【完整源码+数据集+部署教程】【运动的&足球】足球比赛分析系统源码&数据集全套:改进yolo11-RFAConv
背景意义
随着足球运动的全球普及和竞技水平的不断提高,如何有效分析比赛过程中的关键要素,提升球队的战术决策能力,成为了体育科学研究的重要课题。传统的比赛分析方法往往依赖于人工观察和记录,效率低下且容易受到主观因素的影响。近年来,计算机视觉技术的快速发展为体育分析提供了新的解决方案,尤其是目标检测算法的应用,使得自动化分析成为可能。在此背景下,基于改进YOLOv11的足球比赛分析系统应运而生。
YOLO(You Only Look Once)系列算法因其高效的实时目标检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,结合了深度学习的先进技术,能够在复杂场景中快速准确地识别和定位目标。针对足球比赛的特点,本研究将利用YOLOv11对比赛中的球员和足球进行实时检测,从而为教练和分析师提供更为精确的数据支持。我们所使用的数据集包含1300张图像,涵盖了球员和足球这两个主要类别,能够为模型的训练和测试提供丰富的样本。
通过改进YOLOv11的网络结构和训练策略,我们期望提升模型在不同场景下的检测精度和速度,以适应快速变化的比赛环境。此外,本系统的开发不仅有助于提升比赛分析的自动化水平,还能为球队提供数据驱动的战术建议,帮助教练团队制定更为科学的训练和比赛策略。因此,基于改进YOLOv11的足球比赛分析系统的研究,具有重要的理论价值和实际应用意义,将为足球运动的智能化发展贡献一份力量。
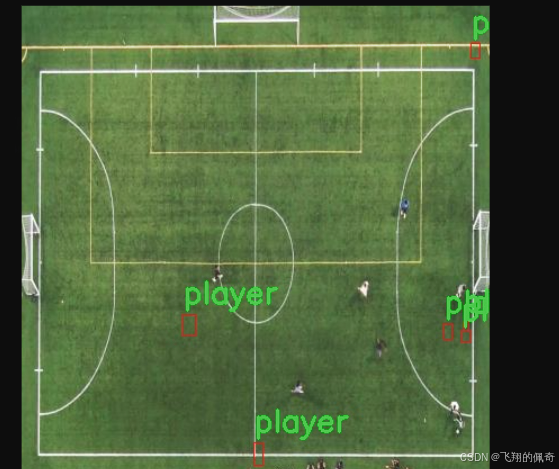
图片效果
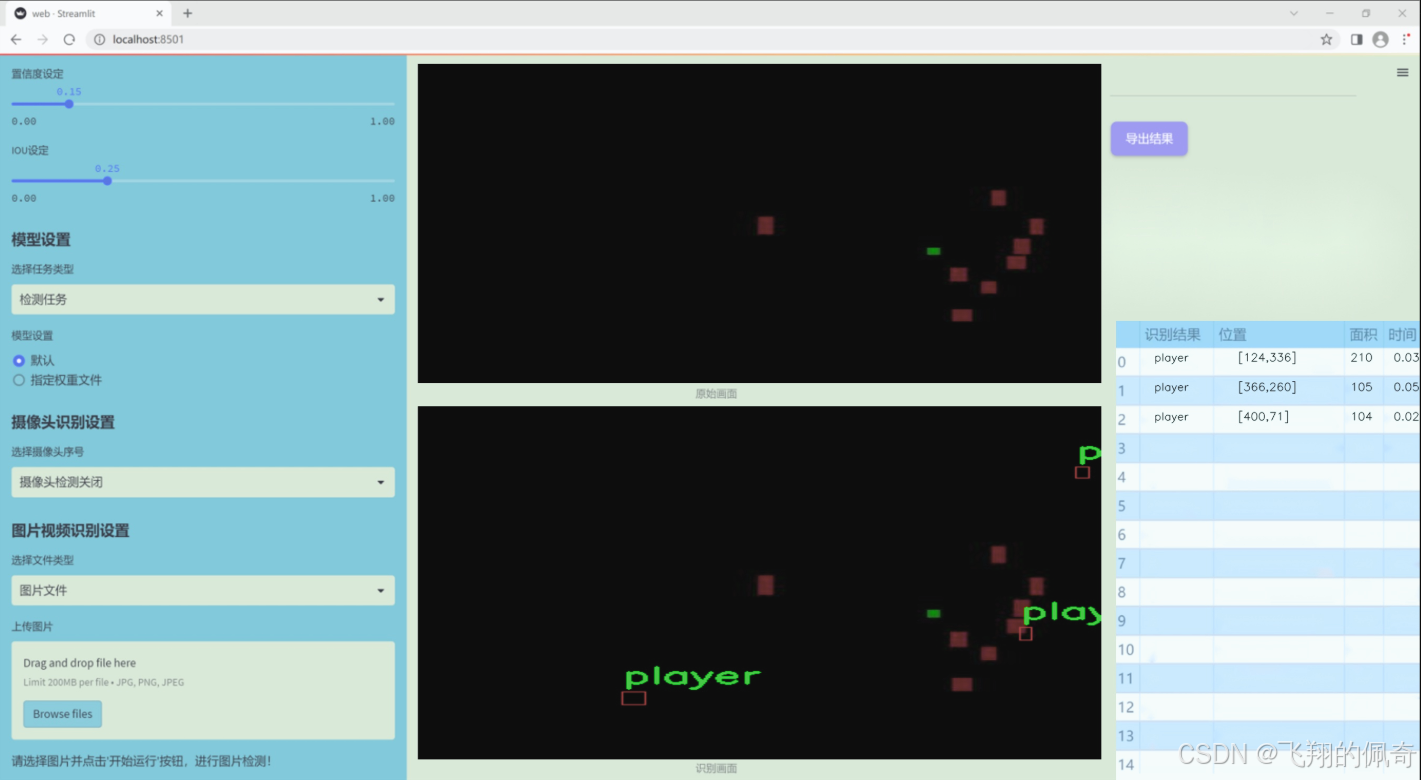
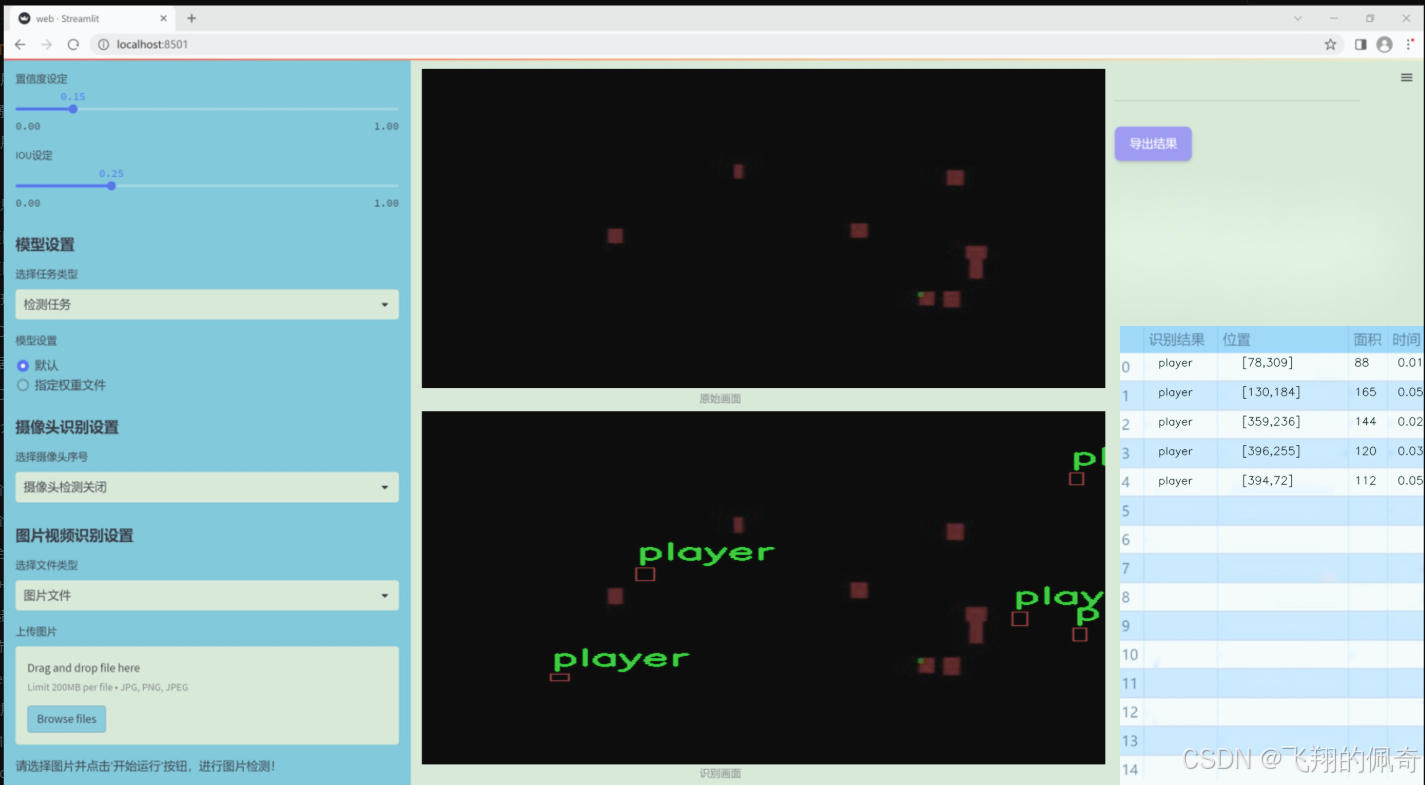
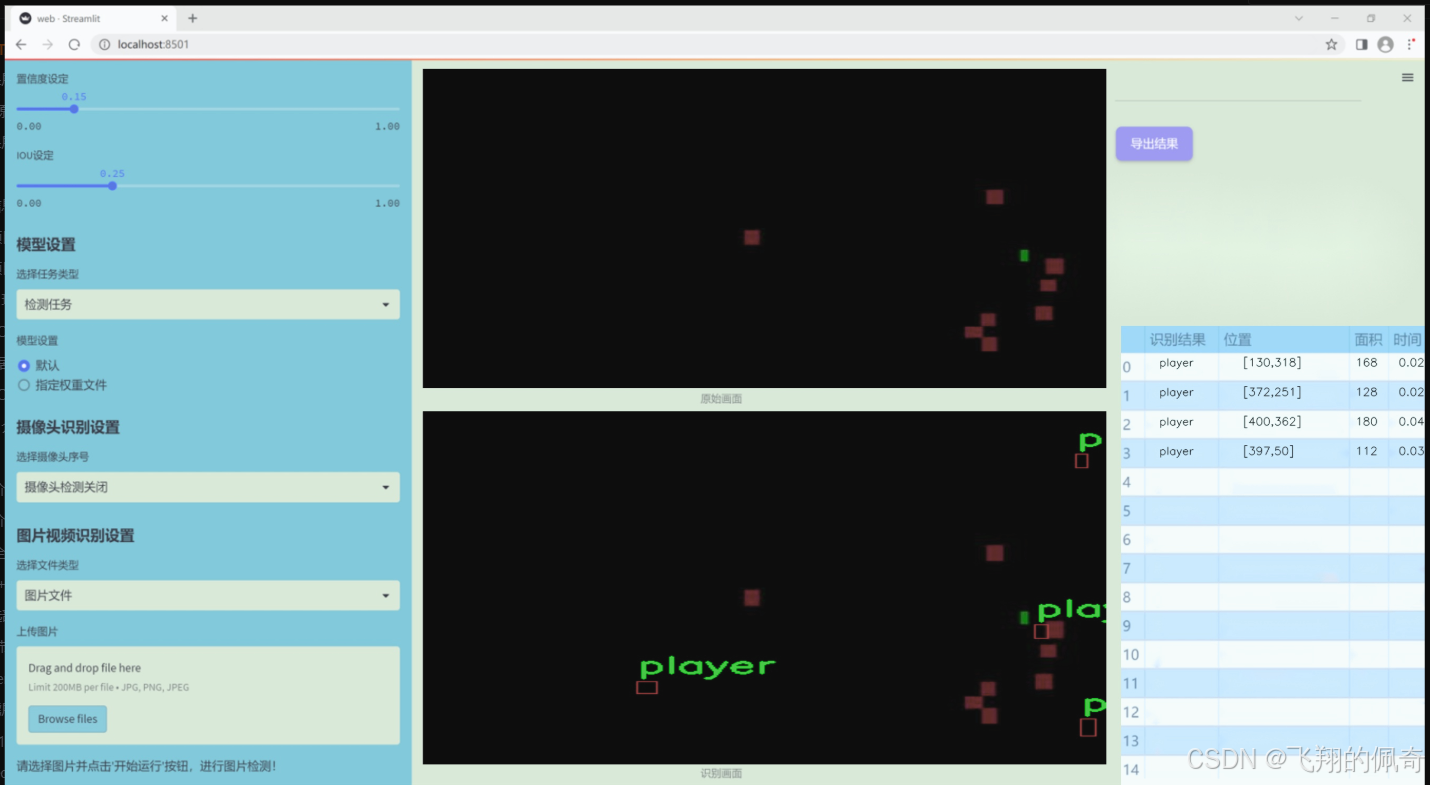
数据集信息
本项目所使用的数据集名为“Football_analytics”,旨在为改进YOLOv11的足球比赛分析系统提供支持。该数据集专注于足球比赛中的关键元素,具体包含两类对象:足球(ball)和球员(player)。数据集的类别数量为2,涵盖了足球比赛中最为重要的两个组成部分,这为系统的训练和测试提供了丰富的基础。
“Football_analytics”数据集经过精心标注,确保每个图像中的球和球员都被准确识别和分类。这种精确的标注不仅提高了模型的训练效率,也为后续的分析和应用提供了可靠的数据基础。数据集中的图像来源于不同的比赛场景,涵盖了多种光照条件、角度和距离,确保模型能够在各种实际情况下进行有效的识别和分析。
通过使用“Football_analytics”数据集,改进后的YOLOv11模型将能够更好地理解足球比赛中的动态场景,识别球员的运动轨迹以及足球的实时位置。这对于战术分析、比赛回放以及实时监控等应用场景具有重要意义。此外,数据集的设计考虑到了足球比赛的复杂性,使得模型在处理不同战术风格和比赛节奏时,能够展现出更高的鲁棒性和准确性。
总之,“Football_analytics”数据集为本项目提供了坚实的数据基础,使得改进YOLOv11的足球比赛分析系统能够在准确性和效率上达到新的高度,推动足球比赛分析技术的发展。




核心代码
以下是对代码中最核心部分的提取和详细注释。代码主要实现了一个频率感知特征融合的神经网络模块,用于密集图像预测。以下是精简后的代码和注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class FreqFusion(nn.Module):
def init(self, channels, scale_factor=1, lowpass_kernel=5, highpass_kernel=3):
“”"
初始化频率感知特征融合模块。
