不定高虚拟列表性能优化全解析
在处理海量数据展示时,不定高虚拟列表是提升性能的关键技术。它通过动态计算和仅渲染可视区域内容,解决了一次性渲染大量DOM导致的性能瓶颈。下面我们详细分析其需求和实现方案。
为了让你快速建立整体认知,下表对比了定高与不定高虚拟列表的核心差异。
| 对比维度 | 定高虚拟列表 | 不定高虚拟列表 |
|---|---|---|
| 核心挑战 | 无,高度固定且已知 | 高度未知,需要在渲染后动态获取和修正 |
| 位置计算 | 简单算术:位置 = 索引 × 固定高度 | 复杂,需累加计算每个项的高度 |
| 关键技术 | 滚动事件处理、索引计算 | 预估高度、高度缓存、动态调整、二分查找 |
| 性能瓶颈 | 海量DOM节点 | 1. 初始高度计算 2. 动态内容(如图片)加载后的布局抖动 |
💡 核心实现方案
不定高虚拟列表的实现,核心思路是 “预估 → 渲染 → 测量 → 修正” 的循环过程。其架构主要包含以下几个关键部分:
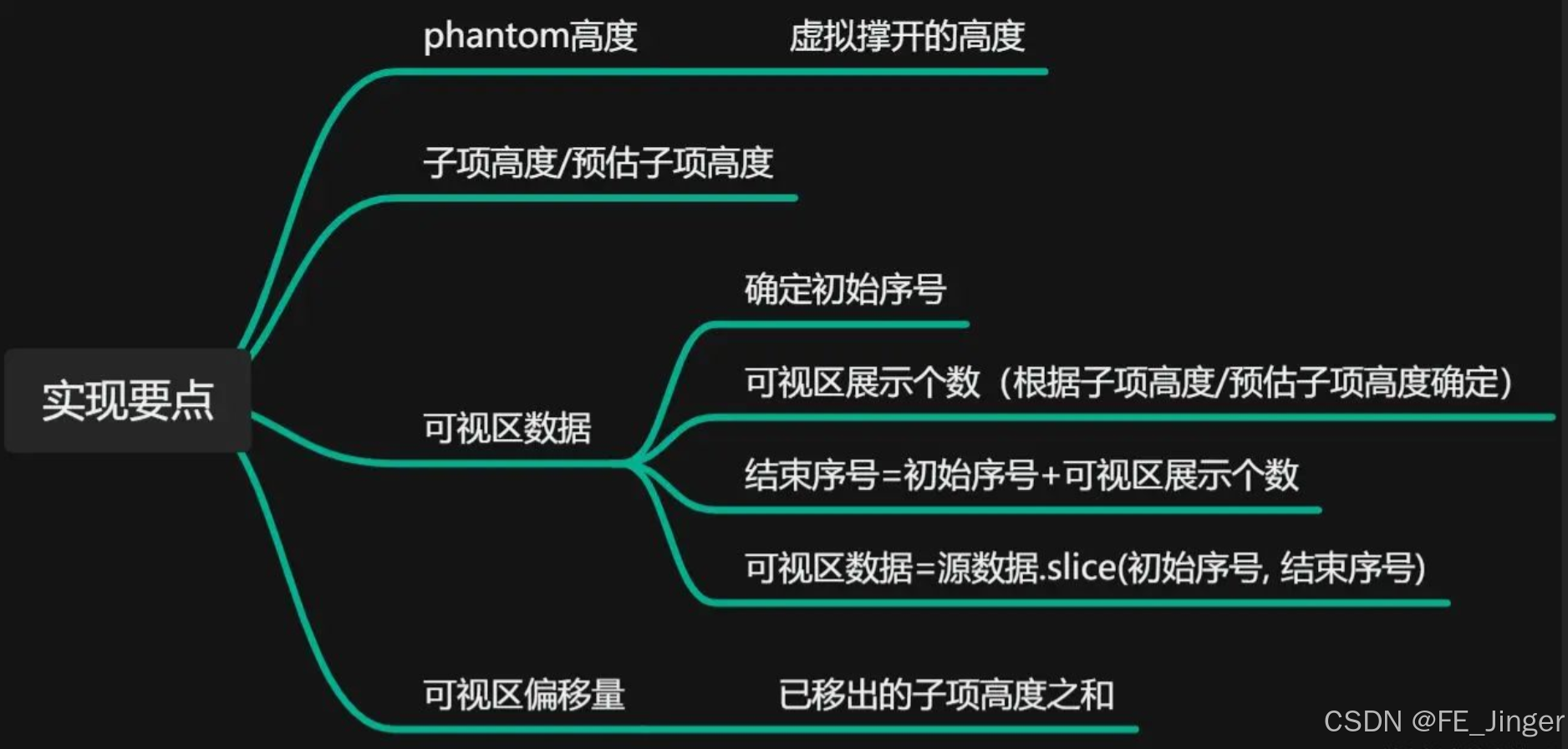
- 占位容器:一个具有完整列表总高度的不可见元素,用于撑起滚动条,模拟全部数据存在的场景。
- 可视区域容器:使用CSS
transform进行偏移,负责渲染当前可见的列表项。 - 位置缓存数组:一个核心数据结构,用于记录每个项的预估和实际高度、顶部位置和底部位置。这是动态计算的基础。
- 滚动监听与计算:监听滚动事件,通过算法确定哪些项应该被渲染。
具体实现步骤如下:
🔧 1. 初始化与预估
在数据加载后、项渲染前,你需要初始化一个“位置数组”。为每个项设置一个预估高度,并基于这个预估高度计算出它们的初始顶部和底部位置。
// 初始化位置数组
function initPositions(listData, estimatedHeight) {const positions = [];let top = 0;for (let i = 0; i < listData.length; i++) {positions.push({index: i,height: estimatedHeight, // 使用预估高度top: top,bottom: top + estimatedHeight,// 可标记是否为实际高度measured: false });top += estimatedHeight;}return positions;
}
列表的初始总高度就是最后一个项的bottom值。
🔧 2. 渲染与测量
基于滚动位置,计算出当前需要渲染的项(可视区域索引±缓冲区),并创建对应的DOM节点进行渲染。
关键的一步在渲染完成后:测量每个已渲染项的实际高度。这通常在框架的updated生命周期或使用MutationObserver、ResizeObserver中完成。
// 测量并更新高度
function updateHeights() {const visibleItems = document.querySelectorAll('.visible-item');visibleItems.forEach(node => {const index = parseInt(node.dataset.index);const realHeight = node.getBoundingClientRect().height;const oldHeight = positions[index].height;// 如果高度发生变化if (realHeight !== oldHeight) {const diff = realHeight - oldHeight;// 更新当前项的高度和位置positions[index].height = realHeight;positions[index].bottom = positions[index].top + realHeight;positions[index].measured = true;// 关键:更新后续所有项的位置for (let j = index + 1; j < positions.length; j++) {positions[j].top += diff;positions[j].bottom += diff;}// 更新占位容器的高度(列表总高度)totalHeight = positions[positions.length - 1].bottom;}});
}
🔧 3. 滚动与查找
当用户滚动时,需要根据滚动条的scrollTop值,快速找到应该显示在可视区域顶部的第一个项。由于位置数组中的bottom值是递增的,可以使用二分查找来优化性能,避免循环遍历。
// 使用二分查找获取起始索引
function getStartIndex(scrollTop, positions) {let left = 0;let right = positions.length - 1;let result = 0;while (left <= right) {const mid = Math.floor((left + right) / 2);if (positions[mid].bottom < scrollTop) {left = mid + 1;} else if (positions[mid].top > scrollTop) {right = mid - 1;} else {// 找到scrollTop所在的项result = mid;break;}}// 如果没精确匹配,left是第一个bottom大于scrollTop的项return left;
}
找到起始索引后,结合容器高度计算出结束索引,并设置可视区域容器的偏移量(transform: translateY)为起始项对应的top值。
🚀 优化策略与注意事项
实现基本功能后,以下优化能极大提升体验和稳定性:
- 缓冲区设置:在可视区域的上方和下方多渲染一些项(如3-5个),避免快速滚动时出现白屏。
- 高度缓存:将已测量的项的实际高度持久化存储(如使用
Map),避免重复测量。 - 防抖滚动监听:对滚动事件进行防抖处理,减少计算频率。
- 处理动态内容:如果项内包含图片等异步加载内容,需要在内容加载完成后(例如监听
img的onload事件)再次触发高度测量和位置更新。使用ResizeObserver是更现代的解决方案。 - 性能权衡:首次加载时遍历所有项计算位置可能较慢。可根据需要,仅在项进入视口时才测量其高度,但滚动条在初始时会有跳跃现象。
💎 总结
实现不定高虚拟列表是一个“动态逼近”的过程。通过预估高度初始化、渲染后精确测量、动态更新后续项位置、高效查找可视范围这套组合拳,可以在保证性能的同时,优雅地处理高度不定的海量数据列表。
理解不定高虚拟列表的实现,确实是前端面试中的一个高频且能体现技术深度的考点。它考察的不仅是你对性能优化的理解,更是对JavaScript、DOM操作和数据结构的综合应用能力。
下面我将为你详细解析其核心原理、关键技术实现以及面试应答思路。
🔍 核心思想与核心挑战
虚拟列表的核心思想很简单:只渲染可视区域内的列表项,通过动态计算和DOM复用,来支撑海量数据的流畅展示。
当列表项高度不固定时,挑战就出现了:
- 无法简单计算:在定高情况下,
startIndex = Math.floor(scrollTop / itemHeight)就能精准定位。但高度不固定时,这个公式失效了。 - 滚动条准确性:如何让滚动条正确反映整个列表的真实长度,而不是基于一个预估高度。
- 动态内容处理:列表项内容可能包含图片等异步加载的资源,加载完成后高度会变化,需要动态调整。
🧠 关键技术实现
解决不定高问题的核心思路是 “预估 → 渲染 → 测量 → 修正”。下图清晰地展示了这一闭环工作流程:
下面我们重点剖析流程中的几个关键环节。
1. 核心数据结构:positions 数组
