一种简单的Yolov8 onnx模型类别标签获取的方法
以下介绍一种使用C# FileStream直接读取onnx模型,获取类标签的方法
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
public class OnnxClassExtractor
{
/// <summary>
/// 从ONNX文件中提取类别名称(内存优化版本)
/// </summary>
/// <param name="filePath">ONNX文件路径</param>
/// <returns>类别名称数组</returns>
public static string[] ExtractClassNames(string filePath)
{
try
{
using (var fileStream = new FileStream(filePath, FileMode.Open, FileAccess.Read))
using (var streamReader = new StreamReader(fileStream, Encoding.UTF8))
{
string line;
while ((line = streamReader.ReadLine()) != null)
{
if (line.Contains("names"))
{
return ParseNamesLine(line);
}
}
}
}
catch (Exception ex)
{
Console.WriteLine($"读取ONNX文件时出错: {ex.Message}");
}
return new string[0];
}
/// <summary>
/// 解析包含names信息的行
/// </summary>
private static string[] ParseNamesLine(string line)
{
try
{
// 查找花括号开始和结束的位置
int braceStart = line.IndexOf('{');
int braceEnd = line.LastIndexOf('}');
if (braceStart < 0 || braceEnd < 0 || braceEnd <= braceStart)
{
Console.WriteLine("未找到有效的花括号");
return new string[0];
}
// 提取花括号内的内容
string content = line.Substring(braceStart + 1, braceEnd - braceStart - 1);
return ParseClassNames(content);
}
catch (Exception ex)
{
Console.WriteLine($"解析names行时出错: {ex.Message}");
return new string[0];
}
}
/// <summary>
/// 解析类别名称
/// </summary>
private static string[] ParseClassNames(string content)
{
var classNames = new List<string>();
try
{
int index = 0;
int length = content.Length;
while (index < length)
{
// 跳过空白字符
while (index < length && char.IsWhiteSpace(content[index]))
index++;
if (index >= length) break;
// 查找数字部分(索引)
int numberStart = index;
while (index < length && char.IsDigit(content[index]))
index++;
if (index >= length) break;
// 跳过冒号和可能的空白
while (index < length && (content[index] == ':' || char.IsWhiteSpace(content[index])))
index++;
if (index >= length) break;
// 确定引号类型
char quoteChar = content[index];
if (quoteChar != '\'' && quoteChar != '"')
{
// 如果没有引号,尝试找到逗号或结束位置
int nameStart = index;
while (index < length && content[index] != ',')
index++;
string classname = content.Substring(nameStart, index - nameStart).Trim();
if (!string.IsNullOrEmpty(classname))
classNames.Add(classname);
index++; // 跳过逗号
continue;
}
// 处理带引号的字符串
index++; // 跳过开始引号
int nameStartIndex = index;
// 查找结束引号,注意处理转义情况
while (index < length)
{
if (content[index] == quoteChar)
{
// 检查是否是转义的引号
if (index > 0 && content[index - 1] == '\\')
{
index++;
continue;
}
break;
}
index++;
}
if (index >= length)
{
// 没有找到结束引号,使用当前位置作为结束
index = length;
}
string className = content.Substring(nameStartIndex, index - nameStartIndex);
// 处理转义字符
className = className.Replace("\\'", "'").Replace("\\\"", "\"");
if (!string.IsNullOrEmpty(className))
classNames.Add(className);
index++; // 跳过结束引号
// 跳过逗号和空白
while (index < length && (content[index] == ',' || char.IsWhiteSpace(content[index])))
index++;
}
}
catch (Exception ex)
{
Console.WriteLine($"解析类别名称时出错: {ex.Message}");
}
return classNames.ToArray();
}
/// <summary>
/// 优化的版本 - 使用缓冲区读取,适用于大文件
/// </summary>
public static string[] ExtractClassNamesOptimized(string filePath, int bufferSize = 4096)
{
try
{
using (var fileStream = new FileStream(filePath, FileMode.Open, FileAccess.Read))
{
byte[] buffer = new byte[bufferSize];
StringBuilder lineBuilder = new StringBuilder();
int bytesRead;
while ((bytesRead = fileStream.Read(buffer, 0, buffer.Length)) > 0)
{
string chunk = Encoding.UTF8.GetString(buffer, 0, bytesRead);
lineBuilder.Append(chunk);
// 检查当前缓冲区是否包含names
string currentText = lineBuilder.ToString();
if (currentText.Contains("names"))
{
return ParseNamesLine(ExtractCompleteLine(currentText, "names"));
}
// 如果缓冲区太大,保留最后一部分以避免内存过度使用
if (lineBuilder.Length > bufferSize * 2)
{
string remaining = lineBuilder.ToString();
int keepFrom = Math.Max(0, remaining.Length - bufferSize);
lineBuilder = new StringBuilder(remaining.Substring(keepFrom));
}
}
}
}
catch (Exception ex)
{
Console.WriteLine($"优化读取ONNX文件时出错: {ex.Message}");
}
return new string[0];
}
/// <summary>
/// 从文本中提取包含关键字的完整行
/// </summary>
private static string ExtractCompleteLine(string text, string keyword)
{
int keywordIndex = text.IndexOf(keyword);
if (keywordIndex < 0) return string.Empty;
// 查找行开始
int lineStart = keywordIndex;
while (lineStart > 0 && text[lineStart - 1] != '\n' && text[lineStart - 1] != '\r')
lineStart--;
// 查找行结束
int lineEnd = keywordIndex;
while (lineEnd < text.Length && text[lineEnd] != '\n' && text[lineEnd] != '\r')
lineEnd++;
return text.Substring(lineStart, lineEnd - lineStart).Trim();
}
}
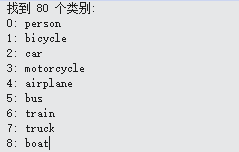
使用方法:
string onnxFilePath = @"D:\ultralytics-main\yolov8s.onnx";// 方法1: 流式逐行读取(内存效率高)string[] classNames1 = OnnxClassExtractor.ExtractClassNames(onnxFilePath);// 方法2: 缓冲区读取(适用于大文件)string[] classNames2 = OnnxClassExtractor.ExtractClassNamesOptimized(onnxFilePath);if (classNames1.Length > 0){Console.WriteLine($"找到 {classNames1.Length} 个类别:");for (int i = 0; i < classNames1.Length; i++){Console.WriteLine($"{i}: {classNames1[i]}");}}else{Console.WriteLine("未找到类别名称");}// 验证两种方法结果是否一致if (classNames1.Length == classNames2.Length){Console.WriteLine("两种方法结果一致");}部分结果如下: