C语言进阶:(一)深度剖析函数栈帧:从创建到销毁
目录
前言
一、基础概念铺垫:搞懂栈与函数栈帧
1.1 什么是栈?
1.2 什么是函数栈帧?
1.3 理解函数栈帧的核心价值
二、寄存器与汇编指令
2.1 关键寄存器说明
2.2 核心汇编指令说明
三、实战环境配置:让汇编代码更 “纯净”
3.1 关闭 “仅我的代码调试”
3.2 关闭优化选项
3.3 启用反汇编查看
四、函数栈帧的完整生命周期:从创建到销毁
4.1 示例代码
4.2 函数调用堆栈分析
4.3 main 函数栈帧的创建
4.3.1 栈帧创建的核心步骤总结
4.3.2 为什么未初始化的局部变量是随机值?
4.4 main 函数中局部变量的创建与初始化
关键结论:局部变量的存储本质
4.5 函数调用:参数传递与 Add 函数栈帧创建
4.5.1 参数传递的汇编实现
4.5.2 关键问题:参数传递的顺序是怎样的?
4.5.3 call 指令的核心作用
4.5.4 Add 函数栈帧的创建
4.5.5 形参 x 和 y 的存储位置
4.6 Add 函数的执行与返回值传递
关键结论:返回值的传递方式
4.7 Add 函数栈帧的销毁
栈帧销毁的核心目的
4.8 main 函数接收返回值与后续执行
关键步骤说明
五、常见问题分析
5.1 局部变量是如何创建的?
5.2 为什么未初始化的局部变量值是随机的?
5.3 函数参数的传递顺序是怎样的?
5.4 形参和实参的关系是什么?
5.5 函数返回值是如何带回的?
5.6 数组越界为什么会导致程序崩溃?
总结
前言
在 C 语言编程中,我们每天都在与函数打交道 —— 将复杂功能拆解为独立函数、通过函数调用实现逻辑复用、依赖函数返回值传递计算结果。但你是否曾深入思考过:函数调用时参数是如何传递的?局部变量为何不初始化会是随机值?函数返回值是通过什么方式带回主调函数的?这些问题的答案,都隐藏在 “函数栈帧” 这一核心概念中。
函数栈帧是理解 C 语言底层执行机制的关键,它不仅能解答上述疑问,更能帮助我们排查数组越界、野指针等底层 bug。本文将基于 VS2019 编译器,从栈的基础概念出发,结合汇编指令与实战代码,一步步拆解函数栈帧的创建、函数调用、参数传递、返回值带回及栈帧销毁的完整过程,带你看透 C 语言函数执行的底层逻辑。下面就让我们正式开始吧!
一、基础概念铺垫:搞懂栈与函数栈帧
在深入分析函数栈帧之前,我们需要先明确几个核心基础概念,这是理解后续内容的前提。
1.1 什么是栈?
栈(stack)是计算机系统中一种特殊的动态内存区域,遵循 “先进后出(First In Last Out, FILO)” 的核心规则。你可以把它想象成一叠叠放在桌面上的书本:先放上去的书在最底层,必须最后才能取出;后放上去的书在最顶层,可以最先取出。
在计算机中,栈的核心操作有两个:
- 入栈(push):将数据压入栈顶,栈的空间会随之增大;
- 出栈(pop):将栈顶的数据弹出,栈的空间会随之减小。
一个关键特性需要牢记:在经典操作系统(如 Windows、Linux)中,栈总是向下增长的 —— 即栈从高内存地址向低内存地址扩展。例如,初始时栈顶指向地址 0x0012FF7C,当压入一个 4 字节的整数后,栈顶会移动到 0x0012FF78(地址减小了 4)。
在 x86 架构(32 位系统)中,栈的操作由两个关键寄存器维护:
- esp(Extended Stack Pointer):栈顶寄存器,始终指向栈的当前顶部;
- ebp(Extended Base Pointer):栈底寄存器,始终指向当前函数栈帧的底部。
这两个寄存器就像栈帧的 “边界标记”,它们之间的内存区域,就是当前函数的栈帧空间。
1.2 什么是函数栈帧?
函数栈帧(stack frame)是函数调用过程中,在程序的调用栈(call stack)上为该函数开辟的专属内存空间。简单来说,每一次函数调用,都会创建一个对应的函数栈帧;函数执行结束后,其栈帧会被销毁。
这个专属空间的核心作用的是存储三类数据:
- 函数参数与返回值;
- 临时变量:包括函数的非静态局部变量、编译器自动生成的临时变量(如表达式计算过程中的中间变量);
- 上下文信息:包括函数调用前后需要保持不变的寄存器值(如 ebx、esi、edi 等通用寄存器),确保函数执行完毕后能恢复主调函数的执行环境。
函数栈帧的本质,是函数执行的 “独立环境”—— 每个函数都有自己的栈帧,栈帧之间通过 ebp 寄存器串联(后一个函数栈帧会保存前一个函数栈帧的 ebp 值),形成调用链,这也是调试时 “函数调用堆栈” 的底层原理。
1.3 理解函数栈帧的核心价值
掌握函数栈帧的创建与销毁逻辑,能帮我们彻底搞懂以下 C 语言的核心问题:
- 局部变量是如何创建和存储的?
- 为什么未初始化的局部变量值是随机的?
- 函数调用时参数的传递顺序是怎样的?
- 形参和实参的关系是什么?为什么值传递无法修改实参?
- 函数返回值是如何带回主调函数的?
- 数组越界访问为什么会导致程序崩溃(甚至修改其他变量的值)?
这些问题看似独立,实则都与函数栈帧的内存布局和操作逻辑直接相关。接下来,我们将通过实战代码与汇编指令分析,逐一拆解这些问题的答案。
二、寄存器与汇编指令
要分析函数栈帧的底层操作,必须先熟悉参与栈帧管理的关键寄存器和汇编指令。因为函数栈帧的创建、销毁本质上都是通过汇编指令操作寄存器和内存实现的。
2.1 关键寄存器说明
在 x86 架构下,与函数栈帧相关的核心寄存器有以下 5 个:
| 寄存器 | 中文名称 | 核心作用 |
|---|---|---|
| eax | 累加器 | 通用寄存器,常用于存储函数返回值、临时计算结果 |
| ebx | 基址寄存器 | 通用寄存器,存储临时数据,函数执行时需保存其原值 |
| ebp | 栈底寄存器 | 指向当前函数栈帧的底部,作为栈帧内存访问的基准 |
| esp | 栈顶寄存器 | 指向当前函数栈帧的顶部,随入栈 / 出栈操作动态变化 |
| eip | 指令寄存器 | 存储下一条要执行的指令地址,控制程序执行流程 |
其中,ebp 和 esp 是栈帧管理的 “核心搭档”—— 它们的地址范围界定了当前函数栈帧的大小,所有栈帧内的数据(参数、局部变量、上下文信息)都通过 ebp 的地址偏移来访问。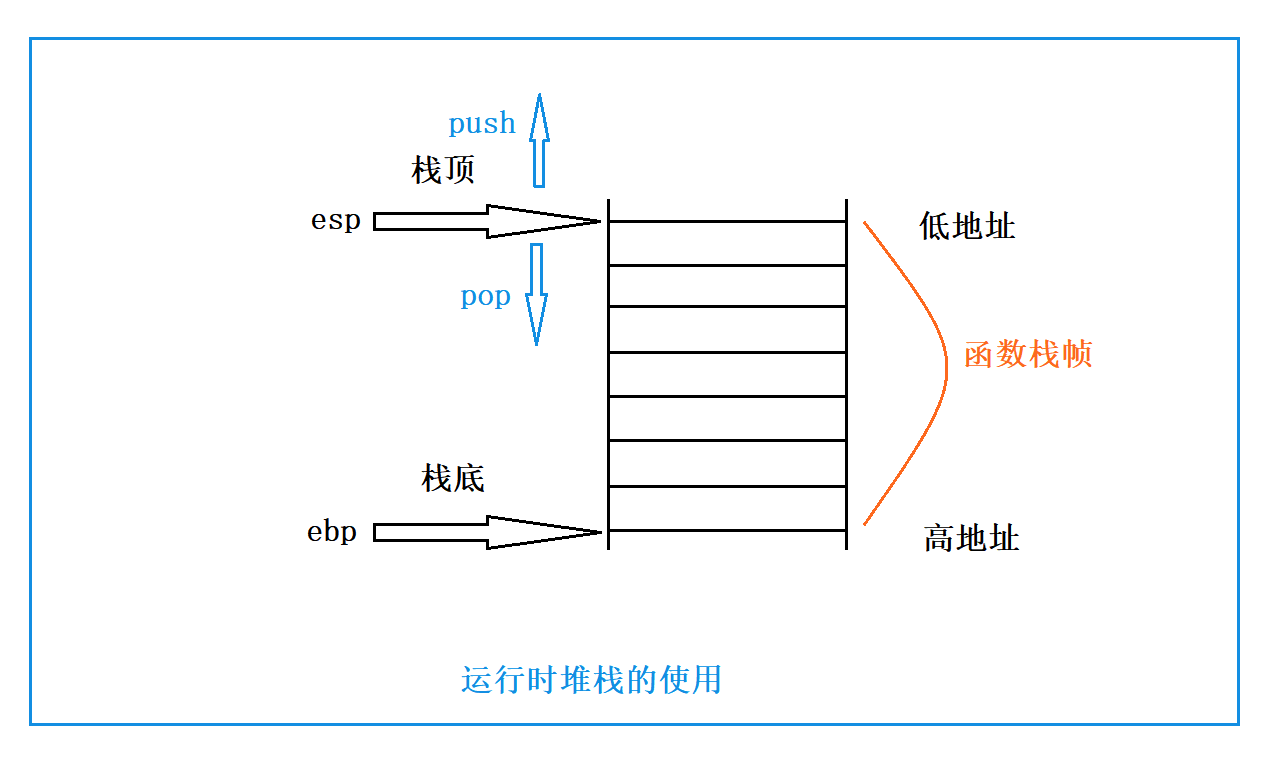
2.2 核心汇编指令说明
函数栈帧的操作主要依赖以下汇编指令,我们结合功能和示例逐一说明:
| 汇编指令 | 功能描述 | 示例(结合栈帧操作) | |
|---|---|---|---|
| mov | 数据转移指令 | 将一个寄存器 / 内存的值赋值给另一个寄存器 / 内存 | mov ebp, esp(将 esp 的值赋给 ebp) |
| push | 入栈指令 | 将数据压入栈顶,esp 自动减 4(32 位系统,每次压入 4 字节) | push ebp(将 ebp 寄存器的值压栈) |
| pop | 出栈指令 | 将栈顶数据弹出到指定寄存器 / 内存,esp 自动加 4 | pop edi(将栈顶值弹出到 edi 寄存器) |
| sub | 减法指令 | 两个操作数相减,结果存放在第一个操作数中 | sub esp, 0E4h(esp = esp - 0E4h) |
| add | 加法指令 | 两个操作数相加,结果存放在第一个操作数中 | add esp, 8(esp = esp + 8) |
| call | 函数调用指令 | 1. 将下一条指令地址压栈(用于函数返回);2. 跳转到目标函数地址 | call Add(调用 Add 函数) |
