成能力基础上,进一步支持以可编排的方式自定义语义增强策略,为用户提供更多优化检索与排序的技术手段。
通过上述增强,RAGFlow 将持续提升检索精度,成为为大模型提供高质量上下文的有力支撑。
最后,感谢您的关注与支持,欢迎在 GitHub 上为 RAGFlow 点亮 Star,与我们一同见证大模型技术的持续进化!
GitHub: https://github.com/infiniflow/ragflow