这是实现不定高虚拟列表的大脑,它记录了每个列表项的精确位置信息。通常是一个数组,每个元素包含:
const positions = [{ index: 0, height: 80, top: 0, bottom: 80, measured: true },{ index: 1, height: 120, top: 80, bottom: 200, measured: true },{ index: 2, height: 60, top: 200, bottom: 260, measured: false },// ...
];
top、bottom:表示该列表项顶部和底部相对于整个列表起始位置的像素值。height:该列表项的实际高度(或初始化的预估高度)。measured:标记此高度是否已被实际测量过。
列表的总高度就是最后一个元素的 bottom 值,这个值用于设置占位元素的高度,从而撑起正确的滚动条。
2. 高效查找:二分查找定位 startIndex
在定高情况下,我们可以用 scrollTop / itemHeight 快速算出起始索引。在不定高情况下,由于 positions 数组中每个项的 bottom 值是单调递增的,我们可以使用二分查找来快速定位,将时间复杂度从O(n)降为O(log n)。
查找逻辑是:找到 positions 中第一个 bottom 值大于当前滚动条scrollTop的项,该项的 index 就是 startIndex。
3. 动态测量与连锁更新
这是实现不定高虚拟列表最精巧的一步,对应流程图中的“测量”和“更新”环节:
- 测量真实高度:当列表项被渲染到DOM后,通过
getBoundingClientRect()或offsetHeight获取其真实高度。 - 计算高度差:比较真实高度与
positions中记录的高度(可能是预估高度),得到差值diff。 - 连锁更新:如果
diff !== 0,则需要:- 更新当前项:修正当前项在
positions中的height和bottom。 - 更新后续所有项:因为当前项的高度变了,后面所有项的位置(
top和bottom)都需要同步更新。这是保证位置计算准确的关键。 - 更新总高度:更新完成后,列表的总高度(最后一个项的
bottom)也会改变,需要同步更新占位元素的高度。
- 更新当前项:修正当前项在
💡 面试进阶考察点
当你讲清楚基本原理后,面试官可能会深入追问以下问题,请做好准备:
| 考察点 | 问题示例 | 应答思路 |
|---|---|---|
| 性能优化 | “如何避免频繁重排(Reflow)?” | 提及使用 requestAnimationFrame 对滚动事件进行节流,以及使用 transform: translateY 进行偏移,因为这属性通常不会触发重排。 |
| 数据结构 | “为什么用二分查找?还有其他方法吗?” | 强调 positions 数组的有序性(bottom递增)使得二分查找成为最优解。可以对比线性查找的低效。 |
| 边界处理 | “如果列表项高度动态变化(如图片加载)怎么办?” | 提出使用 ResizeObserver API来监听列表项尺寸的变化,并在变化时重新触发测量和更新流程。 |
| 缓冲区设计 | “快速滚动时如何避免白屏?” | 说明会在可视区域的上方和下方多渲染一部分“缓冲区”项目,例如 startIndex - bufferSize 到 endIndex + bufferSize。 |
🚀 面试应答策略
- 开场定性:“不定高虚拟列表是解决海量不规则数据展示性能问题的关键技术,其核心在于动态测量和精准定位。”
- 阐述核心数据结构:首先说明
positions数组的作用和结构,这是理解所有后续步骤的基础。 - 分步解析流程:按照“初始化预估 -> 渲染测量 -> 动态修正 -> 滚动查找”的逻辑顺序讲解,并强调二分查找的重要性。
