【论文精读】EvalCrafter:文本到视频生成模型的全面评测框架
标题:EvalCrafter: Benchmarking and Evaluating Large Video Generation Models
作者:Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, Ying Shan
单位:Tencent AI Lab;City University of Hong Kong;University of Macau;The Chinese University of Hong Kong
发表:arXiv preprint arXiv:2310.11440v3 [cs.CV],发布日期 2024 年 3 月 23 日
论文链接:https://arxiv.org/pdf/2310.11440
项目链接:http://evalcrafter.github.io
关键词:文本到视频生成(Text-to-Video Generation, T2V)、模型评测基准(Evaluation Benchmark)、客观指标体系(Objective Metric System)、人类偏好对齐(Human Preference Alignment)、生成式 AI(Generative AI)、扩散模型(Diffusion Models)
一、研究背景与核心痛点
近年来,生成式 AI 在视觉领域进展显著:文本到图像(T2I)模型如 Stable Diffusion(SD)、SDXL 已能生成高保真图像;T2V 技术也借助扩散模型的 temporal 扩展(如 LVDM、MagicVideo)与商业服务(如 Gen2、PikaLab)实现突破。但当前 T2V 评测存在三大核心痛点,严重制约技术迭代方向的判断:
-
指标单一化,覆盖维度不足现有评测多依赖 FVD、IS 等传统 GAN 指标,仅关注 “生成视频与真实视频的分布匹配”,却忽略 T2V 的核心需求 —— 文本与视频的对齐性、运动的自然性、帧间的时间一致性。例如,FVD 无法判断生成视频是否符合 “红色汽车行驶” 的 prompt 描述,也无法评估 “汽车运动是否连贯”。
-
基准缺失,实验不可比缺乏统一、多样化的评测 prompt 集合:部分研究使用自定义 prompt,部分依赖小样本数据集,导致不同模型的性能对比缺乏公平性。例如,某模型在 “简单风景” prompt 上表现优异,但在 “复杂人类动作” prompt 上完全失效,却因基准单一未被发现。
-
客观指标与人类偏好脱节单纯平均客观指标无法反映用户真实感受:例如,某模型运动幅度大(Flow-Score 高),但用户可能更偏好轻微、自然的运动;高分辨率模型未必比低分辨率模型更受青睐。
为解决上述问题,EvalCrafter 提出 “多样化基准 + 多维度指标 + 人类对齐” 的三位一体评测框架,填补了 T2V 全面评测的空白。

注:灰色模块为 prompt 的元类别(Food、Human、Animal、Object 等)与关键属性(Actions、Style、Camera motion等);黑色圆圈为四大评测维度(Visual qualities、Content qualities、Motion qualities、Text-video alignment)
