Elasticsearch从入门到进阶——Elasticsearch部署与使用
目录
1 简介
1.1 Elasticsearch简介
1.2 核心概念
2 docker部署elasticsearch
2.1 部署elasticsearch
2.2 部署Kibana
2.3 docker compose容器编排部署方式
3 基本命令
3.1 新增
3.2 查询
3.3 删除
3.4 修改
4 分词器ik
4.1 如何分词
4.2 安装ik分词器
4.3 分词模式
4.3.1 ik_smart分词模式
4.3.2 ik_max_word分词模式
5 SpringBoot项目集成elasticsearch
5.1 引入依赖
5.2 配置文件
5.3 代码示例
5.3.1 定义elasticsearch映射实体类
5.3.2 定义接口继承ElasticsearchRepository接口
1 简介
1.1 Elasticsearch简介
Elasticsearch(ES)是一个分布式搜索引擎,基于Apache Lucene(Lucene是当搜索引擎库)构建。它专为处理海量数据设计,支持结构化/非结构化数据的全文检索、聚合分析及实时监控。核心价值在于解决传统数据库在大数据场景和分布式场景下的检索瓶颈。
比如传统的数据库MySQL,如果想在其中搜索某条记录,基于关键词搜索,通常采用模糊匹配like。在少量数据下,遍历全库的方式系统还能抗住,但是在大量数据下,该操作的效率就会非常低下,因此仅依靠模糊匹配就难以解决关键词搜索的问题。Elasticsearch就能很好的解决这个问题。
1.2 核心概念
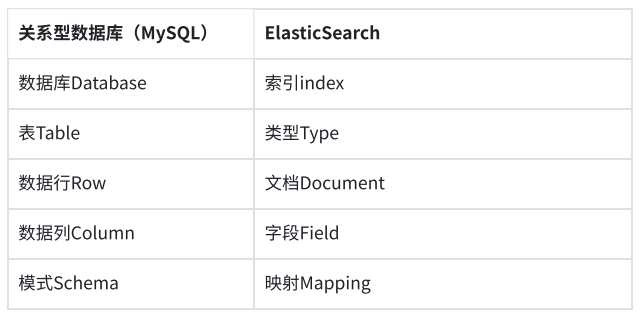
(1)索引Index:索引,具有相同结构的文档集合,类似于关系型数据库的数据库实例(6.0.0版本type废弃后,索引的概念下降到等同于数据库表的级别)。一个集群里可以定义多个索引,如客户信息索引、商品分类索引、商品索引、订单索引、评论索引等等,分别定义自己的数据结构。索引命名要求全部使用小写,建立索引、搜索、更新、删除操作都需要用到索引名称。
(2)类型Type:类型,原本是在索引(Index)内进行的逻辑细分,但后来发现企业研发为了增强可阅读性和可维护性,制订的规范约束,同一个索引下很少还会再使用type进行逻辑拆分(如同一个索引下既有订单数据,又有评论数据),因而在6.0.0版本之后,此定义废弃。
(3)文档Document:文档是一个可被索引的基础信息单元,Document(文档)是JSON格式的,Document就像是MySQL中某个Table表的每一行的数据,Document中可以包含多个字段,每个字段可以是文本、数字、日期等类型。