| ret | 函数返回指令 | 从栈顶弹出 call 指令保存的返回地址,赋值给 eip,跳回主调函数 | ret(Add 函数执行完毕返回) |
| lea | 加载有效地址指令 | 将内存地址计算后赋值给寄存器 | lea edi, [ebp-24h](将 ebp-24h 的地址赋给 edi) |
| rep stos | 重复存储指令 | 按 ecx 指定的次数,将 eax 的值存储到 edi 指向的内存区域 | rep stos dword ptr es:[edi](重复 9 次,将 eax 的值存入 edi 指向的内存) |
这些指令是栈帧操作的基石—— 比如 push 和 pop 用于保存 / 恢复寄存器值,sub 用于扩展栈空间,mov 用于初始化变量,call 和 ret 用于函数调用与返回。后续分析中,我们会频繁用到这些指令,大家可以先熟悉其功能。
三、实战环境配置:让汇编代码更 “纯净”
为了避免编译器附加代码干扰栈帧分析,我们需要对 VS2019 进行简单配置,让生成的汇编代码更简洁、更贴近底层逻辑。
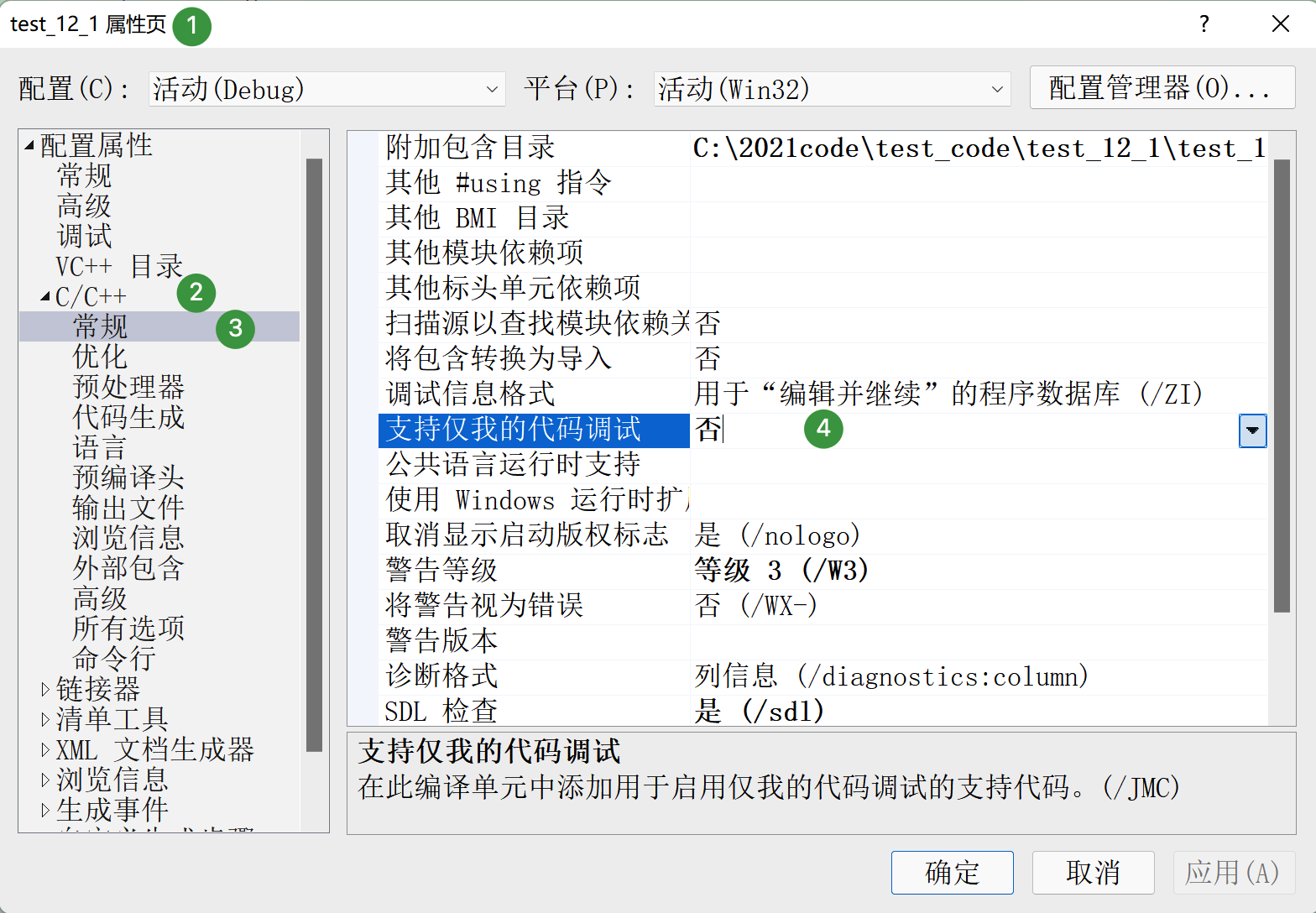
3.1 关闭 “仅我的代码调试”
默认情况下,VS2019 的 “仅我的代码调试” 功能会在汇编中插入大量辅助代码,影响我们对核心逻辑的观察。关闭步骤如下:
- 右键项目 → 属性 → 配置属性 → C/C++ → 调试;
- 将 “支持仅我的代码调试” 设置为 “否”;
- 点击 “应用”→“确定”。
3.2 关闭优化选项
编译器的优化会改变代码执行顺序和内存布局,导致汇编代码与我们编写的 C 代码不一致。关闭步骤如下:
- 右键项目 → 属性 → 配置属性 → C/C++ → 优化;
- 将 “优化” 设置为 “禁用(/Od)”;
- 点击 “应用”→“确定”。
3.3 启用反汇编查看
配置完成后,我们需要通过调试模式查看汇编代码:
- 在代码中设置断点(如 main 函数的第一行);
- 按 F5 启动调试,程序停在断点处;
- 右键代码编辑区 → 转到反汇编,即可看到 C 代码对应的汇编指令。
注意:VS 每次调试都会为程序重新分配内存地址,因此本文中的汇编地址(如 00BE1820)仅为示例,实际调试时地址会不同,但指令逻辑完全一致。
四、函数栈帧的完整生命周期:从创建到销毁
为了让分析更直观,我们以一个简单的加法函数调用为例,全程跟踪函数栈帧的创建、函数调用、参数传递、返回值带回及栈帧销毁的完整过程。
4.1 示例代码
#include <stdio.h>// 加法函数:计算两个整数的和
int Add(int x, int y)
{int z = 0; // 局部变量zz = x + y; // 计算x+y,结果存入zreturn z; // 返回z的值
}int main()
{int a = 3; // 局部变量a,初始化为3int b = 5; // 局部变量b,初始化为5int ret = 0; // 局部变量ret,用于接收Add函数的返回值ret = Add(a, b); // 调用Add函数,传入a和b,返回值存入retprintf("%d\n", ret); // 打印结果return 0;
}这段代码的核心逻辑是:main 函数调用 Add 函数,传入 3 和 5,Add 函数计算和后返回,main 函数接收返回值并打印。接下来,我们将从 main 函数的栈帧创建开始,一步步拆解每一个汇编指令的作用。
4.2 函数调用堆栈分析
在调试时,我们可以通过 “调用堆栈” 窗口(右击勾选 “显示外部代码”)看到函数的调用关系: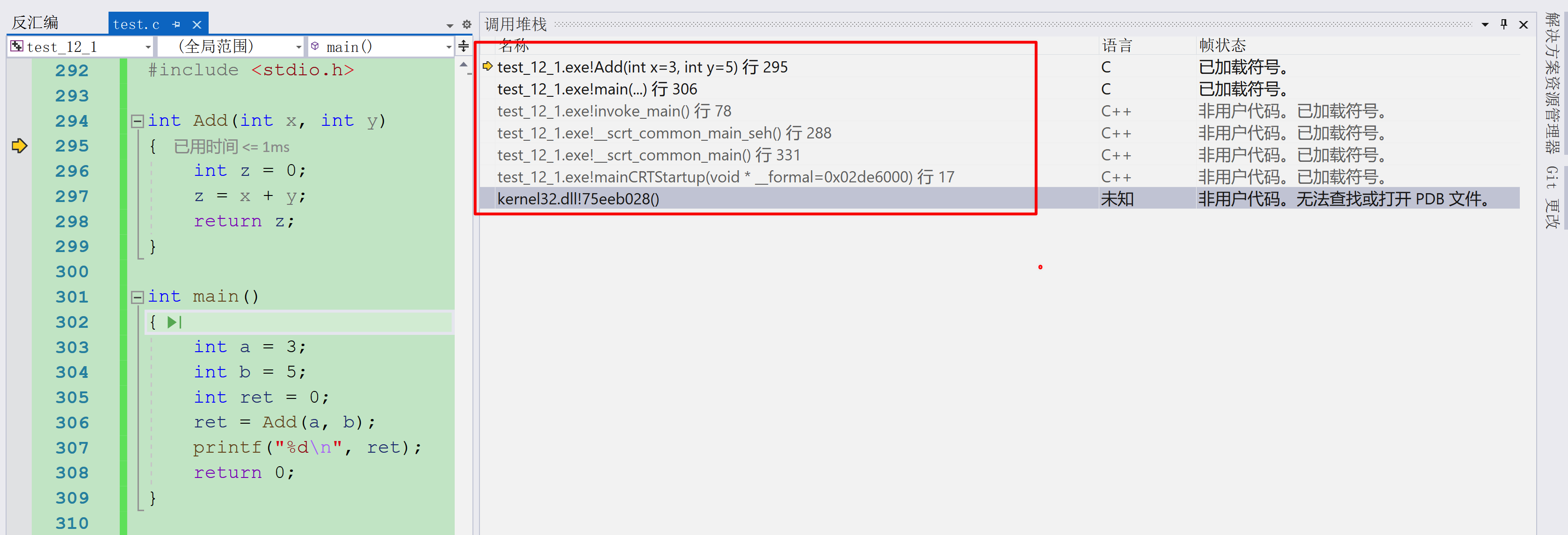
Add(int x, int y) // 当前正在执行的函数
main() // 调用Add的主调函数
invoke_main() // 调用main的函数
... // 更上层的系统函数(暂不关注)从调用堆栈可以看出:main 函数并非程序的 “最顶层” 函数,而是由 invoke_main 函数调用的。每个函数都会维护自己的栈帧,栈帧之间通过 ebp 寄存器串联,形成完整的调用链。
我们的分析将围绕三个核心栈帧展开:
- invoke_main 函数栈帧(作为 main 函数的调用者,提供 main 的栈帧基础);
- main 函数栈帧(创建、传参、调用 Add、接收返回值);
- Add 函数栈帧(创建、计算、返回结果、销毁)。
4.3 main 函数栈帧的创建
main 函数的栈帧是在 invoke_main 函数调用 main 时创建的。当程序执行到 main 函数的第一行时,对应的汇编指令如下(已添加详细注释):
int main()
{// 以下是main函数栈帧创建的核心指令00BE1820 push ebp ; 1. 将invoke_main函数栈帧的ebp压栈(保存上一层栈帧的底部); 此时esp = esp - 4(入栈操作,栈顶下移)00BE1821 mov ebp, esp ; 2. 将当前esp的值赋给ebp,此时ebp成为main函数栈帧的底部; 至此,ebp和esp共同界定了main函数栈帧的初始范围00BE1823 sub esp, 0E4h ; 3. 扩展栈空间:esp = esp - 0E4h(0E4h是16进制,对应228字节); 这部分空间用于存储main函数的局部变量、临时数据和调试信息00BE1829 push ebx ; 4. 保存ebx寄存器的值到栈中(esp-4)00BE182A push esi ; 5. 保存esi寄存器的值到栈中(esp-4)00BE182B push edi ; 6. 保存edi寄存器的值到栈中(esp-4); 注:ebx、esi、edi是通用寄存器,main函数执行时可能会修改它们; 因此先保存原值,后续函数退出时恢复,避免影响上一层函数// 以下是main函数栈帧空间的初始化(填充0xCCCCCCCC)00BE182C lea edi, [ebp-24h] ; 7. 将ebp-24h的地址加载到edi(edi指向栈帧中某块内存的起始地址)00BE182F mov ecx, 9 ; 8. 将9存入ecx(ecx作为循环计数器,控制重复次数)00BE1834 mov eax, 0CCCCCCCCh ; 9. 将0xCCCCCCCC存入eax(要填充的值)00BE1839 rep stos dword ptr es:[edi] ; 10. 循环9次,将eax的值(0xCCCCCCCC)存入edi指向的内存; 每次循环edi+4(dword为4字节),ecx-1,直到ecx=0
}4.3.1 栈帧创建的核心步骤总结
main 函数栈帧的创建过程可以概括为 5 步:
- 保存上一层栈帧的 ebp:通过
push ebp将 invoke_main 函数的 ebp 压栈,确保后续能恢复上一层栈帧; - 建立当前栈帧的 ebp:通过
mov ebp, esp将当前 esp 的值赋给 ebp,ebp 成为 main 栈帧的 “基准点”; - 扩展栈空间:通过
sub esp, 0E4h减小 esp 的值,开辟出 main 函数所需的栈空间(局部变量、临时数据等); - 保存上下文寄存器:将 ebx、esi、edi 寄存器的值压栈,避免后续修改影响上一层函数;
- 初始化栈帧空间:通过
rep stos指令将栈帧的部分区域填充为 0xCCCCCCCC,这是编译器的调试机制。
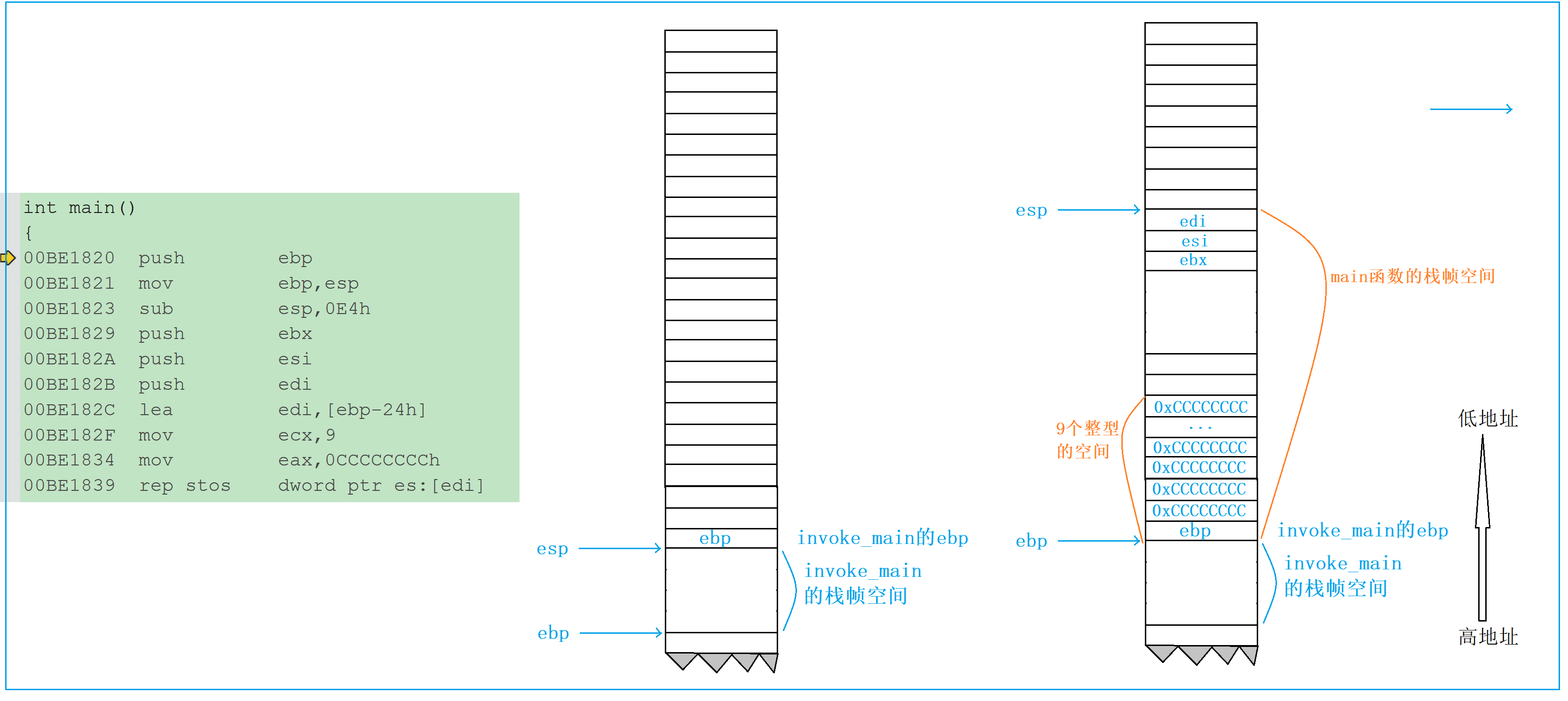
4.3.2 为什么未初始化的局部变量是随机值?
这里有一个关键细节:编译器用 0xCCCCCCCC 填充栈帧空间。如果我们定义了一个未初始化的局部变量(如char arr[20];),它会被分配到这块填充了 0xCCCCCCCC 的内存中。
