聚类算法实战:从 KMeans 到 DBSCAN
聚类算法实战:从 KMeans 到 DBSCAN 的完整实现
前言
聚类算法是机器学习中一种重要的无监督学习方法,它能够将数据集中的样本按照相似性自动分组。本文将通过实际案例,详细介绍两种常用的聚类算法:KMeans 和 DBSCAN,并使用 Python 的 scikit-learn 库进行实现。
题目要求
本次实战任务包含两个主要要求:
要求一:3D 可视化聚类结果
-
使用 Axes3D 将聚类结果显示在 3 维空间中
-
以花瓣宽度、萼片长度、花瓣长度分别作为 x,y,z 三个维度
-
直观展示数据的聚类分布情况
要求二:DBSCAN 算法实现
-
应用 sklearn 库中的 DBSCAN 算法进行聚类
-
使用 make_blobs 方法随机生成 750 条数据,包含 3 个类簇
-
对数据进行标准化处理(StandardScaler)
-
确保每个维度的方差为 1,均值为 0
-
避免某些维度过大的特征值主导预测结果
算法原理简介
KMeans 算法
KMeans 是一种基于距离的聚类算法,其基本思想是:
-
随机选择 K 个初始聚类中心
-
计算每个样本到各个聚类中心的距离
-
将样本分配到距离最近的聚类中心
-
更新每个聚类的中心(取该聚类所有样本的均值)
-
重复步骤 2-4,直到聚类中心不再显著变化或达到最大迭代次数
DBSCAN 算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法:
-
根据给定的半径 ε 和最小样本数 min_samples,识别核心点
-
核心点是指在其 ε 邻域内至少包含 min_samples 个样本的点
-
由核心点密度可达的所有点形成一个聚类
-
不属于任何核心点邻域的点被视为噪声点
完整代码实现
下面是完整的聚类算法实现代码,包含数据处理、算法实现、结果评估和可视化等功能模块。
# -*- coding: utf-8 -*-"""聚类算法示例代码功能:包含KMeans聚类Iris数据集、DBSCAN聚类模拟数据的完整流程,涵盖数据加载、预处理、聚类、评估和可视化功能"""# 通用库导入import numpy as npimport matplotlib.pyplot as pltfrom sklearn import metricsfrom sklearn.preprocessing import StandardScaler# ------------------------------# 模块1:通用配置# 功能:设置全局绘图样式,确保中文显示正常# ------------------------------def setup_plot_style():"""设置绘图样式,确保中文标签和负号正常显示"""plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文显示plt.rcParams['axes.unicode_minus'] = False # 负号显示plt.style.use('seaborn-v0_8-notebook') # 整体风格# ------------------------------# 模块2:数据处理# 功能:提供数据加载、生成和预处理功能,支持Iris数据集和模拟数据# ------------------------------def load_iris_data():"""加载Iris鸢尾花数据集返回:X (np.ndarray): 