大数据存储治理三剑客 -- 冷备、压缩、生命周期
1 目标与需求概述
为公司内所有团队(组)提供统一的数据冷备(归档)、压缩与文件合并、生命周期管理(保留/删除/恢复)能力,降低长期存储成本。
支持审计与计费:按组维度统计已用存储与节省量(归档/压缩带来的节省),支持在线预览与存储阈值告警。
提供自助治理平台,让用户自主定义表/目录的治理策略(归档周期、压缩策略、保留策略、访问控制)。
2 方案概览(分层架构)
总体思路:
保留“热数据”在 HDFS/Hive 上可快速访问、对历史分区/冷数据逐步迁移到更低成本的存储(对象存储或冷 HDFS 集群),并通过压缩/合并/列式格式减少占用。
架构分层:
元数据与目录映射层:Hive Metastore + Apache Atlas(或自研元数据服务)
执行层:Data Mover(DistCp 或 Spark 作业)
存储层:HDFS(热/温)、对象存储/冷 HDFS(冷/归档)、可选备份快照集群
审计层: 基于fsimage审计每个部门存储大小,T+1更新数据,再基于NNA实时更新存储大小
治理平台 UI/API:策略配置、报表、告警、审计查询、回收站管理
3 实现细节
3.1 存储分层策略(Hot/Warm/Cold/Archive)
Hot(实时/近实时):最近 N 天(例如最近 30 天)的 Hive 分区,保留在当前 HDFS,低延迟访问。
Warm(查询冷却):30–180 天,仍在 HDFS,但可以启用 EC(Erasure Coding) 减少副本因子(从 3副本降低到 EC),并启用列式压缩(ORC/Parquet + Snappy/Zstd)。
Cold(归档-对象存储):>180 天,迁移到对象存储(S3)或专门的冷 HDFS 集群,保留为列式压缩文件,读取时会触发自动回迁或直接通过外部表读取。
Archive(法律保留/长期备份):满足合规性需求的数据,写入不可变对象或冷快照,保留更长周期,做额外加密与多副本备份。
说明:阈值(30/180 天)可在治理平台由组自定义。
3.2 Hive 表与 HDFS 目录治理
分区优先:要求业务方按日期/业务维度分区(例如 dt=20251022),治理主要以分区为单位执行(避免行级操作)。
外部表最佳实践:建议 Hive 外部表指向 HDFS 路径;迁移/归档操作更改表的分区 LOCATION 指向对象存储路径或创建相应外部表的别名表。
表格式与压缩:统一使用 ORC/Parquet,开启列式压缩(zlib/snappy/zstd)与字典压缩;减少小文件,通过合并任务(Compaction)将小文件合并为大文件(例如 256MB–1GB)以降低 NameNode 内存压力。
事务/ACID 表:若使用 Hive ACID 表,归档需注意事务一致性;建议对于历史分区使用非事务表或在归档前触发 major compaction 并保证没有并发写入。
3.3 数据压缩与小文件治理
压缩策略:
新数据写入时默认使用列式压缩(ORC/Parquet + Snappy/Zstd)。
对历史分区使用更高压缩比(Zstd/DEFLATE)进行二次压缩(离线 compaction)。
小文件合并:定期运行 Spark/Hive compaction job:读取指定分区、合并小文件并写回目标路径(可是覆盖原分区或写入对象存储后切换 LOCATION)。
自动化触发条件:当分区内文件数 > X 或总文件大小 < Y 或平均文件小于 Z(例如平均 < 64MB)时触发合并任务。
3.4 冷备(归档)实现方式
DistCp或者自主开发spark程序进行数据转移(数据转移,数据大小验证,原目录删除等)
使用 HDFS 把文件移动到冷节点或使用 Erasure Coding 降低空间占用;或者用跨集群 DistCp 到冷集群并保留快照。
3.5冷备和压缩流程
本人没有使用DistCp而是采用自研spark任务进行数据的冷备和压缩,冷备和压缩基本流程相似,都是审计需要操作的分区,通过spark任务写入冷备集群,对于压缩则是压缩完再写入原HDFS地址,整个流程最关键的是数据校验和数据完整性监控。因此为了出现故障及时恢复,都需要加个观察期的中间数据,确保冷备和压缩之后的数据没问题,在删除中间数据。
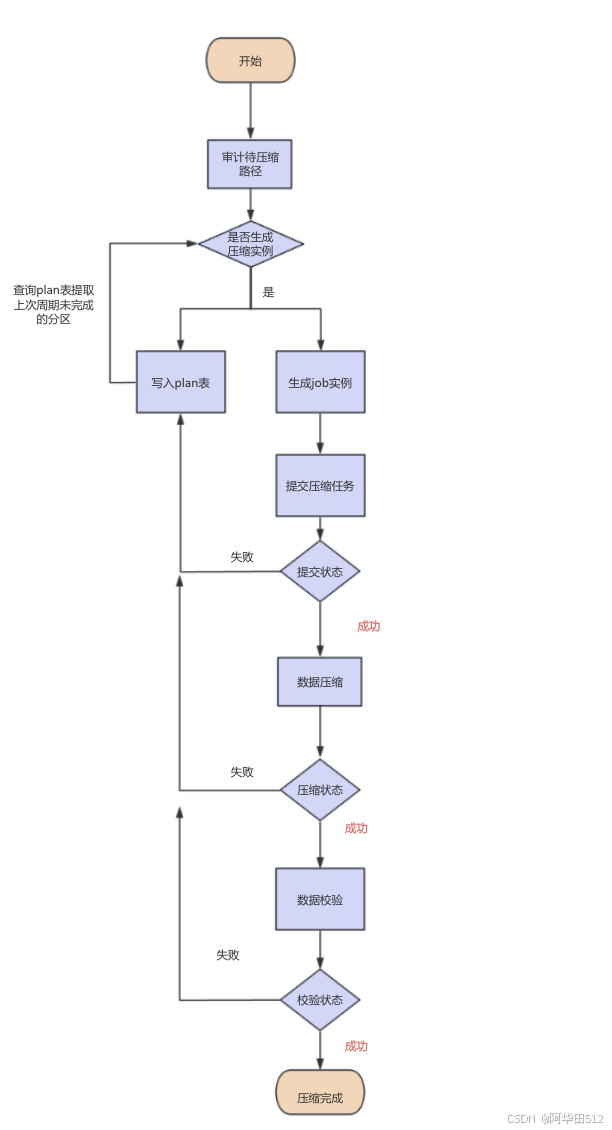
3.6生命周期管理(TTL、保留、Legal Hold)
在治理平台中,为每个表/分区配置策略字段:
hot_days、warm_days、cold_days、archive_days(单位:天)compress_level(默认/高压)compaction_trigger(文件数/平均大小阈值)legal_hold(布尔)及hold_reason、release_date
执行逻辑:Scheduler(基于 Airflow 或 Kubernetes CronJob)定期读取策略并逐级执行:热->warm(EC)->cold(distcp->S3)->archive。
删除回收机制:归档后再删除本地数据前进入“回收站”窗口(例如 7 天),用户可恢复。若 legal_hold=true,则禁用删除/迁移。
3.6 成本优化措施
副本与 EC 调整:热数据保留 3 副本;Warm 使用 Erasure Coding(例如 RS-6-3)降低空间系数;Cold 则以对象存储为主,副本策略由对象存储控制。
压缩与合并:列式压缩 + 小文件合并可大幅降低 NameNode 元数据与 HDFS 存储。
基于使用率的分层迁移:按访问频次自动分层,冷访问迁移减少高成本 HDFS 存储占用。
长期归档到更便宜的类(如 S3 Glacier):若合规允许,将 archive 再降至更低成本冷存储。
3.7 审计与计量(如何统计每个组的使用明细)
数据来源:
NameNode JMX /
fsimage:目录与文件大小、owner、groupHDFS Audit Logs:文件操作行为(创建/删除/rename)
Hive Metastore:表/分区与 owner、location 的元数据
fsimage审计目录存储大小步骤
在 Active NameNode 上触发
saveNamespace()(或等 NameNode 定期做的 fsimage 快照)。从 NameNode 的
dfs.name.dir/current/或fsimage存储目录复制最新的 fsimage 文件到审计机(离线环境)。使用 Hadoop 的 Offline Image Viewer(
oiv)把 fsimage 转换为XML(或Delimited) 格式的可解析输出。用流式解析脚本(Python)扫描 oiv 输出,逐文件聚合到目录路径(注意需要重建完整路径或记录 parent id),并计算逻辑大小与物理占用估算(乘 replication 或根据 EC 估算)。
把聚合结果按目录/组存储到审计表,写入报表/数据库并展示在治理平台或发送告警。
(可选)通过比较不同时间点的 fsimage 审计结果做增长/节省分析