在 GB2312 编码中,两个连续的 0xCC(即 0xCCCC)对应的汉字是 “烫”,这就是为什么未初始化的字符数组打印时会输出一串 “烫烫烫”。而对于整型变量,未初始化时的值就是 0xCCCCCCCC(十进制为 - 858993460),看起来是 “随机值”,实则是编译器填充的默认值。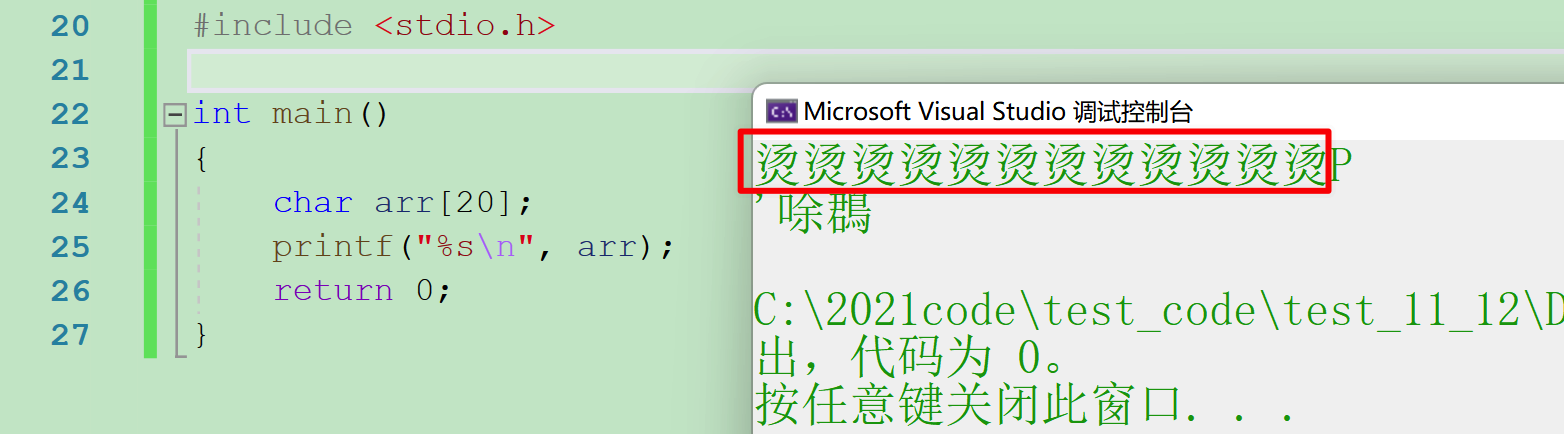
但为什么说它是 “随机值”?因为如果程序多次调用函数,栈帧会重复使用这块内存,上一次函数执行后残留的数据可能会覆盖 0xCCCCCCCC,导致未初始化的局部变量值不确定。这也解释了:局部变量的初始化是必要的,否则其值可能是垃圾数据。
4.4 main 函数中局部变量的创建与初始化
栈帧创建完成后,程序开始执行 main 函数中的核心代码 —— 创建并初始化局部变量 a、b、ret。对应的汇编指令如下:
// 局部变量a = 3
00BE183B mov dword ptr [ebp-8], 3 ; 将3存入ebp-8指向的内存地址,该地址就是变量a的存储位置
// 局部变量b = 5
00BE1842 mov dword ptr [ebp-14h], 5 ; 将5存入ebp-14h指向的内存地址,该地址就是变量b的存储位置
// 局部变量ret = 0
00BE1849 mov dword ptr [ebp-20h], 0 ; 将0存入ebp-20h指向的内存地址,该地址就是变量ret的存储位置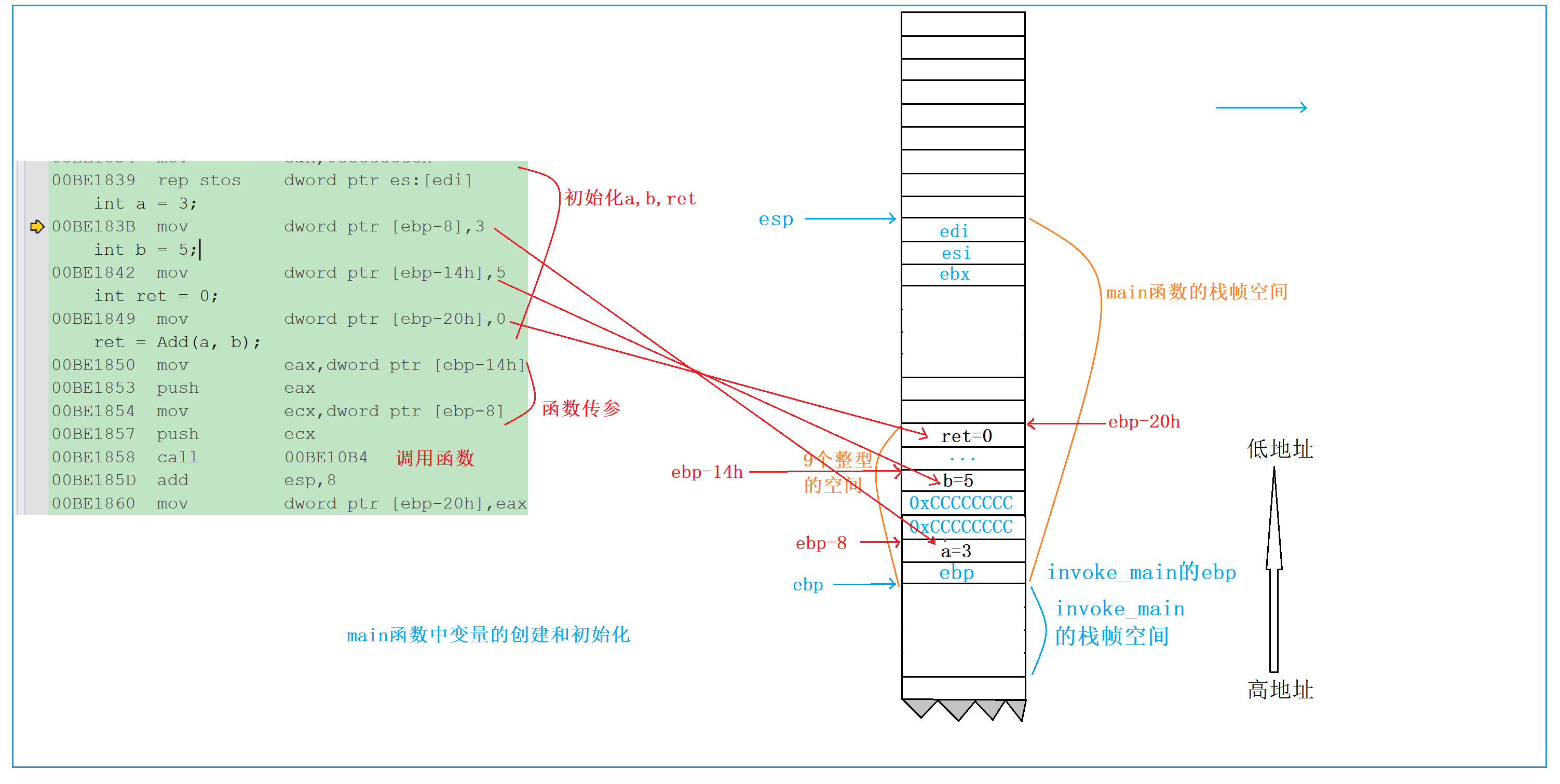
关键结论:局部变量的存储本质
从汇编指令可以看出:
- 局部变量的创建本质是 “在函数栈帧中分配内存地址”——a、b、ret 分别对应 ebp-8、ebp-14h、ebp-20h 的地址;
- 局部变量的初始化本质是 “向分配的内存地址写入值”—— 通过 mov 指令将 3、5、0 分别写入对应的地址;
- 局部变量的地址是相对于 ebp 的偏移量(如 a 在 ebp 下方 8 字节处),因为 ebp 是栈帧的基准点,地址固定,通过偏移量可以准确访问变量。
这里需要注意:栈是向下增长的(高地址→低地址),因此局部变量的地址从高到低依次是:a(ebp-8)→ b(ebp-14h)→ ret(ebp-20h)(因为 14h=20,20h=32,32>20>8,地址越低)。
4.5 函数调用:参数传递与 Add 函数栈帧创建
main 函数执行到ret = Add(a, b);时,会触发 Add 函数的调用。这一过程包含三个核心步骤:参数传递、保存返回地址、创建 Add 函数栈帧。
4.5.1 参数传递的汇编实现
ret = Add(a, b);
// 第一步:传递参数b(实参b的值为5)
00BE1850 mov eax, dword ptr [ebp-14h] ; 将ebp-14h(b的地址)的值5存入eax寄存器
00BE1853 push eax ; 将eax中的5压栈(esp-4),此时栈顶存储的是b的值
// 第二步:传递参数a(实参a的值为3)
00BE1854 mov ecx, dword ptr [ebp-8] ; 将ebp-8(a的地址)的值3存入ecx寄存器
00BE1857 push ecx ; 将ecx中的3压栈(esp-4),此时栈顶存储的是a的值
// 第三步:调用Add函数
00BE1858 call 00BE10B4 ; 1. 将下一条指令(00BE185D)的地址压栈(保存返回地址);; 2. 跳转到Add函数的入口地址(00BE10B4)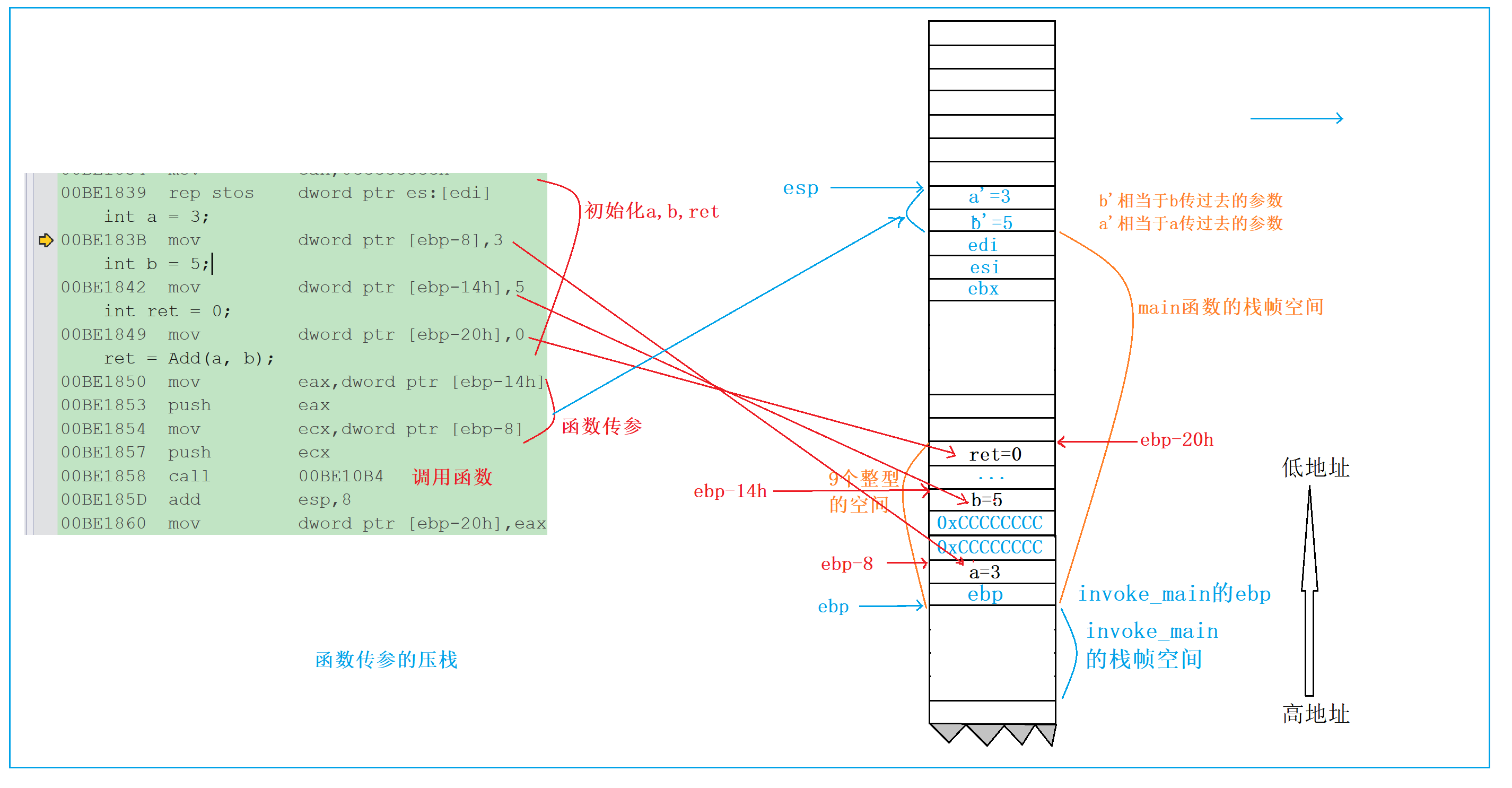
4.5.2 关键问题:参数传递的顺序是怎样的?
从汇编指令可以清晰看出:传递参数时,先传递 b(第二个实参),再传递 a(第一个实参)。这意味着C 语言函数参数的传递顺序是 “从右到左”。
为什么是从右到左?核心原因是栈的 “先进后出” 特性。函数调用时,参数需要压入栈中,而函数内部是通过 ebp 的正偏移量访问参数(后续会看到)。如果从左到右传递参数,第一个参数会被压在栈的下方,访问时需要计算更大的偏移量;而从右到左传递,第一个参数会在栈的上方(靠近 ebp),访问更高效。
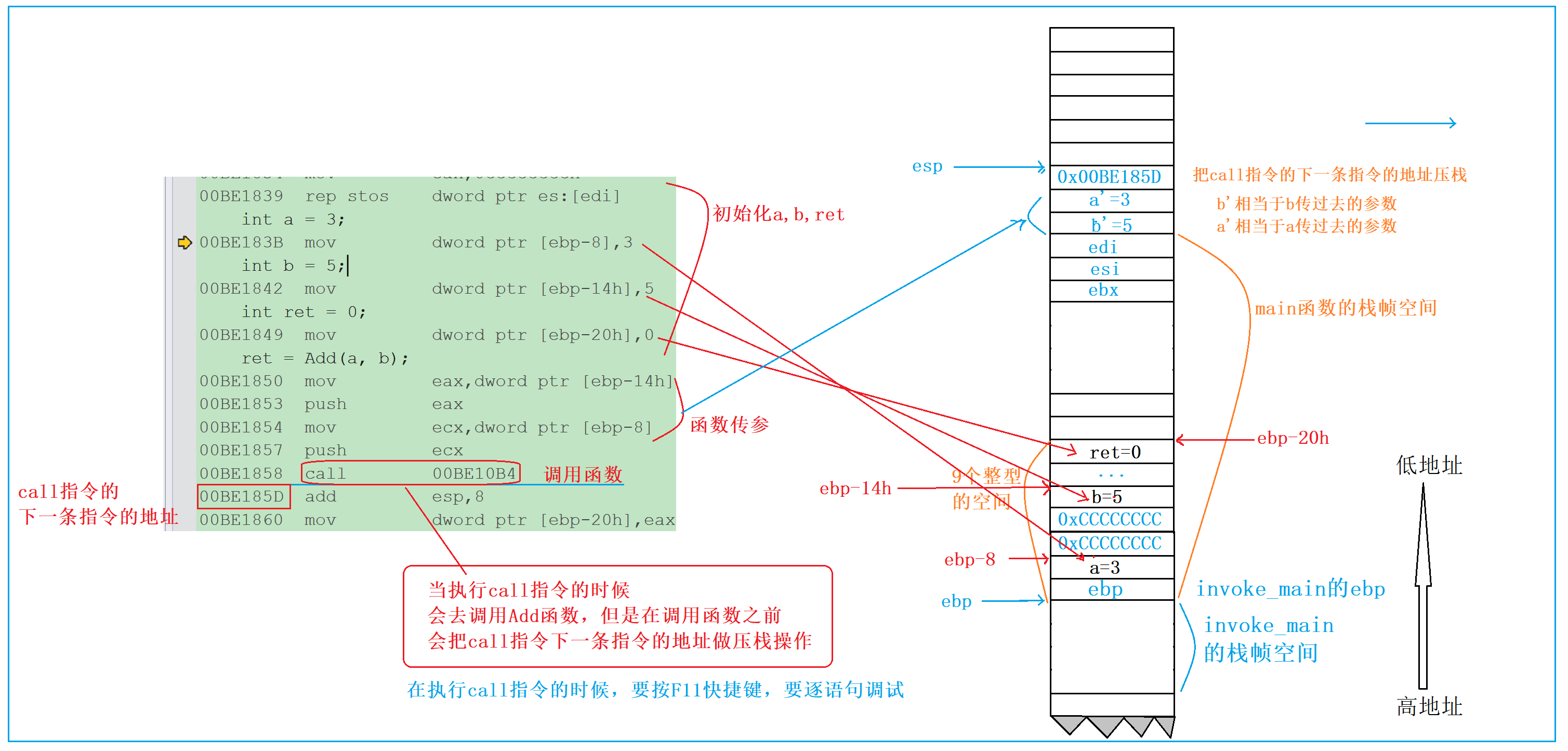
4.5.3 call 指令的核心作用
call 指令是函数调用的关键,它做了两件事:
- 保存返回地址:将 call 指令的下一条指令(
00BE185D add esp,8)的地址压栈。这是为了让 Add 函数执行完毕后,能回到 main 函数继续执行后续代码;- 跳转到目标函数:将 Add 函数的入口地址(00BE10B4)赋值给 eip 寄存器,程序开始执行 Add 函数的代码。
4.5.4 Add 函数栈帧的创建
当程序跳转到 Add 函数后,首先会创建 Add 函数的栈帧。其过程与 main 函数栈帧的创建几乎一致,只是栈空间大小不同:
int Add(int x, int y)
{// Add函数栈帧创建开始00BE1760 push ebp ; 1. 将main函数栈帧的ebp压栈(保存上一层栈帧的底部),esp-400BE1761 mov ebp, esp ; 2. 将当前esp的值赋给ebp,ebp成为Add函数栈帧的底部00BE1763 sub esp, 0CCh ; 3. 扩展栈空间:esp = esp - 0CCh(204字节),用于存储Add的局部变量00BE1769 push ebx ; 4. 保存ebx寄存器的值,esp-400BE176A push esi ; 5. 保存esi寄存器的值,esp-400BE176B push edi ; 6. 保存edi寄存器的值,esp-4// 局部变量z的创建与初始化int z = 0;00BE176C mov dword ptr [ebp-8], 0 ; 将0存入ebp-8指向的内存地址,该地址是变量z的存储位置
}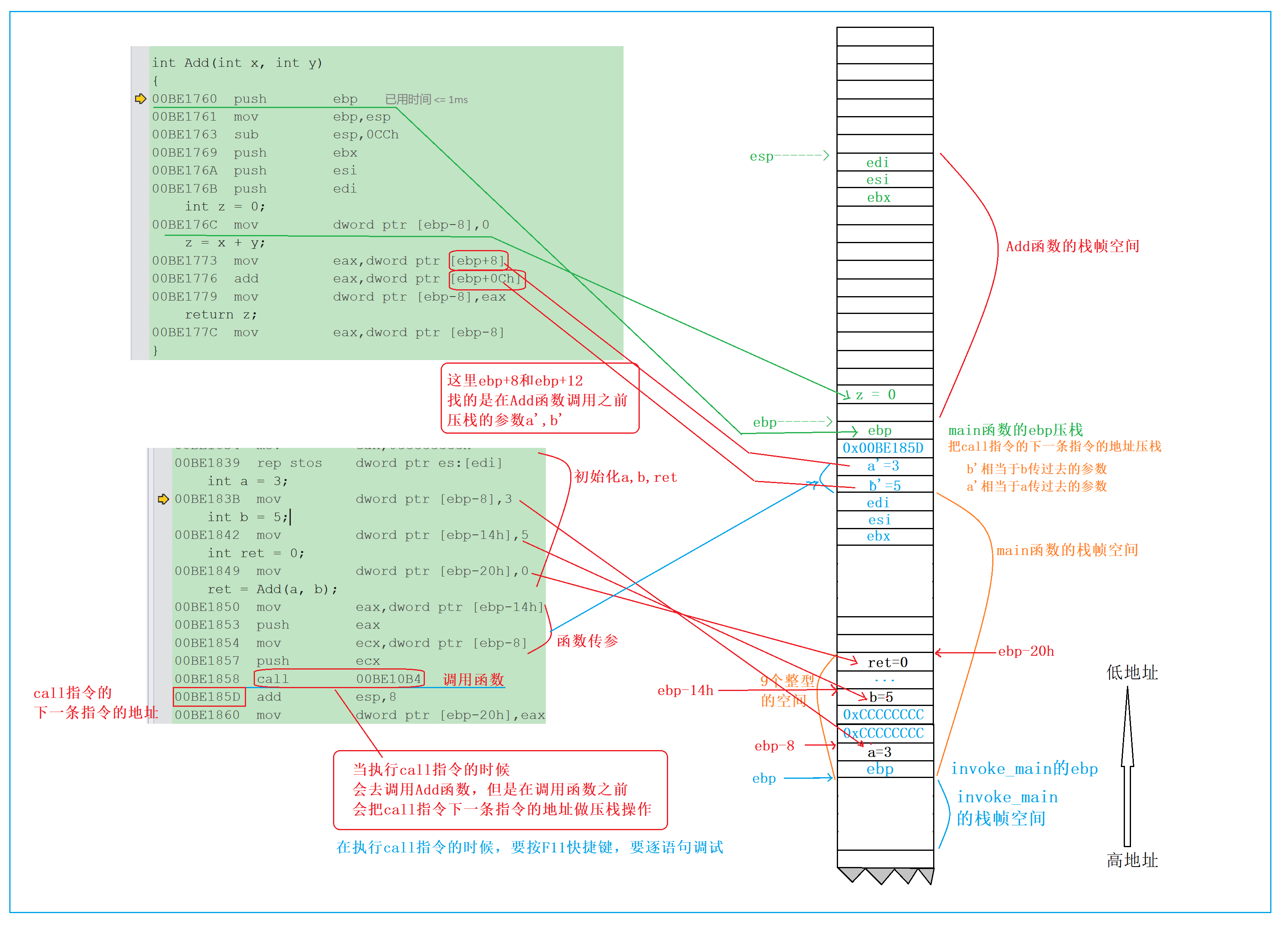
4.5.5 形参 x 和 y 的存储位置
Add 函数的形参 x 和 y 是如何存储的?我们结合当前的 ebp 和栈布局来分析:
此时,ebp 是 Add 函数栈帧的底部,其值等于 main 函数调用 Add 时压入最后一个参数后的 esp(即压入 a 的值后的 esp)。栈的布局如下(从高地址到低地址):
| 地址(相对 ebp) | 存储内容 | 说明 |
|---|---|---|
| ebp+0Ch(12) | 实参 b 的值(5) | 第二个参数,先压栈,位于栈的下方 |
| ebp+8 | 实参 a 的值(3) | 第一个参数,后压栈,位于栈的上方 |
| ebp+4 | 返回地址(00BE185D) | call 指令压入的 main 函数后续指令地址 |
| ebp | main 函数的 ebp 值 | push ebp 压入的上一层栈帧底部地址 |
| ebp-8 | 局部变量 z(0) | Add 函数的局部变量 |
因此,Add 函数中访问形参 x 和 y,本质是通过 ebp 的正偏移量访问栈中的实参拷贝:
- x 对应 ebp+8(存储的是 a 的拷贝 3);
- y 对应 ebp+0Ch(存储的是 b 的拷贝 5)。
这也解释了为什么值传递无法修改实参:形参 x 和 y 是实参 a 和 b 的拷贝,存储在 Add 函数的栈帧中,对 x 和 y 的修改只是修改拷贝的值,不会影响 main 函数栈帧中 a 和 b 的原始值。
4.6 Add 函数的执行与返回值传递
Add 函数的核心逻辑是计算 x+y 并返回结果。对应的汇编指令如下:
z = x + y;
// 第一步:将x的值(ebp+8处的3)存入eax
00BE1773 mov eax, dword ptr [ebp+8] ; eax = x = 3
// 第二步:将y的值(ebp+0Ch处的5)加到eax中