二、核心设计:基准构建与指标体系
EvalCrafter 的两大核心创新的是 “覆盖真实需求的评测基准” 与 “针对性的多维度指标”,二者结合实现了对 T2V 模型的 “全维度扫描”。
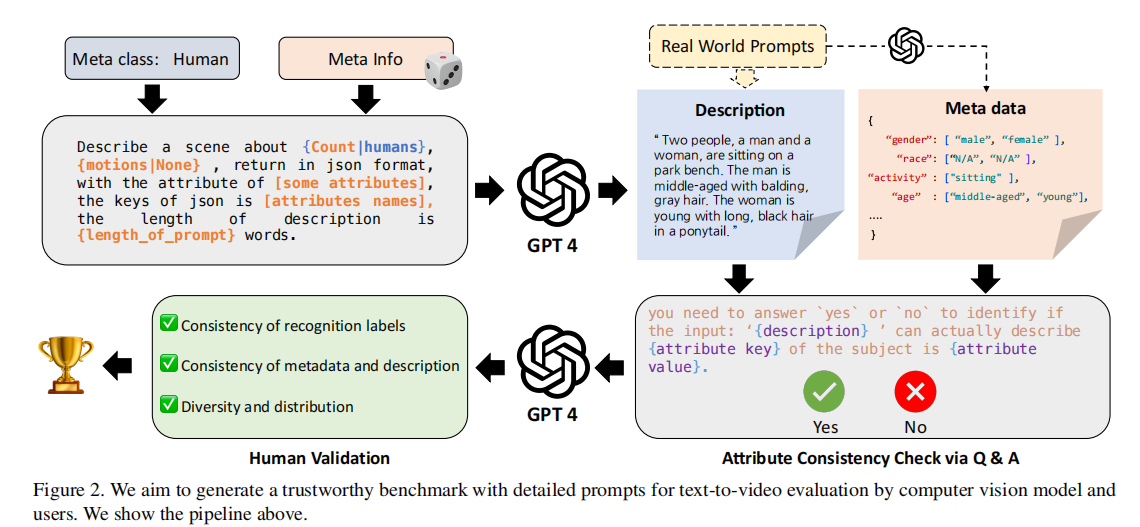
注:展示从 “真实世界 prompt” 到 “最终可评测 prompt” 的全流程:人类定义元类别→GPT-4 生成描述与元数据→GPT-4 问答式校验一致性→人工验证属性匹配度。
2.1 评测基准构建:700 个 prompt 的 “真实 + 多样 + 可标注” 逻辑
基准的核心目标是 “反映真实用户需求、覆盖多场景、支持精准评测”,构建过程分为数据采集分析、prompt 生成校验、基准优化三步,每一步均以 “实用性” 为导向:
步骤 1:真实用户数据采集与分析
研究团队从 T2V 用户活跃的 Discord 社区(如 FullJourney、PikaLab)收集了60 万条真实 prompt,过滤重复、无意义内容后保留 20 万条有效数据。通过统计分析,明确了用户需求的核心特征:
- 长度分布:90% 的 prompt 包含 3-40 个单词,平均长度 12.3 个单词,与真实用户输入习惯一致;
- 核心元类别:用户需求集中在四大类 ——人类(Human)、动物(Animal)、物体(Object)、风景(Landscape),占比超 80%;
- 关键属性:50% 以上的 prompt 包含 “风格(如水彩画、赛博朋克)”“运动(如跑步、跳跃)”“相机动作(如平移、缩放)” 等细节描述。
这些发现为后续 prompt 的生成提供了 “真实锚点”,避免基准与实际需求脱节。
步骤 2:prompt 生成与一致性校验
为保证基准的 “多样性” 与 “可评测性”,prompt 通过 “LLM 辅助生成 + 双重校验” 生成,流程如下:
- LLM 生成初始 prompt:基于四大元类别,使用 GPT-4 生成包含具体属性的场景描述。例如,针对 “人类” 元类别,生成 “Two people, a man and a woman, are sitting on a park bench. The man is middle-aged with balding, gray hair. The woman is young with long, black hair in a ponytail”,同时提取元数据(如 “gender: [male, female]”“age: [middle-aged, young]”);
- GPT-4 自校验一致性:由于 GPT-4 生成的 “属性” 与 “描述文本” 可能不一致(如描述中未提及 “女性头发颜色”,却标注 “black hair”),研究团队让 GPT-4 以问答形式验证(如 “Is the woman's hair color mentioned in the description? If yes, what is it?”),过滤不一致的 prompt;
- 人工筛选与补充:加入真实用户 prompt 与 T2I 评测基准(如 DALL-Eval、Draw-Bench)中的优质 prompt,确保覆盖 “风格化”“复杂动作” 等特殊场景。
最终形成700 个 prompt的基准集合,每个 prompt 均包含完整的元数据标注(颜色、数量、动作等),为后续指标计算提供 ground truth。
步骤 3:基准的多样性与结构优化
最终的 700 个 prompt 具备三大特点,确保对模型能力的 “全面探测”:
- 元类别均衡覆盖:四大元类别各含 175-200 个 prompt,每个类别下细分 “真实场景”“风格化场景”“相机控制场景”;
- 属性丰富度:包含 50 种风格(如 Hokusai 浮世绘、SD 游戏风)、20 种相机动作(如 pan left、zoom in),随机嵌入 250 个 prompt 中;
- 长度匹配真实需求:平均长度 12.3 个单词,与真实用户 prompt 分布一致,避免因 prompt 过长 / 过短导致的评测偏差。
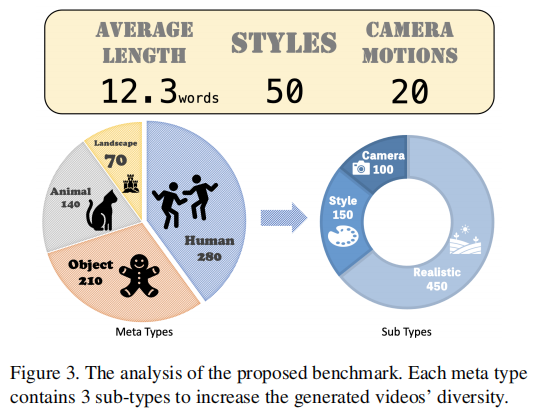
注:左侧展示基准 prompt 的平均长度(12.3 words)、风格数量(50 种)、运动类型(20 种)、相机动作(7 种);右侧展示四大元类别的子类型分布(每个元类别含 3 个子类型,如 “人类” 含 “单人”“多人”“带动作人类”)。
2.2 多维度指标体系:针对 T2V 特性的 17 个客观指标
EvalCrafter 首次将 T2V 评测分为四大核心维度,设计 17 个客观指标,覆盖从 “视觉观感” 到 “文本对齐” 再到 “运动连贯性” 的全链条需求,每个指标均针对 T2V 的技术痛点设计,而非简单复用 T2I 指标。
维度 1:视频视觉质量(Visual Quality)
评估视频的 “观感优劣”,包括美学价值与技术缺陷,核心指标 3 个:
- VQA_A(美学质量评分):基于 Dover 模型(训练数据含人类标注的美学偏好),评估视频的构图、色彩协调性等美学属性,分数越高表示越符合人类审美;
- VQA_T(技术质量评分):同样基于 Dover 模型,评估视频的噪声、模糊、伪影等技术缺陷,分数越高表示技术质量越好;
- IS(Inception 分数):复用 T2I 经典指标,通过 ImageNet 预训练的 Inception 网络,评估视频帧的 “多样性” 与 “真实性”,分数越高表示内容越多样且贴近真实世界。
维度 2:文本 - 视频对齐(Text-Video Alignment)
验证 “生成视频是否符合 prompt 描述”,是 T2V 的核心需求,核心指标 7 个:
- CLIP-Score:使用 CLIP-ViT-B/32 模型,计算每帧图像嵌入与文本嵌入的余弦相似度,取平均值作为全局对齐分数;
- SD-Score:针对 T2V 模型多基于 SD 微调的特性,用 SDXL 生成 5 张 prompt 对应的参考图像,计算视频帧与参考图像的嵌入相似度,解决 “微调导致的概念遗忘”(如 SD 能生成 “红色汽车”,但微调后的 T2V 模型却生成 “蓝色汽车”);
