三分钟部署最新开源大模型!Amazon SageMaker JumpStart 生成式 AI 实战指南
摘要:还在为部署生成式AI模型而头疼吗?环境配置、资源管理、推理部署...每一步都是坑。本文将介绍如何利用 Amazon SageMaker JumpStart,像“点菜”一样,在几分钟内一键部署 Llama、Mistral 等最新开源大模型,并提供一个完整的代码实战演示。
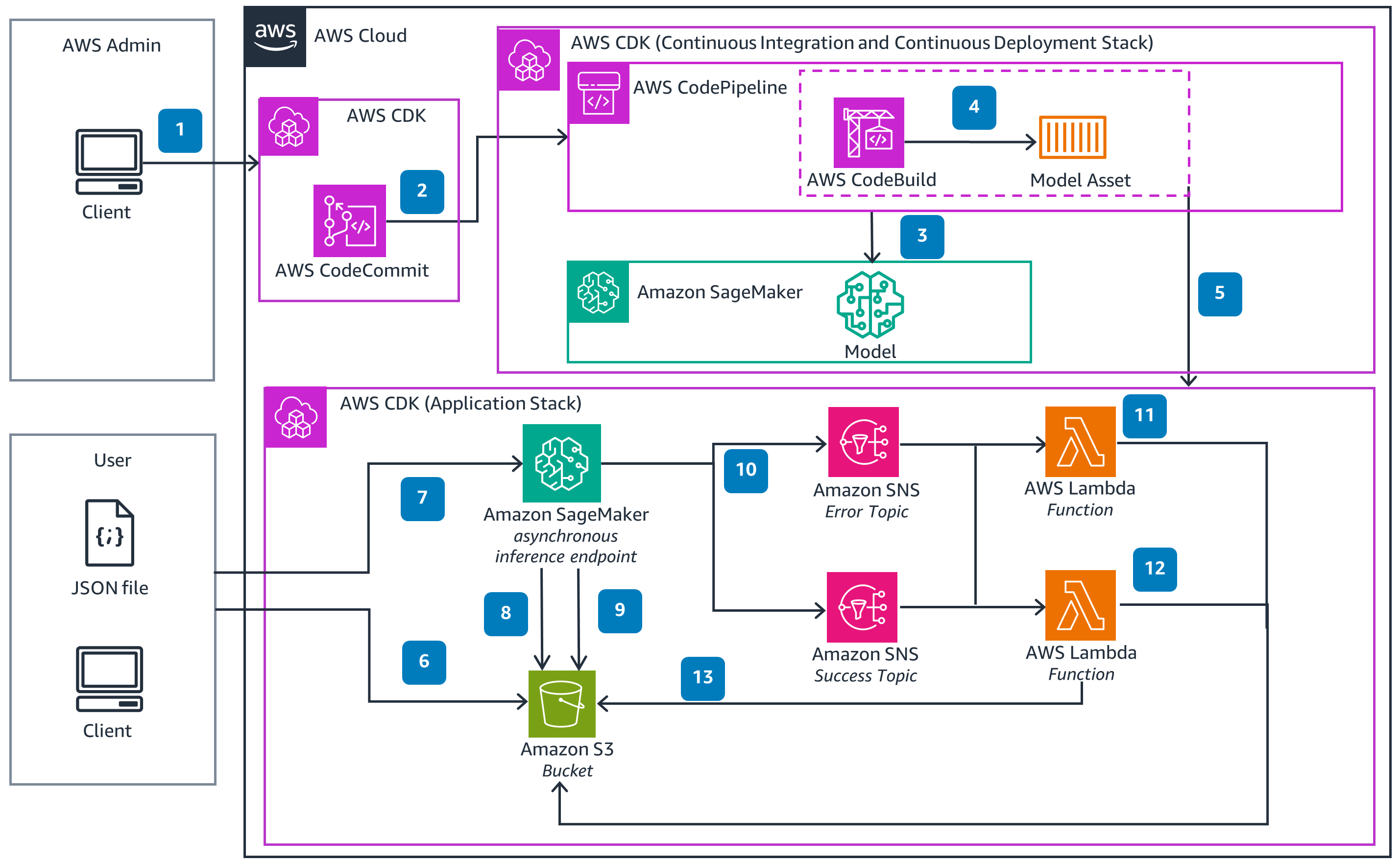
运作方式
这些技术细节以体系结构图为特色,以说明如何有效地使用此解决方案。架构图显示了关键组件及其交互,逐步概述了架构的结构和功能
一、 生成式AI的浪潮与部署之痛
生成式AI正在重塑各行各业,从代码生成、内容创作到智能客服,其潜力无限。然而,对于大多数开发者和团队而言,从“发现一个好模型”到“真正用起来”,中间横亘着一条巨大的鸿沟:
-
环境配置复杂:CUDA、PyTorch、TensorFlow... 依赖环境配置足以让人望而却步。
-
资源管理困难:需要多少GPU?如何扩缩容?成本如何控制?
-
部署流程繁琐:将模型打包成可扩展、高可用的API服务并非易事。
-
模型选择困难:开源模型层出不穷,哪个才最适合我的业务场景?
有没有一种服务,能让我们专注于应用和创新,而非底层基础设施的繁琐运维?