(4)字段Field:字段是文档中的一个元素或属性,每个字段都有一个数据类型,如字符串、整数、日期等。
(5)映射Mapping:Mapping是ES中的一个很重要的内容,它类似于传统关系型数据中table的schema(定义了数据库中的数据如何组织,包括表的结构、字段的数据类型、键的设置(如主键、外键)等),用于定义一个索引的数据的结构(mapping中主要包括字段名、字段数据类型和字段索引类型。)。在ES中,我们可以手动创建mapping,也可以采用默认创建方式。在默认配置下,ES可以根据插入的数据自动地创建mapping。
以下是Elasticsearch和MySQL概念的对应关系:
2 docker部署elasticsearch
2.1 部署elasticsearch
拉取镜像:
docker pull elasticsearch:8.5.3创建网络:
docker network create elastic-network启动容器:
docker run -d --name elasitc-dev -e "ES_JAVA_OPTS=-Xms256m -Xmx256m" -e "discovery.type=single-node" -v 宿主机路径:/usr/share/elasticsearch/plugins -e "xpack.security.enabled=false" --privileged --network elastic-network -p 9200:9200 -p 9300:9300 elasticsearch:8.5.3由于es需要用到Java,因此需要Java的内存配置,即ES_JAVA_OPTS。
discovery.type=single-node表示单机模式启动。
宿主机路径:/usr/share/elasticsearch/plugins表示将elasticsearch的插件路径挂载到宿主机的路径上,后续通过在宿主机路径放入elasticsearch的插件,可以让elasticsearch在启动时读取插件,比如分词器。
--network elastic-network表示使用该网络统一管理容器通信,因为还需要部署Kibana,该客户端需要连接elasticsearch,因此在同一个网络下容器可以进行通信。
2.2 部署Kibana
Kibana是elasticsearch的可视化客户端,它们之间的关系就类似Navicat和MySQL之间的关系。
拉取镜像,需要注意,kibana的版本需要和elasticsearch版本一致:
docker pull kibana:8.5.3启动容器:
docker run -d --name kibana-dev -e "ELASTICSEARCH_HOSTS=http://elasitc-dev:9200" -e "I18N_LOCALE=zh-CN" -p15601:5601 --net=elasitc-network kibana:8.5.3由于Kibana需要连接elasticsearch,因此需要配置ELASTICSEARCH_HOSTS为elasticsearch的ip+端口号地址。
"I18N_LOCALE=zh-CN"表示使用中文显示界面。
--net=elasitc-network表示和elasticsearch使用同一个网络,这样上述配置elasticsearch的ip就可以直接使用容器名,同一个容器下会自动解析为ip。
2.3 docker compose容器编排部署方式
这里推荐使用容器编排技术来部署上述服务,具体的docker-compose.yml文件如下:
version: '3.8'
#启动命令 docker compose -p 项目名 -f docker-compose-mid.yml up -d
#通过docker-compose-mid.yml文件以后台(-d)启动(up)名为项目名的docker环境(多镜像)
services:elasticsearch-server:container_name: elasticsearch-serverimage: elasticsearch:8.5.3ports:- "9200:9200"# 挂载本地目录用于存储 Elasticsearch的数据、插件。volumes:- ./elasticsearch/es-plugins:/usr/share/elasticsearch/plugins- ../data/elasticsearch/data:/usr/share/elasticsearch/data# 设置为单节点模式,并限制 Java 虚拟机的内存使用。暂时禁用了Elasticsearch的安全特性environment:discovery.type: single-nodeES_JAVA_OPTS: "-Xms1g -Xmx1g"xpack.security.enabled: false# 通过执行 curl 命令检查 Elasticsearch 的集群健康状态。healthcheck:test: [ "CMD", "curl", "-s", "http://localhost:9200/_cluster/health?wait_for_status=green&timeout=1s" ]interval: 30stimeout: 5sretries: 10networks:- elastic_networkkibana-server:image: kibana:8.5.3container_name: kibana-serverports:- "10010:5601"# 依赖于 elasticsearch-server 服务,并在其健康时启动。depends_on:oj-elasticsearch-server:condition: service_healthy# 设置系统语言为中文,并指定连接到 Elasticsearch 的 URLenvironment:I18N_LOCALE: zh-CNELASTICSEARCH_URL: http://elasticsearch:9200networks:- elastic_network# 声明网络elastic_network供上述容器接入
networks:elastic_network:启动结果如下:

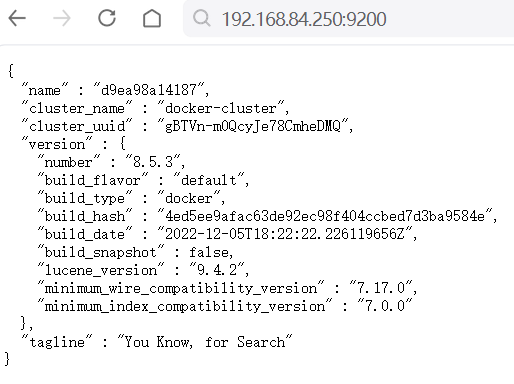
访问ip+端口号可以检验elasticsearch和kibana是否启动成功:
3 基本命令
进入Kibana的开发工具:
3.1 新增
PUT /employee/_doc/1
{"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]
}
PUT /employee/_doc/2
{"first_name" : "Jane","last_name" : "Smith","age" : 32,"about" : "I like to collect rock albums","interests": [ "music" ]
}
PUT /employee/_doc/3
{"first_name" : "Douglas","last_name" : "Fir","age" : 35,"about": "I like to build cabinets","interests": [ "forestry" ]
}使用PUT命令来新增一个文档,索引为employee,_doc是默认类型(6.0.0版本后弃用该概念,变为固定路径),1表示文档id,文档内容是JSON格式,每个JSON的属性即为字段:
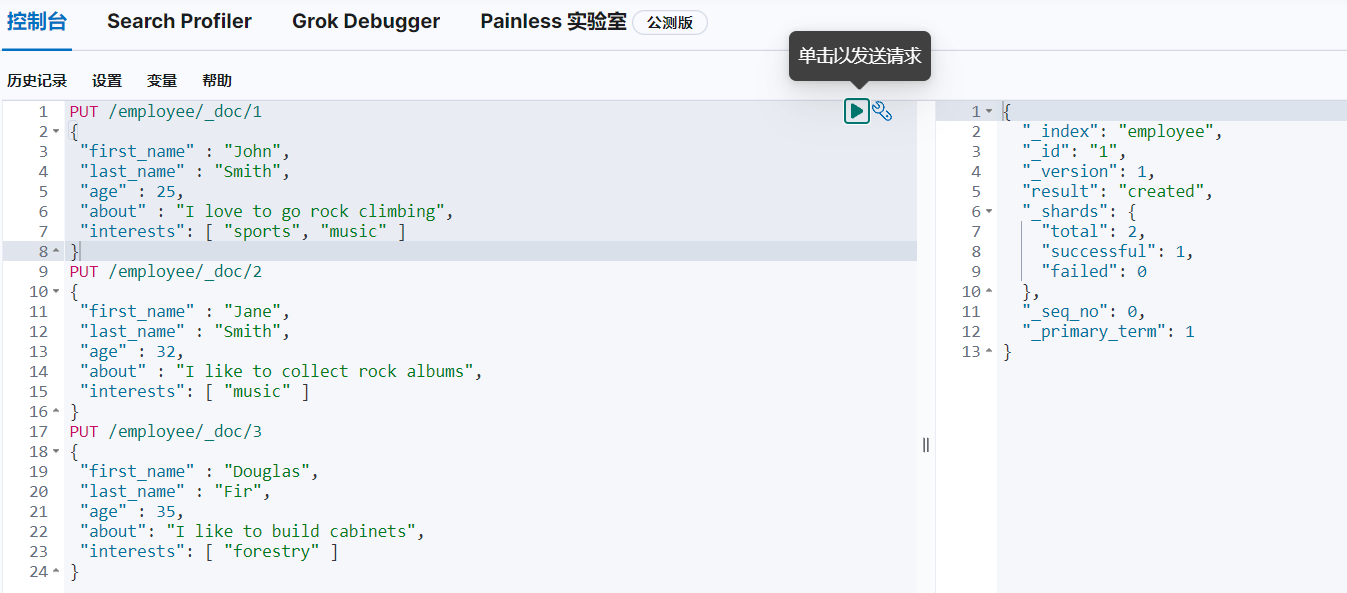
3.2 查询
GET /employee/_search查询employee索引下的全部文档:
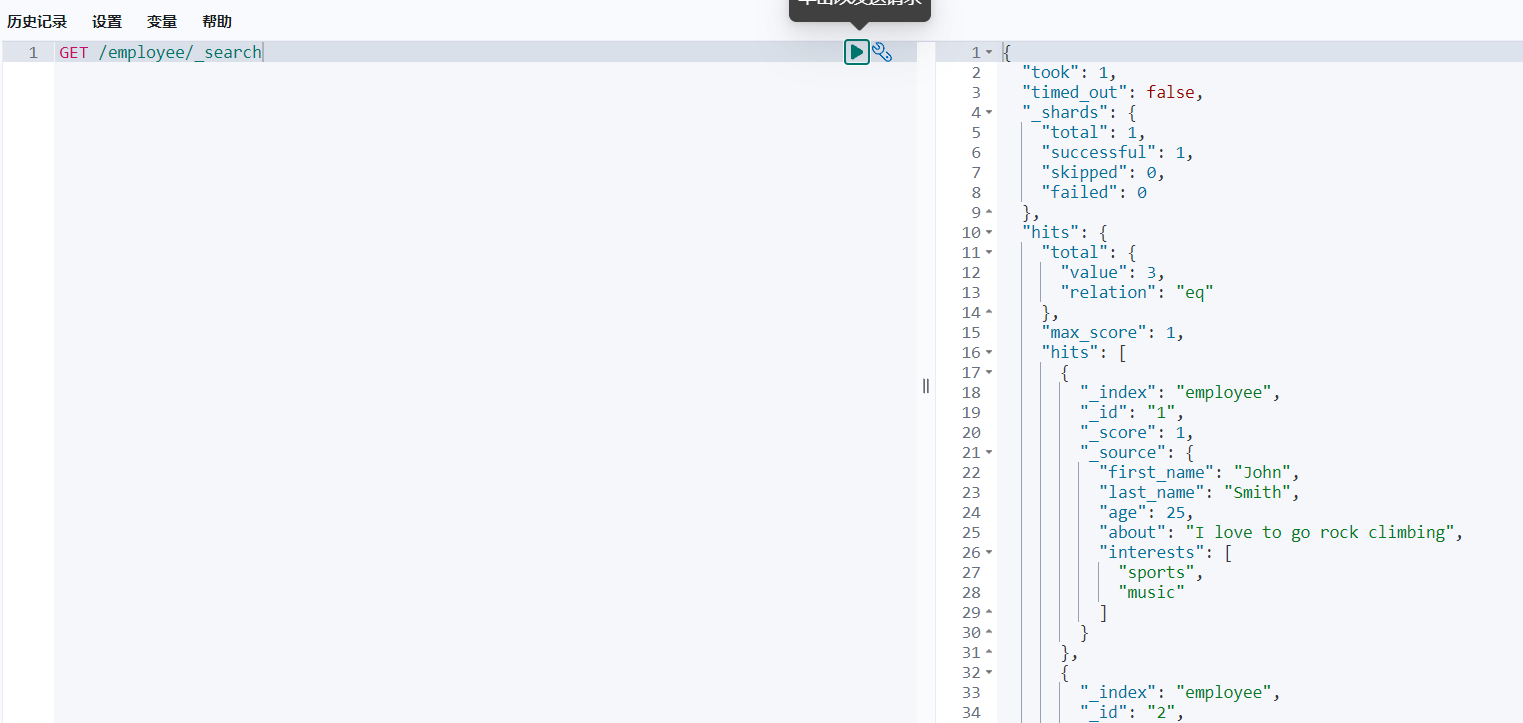
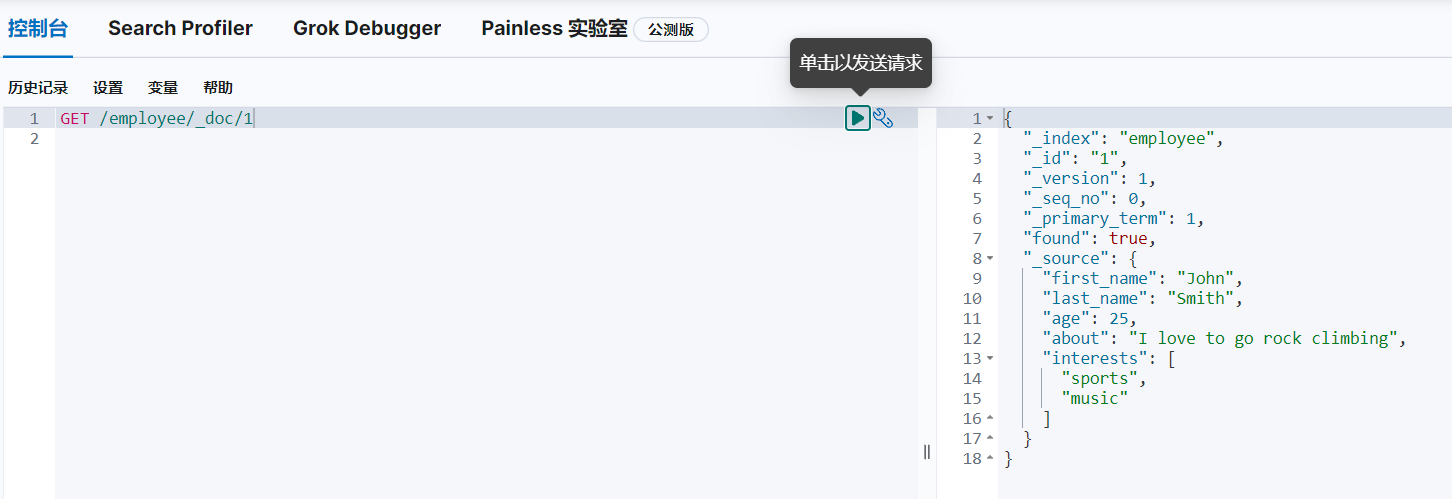
GET /employee/_doc/1
查询文档id为1的文档:
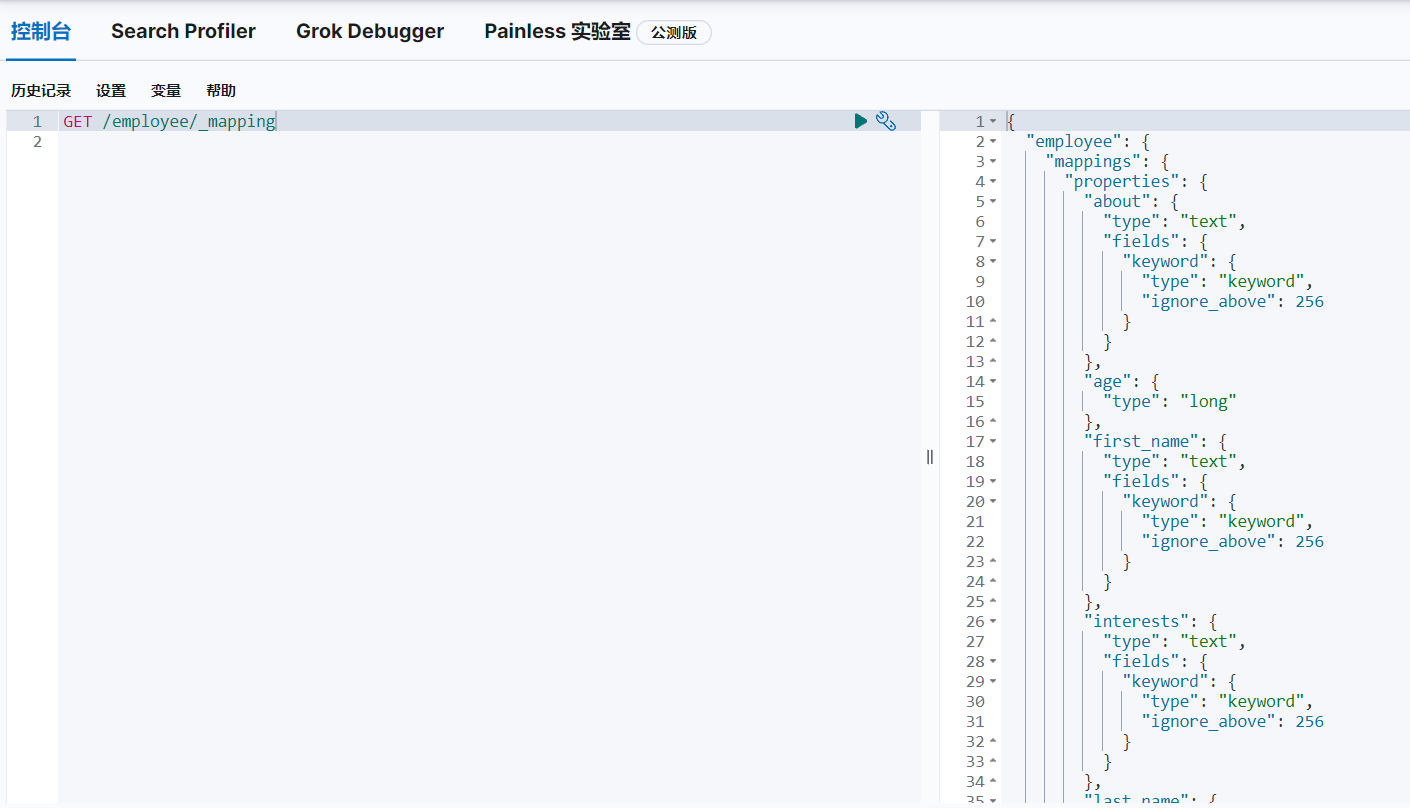
GET /employee/_mapping查询employee索引的数据的结构:
3.3 删除
DELETE /employee/_doc/1删除索引employee下文档id为1的文档:
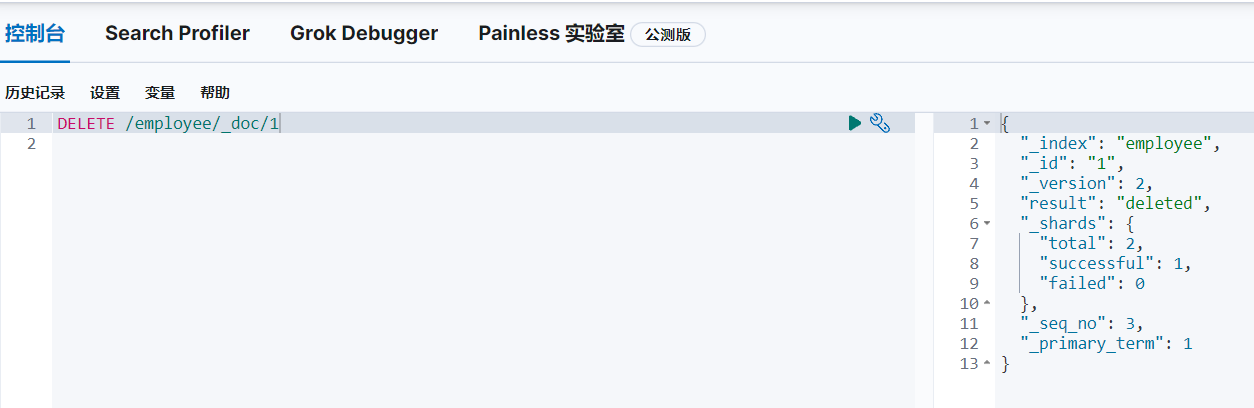
DELETE /employee删除索引employee:
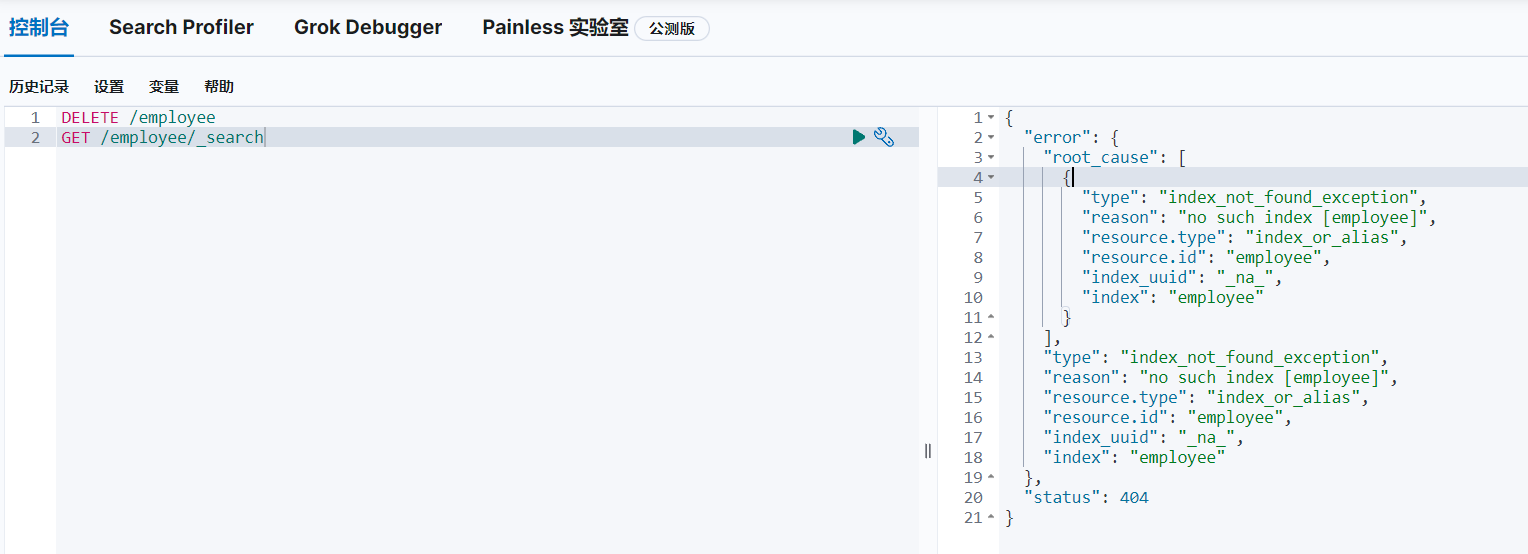
3.4 修改
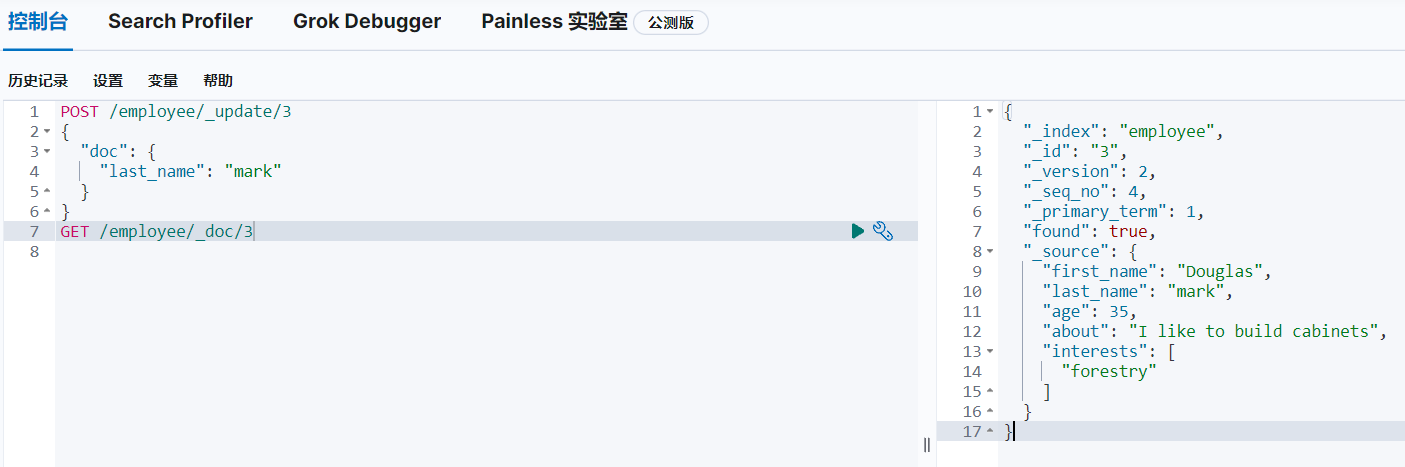
POST /employee/_update/3
{"doc": {"last_name": "mark"}
}
GET /employee/_doc/3POST修改索引employee的文档id为3的文档,修改字段last_name的值为mark:
4 分词器ik
4.1 如何分词
一句话是由一个一个词组成的,分词的最主要目的是便于找到词在哪个文档中出现过,比如我想搜索Java学习路线,分词后可能就是:Java、学习、路线,也可能是Java、学、习、路、线。无论是哪种分词方式,只要我搜索Java,都可以搜到Java学习路线,但是如果搜索学习,那第二种分词方式很可能无法索引到内容。这就是不同分词方式的影响结果。
而Elasticsearch默认采用一个字一个字的分词方式,这不符合中文习惯,需要安装其它分词器。
4.2 安装ik分词器
安装ik分词器需要和Elasticsearch的版本对应,前往下面的地址下载分词器:
ik分词器历史版本![]() https://release.infinilabs.com/analysis-ik/stable/
https://release.infinilabs.com/analysis-ik/stable/
下载完成后,将分词器压缩包解压到es容器内/usr/share/elasticsearch/plugins目录下,也可以通过配置挂载目录的方式将插件放在挂载目录下:
volumes:- ./elasticsearch/es-plugins:/usr/share/elasticsearch/plugins
输入命令检验是否安装成功:
GET _cat/plugins
4.3 分词模式
ik分词器有两种分词模式,根据不同的场景选择不同的分词模式:
4.3.1 ik_smart分词模式
ik_smart分词模式就像名字一样,尽可能聪明,也就是尽可能的保证词语的完整性,从而保证词语的完整语义。比如:喜欢这个词并不会被拆分为喜、欢,而是保留完整词语。