- BLIP-BLEU:用 BLIP2 模型生成视频的 5 段文本描述,计算描述与原 prompt 的 BLEU 分数,从 “文本转述” 角度验证对齐性;
- Detection-Score:用 SAMTrack(分割跟踪模型)检测视频中是否存在 prompt 指定物体(如 “猫”),每 5 帧检测一次,计算 “存在目标物体的帧占比”;
- Count-Score:评估物体数量的准确性,公式为
(
为检测数量,
为真实数量),分数越高表示数量越准确;
- Color-Score:检测物体颜色是否与 prompt 一致(如 “红色汽车”),每 5 帧检测一次,计算 “颜色匹配的帧占比”;
- OCR-Score:用 PaddleOCR 检测视频中的文字,计算 Word Error Rate(WER)、Normalized Edit Distance(NED)、Character Error Rate(CER)的平均值,评估文本生成能力(T2V 的常见痛点)。
维度 3:运动质量(Motion Quality)
视频与图像的核心差异在于 “运动”,评估运动的 “自然性” 与 “符合 prompt 描述性”,核心指标 3 个:
- Action-Score:用 MMAction2 工具包与预训练的 VideoMAE V2 模型,识别人类动作(如 “跑步”“跳跃”),以分类准确率为分数,仅针对含人类的 prompt;
- Flow-Score:用 RAFT 模型计算相邻帧的光流(运动向量),取平均值作为运动强度指标(中性指标,无绝对优劣,需结合 prompt 判断);
- Motion AC-Score:基于 Flow-Score 设定阈值 ρ=5(通过人类主观观察确定),判断视频运动幅度是否与 prompt 一致(如 “轻微晃动” 对应 Flow-Score<5,“快速行驶” 对应 Flow-Score>5),分数越高表示一致性越好。
维度 4:时间一致性(Temporal Consistency)
评估 “帧间内容的连贯性”,避免 “跳帧”“物体突变” 等问题,核心指标 3 个:
- Warping Error:用光流将前一帧 “扭曲(warp)” 到后一帧位置,计算扭曲后图像与真实后一帧的像素差异,取平均值 —— 分数越低表示帧间变化越平滑,一致性越好;
- CLIP-Temp:计算相邻帧的 CLIP 嵌入余弦相似度,取平均值 —— 分数越高表示帧间语义一致性越好(如 “汽车” 不会突然变成 “树”);
- Face Consistency:针对含人脸的 prompt,以第一帧人脸为参考,计算后续帧与人脸嵌入的余弦相似度 —— 分数越高表示人脸身份越稳定(如 “某名人” 不会突然变成陌生人)。
2.3 人类偏好对齐:让指标贴合用户真实感受
客观指标与人类主观感受常存在偏差:例如,高 Flow-Score(运动幅度大)未必受用户喜欢,高分辨率也不代表视觉吸引力更强。EvalCrafter 通过线性回归模型,将客观指标与人类评分对齐,实现 “指标分数 = 用户偏好” 的映射,具体步骤如下:
最终收集 8647 条评分,过滤异常数据(如标准差 > 1.5 的评分)后,保留 1024 条有效数据作为对齐训练集。
-
用户研究设计选择 5 个代表性 T2V 模型(ModelScope、ZeroScope、Gen2、Floor33、PikaLab),基于 700 个 prompt 生成 2500 个视频(每个 prompt 对应 5 个模型);为保证公平性:
- 统一 Gen2、PikaLab 的视频宽高比为 16:9(与其他模型一致);
- 为所有视频添加 PikaLab 水印(因 PikaLab 无法生成无水印视频);
- 用 SDXL 生成 3 张参考图像,帮助标注者理解 prompt 含义。
-
评分规则与数据筛选邀请 7 名专业标注者,从 5 个维度评分(1-5 分,5 分为最佳):
- 视觉质量:模糊、噪声等缺陷的严重程度;
- 文本 - 视频对齐:视频是否符合 prompt 描述;
- 运动质量:运动是否自然、符合 prompt;
- 时间一致性:帧间是否连贯;
- 主观喜好:整体是否符合用户偏好。
- 对齐模型训练与验证用 80% 的有效数据训练线性回归模型:以 “四大维度的客观指标” 为输入,以 “人类评分” 为输出,通过最小化残差平方和拟合指标权重;用 20% 的数据验证效果 —— 结果显示,对齐后的综合分数与人类评分的 Spearman 相关系数(ρ)、Kendall 相关系数(ϕ)均高于 “单纯平均客观指标”,证明对齐模型有效。
三、实验结果与图表解读
EvalCrafter 对 8 个主流 T2V 模型(含 6 个开源模型、2 个商业模型)进行了全面评测,通过 “模型基础参数对比”“各维度性能排名”“指标与人类评分相关性” 三大实验,揭示 T2V 模型的真实性能差异与技术瓶颈。
3.1 模型基础参数对比
表 1 展示了 8 个评测模型的核心参数,是后续性能对比的 “公平性基础”:
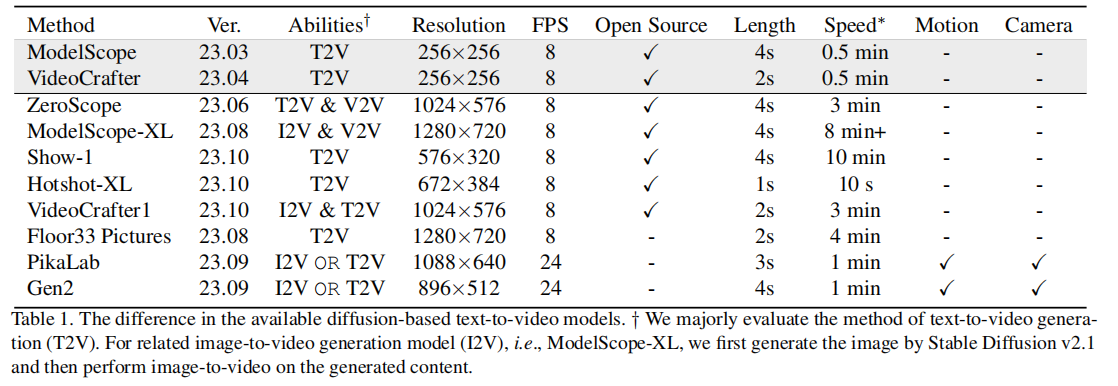
- 开源模型多聚焦 T2V 能力,分辨率集中在 256×256-1024×576,帧率均为 8 FPS,生成速度差异大(Hotshot-XL 仅 10 秒,ModelScope-XL 需 8 分钟 +);
- 商业模型(PikaLab、Gen2)支持 I2V(图像到视频)、更高帧率(24 FPS)与运动 / 相机控制,但闭源且生成速度固定(1 分钟);
- 分辨率与开源 / 闭源无绝对关联:ModelScope-XL(开源)分辨率(1280×720)高于 Gen2(商业,896×512),为后续 “分辨率与视觉质量无关联” 的发现埋下伏笔。
3.2 模型各维度性能排名
表 2 展示了 8 个模型在四大维度的 “人类偏好对齐后得分”(括号内为排名),图 4 展示了模型的综合性能对比,二者共同了揭示模型的 “长板与短板”:
表 2:人类偏好对齐后的模型各维度得分与排名
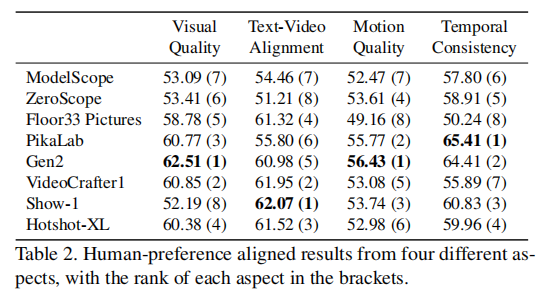
图 4:模型综合性能对比
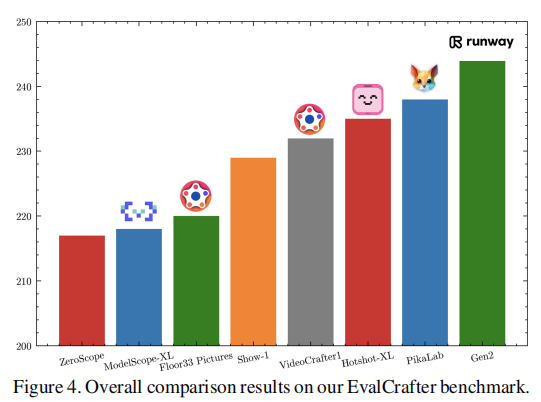
- 核心内容:以柱状图展示 8 个模型的 “人类偏好对齐后综合得分”,Gen2、VideoCrafter1、PikaLab 位列前三,Show-1、ModelScope 排名靠后。
