MySQL 体系结构、SQL 执行与设计范式
文章目录
- 一、数据库基础概念
- 1.1 数据库定义
- 1.2 OLTP 与 OLAP
- OLTP:联机事务处理
- OLAP:联机分析处理
- 1.3 数据库术语
- 1.4 SQL 与分类
- 二、MySQL 体系结构
- 2.1 MySQL Connectors
- 2.2 MySQL shell
- 2.3 服务层 (Server 层)
- 2.4 存储引擎层(Engine 层)
- 2.5 物理文件结构
- 三、MySQL 怎么执行一条 select 语句?
- 3.1 连接器
- 3.2 查询缓存
- 3.3 分析器
- 3.4 优化器
- 3.5 执行器
- 四、数据库设计范式
- 4.1 第一范式(1NF):列不可分
- 4.2 第二范式(2NF):依赖主键(联合索引),无部分依赖
- 4.3 第三范式(3NF):2NF基础上直接依赖,无传递依赖
- 4.4 反范式
一、数据库基础概念
1.1 数据库定义
数据库(Database)是按照特定的数据结构来组织、存储和管理数据的仓库。它是一个长期存储在计算机中的、有组织的、可共享的大量数据集合,能够通过统一的方式实现数据的存取与管理。
简单来说,数据库的本质是——数据的结构化存储 + 有序的访问管理机制。
与普通文件系统不同,数据库在逻辑层面上管理数据的完整性、一致性与安全性。
1.2 OLTP 与 OLAP
OLTP:联机事务处理
OLTP 主要对数据库进行增删改查操作,用于记录某类业务事件的发生。数据会以增删改的方式在数据库中进行更新处理,要求实时性高、稳定性强,确保数据及时更新成功,通常采用行式存储。
这类系统强调:
- 实时性:操作必须即时生效;
- 一致性:保证事务 ACID;
- 高并发:支持大量用户并行访问;
- 行式存储:适合频繁更新的业务场景。
常见应用:银行转账、订单系统、库存管理等。
OLAP:联机分析处理
当数据积累到一定程度,需要对过去发生的事情做总结分析时,就会进行 OLAP。它会把过去一段时间内产生的数据拿出来统计分析,为公司决策提供支持,主要对数据库进行查询操作,一般采用列式存储。
这类系统强调:
- 读多写少:主要执行复杂的 SELECT;
- 聚合与统计能力强;
- 列式存储:压缩率高、查询性能好;
- 适合数据仓库场景。
常见应用:报表分析、销售趋势分析、BI 系统等。
1.3 数据库术语
- 数据库(Database):数据库是一些关联表的集合;
- 数据表(Table):数据的二维结构,由行和列组成。
- 列(Column):一列包含相同类型的数据;
- 行(Row):或者称为记录,是一组相关的数据;
- 主键(Primary Key):唯一标识一条记录,不能为空且唯一,一个数据表只能包含一个主键;
- 外键(Foreign Key):外键用来关联两个表,保证参照完整性。MyISAM 存储引擎本身并不支持外键,只起到注释作用;而 InnoDB 完整支持外键;
- 复合键(Composite Key):或称组合键,由多个字段共同组成的主键。
- 索引(Index):用于快速访问数据表的数据,是对表中的一列或者多列的值进行排序的一种结构。
1.4 SQL 与分类
SQL(Structured Query Language)是数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统,是关系数据库系统的标准语言。它可以完成数据定义、数据查询、数据操作、访问控制及事务控制等功能。
关系型数据库包括:MySQL、PostgreSQL、Oracle、SQL Server、Sybase、MS Access 等。
① DQL 数据查询语言(Data Query Language)
select:从一个或者多个表中检索特定的记录。
② DML 数据操作语言(Data Manipulation Language)
insert:插入记录;update:更新记录;delete:删除记录。
