频繁读写文件,page cache不及时释放的后果
结果就是,k8s虚拟机器的内存会被慢慢耗尽,一旦整体可用内存不足,k8s会自动驱逐并重启pod
举例:
比如配置docker容器总内存3G,JVM 1.8G。用户从物理磁盘下载一个1.6G的视频文件,JVM不会内存溢出,但是整个容器内存不足。k8s会自动为该docker容器进行扩容,如果整个服务器也没有可用内存了,k8s会自动重启这个docker容器。
我遇到得不只是文件的下载上传,恶心的是:还要将1-200个pdf顺序下载下来,合并成一个文件!
如何解决:
1、k8s层面
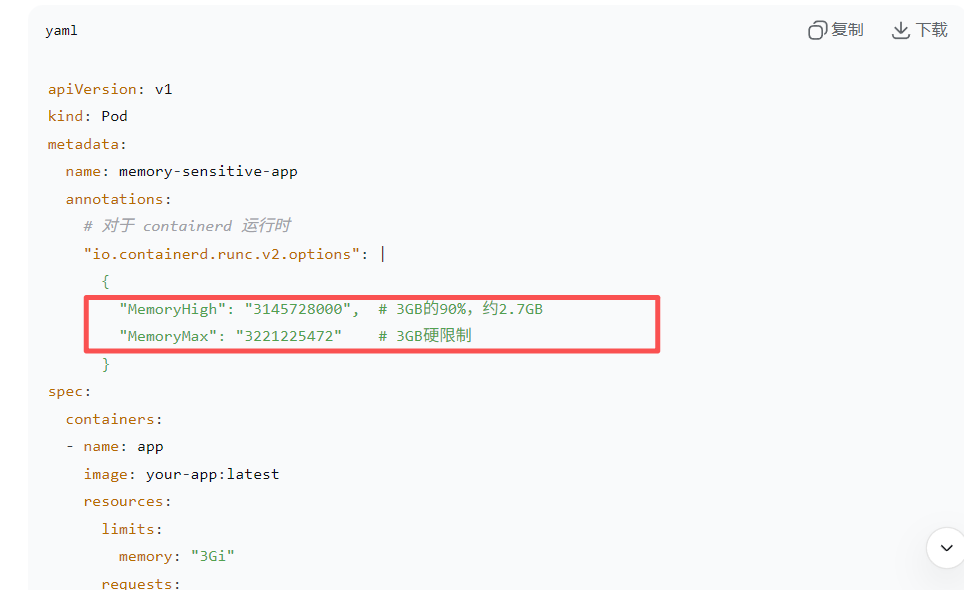
工作原理:当 Pod 内存使用(RSS + PageCache)超过 MemoryHigh 时,内核会优先回收该 Pod 的 PageCache,而不是直接触发 OOM。大可放心,它不会回收你当前正在使用的pagecache!