- 解读:综合得分反映模型的 “全面性”——Gen2 因视觉质量、运动质量、时间一致性均位列前 2,成为综合最优;Show-1 虽文本对齐第一,但视觉质量垫底,综合得分低。
关键结论:
- 商业模型在 “运动与时间一致性” 上优势显著:Gen2(运动质量 1、时间一致性 2)、PikaLab(运动质量 2、时间一致性 1)的帧间连贯性与运动自然性远超开源模型,这与二者支持 24 FPS、运动控制有关;
- 开源模型在 “文本对齐” 上有惊喜:Show-1(文本对齐 1)、VideoCrafter1(文本对齐 2)的文本 - 视频匹配度高于商业模型,可能因开源模型更易基于 SD 的文本理解能力微调;
- 无 “全能模型”:所有模型均有明显短板 —— 如 Floor33 文本对齐第 4,但运动质量、时间一致性均为第 8;ModelScope 各维度均处于中下游,无突出能力。
3.3 指标与人类评分的相关性
表 3 展示了客观指标与人类评分的 Spearman(ρ)、Kendall(ϕ)相关系数”:
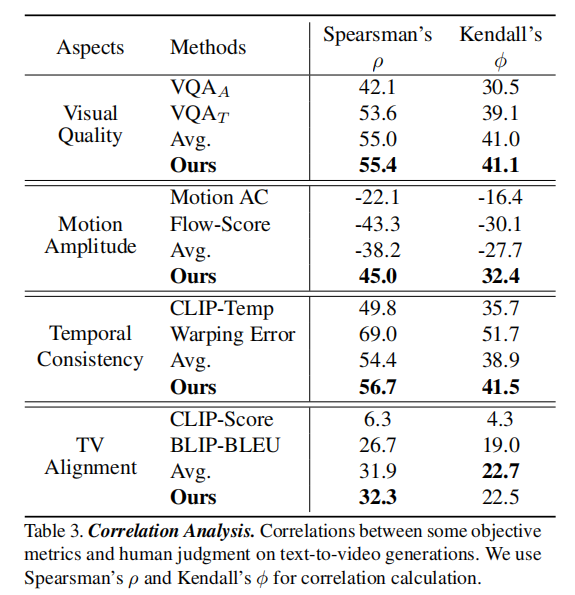
关键结论:
- 部分 “常用指标” 相关性极低:CLIP-Score(文本对齐)与人类评分的 Spearman 相关系数仅 6.3,远低于 BLIP-BLEU(26.7),证明 CLIP-Score 无法有效反映文本 - 视频的真实对齐性;
- 运动幅度指标与人类偏好负相关:Motion AC-Score、Flow-Score 与人类评分的相关系数均为负(-22.1、-43.3),说明用户反感 “过大的运动幅度”,偏好轻微、自然的运动;
- 对齐模型提升指标有效性:所有维度的 “对齐后指标” 相关性均高于 “平均指标”,尤其是运动幅度维度(从 - 38.2 提升至 45.0),证明人类偏好对齐的必要性。
3.4 模型在不同元类别与风格上的性能
图 6 展示了 8 个模型在 “四大元类别(人类、动物、物体、风景)” 与 “两种风格(真实、风格化)” 上的指标表现,揭示模型的 “场景适应性”:
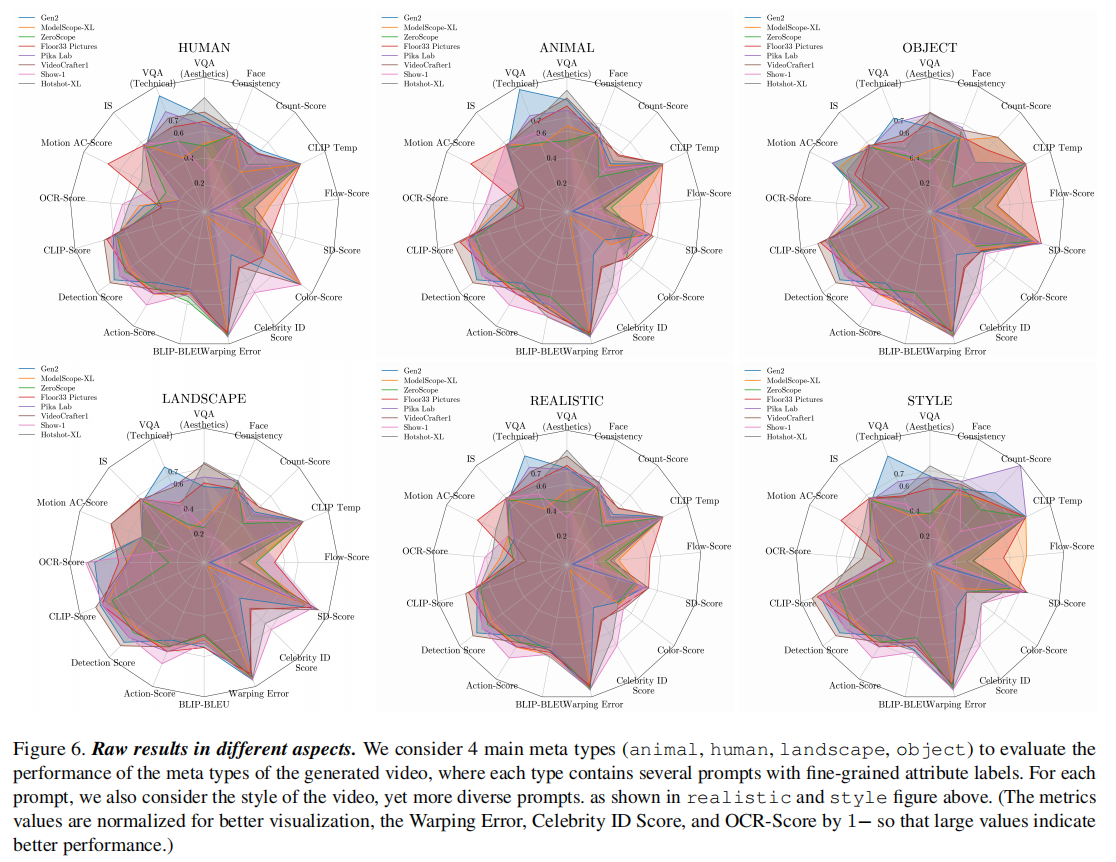
- 核心内容:以子图形式展示每个模型在不同元类别、风格上的关键指标(如 VQA_A、CLIP-Score、Warping Error),指标值已归一化(Warping Error、OCR-Score 等 “越低越好” 的指标用 1 - 原值处理,确保高值表示优)。
- 解读:
- 元类别适应性差异大:Gen2 在 “人类、动物” 元类别上的 VQA_A(美学质量)高于 Floor33,但在 “风景、物体” 元类别上低于 Floor33;
- 风格化场景更具挑战性:所有模型在 “风格化” 场景(如 Hokusai 风格)的 CLIP-Score(文本对齐)均低于 “真实” 场景,说明模型对风格化 prompt 的理解仍不足;
- 人脸一致性差异显著:PikaLab 在 “人类” 元类别上的 Face Consistency(人脸一致性)最高,ZeroScope 最低,证明部分模型存在 “人脸突变” 问题。
四、10 个颠覆性关键发现
