D030知识图谱科研文献论文推荐系统vue+django+Neo4j的知识图谱|论文本文相似度推荐|协同过滤
文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
📑 编号:D030
📑 vue+django+neo4j+mysql 前后端分离架构、图数据库
📑 文献知识图谱:综合查询、作者、刊物、文献、关键词等关系
📑 协同过滤推荐算法实现科研论文文献推荐
📑 基于文献相似度的推荐算法 【基于摘要、关键词等文本向量嵌入】
📑 数据大屏、刊物分析可视化、词云分析
📑 文献收藏、评分、摘要、关键词
📑 文献管理、用户管理、权限管理、个人设置
📑 爬虫:selenium接管浏览器爬取ZW论文文献数据
1 视频演示
论文推荐vue+Neo4j知识图谱科研文献推荐系统vue+django框架,基于Neo4j的知识图谱
2系统总体设计
2.1 功能模块图
采用neo4j图数据库存储论文文献的关系,数据获取采用爬虫爬取网络论文数据。

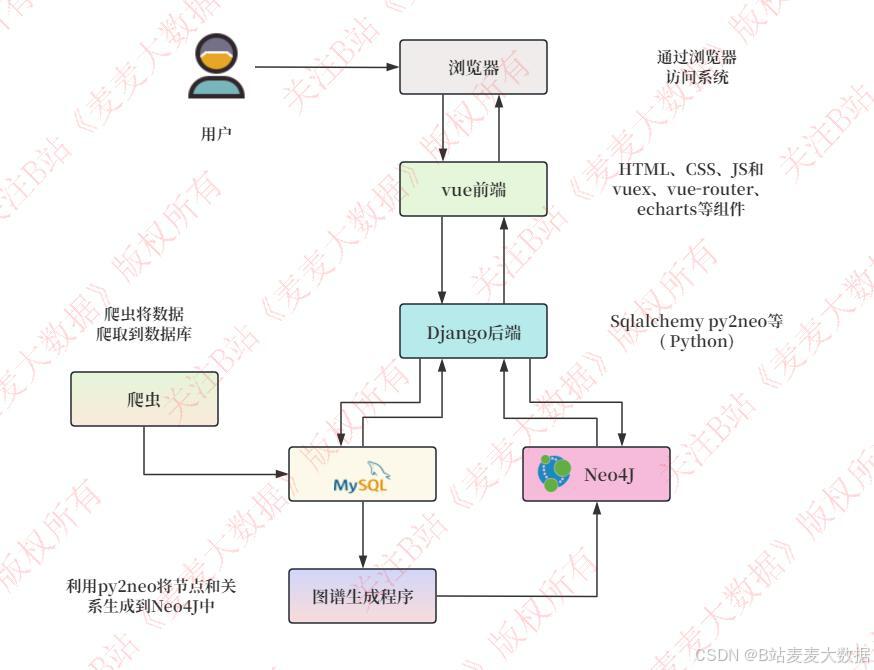
2.2 系统架构图
3功能介绍
vue + django + neo4j + mysql 来实现的人工智能文献可视化分析系统,具有推荐功能(基于用户和物品的协同过滤推荐算法)、前端采用vuetify + vue2.6 来做,后端使用django restframework 轻松实现增删改查,其中neo4j 存储的是人工智能文献的知识图谱,有文献名、来源刊物、分类、作者等节点以及他们之前的关系,在系统内可以进行图谱的可视化,这部分集成了echarts的关系图来实现,同时可以进行检索, 系统的其他功能方面,可以对论文进行收藏,评分,以及基于echarts 的多种可视化分析,包括刊物分析、词云分析、下载量、引用量等分析。
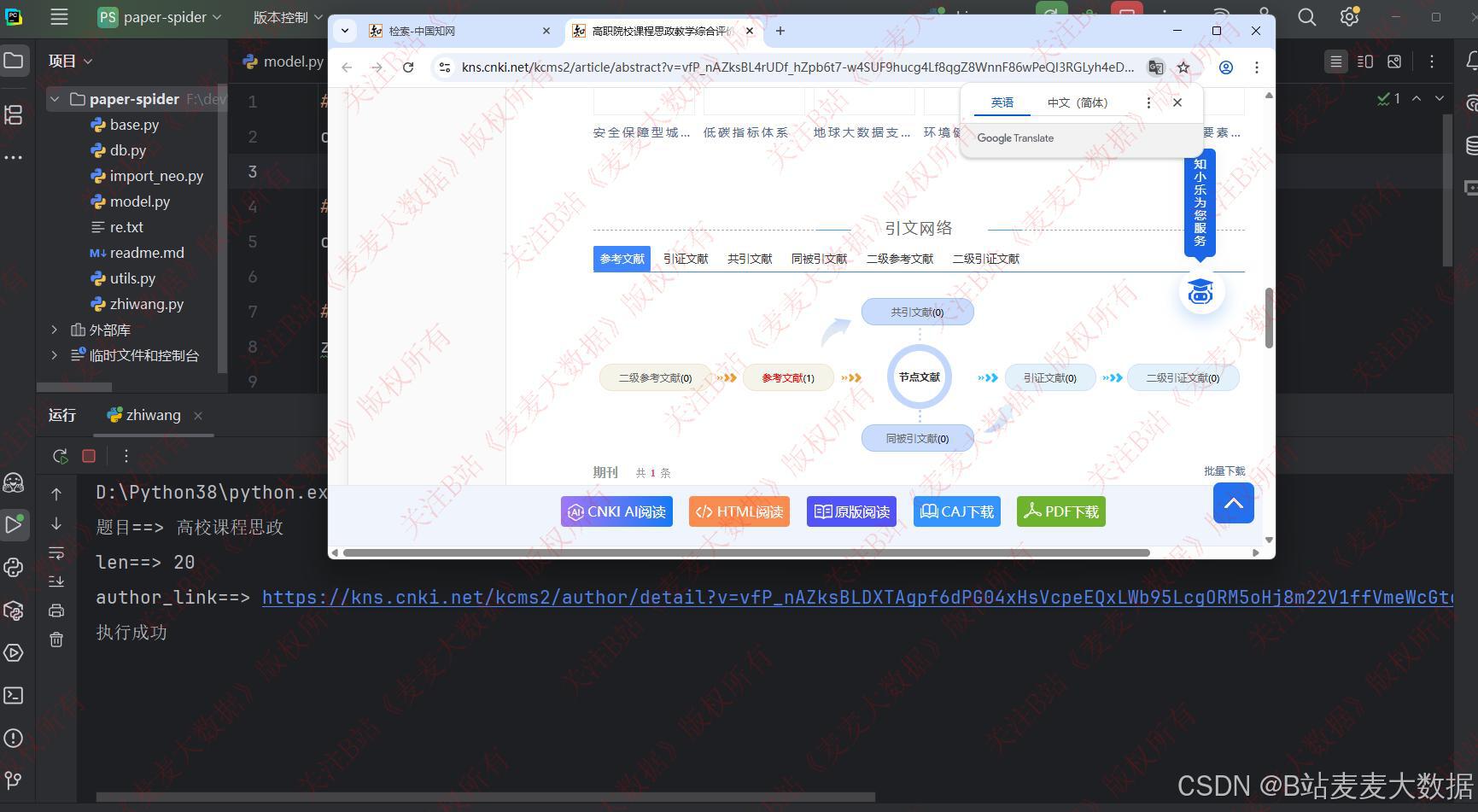
3.1 文献爬虫
第一步是数据采集方面也就是数据爬虫,是通过selenium来读取中国知网数据进行采集的,存储到mysql中,然后通过编写python脚本,通过py2neo 构建知识图谱到neo4j中。
3.2 知识图谱构建
利用python编写代码,构建知识图谱,对知识图谱的构建过程添加进度显示,方便用户进行观察。
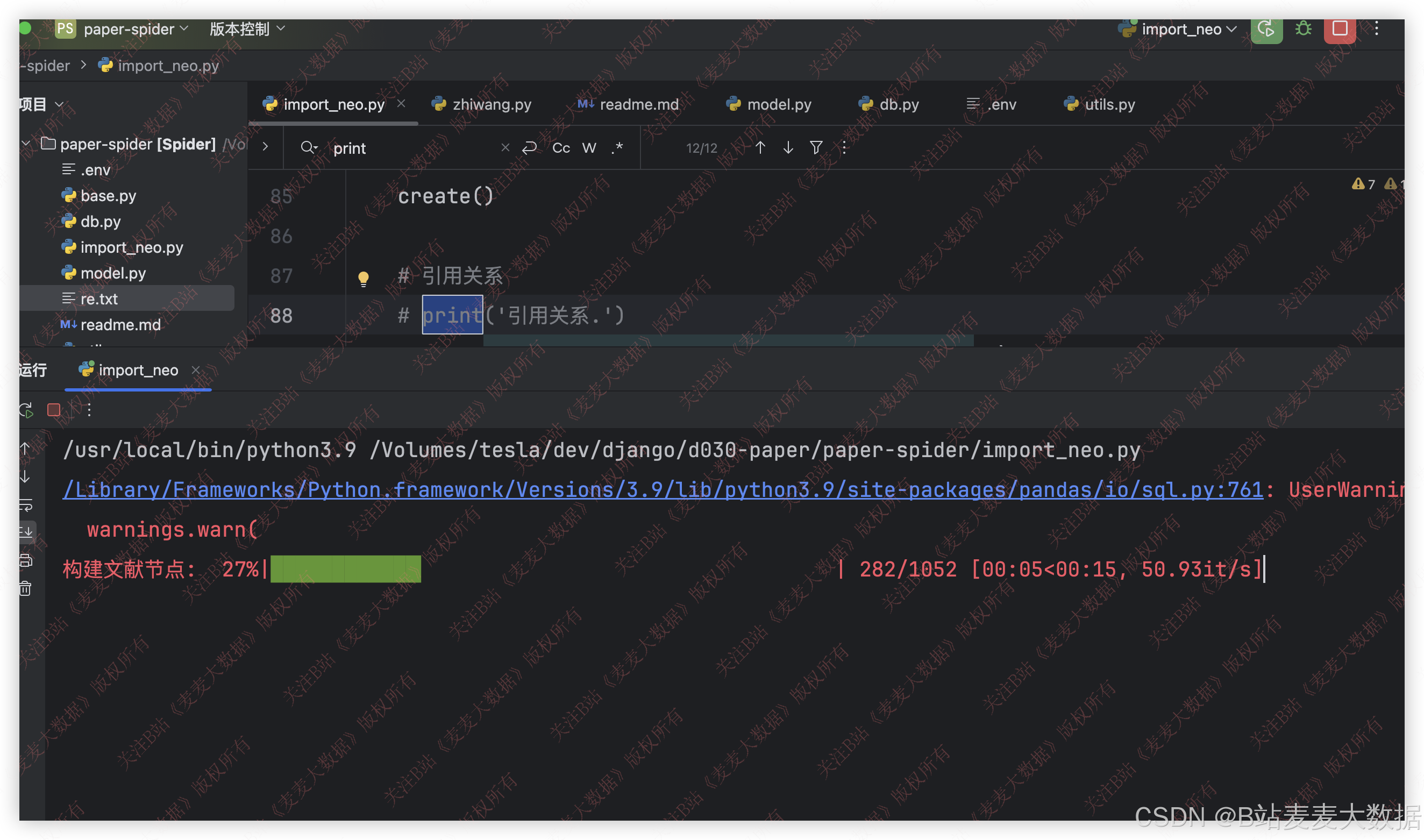
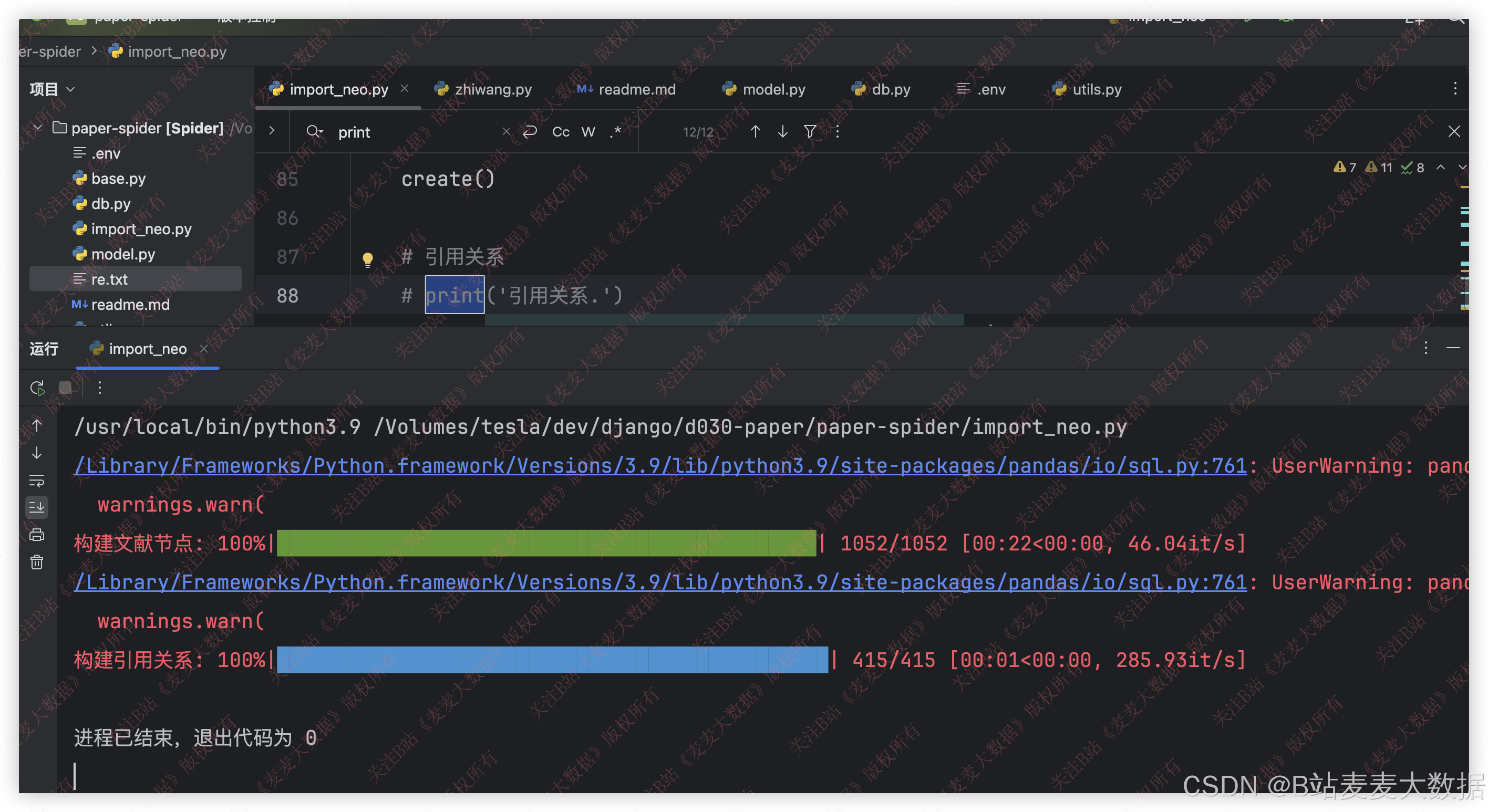
构建好的neo4j界面从localhost:7474进行访问:
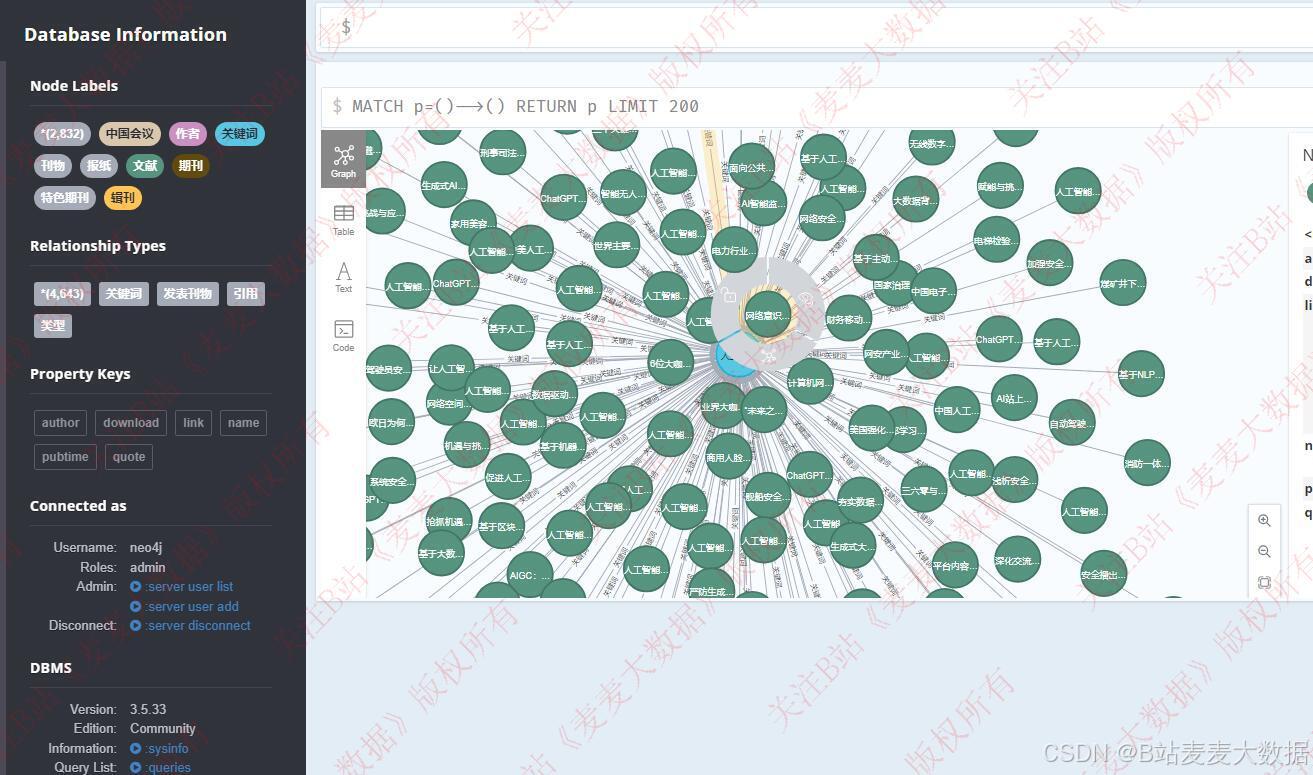
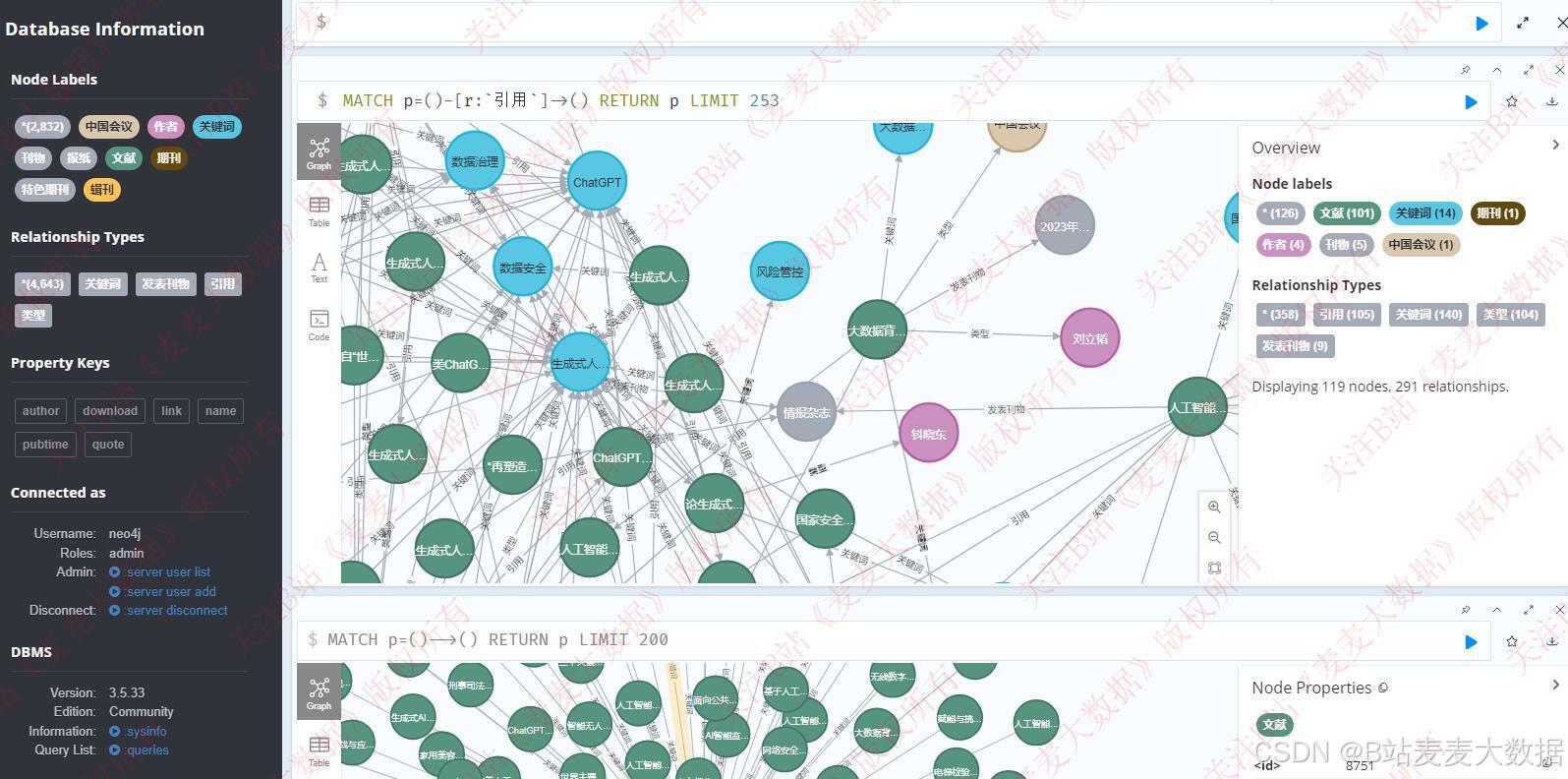

3.3 登录与注册
本系统的登录是使用一个Vue界面来完成的

3.4 论文检索