2、下载大文件用NIO
@GetMapping("/download/optimal/{filename}")
public void downloadOptimal(@PathVariable String filename,HttpServletResponse response) throws IOException {Path filePath = Paths.get("/data/files", filename);if (!Files.exists(filePath)) {response.setStatus(404);return;}// 设置响应头response.setContentType("application/octet-stream");response.setHeader("Content-Disposition", "attachment; filename=\"" + filename + "\"");response.setHeader("Content-Length", String.valueOf(Files.size(filePath)));// 使用零拷贝传输try (FileChannel channel = FileChannel.open(filePath, StandardOpenOption.READ);WritableByteChannel socketChannel = Channels.newChannel(response.getOutputStream())) {long transferred = 0;long size = Files.size(filePath);// 循环确保完整传输(可能一次transferTo无法传输完所有数据)while (transferred < size) {transferred += channel.transferTo(transferred, size - transferred, socketChannel);}}
}
显著减少 JVM 堆内存占用
3、pdfbox合并所有的pdf文件—>一个猛大的文件
原则:
1、文件太多的情况下,一定要分批处理,每处理完一批次,清理一批缓存。
2、用不到的文件一定要及时删除
public static File mulFilePdfToOne(List<File> files, String targetPath) {return mulFilePdfToOne(files, targetPath, 5); // 默认每批5个文件
}public static File mulFilePdfToOne(List<File> files, String targetPath, int batchSize) {log.info("pdf拼接开始, 总共{}个文件, 批次大小: {}", files.size(), batchSize);if (files.isEmpty()) {throw new IllegalArgumentException("文件列表不能为空");}// 单文件直接返回副本if (files.size() == 1) {try {return copySingleFile(files.get(0), targetPath);} catch (IOException e) {throw new RuntimeException("复制单文件失败: " + e.getMessage(), e);}}List<File> tempFiles = new ArrayList<>();List<File> sourceFiles = new ArrayList<>(); // 有效的源文件try {// 过滤有效的源文件for (File file : files) {if (file.exists() && file.isFile()) {sourceFiles.add(file);}}if (sourceFiles.isEmpty()) {throw new IllegalArgumentException("没有找到有效的PDF文件");}// 分批次合并List<List<File>> batches = createBatches(sourceFiles, batchSize); // 修复:List<List<File>>for (int i = 0; i < batches.size(); i++) {File batchResult = mergeBatch(batches.get(i), "temp_batch_" + i + ".pdf");tempFiles.add(batchResult);// 批次间内存优化if (i > 0) {optimizeMemory();}}// 合并所有临时文件return mergeBatch(tempFiles, targetPath);} catch (IOException e) {log.error("PDF拼接失败,已处理临时文件: {}", tempFiles.size(), e);// 保留原始文件,只清理临时文件cleanupTempFiles(tempFiles, targetPath);throw new RuntimeException("PDF合并失败: " + e.getMessage(), e);} finally {// 注意:原始代码中这里会删除源文件,现在移除了这个逻辑// 源文件删除应该由调用方控制}
}// 修复:返回 List<List<File>> 而不是 List<File>
private static List<List<File>> createBatches(List<File> files, int batchSize) {List<List<File>> batches = new ArrayList<>();for (int i = 0; i < files.size(); i += batchSize) {int end = Math.min(i + batchSize, files.size());// 修复:创建新的ArrayList,而不是强制转换batches.add(new ArrayList<>(files.subList(i, end)));}return batches;
}private static File mergeBatch(List<File> batchFiles, String outputPath) throws IOException {PDFMergerUtility mergePdf = new PDFMergerUtility();// 使用临时文件缓存,减少内存占用RandomAccessStreamCache.StreamCacheCreateFunction streamCache = IOUtils.createTempFileOnlyStreamCache();for (File file : batchFiles) {mergePdf.addSource(file);}mergePdf.setDestinationFileName(outputPath);mergePdf.mergeDocuments(streamCache);return new File(outputPath);
}private static void optimizeMemory() {// 提醒GC清理上一批次的内存System.gc();try {Thread.sleep(100); // 给GC一点时间} catch (InterruptedException e) {Thread.currentThread().interrupt();}
}// 修复:添加targetPath参数
private static void cleanupTempFiles(List<File> tempFiles, String targetPath) {for (File tempFile : tempFiles) {if (tempFile.exists() && !tempFile.getAbsolutePath().equals(targetPath)) {try {Files.delete(tempFile.toPath());log.debug("删除临时文件: {}", tempFile.getAbsolutePath());} catch (IOException e) {log.warn("删除临时文件失败: {}", tempFile.getAbsolutePath(), e);}}}
}private static File copySingleFile(File sourceFile, String targetPath) throws IOException {Files.copy(sourceFile.toPath(), Paths.get(targetPath), StandardCopyOption.REPLACE_EXISTING);return new File(targetPath);
}
合并过程的代码提供整体思路,不一定对。没有验证过。。。。