EvalCrafter 通过全面实验,总结出 10 个关于 T2V 技术现状的关键发现,这些发现颠覆了传统认知,为后续模型优化与评测设计提供了明确方向:
发现 1:单一维度评测无意义
模型在不同维度的排名差异极大 —— 如 Show-1 文本对齐第一,但视觉质量第八;Floor33 文本对齐第四,但运动质量第八。这证明 “仅看某一维度性能” 无法判断模型的实际可用性,必须通过多维度综合评测。
发现 2:元类别评测不可或缺
模型在不同元类别上的表现差异显著 ——Gen2 在 “人类、动物” 上的 VQA_A 高于 Floor33,在 “风景、物体” 上却低于 Floor33;ZeroScope 在 “物体” 元类别上的 Detection-Score(物体检测)高于 ModelScope,但在 “人类” 元类别上更低。这说明评测必须按元类别细分,避免 “以偏概全”。
发现 3:用户更看重视觉吸引力而非文本对齐
Gen2 的文本 - 视频对齐排名仅第 5,但主观喜好度排名第 1—— 原因是其视觉质量(第 1)、时间一致性(第 2)更优。这证明用户对 “好看” 的优先级高于 “准确”,模型优化需平衡 “视觉质量” 与 “文本对齐”。
发现 4:所有模型均无法通过文本控制相机动作
尽管 Gen2、PikaLab 支持通过额外参数(如按钮、滑块)控制相机动作,但无法理解 “相机左移”“缓慢缩放” 等文本指令 —— 生成视频的相机运动与 prompt 描述完全无关。这说明 T2V 模型对 “相机运动语义” 的理解仍为空白。
发现 5:分辨率与视觉吸引力无显著关联
Gen2(896×512)、Hotshot-XL(672×384)的分辨率低于 ModelScope-XL(1280×720),但视觉质量(VQA_A、VQA_T)却更高。这证明 “高分辨率≠高视觉质量”,视频的清晰度、色彩协调性、无伪影比单纯的像素数量更重要。
发现 6:运动幅度并非越大越好
Motion AC-Score、Flow-Score 与人类评分呈负相关 —— 用户更偏好 PikaLab、Gen2 生成的 “轻微运动” 视频,而非 ZeroScope、Floor33 的 “大幅运动” 视频。这提示模型优化需聚焦 “运动自然性”,而非 “运动幅度”。
发现 7:文本生成仍是普遍难题
所有模型的 OCR-Score 均低于 60——ZeroScope、Floor33 生成的文字模糊、错字率高;即使表现最好的 Show-1,也无法稳定生成 “清晰、准确” 的文字(如 prompt 要求 “红色 U-Turn 标志”,生成的标志文字为 “U-Tm”)。这说明 T2V 模型在 “文本生成” 任务上仍需突破。
发现 8:部分开源模型存在 “灾难性遗忘”
ZeroScope、ModelScope、Floor33 等开源模型常生成 “完全错误” 的视频 —— 如 prompt 要求 “红色汽车行驶”,却生成 “蓝色摩托车静止”,且伴随严重噪声与扭曲。这源于 “灾难性遗忘”:这些模型基于 SD 微调时,丢失了 SD 对 “物体类别、颜色” 的理解能力。
发现 9:指标有效性差异显著,需谨慎选择