答案是肯定的——Amazon SageMaker JumpStart。
二、 什么是 SageMaker JumpStart?你的生成式AI“应用商店”
你可以把 SageMaker JumpStart 想象成 AWS 为机器学习领域打造的“一站式应用商店”或“模型超市”。
它集成了来自 AWS、领先 AI 公司(如 Hugging Face)和顶级开源社区的大量预训练模型,涵盖了自然语言处理、计算机视觉、推荐系统等多个领域。对于生成式AI,它更是重点集成了包括 Llama 2、Mistral、Falcon、Stable Diffusion 等在内的明星模型。
它的核心价值在于:
-
开箱即用:无需自行搜索、下载和配置模型。
-
一键部署:点击几下鼠标或运行几行代码,即可将模型部署为可扩展的实时API端点。
-
全托管服务:AWS负责底层的基础设施、安全和扩缩容,你只需为调用付费。
三、 实战:五分钟部署 Llama 2 大模型
让我们以部署 Meta 的 Llama 2 Chat 13B 模型为例,展示整个流程是多么的简单高效。
步骤一:进入 SageMaker 控制台并找到 JumpStart
-
登录 AWS Management Console,搜索并进入 Amazon SageMaker。
-
在左侧导航栏中,点击 JumpStart。
你现在会看到一个琳琅满目的模型广场,顶部有搜索框,可以快速找到你想要的模型。
步骤二:选择并配置模型
-
在搜索框中输入 “Llama 2 Chat”,然后选择 “Llama 2 Chat 13B” 模型卡片。
-
点击模型卡片,你会看到模型的详细介绍、性能、许可证等信息。
-
滚动到 “Deployment configuration” 部分:
-
SageMaker Hosting:选择终端节点类型(如
ml.g5.2xlarge,这是一种性价比很高的GPU实例)。JumpStart 会自动为你推荐适合该模型的实例类型。 -
Endpoint name:为你部署的API起一个名字,例如
jumpstart-llama2-13b-chat。
-
步骤三:一键部署与等待
-
点击 “Deploy” 按钮。
-
SageMaker 现在会在后台自动完成所有繁重的工作:
-
从模型仓库拉取 Llama 2 模型镜像。
-
在你的AWS账户中启动指定的EC2实例。
-
将模型加载到实例中。
-
配置网络和安全组。
-
最终,提供一个 HTTPS 终端节点 URL。
-
这个过程大约需要 5-10分钟。部署成功后,控制台会显示终端节点的状态为 “InService”。
步骤四:调用你的专属大模型API
现在,你可以通过任何AWS SDK(如Python的boto3)或直接通过HTTP请求来调用这个端点了。以下是使用 boto3 的示例代码:
import json
import boto3# 创建SageMaker Runtime客户端
runtime = boto3.client('sagemaker-runtime')# 你的终端节点名称
endpoint_name = 'jumpstart-llama2-13b-chat'# 构建请求载荷
payload = {"inputs": "请用中文介绍一下亚马逊云科技。","parameters": {"max_new_tokens": 512, # 生成的最大token数"temperature": 0.5, # 控制创造性 (0.0-1.0)"top_p": 0.9, # 核采样参数"do_sample": True # 启用采样}
}# 调用端点
response = runtime.invoke_endpoint(EndpointName=endpoint_name,ContentType='application/json',Body=json.dumps(payload)
)# 解析并打印结果
result = json.loads(response['Body'].read().decode())
print(result[0]["generated_text"])运行这段代码,你将立刻得到 Llama 2 模型生成的中文回答! 至此,一个世界级的开源大模型就已经完全在你的掌控之中,成为了一个随时可调用的云服务。
四、 进阶玩法与最佳实践
-
快速实验与评估:JumpStart 让你可以快速部署多个不同规格的模型(如 Llama 2 7B, 13B, 70B),并行地进行测试和评估,找到性价比最高的选择。
-
保护你的投资:对于生产环境,务必:
-
配置自动扩缩容:根据流量动态调整实例数量,节约成本。
-
启用终端节点加密:保证数据传输安全。
-
使用 IAM 策略:严格控制谁有权限调用你的模型端点。
-
-
从 JumpStart 到自定义训练:JumpStart 不仅是部署工具,许多模型还提供了在你自己数据上进一步微调(Fine-tuning)的脚本,让你能打造专属的、更具竞争力的模型。
五、 总结:为什么选择 SageMaker JumpStart?
在生成式AI的竞争中,速度就是一切。SageMaker JumpStart 从根本上解决了模型部署的“最后一公里”问题,为开发者和企业带来了三大核心优势:
-
极致简化:将复杂的 MLOps 流程简化为几次点击,极大降低了技术门槛。
-
企业级就绪:部署的端点天生具备高可用、安全和可扩展的特性,可直接用于生产环境。
-
紧跟潮流:AWS 持续与顶级AI机构合作,确保 JumpStart 能快速集成最新、最优秀的开源模型。
无论你是想快速验证一个AI想法,还是需要为你的应用集成强大的生成式AI能力,Amazon SageMaker JumpStart 都是你最值得尝试的“加速器”。
立即访问 AWS 管理控制台,在 SageMaker JumpStart 中开启你的第一个生成式AI模型部署吧
互动环节:
你已经使用过 SageMaker JumpStart 了吗?部署了哪个有趣的模型?或者在部署过程中遇到了任何问题?欢迎在评论区留言分享你的经验和见解!