Java-157 MongoDB 存储引擎 WiredTiger vs InMemory:何时用、怎么配、如何验证 mongod.conf
TL;DR
场景:需要给团队一份能直接落地的 MongoDB 存储引擎指南,覆盖配置、校验与常见坑。
结论:生产默认用 WiredTiger;journaling 在 6.1+ 始终启用;WT checkpoint≈60s;缓存默认 max(50%×(RAM−1GB), 256MB);directoryPerDB 与 directoryForIndexes 位置不同。InMemory 仅企业版。
产出:两段可用配置(WT/InMemory)、一组校验命令(确认引擎/缓存/目录生效)。

存储引擎
基本概述
存储引擎是MongoDB数据库系统的核心组件,负责管理数据在内存和硬盘上的存储方式,以及处理数据的读写操作。不同的存储引擎采用不同的数据结构、索引方式和存储策略,直接影响数据库的性能、可靠性和资源消耗。
| 组件 | 已验证版本 | 重点差异 |
|---|---|---|
| MongoDB 社区/企业 | 6.0 / 7.0 / 8.0 | 6.1+版本起journaling永久启用,storage.journal.enabled选项及--journal/--nojournal参数被移除。 |
| 引擎 | WiredTiger / InMemory(Enterprise) | InMemory引擎仅限企业版,数据在进程退出后丢失;默认占用内存为50%RAM−1GB,可通过inMemorySizeGB指定。 |
| 兼容性 | 4.2+ | 4.2版本移除MMAPv1引擎;3.2版本起默认使用WiredTiger引擎。 |
验证引擎
我们可以先验证引擎与参数:
// 1) 看当前引擎
db.serverStatus().storageEngine // 期望: { name: "wiredTiger", ... }// 2) 看 WT cache(GB 或 %)
db.serverStatus().wiredTiger.cache['maximum bytes configured']
// 按公式 ≈ max(50% × (RAM-1GB), 256MB)。 [oai_citation:9‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)// 3) 校验目录策略
// 启用 directoryPerDB 后,dbPath 下应出现每库独立目录;
// 启用 directoryForIndexes 后,应出现 dataPath/{collection,index} 子目录。 [oai_citation:10‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)
MongoDB支持的存储引擎类型
1. MMAPV1存储引擎
- 历史最悠久的MongoDB默认存储引擎(4.2版本前)