③ DDL 数据定义语言(Data Definition Language)
create:创建一个新的表、表的视图或者在数据库中的对象;alter:修改现有的数据库对象(修改表结构),例如修改表的属性或者字段;drop:删除表、数据库对象或者视图;truncate:截断表,清空表内容。
④ DCL 数据控制语言(Data Control Language)
grant:授予用户权限;revoke:收回用户权限。
⑤ TCL 事务控制语言(Transaction Control Language)
commit:事务提交;rollback:事务回滚。
二、MySQL 体系结构
MySQL 由连接池组件、管理服务和工具组件、SQL 接口组件、查询分析器组件、优化器组件、缓冲组件、插件式存储引擎、物理文件等部分组成。
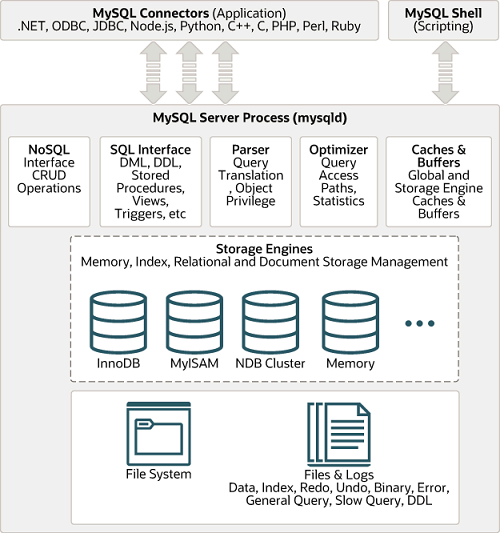
2.1 MySQL Connectors
MySQL 的驱动,服务器需要一个模块实现 MySQL 的协议,并且要有网络功能,才能与 MySQL 建立连接、发送对应语句。不同语言有不同驱动,具备网络功能,可接收和发送数据,实现 MySQL 协议。
- MySQL 提供给不同语言的连接驱动,支持
.NET、ODBC、JDBC、Node.js、Python、C++、PHP、Perl、Ruby等。 - 负责建立连接、发送 SQL 语句、接收返回结果。
- 底层实现了 MySQL 通信协议,用于和服务端交互。
2.2 MySQL shell
控制台,可与 MySQL 建立连接并发送对应的指令。
- 是一个可直接连接 MySQL 的命令行工具,用于执行 SQL、管理数据库实例、运行脚本等。
- 相当于开发者与数据库交互的“控制台界面”。
2.3 服务层 (Server 层)
Server 层是 MySQL 的核心逻辑层,负责 SQL 语句的接收、解析、优化、执行计划制定以及结果返回。
主要组件包括:
- 连接器:管理客户端连接;
- SQL 接口:将 SQL 语句解析生成相应对象;
- 分析器:词法、语法解析;
- 优化器:选择最优执行计划;
- 执行器:根据计划执行 SQL;
- 查询缓存:MySQL 8.0 之前,执行 SELECT 时首先会检查缓存
- 管理服务与工具组件:如备份、复制、集群。
2.4 存储引擎层(Engine 层)
负责数据的实际存储与读写,如 InnoDB、MyISAM、Memory 等。
存储引擎通过统一的接口暴露给 Server 层,具体负责索引管理、事务处理、页缓存(Buffer Pool)等。InnoDB 是默认的可插拔存储引擎。
| 引擎 | 存储限制 | 事务 | 索引 | 锁的粒度 | 数据压缩 | 外键 | 特点 | 适用场景 |
|---|---|---|---|---|---|---|---|---|
| InnoDB | 64TB | 支持 | 支持 | 行锁 | - | 支持 | 事务安全(ACID)、支持行级锁、崩溃恢复 | 默认引擎,OLTP 系统 |
| MyISAM | 256TB | - | 支持 | 表锁 | 支持 | - | 无事务支持、表级锁、读性能好 | 读多写少的系统 |
| Memory | 有(受内存大小限制) | - | 支持 | 表锁 | - | - | 数据存储在内存中,访问速度极快 | 临时数据、高速缓存 |
| NDB Cluster | 无特定单节点存储限制(分布式扩展) | 支持 | 支持 | 行锁 | - | 支持 | 分布式存储引擎,支持事务、行级锁等 | MySQL 集群环境 |
| archive | 无 | - | - | 行锁 | 支持 | - | 只支持插入和查询,数据压缩比高 | 归档类、历史数据存储 |
2.5 物理文件结构
- 数据文件(.ibd / .frm)
- 日志文件(redo / undo / binlog)
- 错误日志、慢查询日志、通用查询日志等。
三、MySQL 怎么执行一条 select 语句?