参数:- channels: 输入特征的通道数,格式为 (高分辨率通道数, 低分辨率通道数)- scale_factor: 上采样因子- lowpass_kernel: 低通滤波器的卷积核大小- highpass_kernel: 高通滤波器的卷积核大小"""super().__init__()hr_channels, lr_channels = channelsself.scale_factor = scale_factor# 压缩高分辨率和低分辨率特征通道self.hr_channel_compressor = nn.Conv2d(hr_channels, hr_channels // 8, kernel_size=1)self.lr_channel_compressor = nn.Conv2d(lr_channels, lr_channels // 8, kernel_size=1)# 低通滤波器卷积层self.content_encoder = nn.Conv2d(hr_channels // 8,lowpass_kernel ** 2,kernel_size=3,padding=1)# 高通滤波器卷积层self.content_encoder2 = nn.Conv2d(hr_channels // 8,highpass_kernel ** 2,kernel_size=3,padding=1)def forward(self, x):"""前向传播函数。参数:- x: 输入特征,格式为 (高分辨率特征, 低分辨率特征)返回:- 融合后的特征"""hr_feat, lr_feat = x# 压缩特征compressed_hr_feat = self.hr_channel_compressor(hr_feat)compressed_lr_feat = self.lr_channel_compressor(lr_feat)# 计算低通和高通特征lowpass_feat = self.content_encoder(compressed_hr_feat)highpass_feat = self.content_encoder2(compressed_hr_feat)# 融合特征fused_feat = lowpass_feat + highpass_feat# 上采样低分辨率特征lr_feat_upsampled = F.interpolate(lr_feat, scale_factor=self.scale_factor, mode='bilinear', align_corners=False)# 返回融合后的特征return fused_feat + lr_feat_upsampled
示例使用
channels = (高分辨率通道数, 低分辨率通道数)
model = FreqFusion(channels=(64, 32))
output = model((hr_input, lr_input))
代码说明
类 FreqFusion: 这是实现频率感知特征融合的核心类,继承自 nn.Module。
初始化方法 init:
接收输入通道数、上采样因子、低通和高通卷积核大小。
定义了高分辨率和低分辨率特征的压缩卷积层。
定义了用于生成低通和高通特征的卷积层。
前向传播方法 forward:
接收高分辨率和低分辨率特征。
压缩特征通道数。
计算低通和高通特征。
将低通和高通特征相加,得到融合特征。
对低分辨率特征进行上采样,并与融合特征相加,最终返回融合后的特征。
这个模块可以用于图像处理任务中,通过融合不同频率的特征来提高图像的预测精度。
该文件 FreqFusion.py 实现了一个名为 FreqFusion 的深度学习模块,主要用于密集图像预测中的频率感知特征融合。该模块结合了高通和低通滤波器的特性,以增强图像特征的表达能力,特别是在图像超分辨率等任务中。
首先,文件导入了必要的库,包括 PyTorch 和一些常用的神经网络模块。接着,定义了一些初始化函数,例如 normal_init 和 constant_init,用于初始化神经网络中的权重和偏置。
接下来,定义了一个 resize 函数,用于调整输入张量的大小,并在必要时发出警告。hamming2D 函数用于生成二维 Hamming 窗,主要用于后续的滤波操作。
FreqFusion 类是该文件的核心部分。在初始化方法中,类接受多个参数,包括通道数、缩放因子、低通和高通核的大小等。类内部定义了多个卷积层,用于对高分辨率和低分辨率特征进行压缩和编码。还包括一些用于特征重采样的选项,如 feature_resample 和 comp_feat_upsample。
在 init_weights 方法中,所有卷积层的权重被初始化为 Xavier 分布或正态分布,以确保网络的良好收敛性。
