关于spiderdemo第二题的奇思妙想
前言
spiderdemo是练习爬虫案例的网站,如下
反爬虫练习平台![]() https://www.spiderdemo.cn/而第二题需要逆向,但是里面的js代码很麻烦,经过混淆,不想搞怎么办?
https://www.spiderdemo.cn/而第二题需要逆向,但是里面的js代码很麻烦,经过混淆,不想搞怎么办?
直接开始
正文
前置分析
其中参数很容易发现
如下
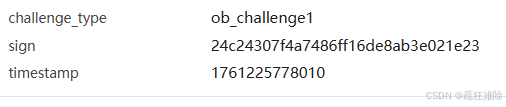
很明显,sign就是加密参数。
搜索一下关键,很容易发现如下

而其中加密使用的是hex_md5,进去看看

一堆不知道是什么东西
但是笔者发现这个hex_md5都在ob_challenge1.js这个js文件中,于是笔者把这个文件下载来,
添加
let a=hex_md5("17612268353402")
console.log(a)运行,报错
var ۦۥۥﱠﱣﱟ = WheelEvent, ۥﱣﱠۦﱣۦ = window, ۥﱟۦﱠۥۦ = document, ۥﱟۦﱠۦۥ = navigator, ﱣﱞﱟﱣﱣﱠ = location, ۥﱟۦﱠﱞۦ = history,
^ReferenceError: WheelEvent is not defined
。。。。
笔者看着也不想逆向,然后,笔者问了AI,AI说是node环境没有window。
笔者突然有个想法,放到html里面试试,如下新建一个a.html文件
<!DOCTYPE html>
<html lang="en" xmlns="">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<script src="ob_challenge1.js">
</script>
<script>let a=hex_md5('17612268353402')console.log(a)
</script>
<body></body>
</html>Pycharm打开页面
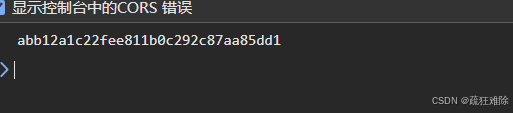
啊,哈哈哈哈哈哈
和前面生成sign一模一样,那说明全部的加密都在这里面,那不需要解混淆,解个寂寞
直接调用html获取参数不就可以了,笔者感觉没问题,说干就干。
调用html
如何调用html,可以使用selenium ,但笔者想使用DP,笔者从来没有使用过,正好尝试一下
DrissionPage官网![]() https://drissionpage.cn/安装过程就不必细说。
https://drissionpage.cn/安装过程就不必细说。
笔者想使用如下的代码获取结果
如下是two.py文件
from DrissionPage import ChromiumPage
page = ChromiumPage()# 1. 加载本地 HTML(file:// 协议)
html_path = 'file:///' + __import__('os').path.abspath('a.html').replace('\\', '/')
page.get(html_path)
# 2. 执行 JS 并拿结果
md5_val = page.run_js("return hex_md5('17612268353402');")
print('MD5 值:', md5_val)# 3. 退出
page.quit()文件位置如下
执行two.py文件,结果如下
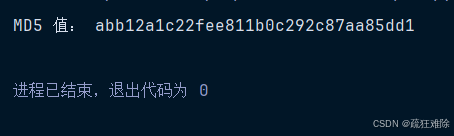
哈哈哈哈哈,成功了。
绕过逆向。哈哈哈哈哈
笔者还发现在Pycharm中打开html,如下

有个localhost:63342,那么直接不装了,代码如下
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get("http://localhost:63342/study-spider/src/spiderDemo/a.html")
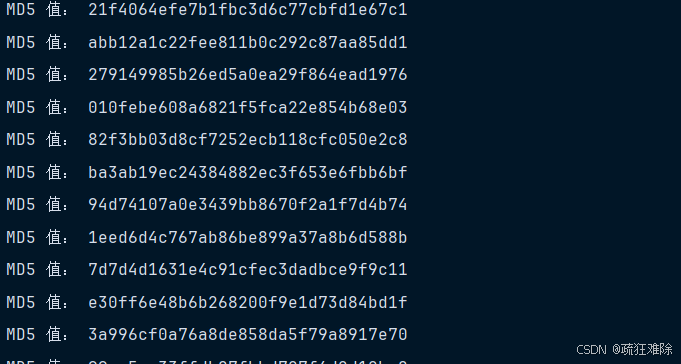
for i in range(1,101):md5_val = page.run_js(f"return hex_md5('1761226835340{i}');")print('MD5 值:', md5_val)
page.quit()直接对localhost:63342发送请求,结果如下
没问题。既然如此,搞事情
编写爬虫
细节不必多言,直接看代码
from DrissionPage import ChromiumPage
import time
import requests
html = ChromiumPage()
html.get("http://localhost:63342/.../a.html")
total=0
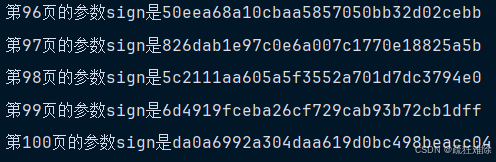
for page in range(1,101):url=f'https://www.spiderdemo.cn/ob/api/ob_challenge1/page/{page}?'timestamp=int(time.time()*1000)sign=html.run_js(f"return hex_md5('{timestamp}{page}');")print("第"+str(page)+"页的参数sign是"+sign)cookies = {'sessionid': '你的sessionid'}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0'}params={'challenge_type':'ob_challenge1','sign':sign,'timestamp':timestamp}response=requests.get(url,params=params,headers=headers,cookies=cookies)success=response.json()['success']if not success:print("Failed to get valid response")else:page_total=sum(response.json()['page_data'])total+=page_total
print(total)笔者html页面路径都去掉了,这个每个人的都不同,看个人。
结果

ok。
总结
感觉卡bug了,没有进行逆向之类的。
就是把那个js文件下载下来,放到html里面,使用DP打开html,调用js函数,获取加密后的结果。
哈哈哈哈哈哈哈哈哈哈哈哈。