- 高有效性指标:Warping Error(时间一致性,ρ=69.0)、VQA_T(视觉质量,ρ=53.6)、BLIP-BLEU(文本对齐,ρ=26.7)与人类评分相关性高,可优先用于评测;
- 低有效性指标:CLIP-Score(文本对齐,ρ=6.3)、Flow-Score(运动幅度,ρ=-43.3)相关性低,单独使用易误导结论。
发现 10:现有模型仍有巨大提升空间
即使综合最优的 Gen2,也存在明显缺陷:
- 复杂场景处理差:无法生成 “多人互动 + 复杂背景” 的视频(如 “3 个孩子在公园玩足球,背景有树木与长椅”);
- 指令跟随弱:无法响应 “红色汽车变蓝色” 的动态指令;
- 实体细节差:生成的人类面部模糊、物体纹理不清晰。这证明 T2V 技术远未达到 “实用化” 阶段。
五、局限性与未来方向
EvalCrafter 虽为 T2V 评测提供了全面框架,但仍存在三点局限性,需在后续工作中优化:
-
基准规模与场景覆盖不足当前 700 个 prompt 虽覆盖四大元类别,但真实世界的 T2V 需求更复杂(如 “动态指令”“多模态输入”“长视频生成”)。未来需扩大基准至数千个 prompt,加入 “5 秒以上长视频”“文本 + 图像混合输入” 等场景。
-
运动质量评测维度单一现有指标仅能评估 “运动幅度”“动作识别”,无法评测 “运动的自然性”(如 “人类跑步姿势是否符合物理规律”)、“运动与场景的匹配性”(如 “鱼在空气中游泳” 的运动错误)。未来需结合视频理解模型,设计更精细的运动指标。
-
人类标注样本量小,可能存在偏差当前人类评分仅来自 7 名专业标注者,样本量小且人群单一(均为 AI 领域研究者),可能无法代表普通用户的偏好。未来需扩大标注团队,加入不同年龄、职业、地域的用户,减少主观偏差。
针对上述局限,论文提出三大未来方向:
- 动态更新基准:定期收集新的用户 prompt 与模型,更新基准集合,确保评测的时效性;
- 端到端评测模型:基于大量人机对齐数据,训练专门的 T2V 评测模型,替代 “多指标加权”,提升评测效率;
- 扩展评测维度:加入 “视频长度”“生成速度”“多轮指令跟随” 等工程化与交互维度,覆盖 T2V 模型的实际应用需求。
六、总结:EvalCrafter 的核心价值与行业影响
EvalCrafter 的核心价值在于:首次为 T2V 模型建立了 “真实基准 + 多维度指标 + 人类对齐” 的标准化评测体系,不仅解决了 “实验不可比、指标不贴合用户” 的行业痛点,更通过 10 个关键发现,为 T2V 技术迭代指明了清晰方向。
对研究者而言,EvalCrafter 的指标体系可指导模型优化优先级 —— 例如,优先提升 Warping Error(时间一致性)、BLIP-BLEU(文本对齐),而非单纯追求高分辨率;对开发者而言,700 个 prompt 基准可快速验证模型的 “场景适应性”,避免产品上线后才发现 “某类 prompt 完全失效”;对用户而言,模型的各维度排名可帮助选择更符合需求的工具(如 “文本对齐优先选 Show-1,视觉质量优先选 Gen2”)。EvalCrafter 指标体系奠定的 “多维度、人机对齐、真实场景” 评测原则,将成为 T2V 技术从 “实验室走向实用化” 的关键基石。