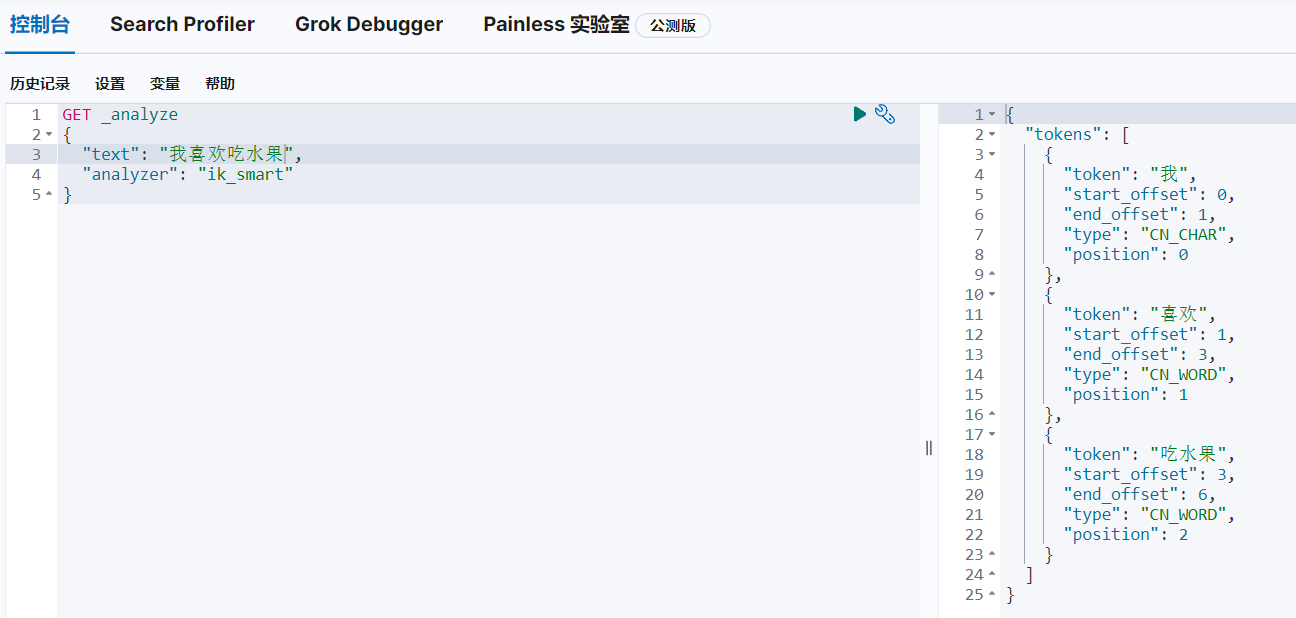
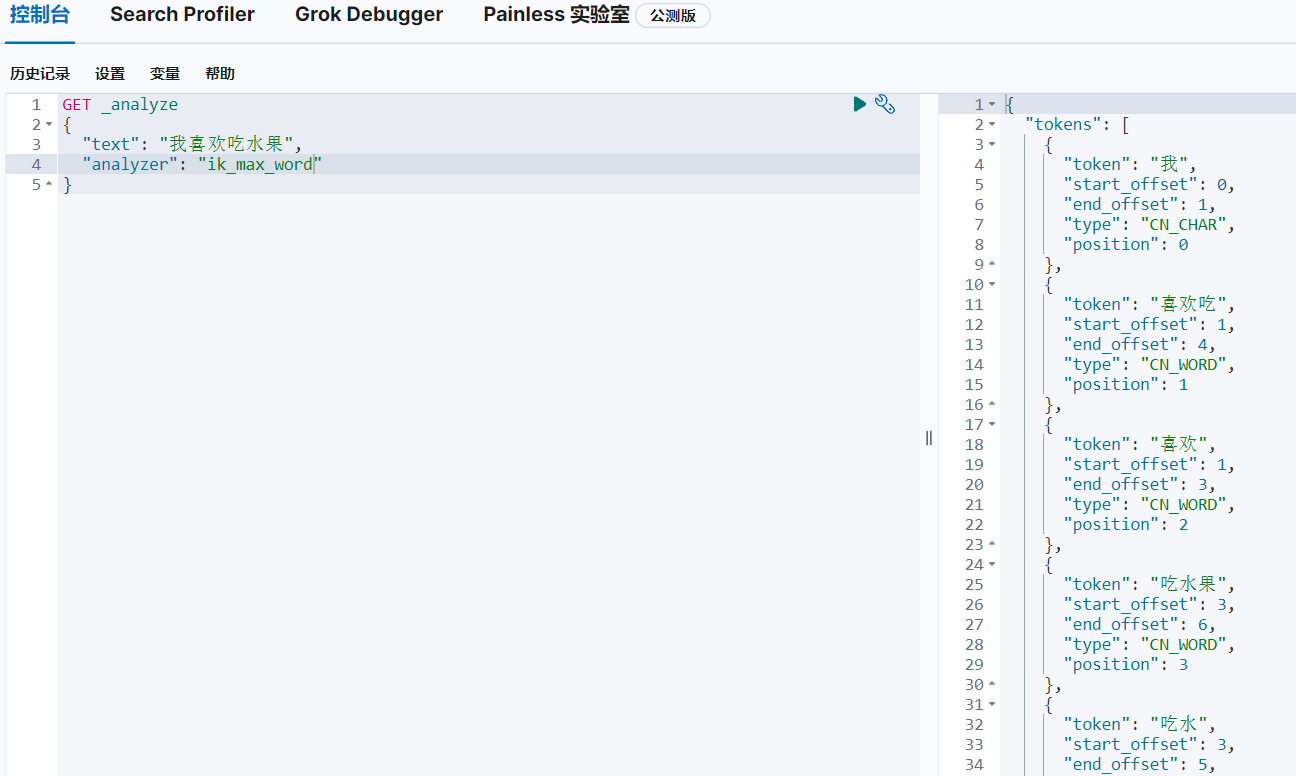
4.3.2 ik_max_word分词模式
ik_max_word分词模式会尽可能多的划分出词组,也就是保证完整词组语义情况下,尽可能多的穷举每个字的词组组合情况:
5 SpringBoot项目集成elasticsearch
5.1 引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>5.2 配置文件
spring:elasticsearch:uris: http://192.168.84.250:9200connectTimeout: 1000socketTimeout: 30000connectionRequestTimeout: 500maxConnTotal: 1005.3 代码示例
将elasticsearch集成到SpringBoot项目中也类似集成mybatis的方式,集成mybatis需要定义数据库映射的实体类,还需要mapper层实现数据库的操作。elasticsearch也需要类似的方式实现:
5.3.1 定义elasticsearch映射实体类
假设正在进行编程题目的数据存储与查询,定义如下实体类:
/*** elasticsearch的题目索引中的文档实体*/
@Getter
@Setter
@Document(indexName = "idx_question")
public class QuestionES {/*** 文档id字段,类型为Long*/@Id@Field(type = FieldType.Long)private Long questionId;/*** 题目标题字段,类型Text,使用ik_max_word作为存储分词器和搜索分词器*/@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")private String title;/*** 题目难度字段,类型Byte,值:1(简单) 2(中等) 3(困难)*/@Field(type = FieldType.Byte)private Integer difficulty;/*** 时间限制,类型Long*/@Field(type = FieldType.Long)private Long timeLimit;/*** 空间限制,类型Long*/@Field(type = FieldType.Long)private Long spaceLimit;/*** 