特征数据(4个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度)y (np.ndarray): 真实标签(3类)"""from sklearn import datasetsnp.random.seed(5) # 固定随机种子,保证结果可复现iris = datasets.load_iris()return iris.data, iris.targetdef generate_synthetic_data(centers=[[1, 1], [-1, -1], [1, -1]],n_samples=750,cluster_std=0.4,random_state=0):"""生成模拟聚类数据参数:centers: 聚类中心坐标列表n_samples: 样本总数cluster_std: 类内标准差(控制数据分散程度)random_state: 随机种子返回:X (np.ndarray): 生成的特征数据true_labels (np.ndarray): 真实聚类标签"""from sklearn.datasets import make_blobsX, true_labels = make_blobs(n_samples=n_samples,centers=centers,cluster_std=cluster_std,random_state=random_state)return X, true_labelsdef standardize_data(X):"""数据标准化处理(均值为0,方差为1)参数:X (np.ndarray): 原始特征数据返回:X_scaled (np.ndarray): 标准化后的特征数据"""return StandardScaler().fit_transform(X)# ------------------------------# 模块3:聚类算法# 功能:封装KMeans和DBSCAN两种聚类算法,提供统一接口# ------------------------------def kmeans_clustering(X, n_clusters=3, random_state=42):"""使用KMeans算法进行聚类参数:X (np.ndarray): 特征数据n_clusters: 聚类数量random_state: 随机种子返回:pred_labels (np.ndarray): 聚类预测标签"""from sklearn.cluster import KMeanskmeans = KMeans(n_clusters=n_clusters,n_init=10, # 多次初始化取最优结果,避免警告random_state=random_state)kmeans.fit(X)return kmeans.labels_def dbscan_clustering(X, eps=0.3, min_samples=10):"""使用DBSCAN算法进行聚类参数:X (np.ndarray): 特征数据eps: 邻域半径(核心点的范围)min_samples: 成为核心点所需的最小样本数(包括自身)返回:pred_labels (np.ndarray): 聚类预测标签(-1表示噪声点)core_samples_mask (np.ndarray): 核心样本掩码(True表示核心点)"""from sklearn.cluster import DBSCANdbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan.fit(X)# 生成核心样本掩码core_samples_mask = np.zeros_like(dbscan.labels_, dtype=bool)core_samples_mask[dbscan.core_sample_indices_] = Truereturn dbscan.labels_, core_samples_mask# ------------------------------# 模块4:聚类评估# 功能:计算聚类结果的关键评估指标,支持有真实标签和无真实标签场景# ------------------------------def evaluate_clustering(true_labels, pred_labels, X):"""评估聚类结果,计算关键指标参数:true_labels (np.ndarray): 真实标签(若为None则不计算同质性得分)pred_labels (np.ndarray): 预测标签X (np.ndarray): 特征数据(用于计算轮廓系数)返回:metrics_dict (dict): 包含评估指标的字典"""# 计算有效聚类数(排除噪声点)n_clusters = len(set(pred_labels)) - (1 if -1 in pred_labels else 0)# 计算噪声点数量n_noise = list(pred_labels).count(-1)metrics_dict = {"估计聚类数": n_clusters,"噪声点数量": n_noise,"轮廓系数": metrics.silhouette_score(X, pred_labels) # 评估聚类紧凑性和分离度}# 若有真实标签,计算同质性得分(衡量与真实标签的一致性)if true_labels is not None:metrics_dict["同质性得分"] = metrics.homogeneity_score(true_labels, pred_labels)return metrics_dict# ------------------------------# 模块5:可视化# 功能:提供3D和2D聚类结果可视化,支持不同聚类算法的结果展示# ------------------------------def visualize_kmeans_3d(X, labels,feature_indices=[3, 0, 2], # 选择展示的3个特征索引feature_names=['花瓣宽度', '萼片长度', '花瓣长度'],title="KMeans 3D聚类结果"):"""3D可视化KMeans聚类结果参数:X: 特征数据labels: 聚类标签feature_indices: 用于可视化的3个特征索引feature_names: 对应特征的名称title: 图表标题"""from mpl_toolkits.mplot3d import Axes3Dfig = plt.figure(figsize=(10, 6))ax = fig.add_subplot(111, projection='3d')# 绘制散点图ax.scatter(X[:, feature_indices[0]],X[:, feature_indices[1]],X[:, feature_indices[2]],c=labels.astype(np.float32),edgecolor='k',s=50 # 点大小)# 隐藏坐标轴刻度标签ax.xaxis.set_ticklabels([])ax.yaxis.set_ticklabels([])ax.zaxis.set_ticklabels([])# 设置坐标轴名称和标题(字体大小适中)ax.set_xlabel('花瓣宽度', fontsize=10)ax.set_ylabel('萼片长度', fontsize=10)ax.set_zlabel('花瓣长度', fontsize=10)ax.set_title("3类聚类结果", fontsize=12)# 调整视角和边距ax.dist = 10 # 视角距离plt.subplots_adjust(left=0.15, right=0.85, bottom=0.15, top=0.85)plt.show()def visualize_dbscan_2d(X, pred_labels, core_samples_mask, title="DBSCAN聚类结果"):"""2D可视化DBSCAN聚类结果(区分核心点、边界点和噪声点)参数:X: 特征数据pred_labels: 聚类标签core_samples_mask: 核心样本掩码title: 图表标题"""plt.figure(figsize=(8, 6))# 定义颜色(光谱色区分不同聚类)unique_labels = set(pred_labels)colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]for label, color in zip(unique_labels, colors):if label == -1:color = [0, 0, 0, 1] # 噪声点用黑色# 筛选该类别的样本class_mask = (pred_labels == label)# 绘制核心样本(圆圈,较大尺寸)core_samples = X[class_mask & core_samples_mask]plt.scatter(core_samples[:, 0], core_samples[:, 1],s=50, c=[color], marker='o',label=f'聚类{label}' if label != -1 else '噪声点')# 绘制边界样本(非核心样本,叉号,较小尺寸)boundary_samples = X[class_mask & ~core_samples_mask]plt.scatter(boundary_samples[:, 0], boundary_samples[:, 1],s=20, c=[color], marker='x')plt.title(title)plt.legend()plt.show()# ------------------------------# 模块6:主函数# 功能:串联各模块,分别演示KMeans和DBSCAN聚类流程# ------------------------------def main_kmeans_iris():"""演示KMeans聚类Iris数据集的完整流程"""# 1. 初始化配置setup_plot_style()# 2. 加载数据X, y_true = load_iris_data()print("Iris数据集加载完成,特征维度:", X.shape)# 3. 执行聚类pred_labels = kmeans_clustering(X, n_clusters=3)# 4. 