- 采用内存映射文件机制
- 使用集合级锁(collection-level locking)
2. WiredTiger存储引擎
- MongoDB 3.2版本后的默认存储引擎
- 提供文档级并发控制(document-level concurrency control)
- 支持数据压缩和加密
- 采用多版本并发控制(MVCC)机制
3. InMemory存储引擎
- 企业版专有功能(MongoDB Enterprise Advanced)
- 完全基于内存的存储解决方案
- 主要特点:
- 所有数据(除少量元数据外)常驻内存
- 不进行持久化磁盘I/O操作
- 查询延迟极低(通常在微秒级)
- 适合对延迟极其敏感的应用场景
InMemory
配置文件如下所示:
# mongod.conf (InMemory / Enterprise)
storage:engine: inMemorydbPath: /var/lib/mongoinMemory:engineConfig:inMemorySizeGB: 8 # 默认≈50%RAM−1GB,可自定义 [oai_citation:18‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)
数据存储机制
- 内存驻留:所有文档、索引和操作数据都保持在RAM中
- 磁盘存储内容:
- 配置元数据(约几MB)
- 操作日志(oplog)用于复制
- 诊断日志和性能指标
- 持久化标识符和集合信息
性能优势
- 极低延迟:典型查询响应时间在100-500微秒之间
- 高吞吐量:可支持每秒数十万次操作
- 无磁盘争用:避免了传统存储引擎的I/O瓶颈
适用场景
- 实时分析系统:需要亚毫秒级响应的OLAP查询
- 高速缓存层:作为应用和主数据库之间的缓存
- 会话存储:需要快速访问的临时用户会话数据
- 金融交易系统:高频交易等对延迟敏感的应用
- 物联网数据处理:大量设备产生的实时数据流
配置注意事项
- 需要足够大的物理内存容纳数据集
- 建议配置为副本集成员以确保高可用性
- 可通过
--inMemorySizeGB参数限制内存使用量 - 监控内存使用情况至关重要
WiredTiger
配置文件如下所示:
# mongod.conf (WiredTiger)
storage:dbPath: /data/mongodirectoryPerDB: true # 每库独立目录(不支持 InMemory) [oai_citation:11‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)engine: wiredTigerwiredTiger:engineConfig:cacheSizeGB: 2 # 或用 cacheSizePct(二者只能选一个) [oai_citation:12‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)directoryForIndexes: true # 索引单独目录(可配符号链接迁移) [oai_citation:13‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)journalCompressor: snappy # none|snappy|zlib|zstd(默认 snappy) [oai_citation:14‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)collectionConfig:blockCompressor: zstd # snappy|zlib|zstd|none(时间序列默认 zstd) [oai_citation:15‡mongodb.com](https://www.mongodb.com/docs/manual/core/wiredtiger/)indexConfig:prefixCompression: true # 索引前缀压缩(默认启用) [oai_citation:16‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)# 6.1+ 不需要(也不支持)storage.journal.enabled
# 如需,仍可调 commitIntervalMs:
# storage:
# journal:
# commitIntervalMs: 100 # 默认 100ms(WT) [oai_citation:17‡mongodb.com](https://www.mongodb.com/docs/manual/reference/configuration-options/)
以下是扩展后的内容,增加了更多技术细节和应用场景说明:
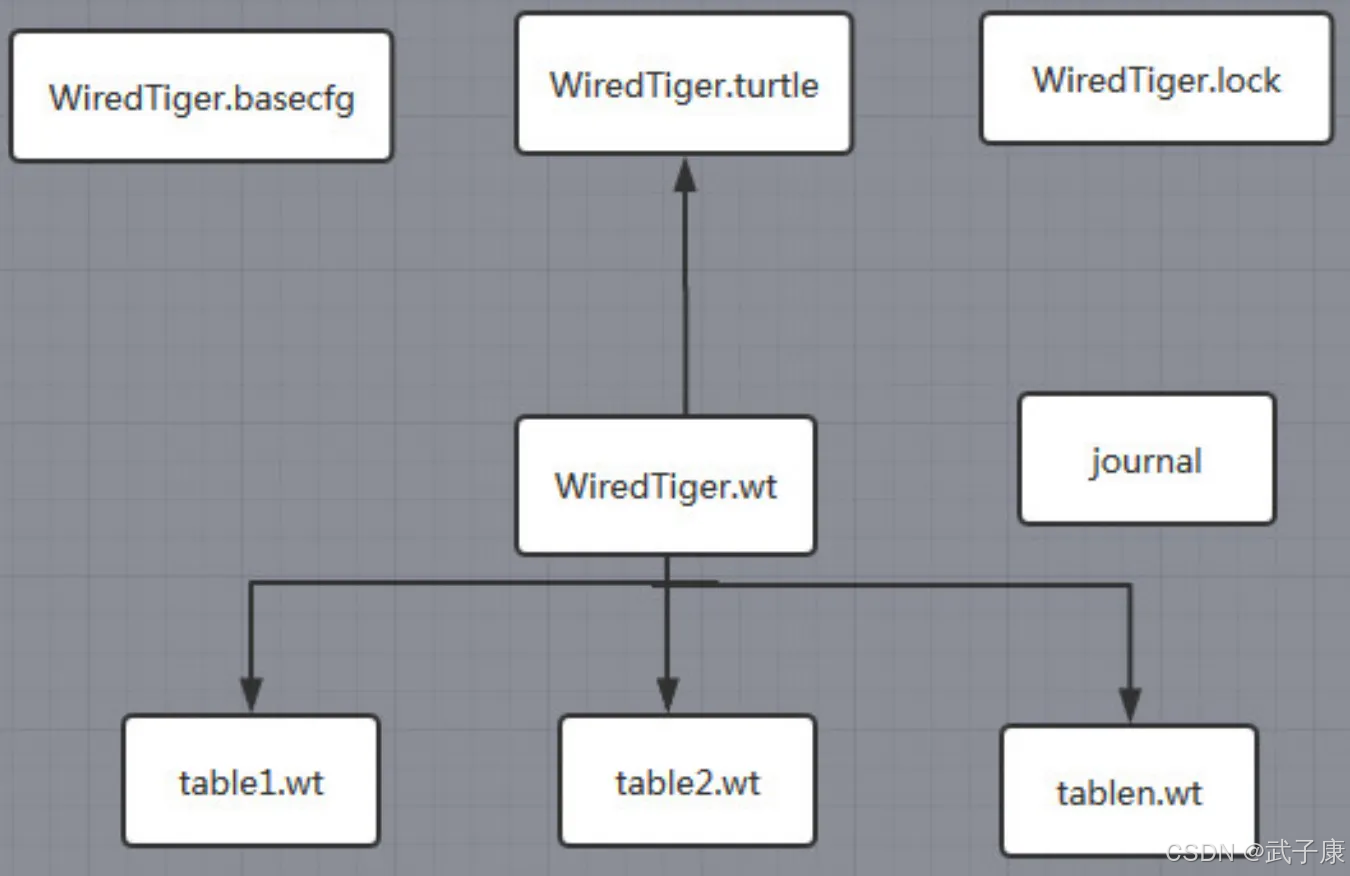
● WiredTiger.basecfg
- 存储引擎的基础配置文件
- 包含全局配置参数如缓存大小、检查点间隔等
- 与ConfigServer保持同步,确保集群配置一致性
- 示例配置项:cache_size=4GB,checkpoint=(wait=60s)
● WiredTiger.lock
- 实现并发控制的锁文件
- 采用独占锁(排他锁)和共享锁机制
- 支持事务隔离级别控制
- 实际应用场景:防止多个写操作同时修改同一数据页
● table*.wt
- 每个表对应一个物理存储文件
- 采用B+树索引结构存储
- 文件命名规则:table__.wt
- 示例:table_users_12345.wt 存储用户集合数据
- 支持压缩存储(可选snappy/zlib算法)
● WiredTiger.wt
- 元数据存储的核心文件
- 记录所有数据文件的组织结构
- 包含B+树节点分布信息
- 维护表空间到物理文件的映射关系
- 典型大小:约1MB(随表数量增长)
● WiredTiger.turtle
- 元数据的元数据文件
