分布式存储Ceph与OpenStack、RAID的关系
分布式技术有个大家庭,具体见下图。本篇文章主要讲分布式架构里的存储系统--ceph。
一. Ceph的优势
Ceph 是一款开源的分布式存储系统,能统一提供对象存储、块存储和文件存储三种服务,广泛用于云环境和企业级存储场景。

1. Ceph的核心特性
- 分布式架构:数据分散存储在多个节点上,无单一故障点,支持横向扩展,可轻松应对 PB 级甚至 EB 级数据。
- 统一存储接口:一套系统同时支持对象存储(兼容 S3、Swift)、块存储(类似硬盘,供虚拟机使用)和文件存储(兼容 POSIX),减少架构复杂度。
- 高可靠性:通过数据副本(默认 3 副本)和自动故障检测、自愈机制,确保数据不丢失,服务不中断。
2.Ceph的应用场景
- 云平台存储:作为 OpenStack、Kubernetes 等云平台的后端存储,为虚拟机、容器提供持久化存储服务。
- 大数据存储:为 Hadoop、Spark 等大数据框架提供高容量、高吞吐的存储支持。
- 企业级存储:替代传统 SAN、NAS 设备,为企业提供低成本、可扩展的统一存储解决方案。
3.Ceph的架构
Monitor(监视器)
- Ceph 集群的 “大脑”,负责维护集群的全局状态和一致性。
- 存储集群中所有组件的位置、状态、网络拓扑等关键信息,是客户端与集群交互的 “导航图”。
- 协调集群一致性:通过 Paxos 算法实现多个 Monitor 之间的状态同步,确保集群配置(如副本数、存储池策略)在分布式环境下的一致性。
- 管理集群元数据:如存储池(Pool)的创建 / 删除、认证授权(通过 Cephx 协议)、集群版本控制等。
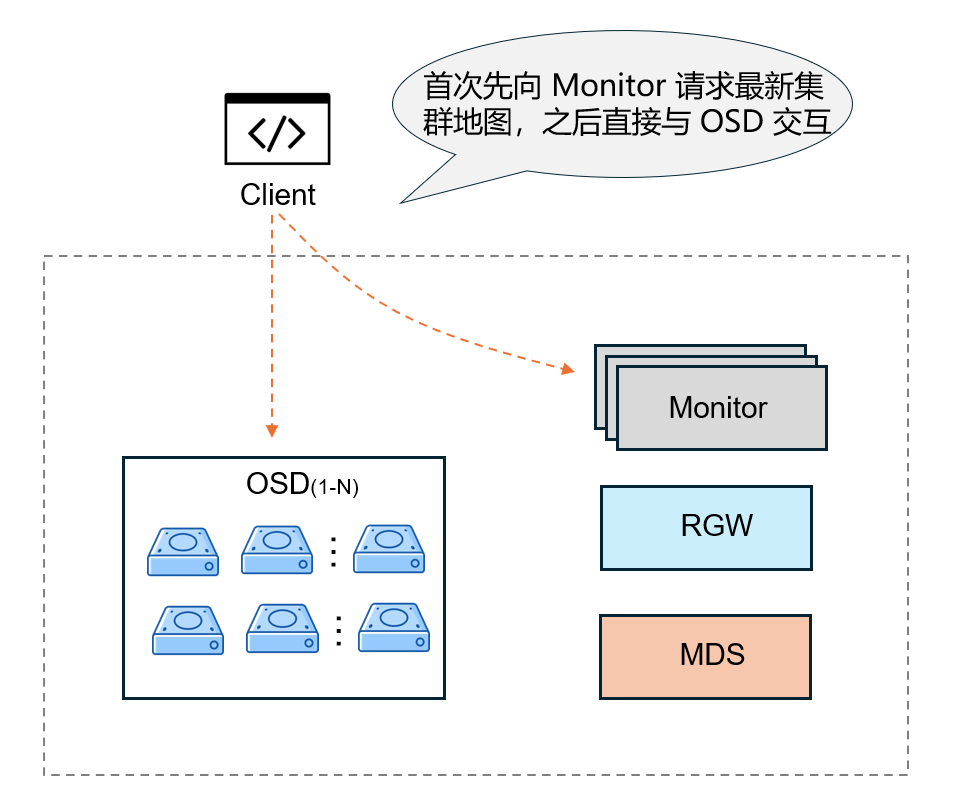
OSD(对象存储守护进程)
- Ceph 集群的 “存储节点”,直接负责数据的存储、读写、复制和故障恢复。
- 将数据以 “对象(Object)” 形式存储在本地硬盘(每个 OSD 通常对应一块物理硬盘),处理客户端的读写请求
- 根据存储池配置的副本策略,在不同 OSD 间同步数据,确保数据冗余
- 故障检测与自愈:OSD 之间通过 “心跳检测” 感知彼此状态,若某 OSD 故障,存活 OSD 会自动触发数据重平衡
MDS(元数据服务器)
- 仅用于 Ceph 文件系统(CephFS),负责管理文件系统的元数据(非实际数据)
- 元数据管理:存储文件的目录结构、文件名、权限、修改时间等元数据(类似传统文件系统的 inode),避免客户端直接操作元数据导致的性能瓶颈。
- 元数据缓存:将热点元数据缓存到内存,加速客户端的目录查询、文件创建等操作。
RGW(对象网关)
- 提供兼容主流对象存储协议的接口,让应用能通过标准 API 访问 Ceph 的对象存储
- 客户端通过 RGW 的 HTTP/HTTPS 接口发送请求,RGW 解析请求后,将对象数据转发给 OSD 存储
- 可横向扩展多个 RGW 节点,通过负载均衡器分发请求,提升并发能力
通过这些组件的协同,Ceph 实现了 “无中心架构”“强一致性”“高可扩展” 的特性,支持从 TB 级到 EB 级的存储需求。