- 主动提及优化和边界:在讲完基础后,可以主动说:“在实际实现中,我们还会考虑……(例如缓冲区、ResizeObserver等)”,这能展示你的经验深度。
- 总结优势:最后总结虚拟列表如何通过减少DOM数量、精准计算来提升性能。
🎯 核心思想与架构示意图
不定高虚拟列表的核心思想是:只渲染可视区域及其附近的少量列表项,通过动态计算和调整,模拟出完整长列表的滚动体验。 其架构主要由三部分组成:
flowchart TDA[外部容器] --> A1[固定高度,监听滚动]B[占位元素] --> B1[撑开滚动条,高度为列表总高]C[可视区域] --> C1[通过Transform控制偏移]C1 --> C2[仅渲染可见项及缓冲区项]A1 --> D[滚动触发计算]B1 --> DD --> E[计算可见项起始索引<br>(使用二分查找)]D --> F[计算偏移量]E --> G[更新可视区域渲染项]F --> G
各组件职责说明:
- 外部容器 (Viewport Container):设有固定高度和
overflow-y: auto,是滚动事件的监听者。 - 占位元素 (Placeholder Element):一个绝对定位的元素,其高度被设置为所有列表项高度的总和,唯一作用就是撑起滚动条,模拟出完整列表的存在。
- 可视区域 (Visible Region):实际渲染列表项的区域。它通过
transform: translateY(offset)在容器内进行偏移,从而制造出滚动效果。其内部只渲染当前需要显示的列表项。
💡 实现步骤与关键技术
下面我们深入实现不定高虚拟列表的几个关键技术点。
1. 初始化与预估高度
由于项的高度不固定,在开始阶段我们需要一个预估高度(estimatedHeight)来初始化每个项的位置信息(positions数组)和占位元素的总高度。
// 初始化位置数组
function initPositions(data, estimatedHeight) {const positions = [];let top = 0;for (let i = 0; i < data.length; i++) {positions.push({index: i,height: estimatedHeight, // 使用预估高度top: top, // 项顶部距离列表顶部的距离bottom: top + estimatedHeight, // 项底部距离列表顶部的距离measured: false // 标记是否已被测量过真实高度});top += estimatedHeight;}return positions;
}
// 列表初始总高度即为最后一个项的bottom值
const totalHeight = positions[data.length - 1].bottom;
2. 渲染、测量与动态校正
这是实现不定高虚拟列表最核心的步骤,遵循 “预估 → 渲染 → 测量 → 修正” 的循环。
- 渲染可见项:根据滚动位置,计算出需要渲染的项(通常是可视区域内的项加上上下缓冲区)。
- 测量真实高度:在项被渲染到DOM后(例如,在Vue的
onUpdated生命周期或使用ResizeObserver),立即通过getBoundingClientRect()获取其真实高度。 - 动态校正与连锁更新:比较真实高度与预估高度,计算出差值(
diff)。然后,更新当前项在positions数组中的高度和底部位置。最关键的一步是,由于当前项的高度变化,其后所有项的位置(top和bottom)都需要进行连锁更新。
// 测量并更新位置的函数