- 存储WiredTiger.wt的校验和与版本信息
- 用于启动时的完整性检查
- 文件大小固定(通常不超过4KB)
● journal(WAL日志)
- 预写式日志保障数据持久性
- 采用循环写入模式
- 默认日志文件大小限制为100MB
- 崩溃恢复时重放未提交事务
- 配置选项:journal=(enabled=true,compressor=snappy)
实现原理
写请求
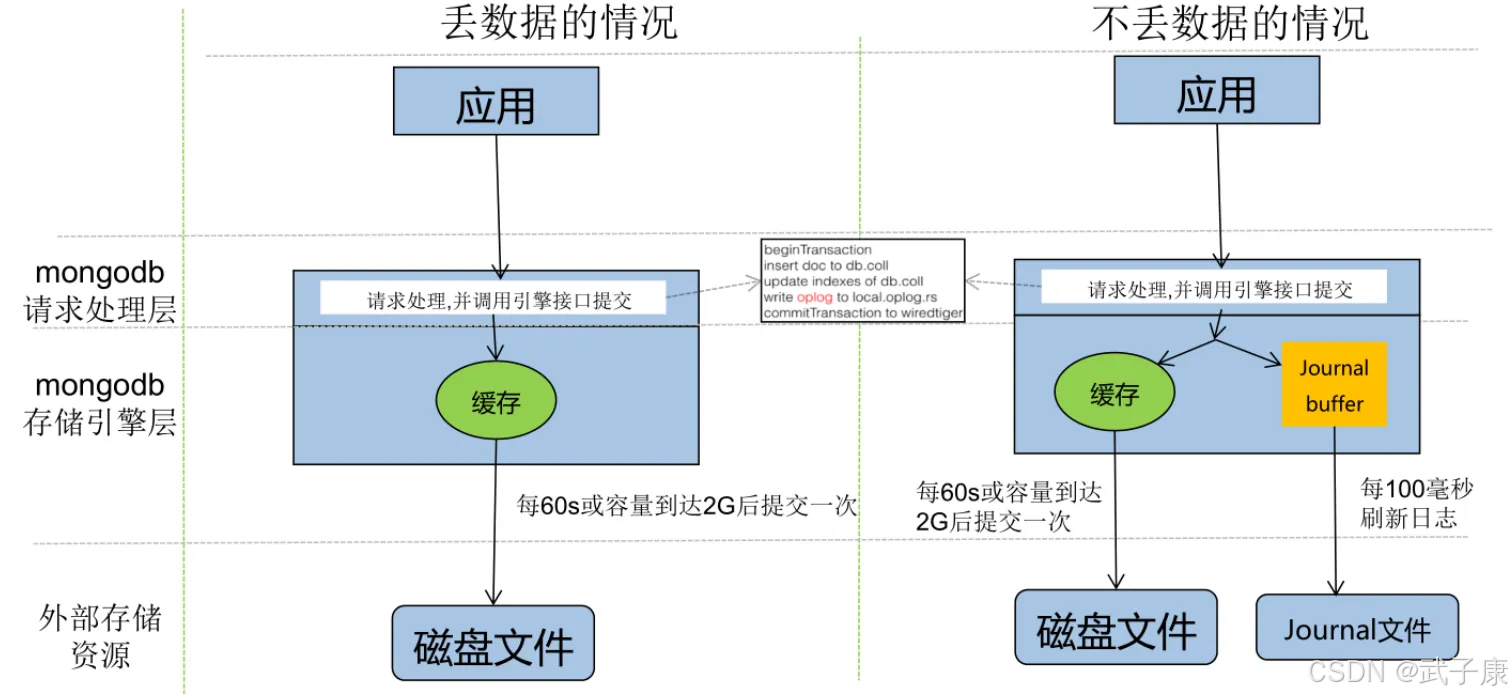
WiredTiger 的写操作会默认写入Cache,并持久化到WAL(Write Ahead Log),每60s或者log达到2G做一次checkpoint,当然我们也可以通过在写入时传入 j:true 的参数强制 journal 文件的同步,writeConcern { w: j, wtimeout: } 产生了快照文件。
WiredTiger 初始化时,恢复至最新的快照状态,然后再根据 WAL 恢复数据,保证数据的完整性。
Cache 是基于BTree的,节点是一个 page,root page是根节点,internal page是中间索引节点,leaf page是真正的存储数据,数据以page为单位读写。
WiredTiger 采用 Copy On Write 的方式管理操作 INSERT、UPDATE、DELETE,写操作会先缓存在 Cache里,持久化时,写操作不会在原来的 leaf page上进行,而是写入新分配的page,每次 checkpoint 都产生一个新的 root page。
checkpoint
● 对所有 table 进行了一次 checkpoint,每个 table 的 checkpoint 的元数据更新至 WiredTiger.wt
● 对 WiredTiger.wt 进行 checkpoint,该table checkpoint的元数据更新至临时文件 WiredTiger.turtle.set
● 将 WiredTiger.turtle.set 重命名为 WiredTiger.turtle
● 上述过程如果中间失败了,WiredTiger在下次连接初始化的时候,首先将数据恢复至最新的快照状态,然后根据 WAL 恢复数据,以保证存储可靠性
Journaling
在数据库宕机时,为保证 MongoDB 中数据的持久性,MongoDB 使用了 Write Ahead Logging 向磁盘上的 journal 文件预先进行写入。
除了 Journal 日志,MongoDB 还使用检查点(checkpoint)来保证数据的一致性,当数据库发生宕机的时候,我们就需要 checkpoint 和 journal 文件协作完成数据的恢复工作。
● 在数据文件中查找上一个检查点的标识符
● 在 journal 文件中查找标识符对应的记录
● 重做对应记录之后的全部操作
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接