二、Ceph与OpenStack关系
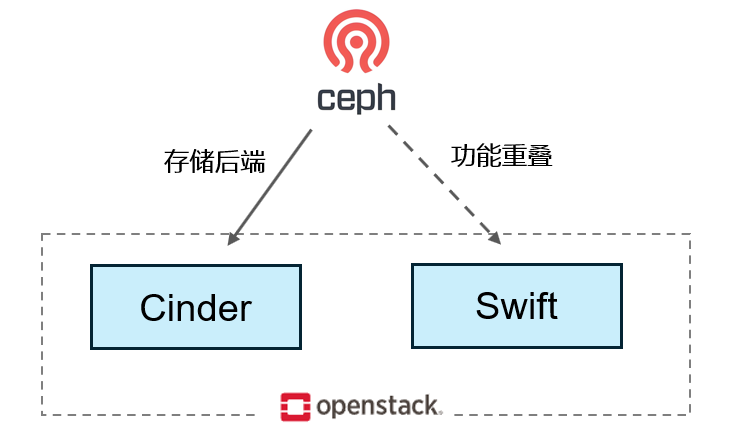
OpenStack 作为最主流的私有云方案之一,它集成了很多开源组件。比如存储组件后端就用到了ceph系统。而Ceph也因为OpenStack而“走红”。
1. Cinder 与 Ceph:块存储的 “接口与后端”
Cinder 是 OpenStack 中管理虚拟机块设备的服务,核心功能是提供块设备的创建、挂载、快照等接口,但数据的实际存储依赖后端存储系统。
Ceph 与 Cinder 的直接关联体现在:
- Ceph 通过其 RBD(RADOS Block Device) 模块,作为 Cinder 的后端存储方案。
- 当用户通过 Cinder API 请求创建块设备时,Cinder 会调用 “RBD 驱动”,在 Ceph 集群中生成对应的 RBD 镜像(块设备),数据由 Ceph 以分布式副本(或纠删码)方式存储。
- 虚拟机(Nova 实例)挂载该块设备时,实际通过 RBD 协议直接与 Ceph 交互读写数据,Cinder 仅负责权限、生命周期等逻辑管理。
2. Swift 与 Ceph:对象存储的 “替代或兼容”
Swift 是 OpenStack 原生的对象存储服务,用于存储非结构化数据(如图片、日志),提供基于 HTTP 的 REST API。
Ceph 与 Swift 的直接关联体现在:
- Ceph 通过其 RGW(RADOS Gateway) 模块,兼容 Swift API(同时兼容 S3 API)。因此,在 OpenStack 中,Ceph RGW 可直接替代 Swift 作为对象存储后端。
- 当用户通过 OpenStack 的对象存储接口(如openstack object 命令)操作数据时,请求会被转发到 Ceph RGW,数据最终以对象形式存储在 Ceph 集群中,RGW 负责协议转换和对象管理。
总结:
Ceph RGW 可作为 Swift 的 “替代实现”,两者功能重叠(均提供对象存储),但 Ceph 凭借分布式架构更易扩展。
三. Ceph 与RAID 关系
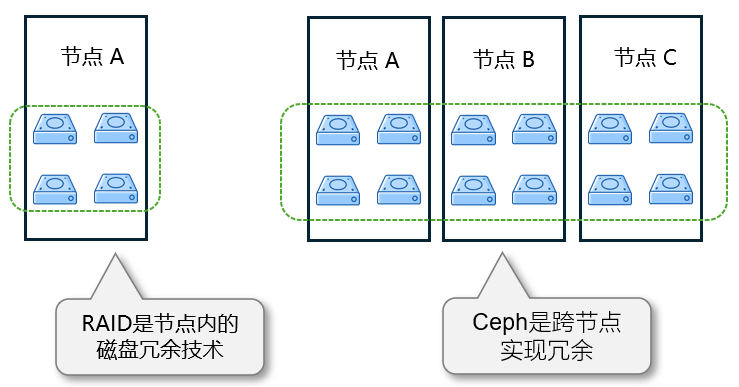
RAID 是单节点内的本地磁盘冗余技术(如 RAID1/5/6),通过同一服务器内的多块磁盘冗余实现数据保护,解决单盘故障问题。
Ceph 是分布式冗余系统,通过跨节点的数据副本(默认 3 副本)或纠删码(EC)实现冗余,解决单节点(甚至多节点)故障问题。
两者的冗余逻辑层级不同:RAID 保护 “单节点内的磁盘”,Ceph 保护 “跨节点的集群数据”。
云方案中 Ceph 不会与 RAID 搭配搭配使用
- Ceph 的 OSD 直接使用裸盘(每块物理磁盘对应一个 OSD 进程),不做本地 RAID。
- 数据冗余完全依赖 Ceph 自身的副本策略。如 3 副本分布在 3 个不同节点,或纠删码(如 4+2 模式,跨 6 个节点容错 2 个)。
- 避免 “双重冗余” 浪费空间(例如 RAID5 本身消耗 1 块盘冗余,Ceph 再做 3 副本,总冗余率过高)