题目内容字段,类型Text,使用ik_max_word作为存储分词器和搜索分词器*/@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")private String content;/*** 题目示例字段,类型Text*/@Field(type = FieldType.Text)private String questionCase;/*** 主函数代码块字段,类型Text*/@Field(type = FieldType.Text)private String mainFuc;/*** 默认代码块字段,类型Text*/@Field(type = FieldType.Text)private String defaultCode;/*** 创建时间字段(排序依据),类型Date*/@Field(type = FieldType.Date, format = DateFormat.date_hour_minute_second)private LocalDateTime createTime;
}5.3.2 定义接口继承ElasticsearchRepository接口
ElasticsearchRepository接口就是spring-boot-starter-data-elasticsearch依赖提供的操作es的接口,需要传入泛型参数<实体类类型, 文档id类型>,然后添加@Repository注解交给Spring管理:
/*** elasticsearch操作对象:类似关系型数据库的mapper层*/
@Repository
public interface QuestionRepository extends ElasticsearchRepository<QuestionES, Long> {/*** 根据题目难度从es中查找分页题目列表* @param difficulty 题目难度* @param pageable 分页参数* @return 题目列表分页数据*/Page<QuestionES> findByDifficulty(Integer difficulty, Pageable pageable);/*** 根据(题目标题、题目内容)(或的关系)、题目难度查找分页题目列表* @param keywordTitle 标题关键字* @param keywordContent 内容关键字* @param difficulty 题目难度* @param pageable 分页参数* @return 题目列表分页数据*///select * from tb_question where (title like '%aaa%' or content like '%bbb%') and difficulty = 