当客户端发送一条 SELECT 查询语句时,MySQL 会依次经历以下五个主要阶段:
- 连接器建立与数据库的连接,并完成用户身份及权限的校验;
- 查询查询缓存看是否命中,命中则直接返回,否则继续执行(8.0 以后舍弃了查询缓存);
- 通过分析器,进行词法句法分析,生成对应的语法树;
- 优化器制定多条执行计划,并选择查询成本最小的计划;
- 执行器根据执行计划,从存储引擎获取数据,并返回给客户端。
3.1 连接器
MySQL 命令处理是多线程并发处理的。主线程负责接收客户端连接,然后为每个客户端的文件描述符(fd)分配一个连接线程,由该连接线程负责处理该客户端的 SQL 命令。
连接器的主要作用是:
- 负责客户端连接请求的接收;
- 校验用户名和密码;
- 分配连接线程并管理连接池;
- 管理用户权限信息。
连接器采用 I/O 多路复用(select/poll/epoll) 的方式监听连接请求。
主线程负责接收连接请求,并为每个客户端分配一个独立线程,用于后续 SQL 处理。
连接建立完成后,线程进入 handle_connection() 主循环,使用 阻塞式 I/O 等待客户端指令。当客户端发送 SQL 命令时,该线程负责完整的 SQL 解析、执行、结果返回。
3.2 查询缓存
在 MySQL 8.0 之前,执行 SELECT 时首先会检查缓存。
缓存以 key-value 形式存储:
- key:SQL 语句文本 + 用户上下文;
- value:查询结果集。
若命中缓存,直接返回结果;否则继续进入分析阶段。
由于缓存粒度过细且频繁失效(数据一更新缓存就作废),在 MySQL 8.0 后该机制被彻底移除。
3.3 分析器
分析器分为两个阶段:
- 词法分析:识别 SQL 中的关键字、表名、字段名;
- 语法分析:根据 SQL 语法规则生成语法树(Parse Tree)。
这一步会检测 SQL 语句是否合法,例如关键字错误、表不存在、字段名拼写错误等。
3.4 优化器
当存在多种执行方式时(如多索引、join 顺序不同),优化器会评估每种方案的代价,并选择成本最小的执行计划。
主要优化内容包括:
- 索引选择;
- 表连接顺序(Join Order);
- 使用全表扫描还是索引扫描;
- 子查询、视图的展开与改写;
- 常量折叠与谓词下推。
最终输出的执行计划可以通过EXPLAIN命令查看。
3.5 执行器
执行器根据优化器的执行计划,真正去执行 SQL 操作。
具体流程如下:
- 调用存储引擎 API;
- 从表中按索引或全表扫描读取数据;
- 将结果逐步返回给客户端。
在执行过程中,执行器还会检查访问权限(如 SELECT 权限),并负责组装结果集。
四、数据库设计范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则,在关系型数据库中这种规则称为范式,是符合某一种设计要求的总结。设计目标是让每个字段只表达一层含义、依赖清晰、避免更新异常。
三范式之间的递进关系: 1NF → 2NF → 3NF 。每一层都在解决上一层的特定问题。
4.1 第一范式(1NF):列不可分
每一列必须是不可再分的原子值。
不符合 1NF 的表(存在可拆分的字段):
| 客户ID | 客户名称 | 联系地址 | 联系电话 |
|---|---|---|---|
| 101 | 张三 | 广东省深圳市南山区科技园路88号 | 13800001111 |
| 102 | 李四 | 北京市海淀区中关村大街1号 | 13900002222 |
| “联系地址”字段包含“省份、城市、详细地址”等可拆分信息,不符合原子性要求。 |
符合 1NF 的表:
| 客户ID | 客户名称 | 省份 | 城市 | 详细地址 | 联系电话 |
|---|---|---|---|---|---|
| 101 | 张三 | 广东省 | 深圳市 | 南山区科技园路88号 | 13800001111 |
| 102 | 李四 | 北京市 | 海淀区 | 中关村大街1号 | 13900002222 |
| 将“联系地址”拆分为“省份、城市、详细地址”,每列均为不可再分的原子值,满足 1NF。 |
4.2 第二范式(2NF):依赖主键(联合索引),无部分依赖