可视化结果visualize_kmeans_3d(X, pred_labels,title="Iris数据集KMeans 3类聚类结果")def main_dbscan_synthetic():"""演示DBSCAN聚类模拟数据的完整流程"""# 1. 初始化配置setup_plot_style()# 2. 生成并预处理数据centers = [[1, 1], [-1, -1], [1, -1]]X, y_true = generate_synthetic_data(centers=centers, n_samples=750)X_scaled = standardize_data(X)print("模拟数据生成完成,标准化后维度:", X_scaled.shape)# 3. 执行聚类pred_labels, core_samples_mask = dbscan_clustering(X_scaled, eps=0.3, min_samples=10)# 4. 评估聚类结果metrics_dict = evaluate_clustering(y_true, pred_labels, X_scaled)print("nDBSCAN聚类评估结果:")for name, value in metrics_dict.items():print(f"{name}:{value:.3f}" if isinstance(value, float) else f"{name}:{value}")# 5. 可视化结果visualize_dbscan_2d(X_scaled, pred_labels, core_samples_mask,title=f"DBSCAN聚类结果(聚类数:{metrics_dict['估计聚类数']})")if __name__ == "__main__":# 运行KMeans聚类Iris数据集示例main_kmeans_iris()# 运行DBSCAN聚类模拟数据示例(取消注释即可运行)# main_dbscan_synthetic()
代码结构解析
模块 1:通用配置
setup_plot_style()函数用于设置全局绘图样式,确保中文标签和负号能够正常显示,为后续的可视化做好准备。
模块 2:数据处理
-
load_iris_data():加载经典的 Iris 鸢尾花数据集,包含 4 个特征和 3 个类别 -
generate_synthetic_data():使用 make_blobs 方法生成模拟聚类数据 -
standardize_data():对数据进行标准化处理,确保每个特征的均值为 0,方差为 1
模块 3:聚类算法
-
kmeans_clustering():实现 KMeans 聚类算法 -
dbscan_clustering():实现 DBSCAN 聚类算法,返回聚类标签和核心样本掩码
模块 4:聚类评估
evaluate_clustering()函数计算聚类结果的关键评估指标,包括:
-
估计聚类数
-
噪声点数量
-
轮廓系数(评估聚类质量)
-
同质性得分(与真实标签的一致性)
模块 5:可视化
-
visualize_kmeans_3d():3D 可视化 KMeans 聚类结果,按照题目要求使用花瓣宽度、萼片长度、花瓣长度作为三个维度 -
visualize_dbscan_2d():2D 可视化 DBSCAN 聚类结果,区分核心点、边界点和噪声点
模块 6:主函数
-
main_kmeans_iris():演示 KMeans 聚类 Iris 数据集的完整流程 -