00BE1776 add eax, dword ptr [ebp+0Ch] ; eax = eax + y = 3 + 5 = 8
// 第三步:将计算结果存入z(ebp-8处)
00BE1779 mov dword ptr [ebp-8], eax ; z = eax = 8return z;
// 第四步:将z的值存入eax寄存器(用于带回返回值)
00BE177C mov eax, dword ptr [ebp-8] ; eax = z = 8关键结论:返回值的传递方式
从汇编指令可以看出,Add 函数的返回值(8)是通过 eax 寄存器带回 main 函数的。这是 C 语言中返回值传递的核心方式:
- 对于内置类型(int、char、float 等)的返回值,编译器会将其存入 eax 寄存器,主调函数从 eax 中读取返回值;
- 对于较大的对象(如结构体、数组),eax 寄存器无法存储,编译器会在主调函数的栈帧中开辟一块空间,将该空间的地址隐式传递给被调函数,被调函数将返回值存入该空间(具体可参考《程序员的自我修养》第 10 章)。
4.7 Add 函数栈帧的销毁
Add 函数执行完 return 语句后,需要销毁其栈帧,恢复 main 函数的栈帧环境,以便 main 函数继续执行。栈帧销毁的汇编指令如下:
return z;
00BE177C mov eax, dword ptr [ebp-8] ; 已执行:将返回值存入eax
00BE177F pop edi ; 1. 弹出栈顶值(之前保存的edi原值),存入edi寄存器,esp+4
00BE1780 pop esi ; 2. 弹出栈顶值(之前保存的esi原值),存入esi寄存器,esp+4
00BE1781 pop ebx ; 3. 弹出栈顶值(之前保存的ebx原值),存入ebx寄存器,esp+4
00BE1782 mov esp, ebp ; 4. 将ebp的值赋给esp,回收Add函数的栈空间(esp回到Add栈帧的底部)
00BE1784 pop ebp ; 5. 弹出栈顶值(main函数的ebp),存入ebp寄存器,esp+4; 此时ebp恢复为main函数的栈帧底部,esp指向main函数栈帧的栈顶
00BE1785 ret ; 6. 弹出栈顶值(call指令保存的返回地址00BE185D),赋值给eip; 程序跳回main函数的返回地址处,继续执行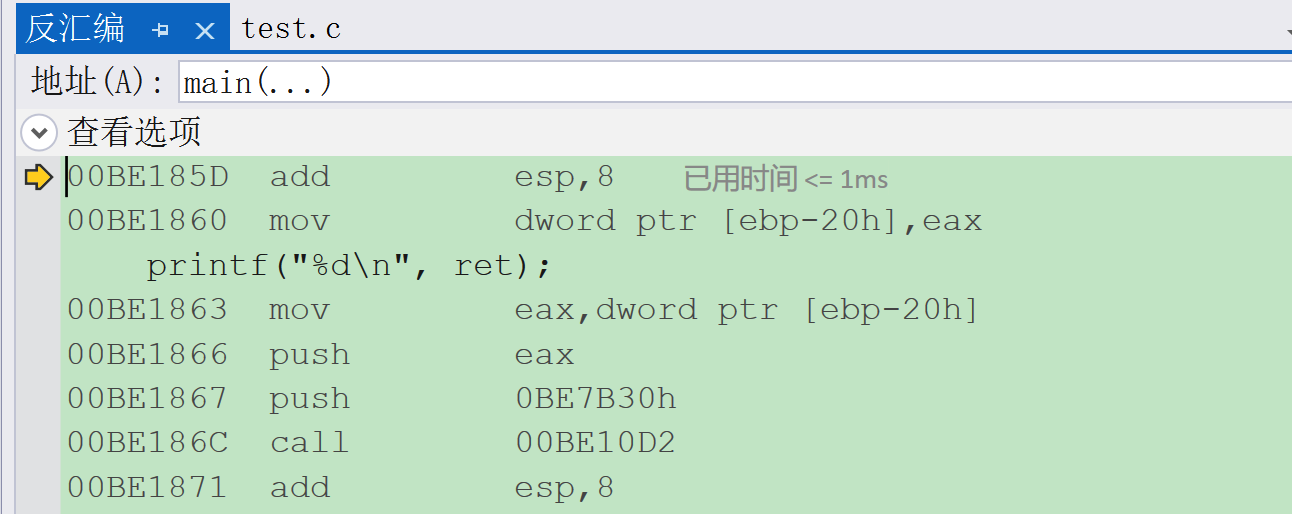
栈帧销毁的核心目的
Add 函数栈帧的销毁过程,本质是 “逆向撤销” 栈帧创建时的操作:
- 恢复保存的寄存器值(edi、esi、ebx);
- 回收 Add 函数的栈空间(mov esp, ebp);
- 恢复 main 函数的栈帧基准(pop ebp);
- 跳回 main 函数继续执行(ret 指令)。
销毁后,Add 函数的栈帧空间被释放,后续其他函数调用可以复用这块内存。
4.8 main 函数接收返回值与后续执行
ret 指令执行后,程序跳回 main 函数的返回地址(00BE185D add esp,8),继续执行后续代码:
// 回到main函数,继续执行call指令的下一条指令
00BE185D add esp, 8 ; 1. esp = esp + 8,跳过main函数压入的两个参数(a和b的拷贝); 此时栈顶恢复到调用Add函数前的状态
00BE1860 mov dword ptr [ebp-20h], eax ; 2. 将eax中的返回值(8)存入ebp-20h(ret变量的地址); 即ret = Add(a,b) = 8// 打印ret的值
printf("%d\n", ret);
00BE1863 mov eax, dword ptr [ebp-20h] ; 将ret的值(8)存入eax
00BE1866 push eax ; 将8压栈(printf的第二个参数)
00BE1867 push 0BE7B30h ; 将字符串"%d\n"的地址压栈(printf的第一个参数)
00BE186C call 00BE10D2 ; 调用printf函数