1@Query("{\"bool\": {\"should\": [{ \"match\": { \"title\": \"?0\" } }, { \"match\": { \"content\": \"?1\" } }], \"minimum_should_match\": 1, \"must\": [{\"term\": {\"difficulty\": \"?2\"}}]}}")Page<QuestionES> findByTitleOrContentAndDifficulty(String keywordTitle, String keywordContent,Integer difficulty, Pageable pageable);}常见的查询操作支持根据字段的简单查询和根据条件或模糊匹配的复杂查询,方法命名规范如下:
(1)命名方式:findBy[字段][操作],并在形参定义查询参数。无需实现方法即可自动生成查询;
(2)@Query:如果查询条件复杂,可以通过@Query自定义查询语句,注解的内容是es的查询语法。
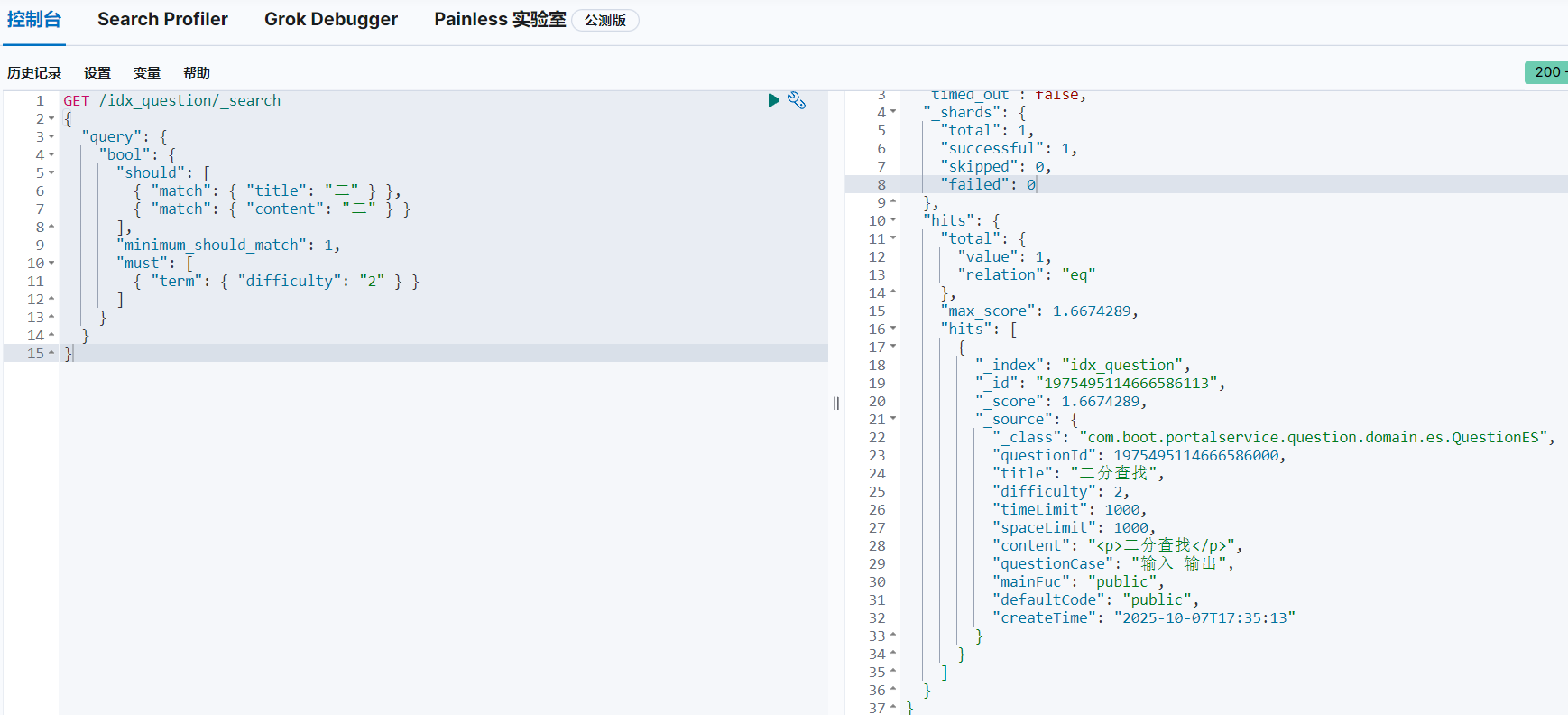
比如,上述查询语句为:
GET /idx_question/_search
{"query": {"bool": {"should": [{ "match": { "title": "?0" } },{ "match": { "content": "?1" } }],"minimum_should_match": 1,"must": [{ "term": { "difficulty": "?2" } }]}}
}bool表示复合查询;
should子句表示应该满足的条件:title字段需匹配参数?0,content字段需匹配参数?1;
minimum_should_match: 1表示至少满足其中一个条件(逻辑or),如果不加该语句,should子句的条件可能一个都不满足也能执行。
must子句表示必须满足的条件:difficulty字段必须精确匹配参数?2;
查询类型有match和term两种,match:对文本字段进行分词匹配(如title、content);term:对精确值字段直接匹配(如difficulty枚举值)。
注意事项:参数占位符?0、?1、?2需替换为实际搜索值。
而集成到SpringBoot的es的操作方法,只需要在需要调用方法的地方执行即可。
主要用到的操作就是存和取,存的话可以调用ElasticsearchRepository接口提供的save()和saveAll()两种方法:

save()方法主要存实体实例,saveAll()方法主要存可迭代的集合实例,比如list列表。