可以通过文献名称模糊搜索,还可以通过类型来筛选,还带有分页功能

3. 5 知识图谱可视化
人工智能文献的知识图谱,有文献名、来源刊物、分类、作者等节点以及他们之前的关系

3.6 文献推荐
使用v-card实现了文献的展示,包含了图片、文献名称、来源刊物、类型、还有发表实现,在卡片下方使用绝对定位设置了2个按钮,一个是查看详情,一个是收藏按钮(这个实际上是一个封装的vue componnent 和文献检索时看到的论文卡片是一样的,是一个代码的复用。)
点击查看详情,可以前往详情页面进一步查看其他扩充信息,比如论文的评分、被下载量、引用量、关键词等,通过链接还可以跳转到知网的原始页面。
另外推荐算法和结合了基于文本嵌入的推荐算法,也就是基于论文文献摘要内容来进行相似度的推荐

3.7 文献详情 / 文献收藏
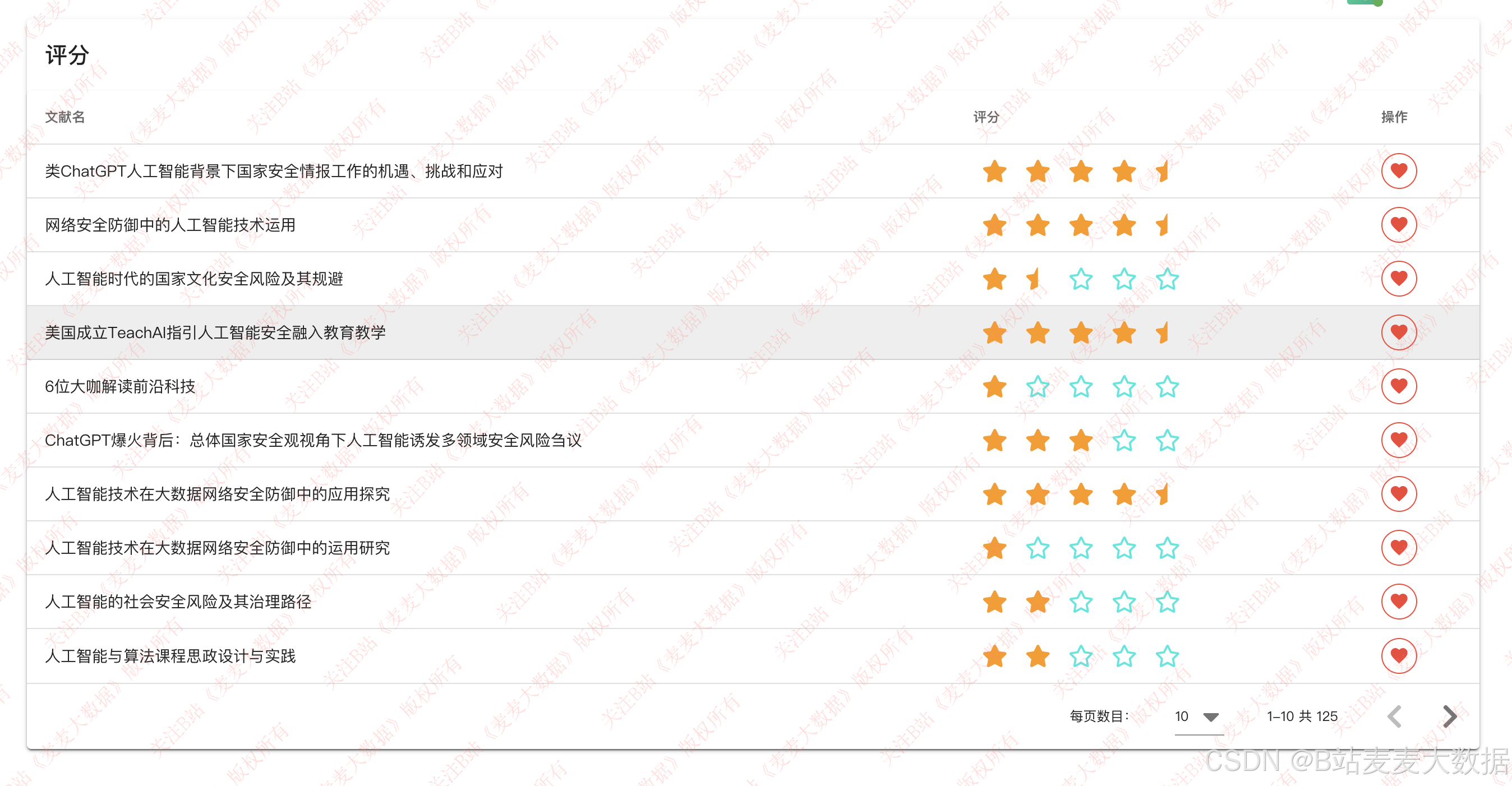