00BE1871 add esp, 8 ; 回收printf的参数栈空间// main函数返回
return 0;
00BE1874 xor eax, eax ; 将eax清零(main函数的返回值为0)
}关键步骤说明
- 回收参数栈空间:
add esp,8跳过两个压入的参数(每个参数 4 字节,共 8 字节),栈顶恢复到调用 Add 前的状态;- 接收返回值:将 eax 中的 8 存入 ret 变量的地址,完成返回值的接收;
- 调用 printf 函数:printf 的参数传递同样遵循 “从右到左” 的顺序,先压入 ret 的值,再压入格式字符串地址;
- main 函数返回:
xor eax,eax将 eax 清零(main 函数的返回值为 0),随后 main 函数的栈帧也会被销毁(过程与 Add 函数类似)。
五、常见问题分析
通过前面的完整分析,我们可以解答开篇提出的几个核心问题,让大家对 C 语言的底层逻辑有更深刻的理解。
5.1 局部变量是如何创建的?
局部变量的创建本质是 “在函数栈帧中分配内存地址”:
- 函数调用时,通过
sub esp, 偏移量扩展栈空间,为局部变量预留内存;- 局部变量的地址是相对于 ebp 的偏移量(如 main 函数的 a 在 ebp-8),ebp 作为栈帧基准,确保地址访问的准确性;
- 局部变量的初始化是向分配的地址写入值,未初始化则保留栈帧的默认填充值(0xCCCCCCCC)或上一次函数残留的数据。
5.2 为什么未初始化的局部变量值是随机的?
未初始化的局部变量值 “随机” 的核心原因是栈的复用性:
- 函数栈帧的内存空间会被重复使用(一个函数执行完毕,栈帧销毁,后续函数调用可复用该空间);
- 未初始化的局部变量会使用栈帧中未被覆盖的旧数据(可能是上一个函数的残留数据,也可能是编译器填充的 0xCCCCCCCC);
- 每次程序运行时,栈帧的分配地址和残留数据都可能不同,因此未初始化的局部变量值看起来是 “随机” 的。
5.3 函数参数的传递顺序是怎样的?
C 语言函数参数的传递顺序是 “从右到左”,这是由栈的特性和编译器的实现逻辑决定的:
- 栈是向下增长的,参数压栈时从右到左,第一个参数会靠近 ebp(栈帧底部);
- 函数内部通过 ebp 的正偏移量访问参数(如 Add 函数的 x 在 ebp+8,y 在 ebp+0Ch),从右到左传递能让参数访问更高效;
- 若参数数量不固定(如 printf 函数),从右到左传递能确保编译器先处理固定参数,再处理可变参数。
5.4 形参和实参的关系是什么?
形参是实参的 “拷贝”,二者存储在不同的栈帧中:
- 实参存储在主调函数的栈帧中(如 main 函数的 a 和 b);
- 函数调用时,实参的值被压入栈中,形参在被调函数的栈帧中通过 ebp 偏移量访问这些拷贝值(如 Add 函数的 x 和 y);
- 对形参的修改仅影响拷贝值,不会改变主调函数中实参的原始值,这就是 “值传递” 的本质。
5.5 函数返回值是如何带回的?
函数返回值的传递方式取决于返回值的类型:
- 内置类型(int、char、float 等):通过 eax 寄存器传递,被调函数将返回值存入 eax,主调函数从 eax 中读取;
- 较大对象(结构体、数组等):在主调函数的栈帧中开辟一块空间,将该空间地址隐式传递给被调函数,被调函数将返回值存入该空间;
- 特殊情况(如返回值为 double):使用 edx+eax 联合传递(edx 存储高位,eax 存储低位)。
5.6 数组越界为什么会导致程序崩溃?
数组越界访问的本质是 “访问了函数栈帧之外的内存”:
- 数组在栈帧中是连续存储的,数组名是数组首元素的地址;
- 若数组越界(如
int arr[3]; arr[5] = 0;),会访问到栈帧中其他变量的内存(如相邻的局部变量)或栈帧之外的内存(如其他函数的栈帧、寄存器保存的值);- 若修改了栈帧之外的关键数据(如返回地址、ebp 值),会导致程序执行流程错乱,最终引发崩溃。
总结
函数栈帧的知识虽然偏底层,但它能帮你从根源上理解 C 语言的执行逻辑,让你在编写代码时更严谨,排查 bug 时更高效。希望本文能带你走进 C 语言的底层世界,让你对 C 语言有更深刻的认识!谢谢大家的支持!