KDD 2025 | CMA:用于时序去噪和预测的统一情境元自适应方法!
本文介绍来自华南师范大学等机构在 KDD 2025 发表的最新研究成果。该研究提出了 CMA,一种统一的情境元自适应框架。它通过一个元学习驱动的扩散过程,使单个模型能够在不重新训练的情况下,灵活适应不同长度的历史观测和未来预测范围。
与为特定配置训练的传统模型不同,CMA 能够在测试时动态调整模型参数,以适应新的数据情境。它将去噪扩散过程与元学习相结合,通过迭代式地生成和优化,使预测序列既能对齐历史观测,又能捕捉到数据分布的最新变化。这一框架在多变的现实场景中展现了卓越的适应性和预测性能,并在六个学术数据集和四个真实营销数据集上取得了显著提升。
另外,我整理了KDD 2025时间序列论文+源码合集,感兴趣的自取!
原文 资料 这里!

【论文标题】CMA: A Unified Contextual Meta-Adaptation Methodology for Time-Series Denoising and Prediction
【论文链接】https://dl.acm.org/doi/10.1145/3711896.3736881
【代码链接】https://github.com/FancyAI-SCNU/CMA_KDD_2025
研究背景
经典的时间序列预测方法,无论是自回归模型还是非自回归模型,通常依赖于固定的历史观测窗口和预设的未来预测步数。这种僵化的架构限制了它们在现实世界任务中的灵活性和有效性,因为真实场景常常需要处理可变的历史长度和预测范围。每当任务设置改变,这些模型就需要重新训练,这在工业应用中既耗时又不切实际。
此外,真实世界的时间序列数据往往表现出非平稳、长程依赖和模式演变等复杂特性。现有方法难以在单一模型中有效捕捉这些动态变化。为了解决这些局限性,研究者们引入了情境学习的概念,旨在让模型能够动态适应变化的输入。具体策略包括:
- in-context learning: 动态适应不同长度的历史观测数据。
- extend-context learning: 在不重新训练的情况下,处理任意长度的未来预测 horizon。
- cross-context learning: 以最小的代价将模型知识迁移到新的数据域。
本文提出的 CMA 框架正是为了统一解决上述挑战,旨在创建一个灵活、高效且适应性强的时序预测新范式。
核心贡献
本研究贡献可总结如下:
- 提出了一个统一的框架 CMA,通过元学习驱动的扩散过程,将持续学习和测试时自适应相结合,显著提升了预测性能并确保了主干模型的灵活性。
- CMA 能够泛化到多种情境学习范式,包括处理可变历史长度的 in-context 学习、灵活未来范围的 ex-context 学习,以及高效的跨域自适应。
- 在推理阶段实现了高效的低秩测试时自适应,将计算成本降低了 98.8%,同时将速度提升了 27%。
- CMA 在六个学术基准数据集上平均性能提升 7%,在四个真实营销数据集上平均提升 16%,全面超越了现有方法。
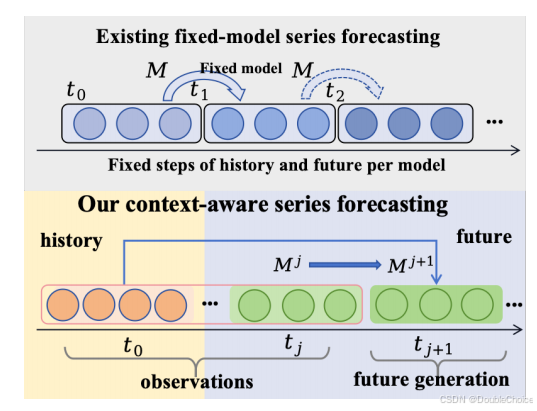
方法解析
该框架通过一个元优化的扩散过程,统一了持续学习和测试时自适应;(2)系统性地解决了 in-context、ex-context 和 cross-context 三种学习范式;(3)在多个学术和真实世界数据集上进行了广泛验证。CMA 的核心思想是,它不依赖于固定的模型,而是学习如何根据当前的情境快速自适应。
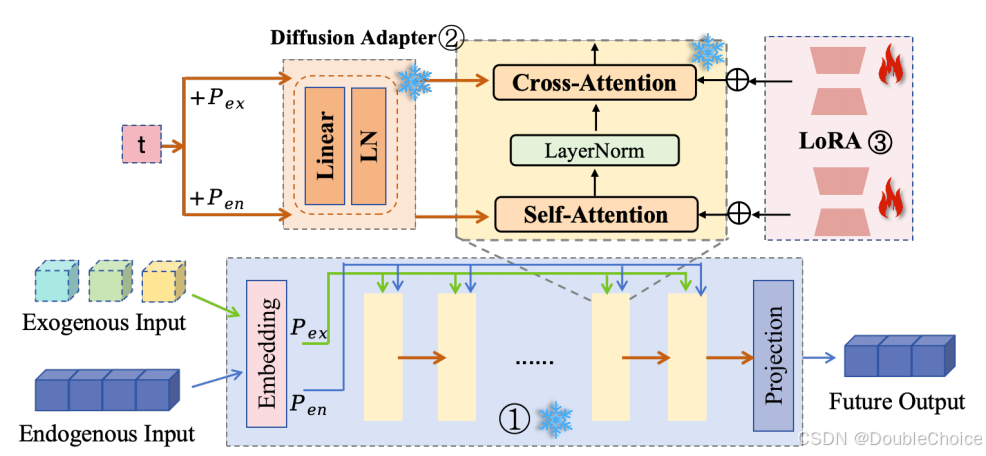
基础架构
CMA 框架可以构建在任何时间序列预测模型之上,论文中以 TimeXer 为例进行说明。其主要包含三个部分:
- 时间序列主干网络:负责基础的序列特征提取和预测。
- 扩散适配器:在主干网络的注意力层中注入扩散过程的时间步信息t,从而引导模型进行分步去噪生成。
- 低秩测试时自适应模块:在测试阶段,该模块被激活,以低成本的方式快速更新模型参数,适应新的数据。
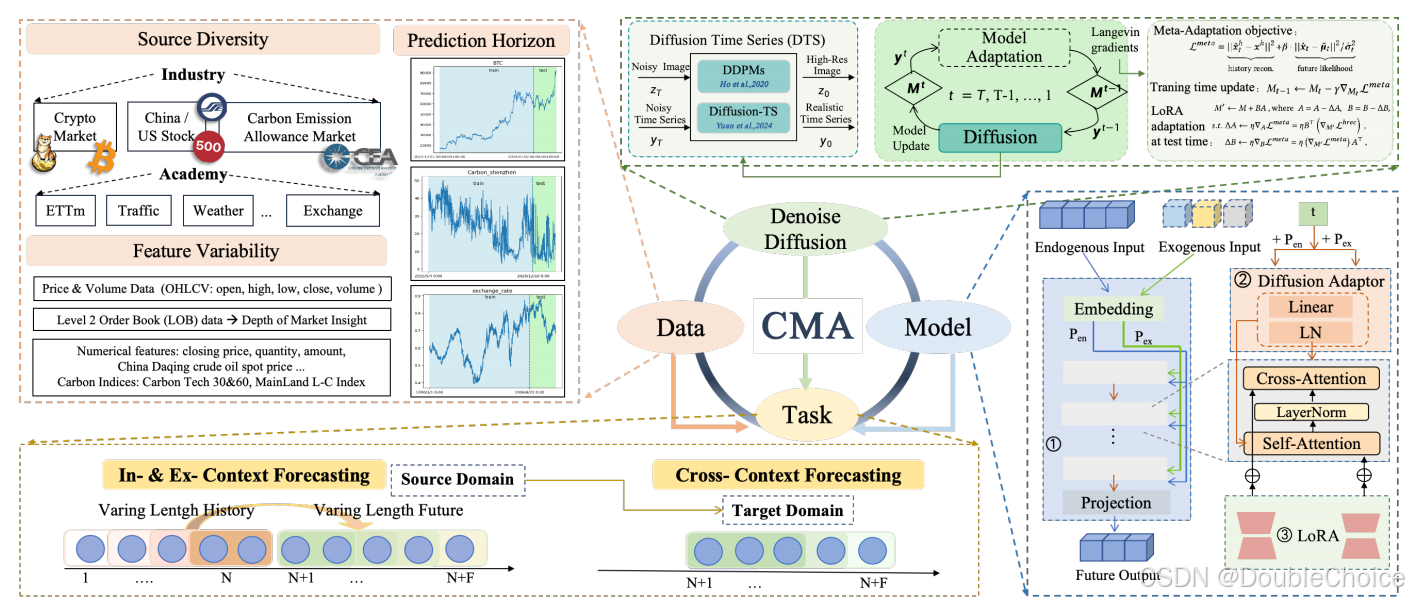
CMA:核心创新点
CMA 的核心是一个迭代式的元自适应过程,它将模型更新与扩散模型的去噪过程深度融合。
1. 通用元自适应过程
在训练时,CMA 的目标是学习如何根据观测数据调整自身参数。它通过优化一个联合学习目标来实现:
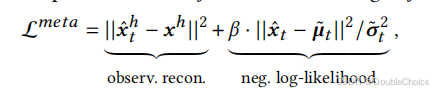
这个损失函数包含两部分:第一项是观测重构损失,确保生成序列与已知的历史数据 xhx^hxh 对齐;第二项是生成序列x的负对数似然,确保生成结果符合数据的整体分布。
在 T 步的去噪过程中,每一步都不仅生成更清晰的序列,还会根据上述 L_meta损失对模型进行一次梯度更新。
这个“生成-更新”的迭代循环,使得模型在完成一次完整的去噪过程后,能够充分适应当前样本的特定模式。
2. 高效的测试时自适应
在推理阶段,对整个模型进行参数更新是昂贵的。为此,CMA 提出低秩测试时自适应。它冻结预训练的主干模型 M,仅更新附加在注意力层中的低秩矩阵 A 和 B。
通过这种方式,模型可以在每个测试样本上进行轻量级的、快速的自适应,而无需进行完整的反向传播。这使得 CMA 在保持高性能的同时,极大地提升了推理效率,使其能够真正应用于实际场景。
三种学习范式
基于元自适应过程,CMA 能够自然地扩展到三种情境学习任务:
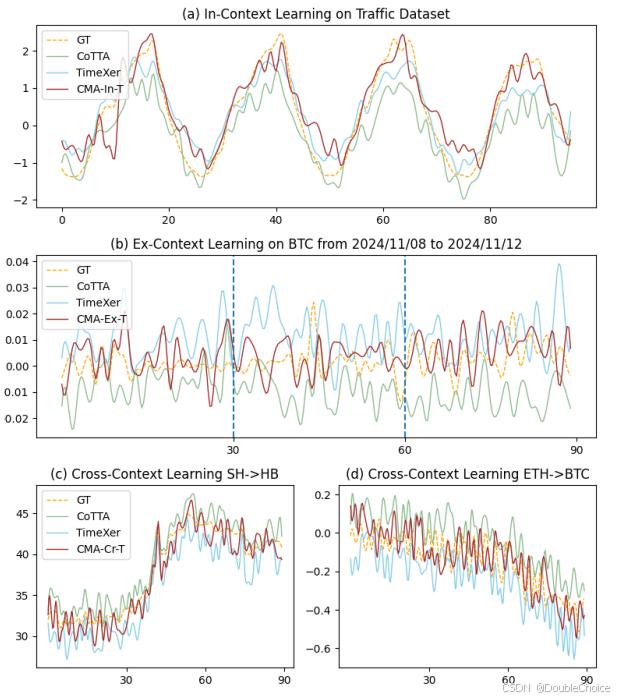
- In-context Learning:通过在历史数据上进行迭代自适应,模型可以处理任意长度的输入序列。
- Ex-context Learning:模型以自回归的方式进行“预测-自适应”循环,从而将预测扩展到任意未来的时间步。
- Cross-context Learning:在新的数据域上,利用 LoRTA 进行快速自适应,实现高效的知识迁移。
实验验证
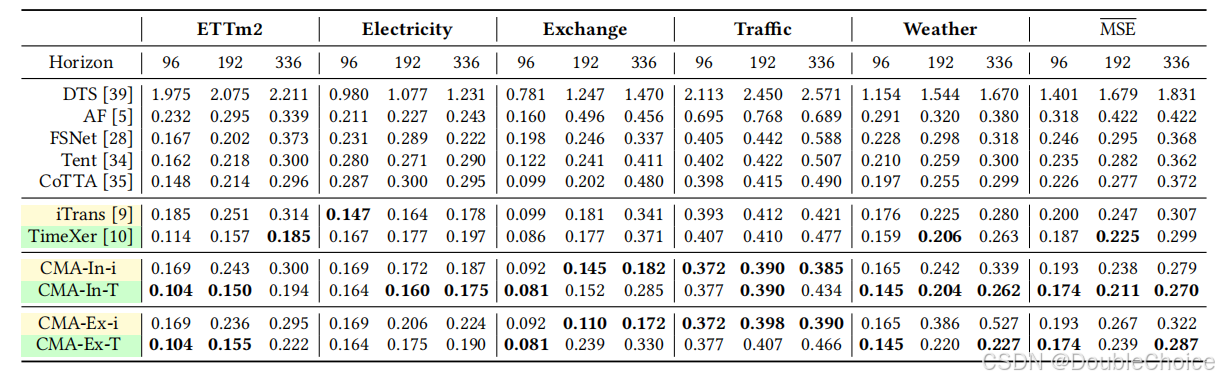
CMA 在多个学术数据集上取得了最先进的性能。以 TimeXer 为主干的 CMA-In-T 模型,在不同预测长度(96, 192, 336)上,相较于其原始主干模型 TimeXer,MSE 分别平均降低了 7%,6% 和 10%。这表明 CMA 的元自适应过程能够有效捕捉数据中的动态模式,从而提升预测精度,尤其是在长期预测任务中优势更为明显。
此外,CMA 不仅效果好,而且效率高。与现有测试时自适应方法相比,CMA 的性能也全面领先,证明了其元学习驱动的扩散过程的优越性。
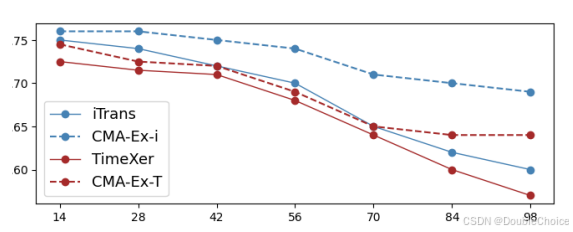
实验探究了模型在 S&P500 数据集上随着预测范围增加的性能变化。传统的 iTrans 和 TimeXer 模型在被强制用于更长预测任务时,性能(R²)会急剧下降。而 CMA-Ex 模型由于具备自适应能力,其性能下降趋势则平缓得多,展现了在未知预测范围下的强大鲁棒性。这得益于 CMA 的自适应机制,它能够持续从最新的预测和历史中学习,动态调整模型以应对未来的不确定性。
总结
本文首先回顾了传统时序预测模型在面对可变历史长度和预测范围时的僵化与局限性。为解决此问题,本文提出了 CMA,一个统一的情境元自适应框架。CMA 巧妙地将去噪扩散过程与元学习相结合,使模型能够在测试时根据具体情境进行高效的自我调整。实验证明,无论是在学术基准还是真实的工业数据集上,CMA 均展现出卓越的预测精度和灵活性。