在文献的卡片上点击收藏后,就可以在文献评分的界面中看到这个文献,在这边可以查看和修改对文献的评分,也可以删除收藏的文献(点最右侧的红心按钮)
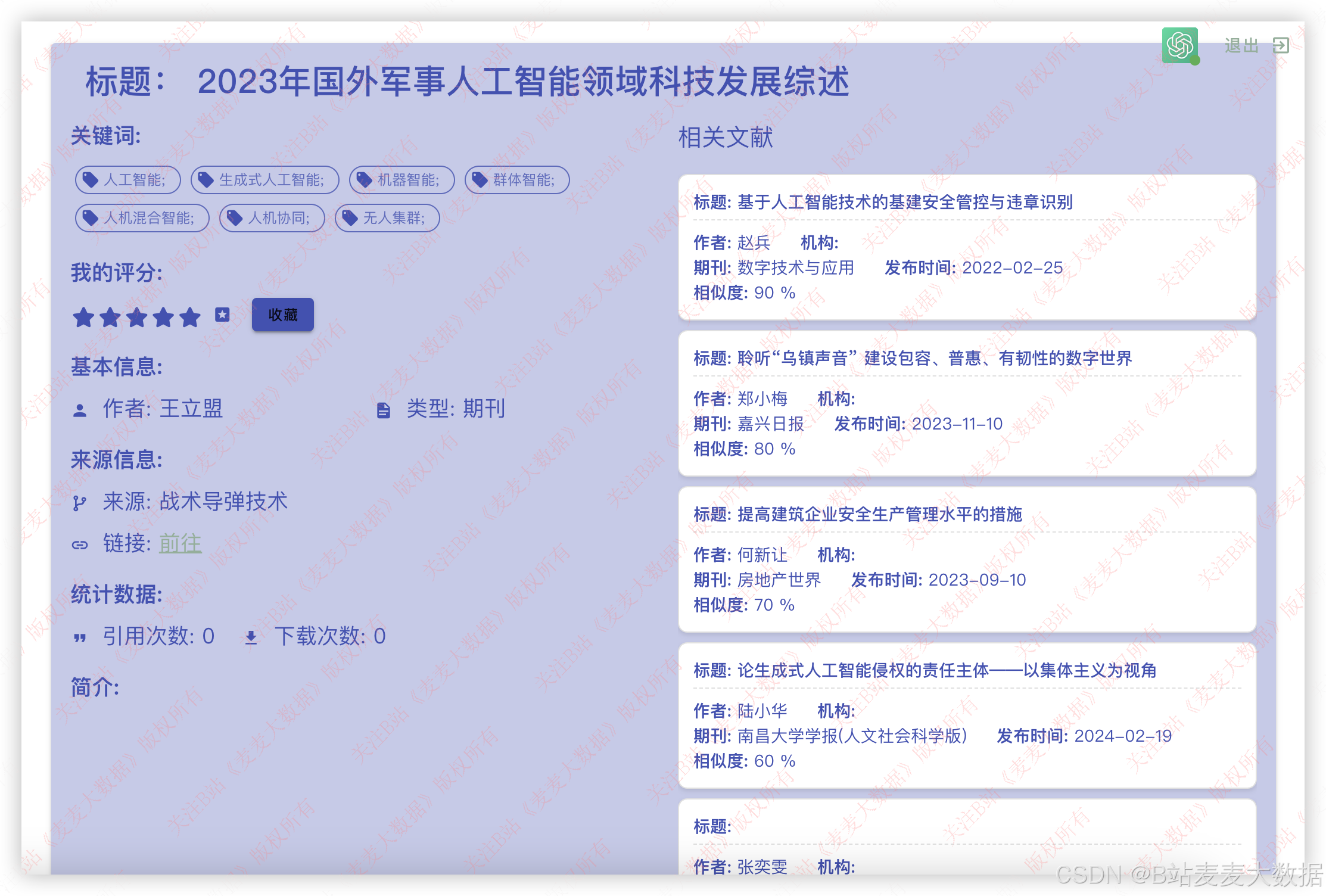
特别需要说明的是在详情页面的右侧还会展示相关性的文献,我们利用文本的相似度,计算最相似的文献五个,在右侧予以显示,并且会显示相似度白分别是多少,点击链接,则可以跳转到这个页面去呢。
文献的收藏:

评分功能:
3.8 可视化分析 (数据大屏 、刊物分析、词云分析)
包含数据大屏、刊物分析、词云分析





3.9 个人设置
包含个人信息修改和密码修改功能,做在一个vue界面中,通过v-tabs实现两个功能的切换,短信修改使用阿里云的短信验证码来进行校验。

3.10 文献管理 (管理员功能)
通过v-datatable 实现文献数据的增删改查,不过需要注意的是我们系统的主要数据都是来源于书爬虫,这个是给管理员用的功能

3.11 用户管理与权限 (管理员功能)