kernel_normalizer 方法用于对生成的掩码进行归一化处理,确保其和为1,以便在后续的卷积操作中使用。
forward 方法是模块的前向传播逻辑,接受高分辨率和低分辨率特征作为输入。根据不同的配置,模块会使用高通和低通滤波器来处理特征,并结合不同的卷积操作生成最终的输出特征。
在 _forward 方法中,具体实现了特征的压缩、掩码的生成以及特征的融合。该方法还考虑了是否使用半卷积(semi_conv)以及是否进行特征重采样(feature_resample)。通过使用 CARAFE(Content-Aware ReAssembly of FEatures)操作,模块能够有效地对特征进行上采样和融合。
LocalSimGuidedSampler 类实现了一个偏移生成器,用于在特征重采样过程中生成局部相似性引导的偏移量。该类包含了计算相似性的逻辑,并在前向传播中使用这些偏移量对特征进行采样。
最后,compute_similarity 函数用于计算输入张量中每个点与其周围点的余弦相似度,以帮助生成更为精确的特征重采样。
整体来看,该文件实现了一个复杂的频率感知特征融合模块,能够有效地处理图像特征并提高图像预测的精度,适用于图像超分辨率等任务。
10.2 shiftwise_conv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias):
“”"
创建一个2D卷积层
“”"
return nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias
)
def get_bn(channels):
“”"
创建一个批归一化层
“”"
return nn.BatchNorm2d(channels)
class Mask(nn.Module):
“”"
定义一个Mask类,用于生成可学习的权重掩码
“”"
def init(self, size):
super().init()
# 初始化权重参数,范围在-1到1之间
self.weight = torch.nn.Parameter(data=torch.Tensor(*size), requires_grad=True)
self.weight.data.uniform_(-1, 1)
def forward(self, x):# 使用sigmoid函数对权重进行归一化w = torch.sigmoid(self.weight)# 将输入x与权重w相乘,得到掩码后的输出masked_wt = w.mul(x)return masked_wt
class ReparamLargeKernelConv(nn.Module):
“”"
定义一个重参数化的大卷积核类
“”"
def init(self, in_channels, out_channels, kernel_size, small_kernel=5, stride=1, groups=1, small_kernel_merged=False, Decom=True, bn=True):
super(ReparamLargeKernelConv, self).init()
self.kernel_size = kernel_size
self.small_kernel = small_kernel
self.Decom = Decom
padding = kernel_size // 2 # 假设卷积不会改变特征图的大小,设置padding为kernel_size的一半
# 根据是否合并小卷积核,选择不同的卷积结构if small_kernel_merged:self.lkb_reparam = get_conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,dilation=1,groups=groups,bias=True,)else:if self.Decom:self.LoRA = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=(kernel_size, small_kernel),stride=stride,padding=padding,dilation=1,groups=groups,bn=bn)else:self.lkb_origin = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,dilation=1,groups=groups,bn=bn,)if (small_kernel is not None) and small_kernel < kernel_size:self.small_conv = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=small_kernel,stride=stride,padding=small_kernel // 2,groups=groups,dilation=1,bn=bn,)self.bn = get_bn(out_channels) # 创建批归一化层self.act = nn.SiLU() # 使用SiLU激活函数def forward(self, inputs):"""前向传播函数"""if hasattr(self, "lkb_reparam"):out = self.lkb_reparam(inputs) # 使用重参数化的卷积elif self.Decom:out = self.LoRA(inputs) # 使用LoRA结构if hasattr(self, "small_conv"):out += self.small_conv(inputs) # 加上小卷积的输出else:out = self.lkb_origin(inputs) # 使用原始卷积if hasattr(self, "small_conv"):out += self.small_conv(inputs) # 加上小卷积的输出return self.act(self.bn(out)) # 返回经过激活和归一化的输出def get_equivalent_kernel_bias(self):"""获取等效的卷积核和偏置"""eq_k, eq_b = fuse_bn(self.lkb_origin.conv, self.lkb_origin.bn) # 融合卷积和批归一化if hasattr(self, "small_conv"):small_k, small_b = fuse_bn(self.small_conv.conv, self.small_conv.bn)eq_b += small_b # 更新偏置eq_k += nn.functional.pad(small_k, [(self.kernel_size - self.small_kernel) // 2] * 4) # 对小卷积核进行填充return eq_k, eq_bdef switch_to_deploy(self):"""切换到部署模式"""if hasattr(self, 'lkb_origin'):eq_k, eq_b = self.get_equivalent_kernel_bias() # 获取等效卷积核和偏置self.lkb_reparam = get_conv2d(in_channels=self.lkb_origin.conv.in_channels,out_channels=self.lkb_origin.conv.out_channels,kernel_size=self.lkb_origin.conv.kernel_size,stride=self.lkb_origin.conv.stride,padding=self.lkb_origin.conv.padding,dilation=self.lkb_origin.conv.dilation,groups=self.lkb_origin.conv.groups,bias=True,)self.lkb_reparam.weight.data = eq_k # 设置卷积核权重self.lkb_reparam.bias.data = eq_b # 设置偏置self.__delattr__("lkb_origin") # 删除原始卷积属性if hasattr(self, "small_conv"):self.__delattr__("small_conv") # 删除小卷积属性
代码核心部分说明:
Mask类:用于生成可学习的权重掩码,利用sigmoid函数将权重限制在0到1之间,并与输入相乘以实现特征选择。
ReparamLargeKernelConv类:实现了一个重参数化的大卷积核结构,支持不同的卷积核大小组合,并能够在前向传播中动态选择使用的卷积层。
前向传播:根据初始化时的设置,选择使用重参数化卷积、LoRA结构或原始卷积,并将小卷积的输出加到主输出上。
融合BN:在获取等效卷积核和偏置时,考虑了批归一化的影响,使得在部署时可以直接使用融合后的卷积核和偏置,提高推理效率。
这个程序文件 shiftwise_conv.py 实现了一个用于深度学习中的卷积操作的模块,特别是处理大核卷积的重参数化和低秩适应(LoRA)卷积。以下是对代码的详细讲解。
首先,文件导入了必要的库,包括 math、torch 及其子模块 nn 和 functional。接着,定义了一个公共接口 all,指定了模块中可以被外部调用的类或函数,这里只有 ReparamLargeKernelConv。
get_conv2d 函数用于创建一个标准的二维卷积层,接收输入通道数、输出通道数、卷积核大小、步幅、填充、扩张率、分组数和是否使用偏置等参数。它会根据给定的卷积核大小计算填充,并返回一个 nn.Conv2d 对象。
get_bn 函数则是创建一个批归一化层,接收通道数作为参数。
Mask 类是一个自定义的 PyTorch 模块,用于生成一个可学习的掩码。它的构造函数初始化了一个权重参数,并在前向传播中通过 Sigmoid 函数将其转化为一个介于 0 和 1 之间的值,然后与输入进行逐元素相乘。
conv_bn_ori 函数用于构建一个包含卷积层和可选的批归一化层的序列。它根据输入参数创建卷积层,并在需要时添加批归一化层。
LoRAConvsByWeight 类实现了基于权重的低秩适应卷积。它在构造函数中初始化了多个卷积层和掩码,并在前向传播中对输入进行处理。该类的核心是 forward_lora 方法,它根据输入的形状和参数对输出进行重排和处理。
rearrange_data 方法负责根据给定的索引和方向(水平或垂直)对数据进行重排,计算填充并调整输出的形状。
shift 方法计算填充和窗口索引,以确保卷积操作不会改变特征图的大小。
conv_bn 函数是一个封装函数,根据卷积核的类型(单一大小或一对大小)调用相应的卷积和批归一化函数。
fuse_bn 函数用于将卷积层和批归一化层融合,生成等效的卷积核和偏置,以便在推理时提高效率。
ReparamLargeKernelConv 类是整个模块的核心,支持重参数化的大核卷积。它在构造函数中初始化了卷积层、批归一化层和激活函数,并根据参数配置选择不同的卷积结构。在前向传播中,它根据不同的条件计算输出,并通过激活函数和批归一化层进行处理。
get_equivalent_kernel_bias 方法用于获取等效的卷积核和偏置,switch_to_deploy 方法则在推理阶段替换卷积层,以便使用融合后的卷积核和偏置。
整体来看,这个文件实现了一个灵活且高效的卷积模块,能够处理不同大小的卷积核,并支持在训练和推理阶段的不同优化策略。
10.3 predict.py
以下是经过简化和注释的核心代码部分:
导入必要的模块
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
“”"
扩展自 BasePredictor 类,用于基于检测模型进行预测的类。
“”"
def postprocess(self, preds, img, orig_imgs):"""对预测结果进行后处理,并返回一个 Results 对象的列表。参数:preds: 模型的预测结果img: 输入图像orig_imgs: 原始图像列表或张量返回:results: 包含处理后结果的 Results 对象列表"""# 应用非极大值抑制(NMS)来过滤重叠的框preds = ops.non_max_suppression(preds,self.args.conf, # 置信度阈值self.args.iou, # IOU 阈值agnostic=self.args.agnostic_nms, # 是否类别无关的 NMSmax_det=self.args.max_det, # 最大检测框数量classes=self.args.classes, # 需要检测的类别)# 如果输入的原始图像不是列表,则将其转换为 numpy 数组if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = [] # 存储处理后的结果for i, pred in enumerate(preds):orig_img = orig_imgs[i] # 获取对应的原始图像# 将预测框的坐标缩放到原始图像的尺寸pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i] # 获取图像路径# 创建 Results 对象并添加到结果列表中results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results # 返回处理后的结果列表
代码说明:
导入模块:引入了进行预测和结果处理所需的模块。
DetectionPredictor 类:该类继承自 BasePredictor,用于实现目标检测的预测功能。
postprocess 方法:这是一个关键方法,负责对模型的预测结果进行后处理。
使用非极大值抑制(NMS)来去除重叠的检测框。
检查原始图像是否为列表,如果不是,则将其转换为 NumPy 数组。
遍历每个预测结果,缩放预测框到原始图像的尺寸,并创建 Results 对象以存储每个图像的预测结果。
返回结果:最终返回一个包含所有处理后结果的列表。
这个程序文件 predict.py 是一个用于目标检测的预测模块,基于 Ultralytics YOLO(You Only Look Once)模型构建。文件中定义了一个名为 DetectionPredictor 的类,它继承自 BasePredictor 类,主要用于处理基于检测模型的预测任务。
在类的文档字符串中,提供了一个示例,展示了如何使用 DetectionPredictor 类进行预测。示例中,首先从 ultralytics.utils 导入了 ASSETS,然后通过指定模型文件和数据源来创建 DetectionPredictor 的实例,最后调用 predict_cli() 方法进行预测。
DetectionPredictor 类中有一个重要的方法 postprocess,该方法负责对模型的预测结果进行后处理。具体来说,它接收三个参数:preds(模型的预测结果)、img(输入图像)和 orig_imgs(原始图像)。在方法内部,首先调用 ops.non_max_suppression 函数对预测结果进行非极大值抑制,以过滤掉冗余的检测框。这个过程使用了一些参数,如置信度阈值、IOU(Intersection over Union)阈值、是否进行类别无关的非极大值抑制、最大检测框数量以及指定的类别。
接下来,方法检查 orig_imgs 是否为列表,如果不是,则将其转换为 NumPy 数组,以便后续处理。然后,方法遍历每个预测结果,并对检测框进行缩放,以适应原始图像的尺寸。最后,将每个原始图像、图像路径、模型名称和检测框信息封装成 Results 对象,并将其添加到结果列表中。
最终,postprocess 方法返回一个包含所有处理后结果的列表。这些结果可以用于后续的分析或可视化,帮助用户理解模型的检测性能和结果。
10.4 SMPConv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
定义相对位置的函数,生成一个包含相对位置坐标的张量
def rel_pos(kernel_size):
tensors = [torch.linspace(-1, 1, steps=kernel_size) for _ in range(2)]
kernel_coord = torch.stack(torch.meshgrid(*tensors), dim=-0) # 生成网格坐标
kernel_coord = kernel_coord.unsqueeze(0) # 增加一个维度
return kernel_coord
定义SMPConv类,继承自nn.Module
class SMPConv(nn.Module):
def init(self, planes, kernel_size, n_points, stride, padding, groups):
super().init()
self.planes = planes # 输出通道数self.kernel_size = kernel_size # 卷积核大小self.n_points = n_points # 关键点数量self.init_radius = 2 * (2/kernel_size) # 初始化半径# 生成卷积核坐标kernel_coord = rel_pos(kernel_size)self.register_buffer('kernel_coord', kernel_coord) # 注册为缓冲区# 初始化权重坐标weight_coord = torch.empty(1, n_points, 2)nn.init.trunc_normal_(weight_coord, std=0.2, a=-1., b=1.) # 使用截断正态分布初始化self.weight_coord = nn.Parameter(weight_coord) # 将其作为可学习参数# 初始化半径参数self.radius = nn.Parameter(torch.empty(1, n_points).unsqueeze(-1).unsqueeze(-1))self.radius.data.fill_(value=self.init_radius) # 填充初始值# 初始化权重weights = torch.empty(1, planes, n_points)nn.init.trunc_normal_(weights, std=.02) # 使用截断正态分布初始化self.weights = nn.Parameter(weights) # 将其作为可学习参数def forward(self, x):kernels = self.make_kernels().unsqueeze(1) # 生成卷积核x = x.contiguous() # 确保输入张量在内存中是连续的kernels = kernels.contiguous() # 确保卷积核在内存中是连续的# 根据输入数据类型选择不同的卷积实现if x.dtype == torch.float32:x = _DepthWiseConv2dImplicitGEMMFP32.apply(x, kernels) # 使用FP32实现elif x.dtype == torch.float16:x = _DepthWiseConv2dImplicitGEMMFP16.apply(x, kernels) # 使用FP16实现else:raise TypeError("Only support fp32 and fp16, get {}".format(x.dtype)) # 抛出异常return x def make_kernels(self):# 计算卷积核diff = self.weight_coord.unsqueeze(-2) - self.kernel_coord.reshape(1, 2, -1).transpose(1, 2) # 计算坐标差diff = diff.transpose(2, 3).reshape(1, self.n_points, 2, self.kernel_size, self.kernel_size) # 重塑形状diff = F.relu(1 - torch.sum(torch.abs(diff), dim=2) / self.radius) # 计算ReLU激活后的差值# 计算最终的卷积核kernels = torch.matmul(self.weights, diff.reshape(1, self.n_points, -1)) # 计算加权卷积核kernels = kernels.reshape(1, self.planes, *self.kernel_coord.shape[2:]) # 重塑形状kernels = kernels.squeeze(0) # 去掉多余的维度kernels = torch.flip(kernels.permute(0, 2, 1), dims=(1,)) # 反转卷积核的维度return kernelsdef radius_clip(self, min_radius=1e-3, max_radius=1.):# 限制半径的范围r = self.radius.datar = r.clamp(min_radius, max_radius) # 限制在[min_radius, max_radius]之间self.radius.data = r # 更新半径