main_dbscan_synthetic():演示 DBSCAN 聚类模拟数据的完整流程
运行结果说明
KMeans 聚类 Iris 数据集
当运行main_kmeans_iris()函数时,会:
-
加载 Iris 数据集(150 个样本,4 个特征)
-
使用 KMeans 算法将数据聚为 3 类
-
生成 3D 可视化图,展示聚类结果
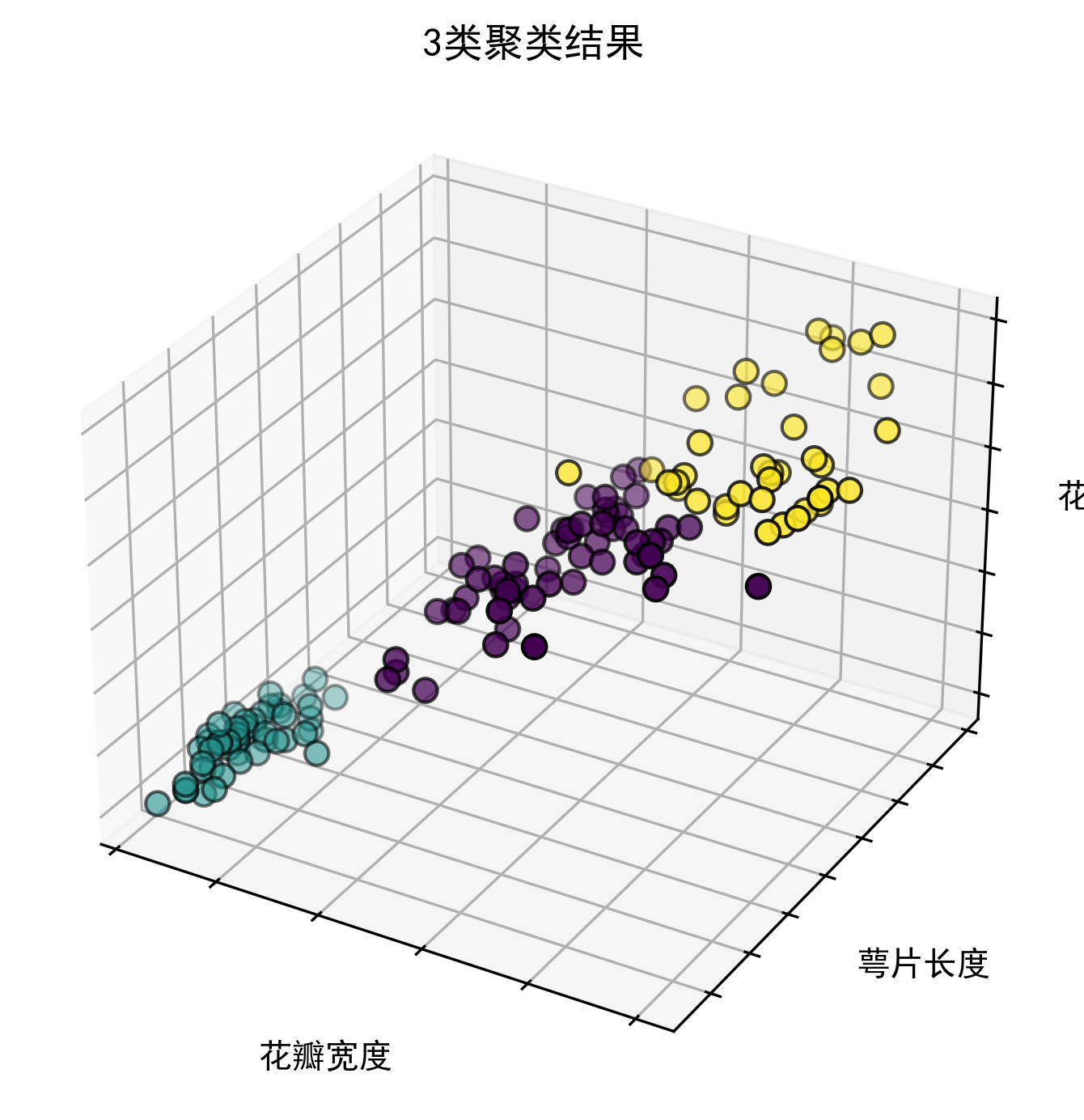
可视化结果将显示一个 3D 散点图,其中:
-
x 轴:花瓣宽度
-
y 轴:萼片长度
-
z 轴:花瓣长度
-
不同颜色代表不同的聚类结果
DBSCAN 聚类模拟数据
当运行main_dbscan_synthetic()函数时,会:
-
生成 750 条包含 3 个类簇的模拟数据
-
对数据进行标准化处理
-
使用 DBSCAN 算法进行聚类
-
输出聚类评估结果
-
生成 2D 可视化图,展示聚类结果
DBSCAN 的输出结果将包括:
-
估计的聚类数量
-
噪声点数量
-
同质性得分(与真实标签的一致性)
-
轮廓系数(聚类质量评估)
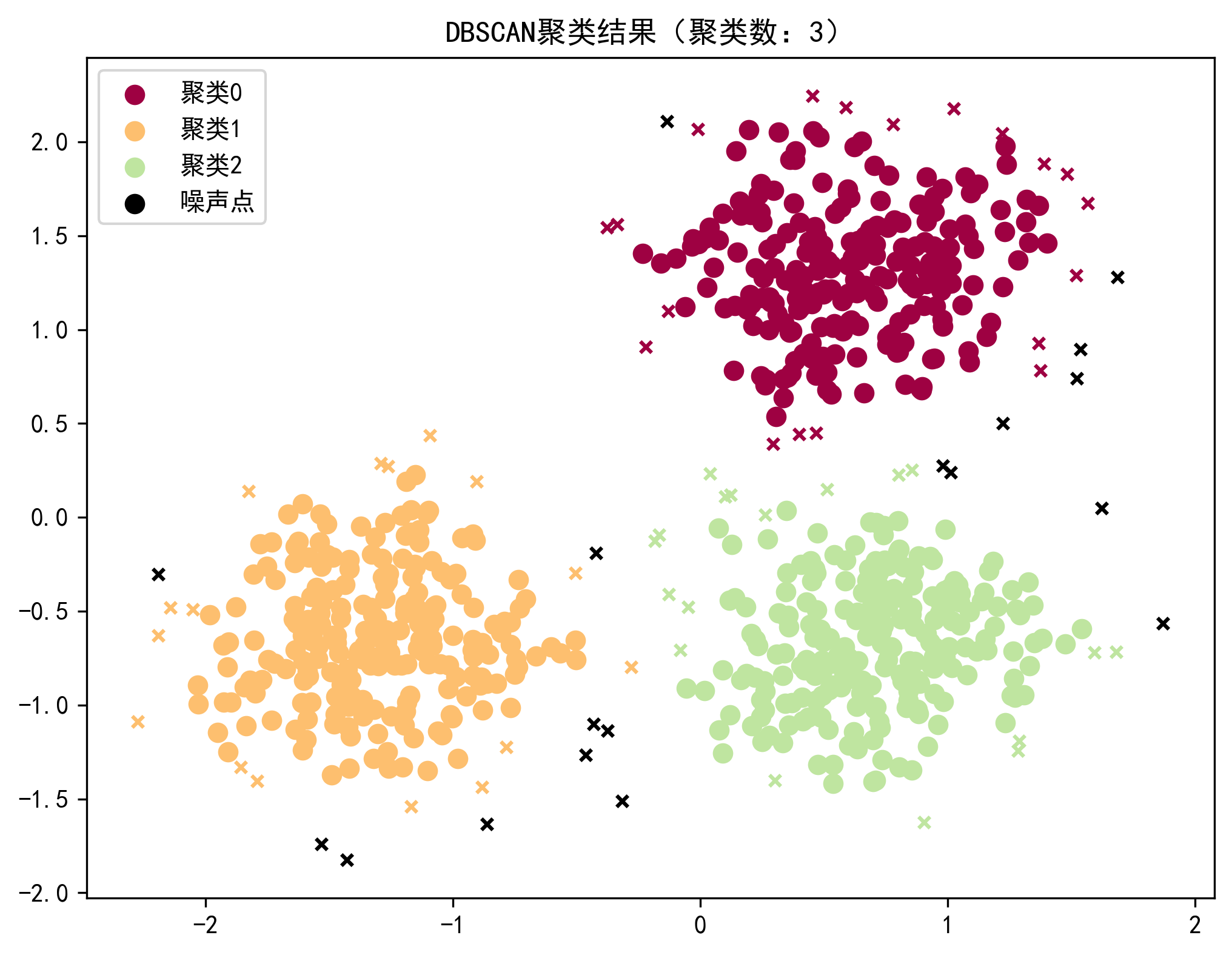
可视化结果将显示一个 2D 散点图,其中:
-
圆圈表示核心点
-
叉号表示边界点
-
黑色点表示噪声点
-
不同颜色代表不同的聚类
结果分析
KMeans 结果分析
KMeans 算法在 Iris 数据集上表现良好,能够将数据清晰地分为 3 个聚类。从 3D 可视化图中可以看出,不同类别的鸢尾花在特征空间中形成了明显的簇。
DBSCAN 结果分析
DBSCAN 算法能够自动发现数据中的聚类数量,而不需要预先指定。从结果中可以观察到:
-
算法成功识别出了 3 个主要聚类
-
识别出了少量噪声点(通常较少)
-
同质性得分接近 1,说明聚类结果与真实标签高度一致
-
轮廓系数较高,说明聚类质量良好
总结与扩展
算法对比
| 特点 | KMeans | DBSCAN |
|---|---|---|
| 聚类数量 | 需要预先指定 | 自动发现 |
| 聚类形状 | 球形簇 | 任意形状 |
| 噪声处理 | 不直接处理 | 明确识别噪声点 |
| 计算复杂度 | 较低(O (n)) | 较高(O (n²)) |
| 参数敏感性 | 对初始中心敏感 | 对 ε 和 min_samples 敏感 |
实际应用场景
- KMeans 适用场景:
-
大规模数据集
-
球形簇分布的数据
-
对算法速度要求较高的场景
- DBSCAN 适用场景:
-
任意形状的聚类
-
需要识别噪声的场景
-
数据分布密度不均匀的情况
改进建议
- 参数优化:
-
KMeans 可以尝试不同的聚类数量
-
DBSCAN 可以通过网格搜索优化 ε 和 min_samples 参数
- 特征工程:
-
尝试特征选择或降维方法
-
对数据进行更细致的预处理
- 算法扩展:
-
尝试其他聚类算法(如层次聚类、高斯混合模型等)
-
结合多种算法的优势
结语
本文详细介绍了 KMeans 和 DBSCAN 两种经典聚类算法的实现过程,并按照题目要求完成了 3D 可视化和数据标准化处理。通过实际案例,我们展示了聚类算法在数据探索和模式识别中的强大能力。
聚类算法作为无监督学习的重要分支,在数据挖掘、图像处理、推荐系统等领域有着广泛的应用。掌握这些基础算法,将为您的数据分析之旅提供强有力的工具支持。
希望本文能够帮助您更好地理解和应用聚类算法!