通过v-datatable 实现用户数据的增删改查,这个是给管理员用的功能,用户的权限对应可以看到什么菜单,

4.1 代码介绍
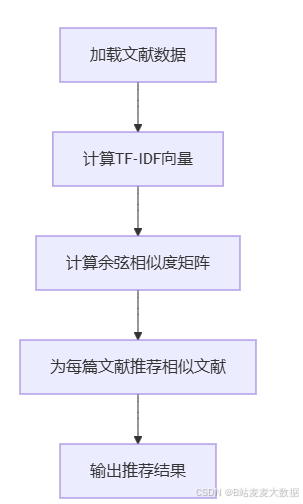
以下是一个基于TF-IDF和余弦相似度的文本相似度推荐算法的Python实现。该算法首先通过TF-IDF向量化文献摘要,然后计算向量间的余弦相似度,最后为每篇文献推荐相似度最高的文献。
4.2 流程图
4.3 核心代码
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similaritydef load_papers(file_path):"""加载文献数据,返回标题、摘要和ID"""papers = pd.read_csv(file_path)return papers['title'], papers['abstract'], papers['id']def compute_similarity(abstracts):"""计算文本间的相似度矩阵"""vectorizer = TfidfVectorizer(stop_words='english')tfidf_matrix = vectorizer.fit_transform(abstracts)return cosine_similarity(tfidf_matrix, tfidf_matrix)def recommend_papers(similarity_matrix, papers_id, current_id, top_n=5):"""为指定文献推荐相似文献"""idx = papers_id.tolist().index(current_id)scores = list(enumerate(similarity_matrix[idx]))scores.sort(key=lambda x: x[1], reverse=True)recommendations = [(papers_id[i], scores[i][1]) for i in scores if i != idx][:top_n]return recommendations# 示例使用
titles, abstracts, paper_ids = load_papers('papers.csv')
similarity_matrix = compute_similarity(abstracts)# 假设当前文献ID为123
recommendations = recommend_papers(similarity_matrix, paper_ids, 123)
print("推荐的文献:")
for paper_id, score in recommendations:print(f"ID: {paper_id}, 相似度: {score:.2f}")