定义SMPCNN类,继承自nn.Module
class SMPCNN(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride, groups, n_points=None, n_points_divide=4):
super().init()
self.kernel_size = kernel_size
if n_points is None:
n_points = int((kernel_size**2) // n_points_divide) # 计算n_points
padding = kernel_size // 2 # 计算填充self.smp = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=1, groups=groups, n_points=n_points)self.small_kernel = 5 # 小卷积核大小self.small_conv = Conv(in_channels, out_channels, self.small_kernel, stride, self.small_kernel // 2, groups, act=False) # 小卷积层def forward(self, inputs):out = self.smp(inputs) # 通过SMP卷积层out += self.small_conv(inputs) # 加上小卷积层的输出return out # 返回结果
代码说明:
SMPConv:自定义的卷积层,使用了相对位置编码和动态卷积核生成。它根据输入的特征图和卷积核坐标计算卷积结果。
SMPCNN:组合了SMPConv和小卷积层的网络结构,通过两个不同大小的卷积核来提取特征,增强模型的表达能力。
make_kernels:生成卷积核的核心函数,通过计算权重坐标与卷积核坐标的差异来生成动态卷积核。
以上代码片段是实现自定义卷积操作的核心部分,结合了动态卷积核生成和小卷积层的特性,适用于深度学习中的图像处理任务。
这个程序文件 SMPConv.py 实现了一种特殊的卷积神经网络模块,主要包含了 SMPConv、SMPCNN、SMPCNN_ConvFFN 和 SMPBlock 等类。程序使用了 PyTorch 框架,并结合了一些自定义的卷积操作和模块。
首先,文件导入了必要的库,包括 PyTorch 的核心模块和一些自定义的模块。SMPConv 类是文件的核心,主要实现了一种新的卷积操作。其构造函数中,初始化了一些参数,如输出通道数、卷积核大小、点数、步幅和填充等。rel_pos 函数用于生成卷积核的相对位置坐标,make_kernels 方法则根据权重和位置坐标生成卷积核。
在 forward 方法中,输入数据通过 make_kernels 生成的卷积核进行卷积操作。这里使用了两种不同精度的深度卷积实现,分别对应于 FP32 和 FP16 数据类型,确保了在不同精度下的高效计算。
radius_clip 方法用于限制半径的范围,防止其超出设定的最小和最大值。
接下来,文件定义了一些辅助函数,如 get_conv2d、get_bn 和 conv_bn 等,这些函数用于创建卷积层和批归一化层,并提供了一些条件判断,以便在特定情况下使用 SMPConv 替代标准卷积。
SMPCNN 类则将 SMPConv 和一个小卷积层结合在一起,通过跳跃连接的方式增强特征提取能力。SMPCNN_ConvFFN 类实现了一个前馈网络,包含了两个逐点卷积层和一个非线性激活函数 GELU,同时也支持 DropPath 机制以提高模型的鲁棒性。
最后,SMPBlock 类结合了逐点卷积和大卷积核的操作,形成一个完整的模块。它首先通过批归一化处理输入,然后进行一系列卷积操作,最后通过跳跃连接将输入与输出相加,形成残差结构。
总体来说,这个文件实现了一种新型的卷积模块,旨在提高卷积神经网络的性能和灵活性,适用于各种计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