在满足 1NF 的基础上,非主键列必须完全依赖主键,不能存在部分依赖。
不符合 2NF 的表(存在部分依赖,主键为“订单编号+商品编号”):
| 订单编号 | 商品编号 | 订单日期 | 商品名称 | 购买数量 | 客户名称 |
|---|---|---|---|---|---|
| OD001 | P001 | 2023-10-01 | 笔记本电脑 | 2 | 甲公司 |
| OD001 | P002 | 2023-10-01 | 鼠标 | 5 | 甲公司 |
| OD002 | P001 | 2023-10-02 | 笔记本电脑 | 1 | 乙公司 |
问题:
“订单日期、客户名称”仅依赖“订单编号”(部分依赖主键),不依赖“商品编号”;
“商品名称”仅依赖“商品编号”(部分依赖主键),不依赖“订单编号”;
不符合“非主键列完全依赖于整个联合主键”的要求。
符合 2NF 的表(拆分部分依赖字段):
① 订单表(主键:订单编号):存储仅依赖订单编号的信息
| 订单编号 | 订单日期 | 客户名称 |
|---|---|---|
| OD001 | 2023-10-01 | 甲公司 |
| OD002 | 2023-10-02 | 乙公司 |
② 商品表(主键:商品编号):存储仅依赖商品编号的信息
| 商品编号 | 商品名称 |
|---|---|
| P001 | 笔记本电脑 |
| P002 | 鼠标 |
③ 订单商品关联表(主键:订单编号+商品编号):存储依赖整个联合主键的信息
| 订单编号 | 商品编号 | 购买数量 |
|---|---|---|
| OD001 | P001 | 2 |
| OD001 | P002 | 5 |
| OD002 | P001 | 1 |
拆分后,每个表的非主键列均完全依赖于自身表的主键(无部分依赖),满足 2NF。
4.3 第三范式(3NF):2NF基础上直接依赖,无传递依赖
在满足 2NF 的基础上,非主键列只能依赖于主键,不能有传递依赖。
不符合 3NF 的表(存在传递依赖,主键:订单编号):
| 订单编号 | 客户ID | 客户名称 | 所属地区 | 地区负责人 |
|---|---|---|---|---|
| OD001 | 101 | 甲公司 | 华东区 | 王经理 |
| OD002 | 102 | 乙公司 | 华北区 | 李经理 |
| OD003 | 101 | 甲公司 | 华东区 | 王经理 |
问题:
“客户名称”依赖“客户ID”,“客户ID”依赖“订单编号”(传递依赖:客户名称 → 客户ID → 订单编号);
“所属地区、地区负责人”依赖“客户ID”(而非直接依赖订单编号),同样存在传递依赖;
不符合“非主键列仅直接依赖于主键”的要求。
符合 3NF 的表(消除传递依赖):
① 订单表(主键:订单编号):仅存储直接依赖订单编号的信息
| 订单编号 | 客户ID |
|---|---|
| OD001 | 101 |
| OD002 | 102 |
| OD003 | 101 |
② 客户表(主键:客户ID):存储依赖客户ID的信息
| 客户ID | 客户名称 | 所属地区 |
|---|---|---|
| 101 | 甲公司 | 华东区 |
| 102 | 乙公司 | 华北区 |
③ 地区表(主键:所属地区):存储依赖地区的信息
| 所属地区 | 地区负责人 |
|---|---|
| 华东区 | 王经理 |
| 华北区 | 李经理 |
说明:拆分后,所有非主键列均仅直接依赖于所在表的主键(无传递依赖),同时减少了数据冗余(如“客户名称、地区负责人”无需在订单表中重复存储),满足 3NF。
4.4 反范式
范式虽能避免数据冗余、减少数据库空间、减小维护数据完整性的麻烦,但采用数据库范式化设计,可能导致数据库业务涉及的表变多,进而造成更多的联表查询,使整个系统的性能降低。因此基于性能考虑,可能需要进行反范式设计,允许一定的冗余存储,以此提升查询效率。
过度范式化可能导致:
- 表数量增多;
- 查询需要频繁多表 join;
- 查询性能下降。
反范式设计允许适度冗余,以性能优先。
常见做法:
- 将常用查询字段冗余存储;
- 增加汇总表;
- 用触发器或定时任务保持数据一致。