function updatePositions(renderedItems, positions) {renderedItems.forEach(node => {const index = parseInt(node.dataset.index); // 获取项的唯一标识const actualHeight = node.getBoundingClientRect().height;const oldHeight = positions[index].height;const diff = actualHeight - oldHeight;if (diff !== 0) {// 1. 更新当前项positions[index].height = actualHeight;positions[index].bottom += diff;positions[index].measured = true;// 2. 连锁更新后续所有项的位置for (let j = index + 1; j < positions.length; j++) {positions[j].top += diff;positions[j].bottom += diff;}}});// 3. 更新占位元素的总高度totalHeight = positions[positions.length - 1].bottom;
}
3. 高效计算可见区域(二分查找)
当用户滚动时,我们需要根据滚动条的scrollTop快速找到应该显示在可视区域顶部的第一个项(startIndex)。由于positions数组中的bottom值是单调递增的,我们可以使用二分查找,将时间复杂度从O(n)优化到O(log n),这对于万级数据量至关重要。
// 使用二分查找获取起始索引
function binaryFindStartIndex(scrollTop, positions) {let left = 0;let right = positions.length - 1;let result = 0;while (left <= right) {const mid = Math.floor((left + right) / 2);if (positions[mid].bottom < scrollTop) {left = mid + 1;} else if (positions[mid].top > scrollTop) {right = mid - 1;} else {// 找到scrollTop所在的项result = mid;break;}}// 如果没精确匹配,left是第一个bottom大于scrollTop的项return left;
}
找到startIndex后,offset(可视区域的Y轴偏移量)就是positions[startIndex].top。
🚀 优化策略与面试亮点
在解释完基本原理后,可以补充以下优化策略,这会让面试官眼前一亮:
- 设置缓冲区 (Buffer):在计算实际渲染项时,除了可视区域内的项,多在上下方多渲染几个(例如各多渲染3个)。这可以有效避免快速滚动时出现白屏。
- 高度缓存:将已经测量过的项的真实高度进行持久化存储(例如使用
Map),避免重复测量。 - 使用 ResizeObserver:对于内容可能动态变化的项(如图片加载),使用
ResizeObserver来监听其尺寸变化,并触发重新测量和位置校正,这比在updated生命周期中处理更精确和高效。 - 性能优化:对滚动事件进行防抖(或使用
requestAnimationFrame)以减少计算频率。
💎 总结与面试应答思路
面试官:“请介绍一下不定高虚拟列表如何实现。”
你可以这样回答:
“不定高虚拟列表的核心思路是‘动态逼近’。首先,我们需要一个预估高度来初始化所有项的位置信息和撑起滚动条的占位元素总高。
滚动时,通过二分查找根据scrollTop快速定位到起始项。然后渲染可视区域及缓冲区的项,项被渲染后立即测量其真实高度。如果与预估高度有差异,就动态校正该项的高度,并连锁更新其后所有项的位置以及列表总高度。
整个过程可以概括为‘预估、渲染、测量、修正’。为了保证体验,我们还会采用设置缓冲区、缓存已测量高度等优化策略。这样,我们就用有限的DOM节点,流畅地渲染了海量不定高的数据。”