AAAI 2025 | 即插即用,川大Mesorch刷新SOTA,用「介观」Transformer架构终结图像造假
1. 基本信息
-
标题: Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization (介观洞察:为图像篡改定位协调多尺度混合架构)
-
论文来源:https://arxiv.org/pdf/2412.13753
2. 核心创新点
-
提出Mesorch混合架构: 创新性地并行使用CNN和Transformer,分别捕获图像的微观细节(篡改痕迹)和宏观语义(物体级别信息),并通过多尺度方法有效协同,以精确捕捉介观层面的篡改伪影。
-
引入自适应加权与剪枝机制: 设计了一个自适应加权模块,能够动态评估并调整不同尺度特征的重要性;同时通过剪枝低贡献度的尺度,在保持甚至提升性能和鲁棒性的前提下,显著降低了模型的计算成本和参数量。
-
定义图像篡改定位新范式: 将图像篡改定位(IML)任务重新定义为在介观层面(mesoscopic level)上同时捕获微观特征与宏观语义的过程,为该领域的研究提供了新的理论视角。
-
实现SOTA性能: 基于Mesorch架构开发了两个基线模型,在四个公开数据集上的实验结果表明,其在F1分数、鲁棒性和计算效率(FLOPs)方面均超越了当前最先进的方法。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/pnSxeErt_jou2LPrbPFCsw
https://mp.weixin.qq.com/s/pnSxeErt_jou2LPrbPFCsw
3. 方法详解
整体结构概述
Mesorch框架的核心思想是并行处理,协同分析图像的微观与宏观信息。首先,输入图像通过离散余弦变换(DCT)被分解为高频和低频分量,并与原图融合,形成高频增强图和低频增强图。高频图被送入专用于捕捉局部细节的CNN模块(Local Feature Module),而低频图则被送入善于理解全局语义的Transformer模块(Global Feature Module)。两个模块并行地在四个不同尺度上提取特征。随后,解码器将这些多尺度特征图生成初步的篡改预测。最后,一个自适应加权模块动态地融合这些来自不同层次、不同来源的预测结果,生成最终的定位掩码。
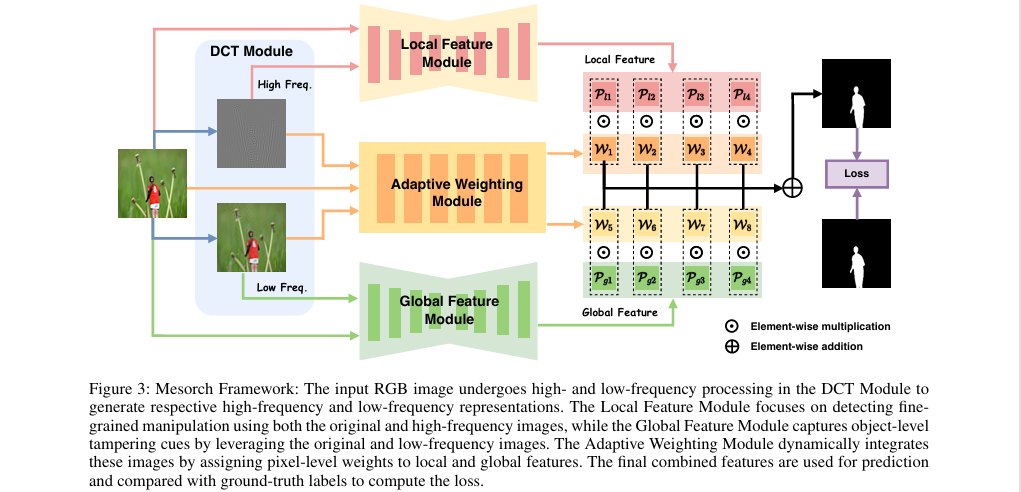
步骤分解
-
频率特征增强:
-
首先,对输入的RGB图像
x应用离散余弦变换(DCT),分离出高频分量x_h和低频分量x_l。 -
然后,将这些频率分量与原始图像
x拼接,生成两个六通道的增强图像:高频增强图I_h和低频增强图I_l,分别用于后续的局部和全局特征提取。
-
-
并行编码与多尺度解码:
-
高频增强图
I_h被输入到LocalFeatureEncoder(基于CNN,如ConvNeXt),低频增强图I_l被输入到GlobalFeatureEncoder(基于Transformer,如Segformer)。 -
两个编码器并行工作,各自在4个不同尺度
i(i=1, 2, 3, 4) 上输出特征图L_s_i和G_s_i。
-
这些特征图随后通过各自的解码器,生成对应每个尺度的局部预测
P_l_i和全局预测P_g_i。
-
-
自适应尺度加权与融合:
-
为了解决不同尺度贡献度不等的问题,设计了一个
AdaptiveWeightingModule。该模块接收原始图像、高频图和低频图的拼接作为输入,输出一个8通道的权重向量W,对应8个(4个局部+4个全局)尺度预测图在每个像素上的重要性。
-
最终的预测结果由所有尺度的预测图
P_all与其对应的权重W进行逐像素的加权求和得到,然后上采样至原图尺寸。
-
-
模型剪枝:
-
在模型初步收敛后,通过评估每个尺度的平均权重来识别其贡献度。计算每个尺度
i的平均权重\bar{W}_i。
-
如果某个尺度的平均权重低于预设阈值
ε,则该尺度被认为是冗余或低效的,并从模型中移除(剪枝),以降低参数量和计算复杂度。
-
4. 即插即用模块作用
Mesorch架构本身,特别是其并行的CNN-Transformer混合编码器与自适应多尺度加权模块,可以被视为一个高效的图像篡改定位解决方案。
适用场景
该技术主要应用于数字媒体取证领域,特别适用于以下任务:
-
图像篡改定位 (IML): 精确检测并分割出图像中被篡改的区域,包括拼接、复制-移动、内容填充(inpainting)等多种篡改类型。
-
伪造图像检测: 适用于需要高精度和高鲁棒性的场景,如新闻真实性核查、司法证据鉴定、保险欺诈检测等。
-
通用密集预测任务: 该架构的设计思想(并行融合局部与全局信息)有潜力被迁移到其他需要同时关注细节和上下文的视觉任务中,如语义分割、显著性目标检测等。
主要作用
该技术为图像篡改定位任务带来了显著的价值:
-
模拟人类视觉系统: 通过并行处理微观痕迹(CNN)和宏观语义(Transformer),模拟了人类专家在鉴定伪造图像时既关注像素级异常又理解场景逻辑的分析过程。
-
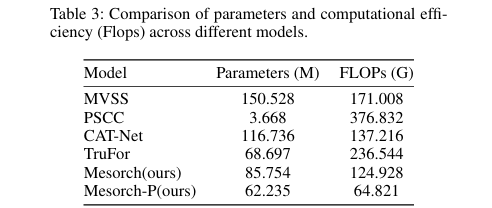
大幅降低计算成本: 通过自适应剪枝机制,模型能够去除冗余的计算分支,在几乎不损失性能的情况下,显著降低了FLOPs和参数量(如表3所示,Mesorch-P模型的FLOPs远低于其他SOTA模型)。
-
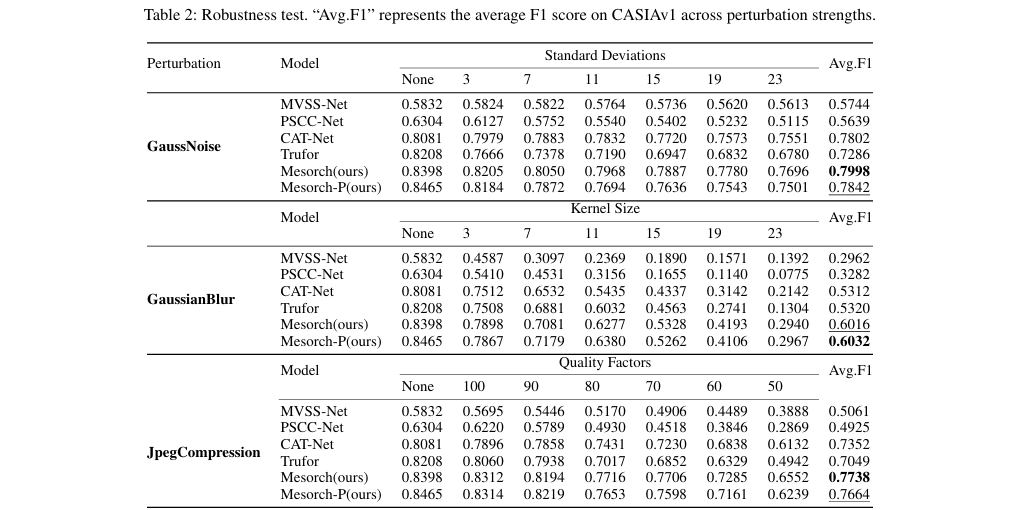
增强鲁棒性: 模型在面对高斯噪声、高斯模糊和JPEG压缩等常见图像失真攻击时,表现出比现有SOTA方法更强的鲁棒性(如表2所示),确保了在现实世界复杂环境下的可靠性。
-
提升定位精度: 结合了CNN的局部感知能力和Transformer的全局上下文理解能力,有效解决了单一架构的局限性,实现了更高的篡改定位精度(如表1所示,F1分数全面领先)。
总结
Mesorch架构是一个高效、鲁棒且轻量化的图像篡改定位框架,它通过并行协同CNN与Transformer,并自适应地融合多尺度信息,实现了对介观层面篡改伪影的精准捕捉。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/pnSxeErt_jou2LPrbPFCsw
https://mp.weixin.qq.com/s/pnSxeErt_jou2LPrbPFCsw