解决时序违例(四)
解决时序违例(四)
文章目录
- 解决时序违例(四)
- 前言
- 1. 逻辑延迟
- 2. 布线延迟
- 3. 降低时钟歪斜
- 4.降低时钟不确定性
前言
对于解决时序违例,也是从四个个部分进行,逻辑延迟,布线延迟,时钟偏斜和不确定性
1. 逻辑延迟
逻辑延迟的根本就是少器件
可通过report_timing、report_timing_summary或report_design_ analysis获取逻辑延迟并分析其对时序的影响。
常规路径是指源端和目的端均为触发器或移位寄存器的路径,且中间逻辑单元为LUT、MUXF或进位链(Carry Chain)。这类路径在设计中最为常见,也是时序违例的常见情形
下图整体来说就是,映射和整理
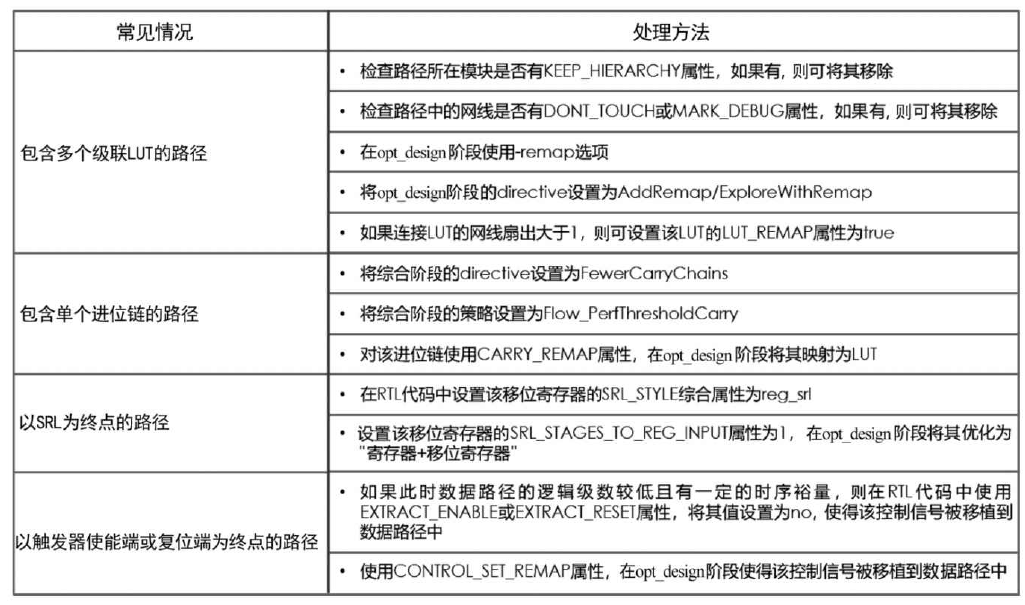
此外,还有一个十分需要注意的是,在写代码或者使用IP时,入股需要跑高时钟频率,一定要使用BLOCK(这里的Block是指DSP48、Block RAM、UltraRAM和GT_CHANNEL)内部的FF

下图是使用BLOCK的三种情况
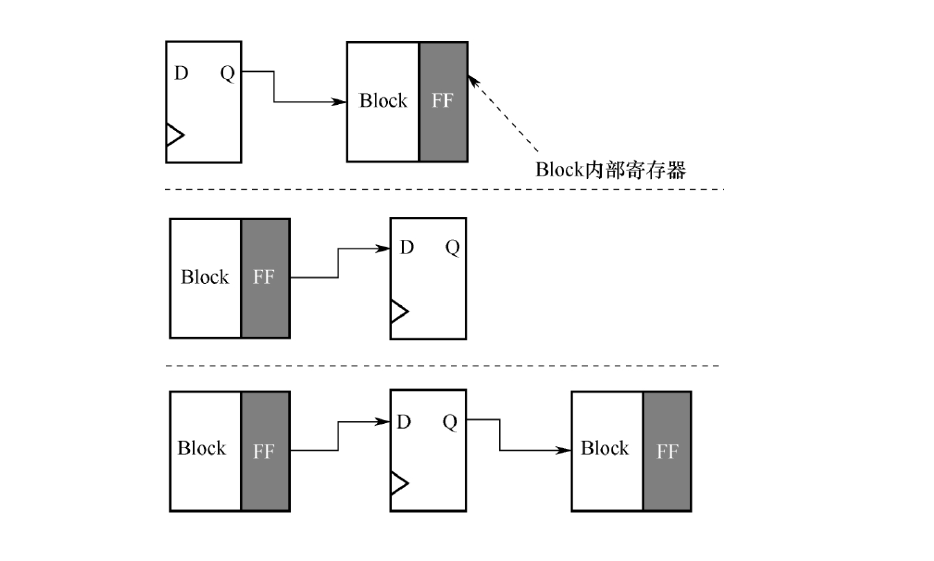
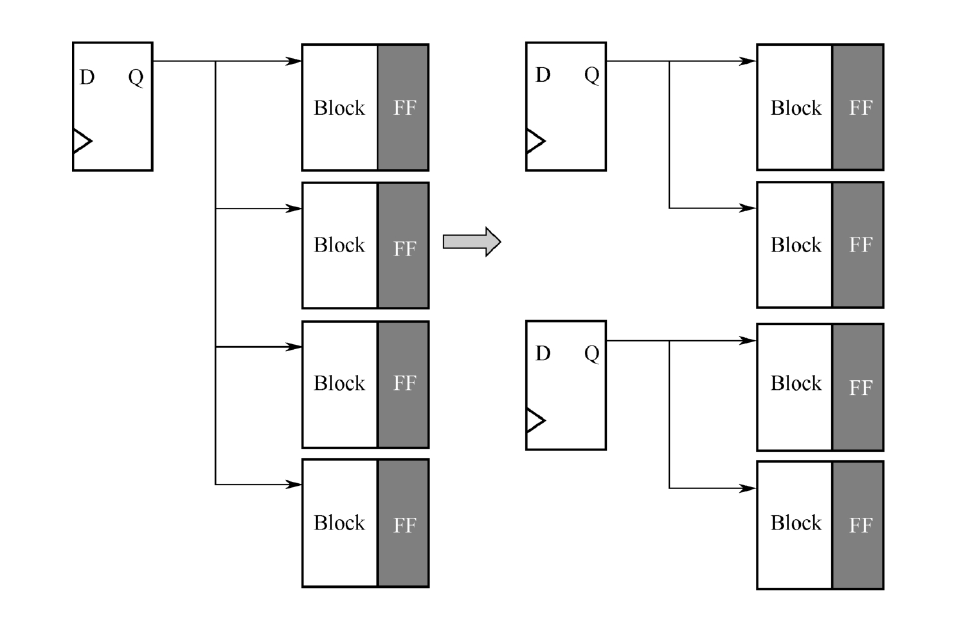
此外,连接到这些Block的控制端口,如使能信号、地址信号等,应尽可能地保证低扇出,否则,应复制寄存器以降低扇出
不同于常规的“FF+LUT+FF”路径,在布局之前,应保证包含Block的路径建立时间裕量能够达到500ps
2. 布线延迟
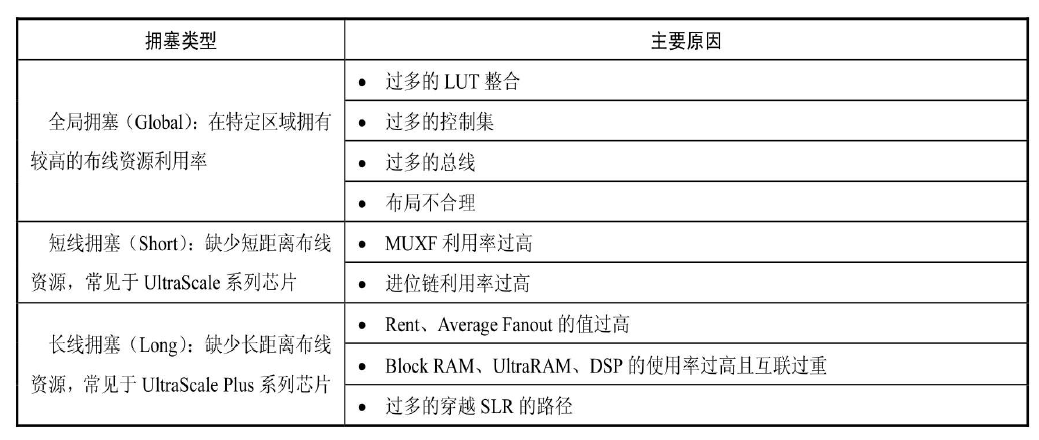
布线延迟的根本在于这块区域的布线资源用的差不多了,也就是拥挤
通常基于布局(place_design)阶段生成的DCP

生成设计复杂度报告
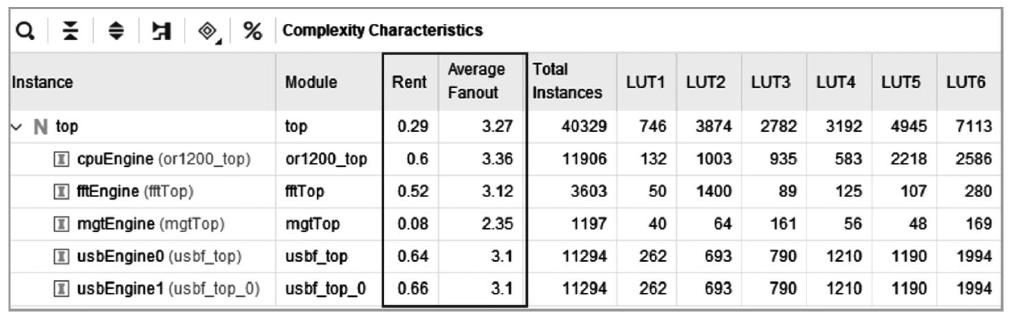
在该报告中应着重关注Rent和Average Fanout的值。Rent或AverageFanout的值越大,说明该模块与其他模块的互联越重。当Rent > 0.5或Average Fanout > 5时,应引起注意,说明该设计很可能出现布线拥塞。
造成拥塞的原因包括过多的MUXF、过长的进位链、过多的控制集、过多的LUT整合等。解决的方法,简单来说就是减少扎堆,尽可能的整合MUXF和进位链,和分散LUT(过大的LUT整和也会造成资源的集中)。或者直接选择更适合重映射的策略,当然这是全局,经可能得选择模块化的策略
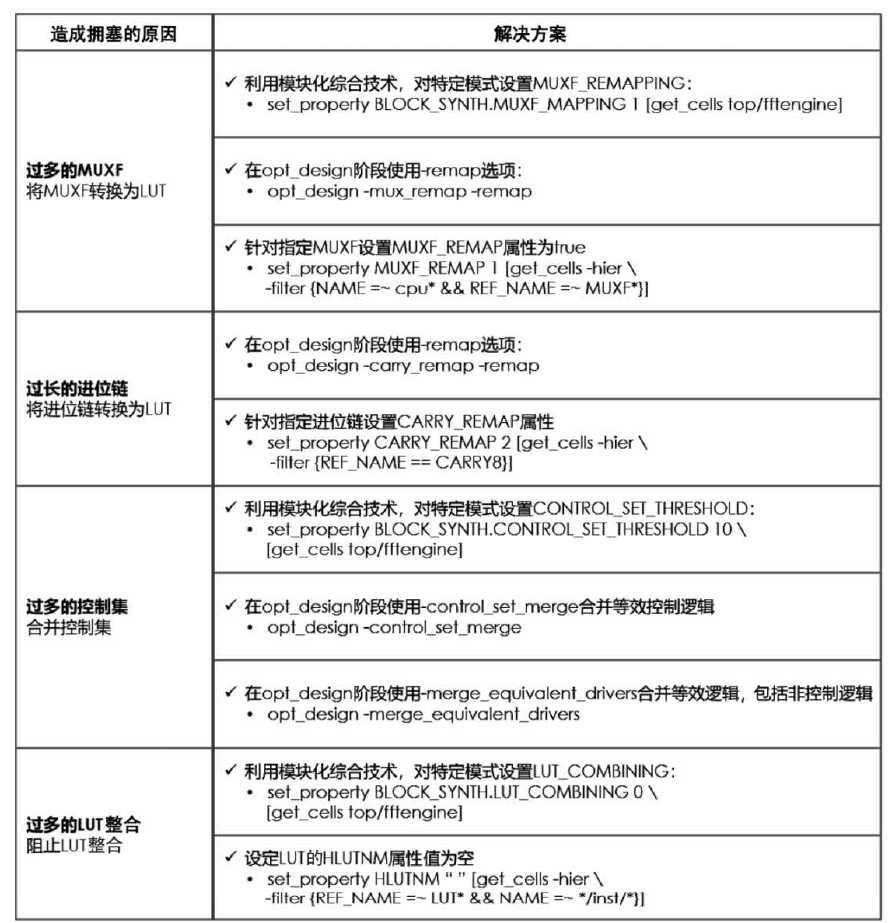
在综合阶段,模块化综合技术是一个很好的方法,可用来将MUXF转换为LUT、将进位链转换为LUT、阻止LUT整合、降低控制集的个数。此外,也可考虑使用OOC综合方式。在实现阶段,可通过选择合适的策略缓解拥塞,如图5.46所示。其中,对于UltraScale芯片,可尝试采用“Congestion_”策略缓解拥塞;对于UltraScale Plus芯片,可尝试采用“Performance_NetDelay_”策略缓解拥塞。
3. 降低时钟歪斜
通常情况下,对于同一时钟下的时序路径,Clock Skew不应超过300ps;对于同步的跨时钟域路径,Clock Skew不应超过500ps。否则,如果相应路径的时序未收敛,就要考虑Clock Skew过大这个因素。
- 对于源时钟和目的时钟为同一时钟的情形(这种情形最为常见),通常Clock Skew会比较低
- 同步跨时钟域路径,一般用代码规避
- 异步跨时钟域路径,一般用代码规避
- 在使用BUFG时,应注意避免BUFGCE级联或不必要的并联(当使用BUFG_GT时,需要注意BUFG_GT可实现分频功能,①中的电路需要通过MMCM实现二分频;②中的电路使用两个BUFG_GT,通过对第2个BUFG_GT的参数DIV进行设置实现二分频,从而节省了1个MMCM。)
4.降低时钟不确定性
时钟不确定性(Clock Uncertainty)是相对于理想时钟而言的,它源于外部输入时钟自身的不确定性、系统抖动或占空比失真,同时由MMCM或PLL引起的输出抖动和相位误差(Phase Error)也会造成时钟的不确定性。因此,降低Clock Uncertainty可从下面几方面着手。
- 在使用Clocking Wizard 时, 选项Minimize Output Jitter 可用于提升VCO频率。
如果是分频关系, 则可根据输出时钟频率之间的关系, 通过BUFGCE_DIV实现分频。相比于通过MMCM实现分频,BUFGCE_DIV不会引入相位误差,从而达到降低Clock Uncertainty的目的。需要注意的是,BUFGCE和BUFGCE_DIV的特性是不一样的,因此为了保证clk1x和clk2x的相位一致,clk2x也要通过BUFGCE_DIV输出,只需把分频因子设置为1即可。
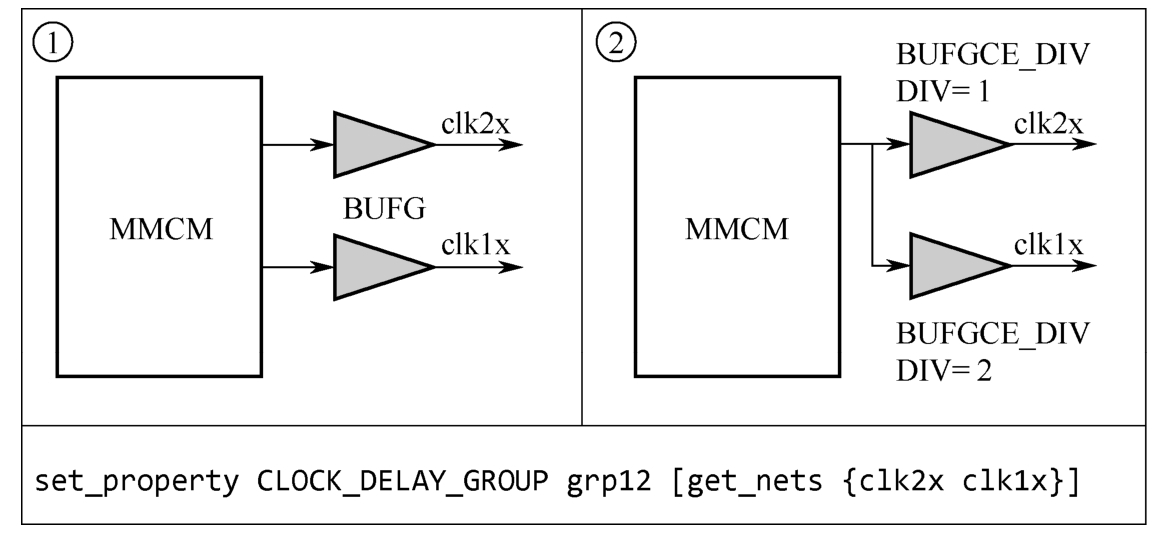
- 在使用CLOCK_DELAY_GROUP 时, 命令中的网线为由BUFGCE_DIV驱动的网线,也就是连接BUFGCE_DIV输出端口的网线,而不是输入端口的网线。
- CLOCK_DELAY_GROUP 是 Xilinx 给同根时钟网打的“同班车标签”——标签相同的时钟网,Vivado 会在布局布线阶段强制把它们的插入延迟(Insertion Delay)调到几乎相等,从而把时钟歪斜(Clock Skew)压到最低。您可使用 CLOCK_DELAY_GROUP 约束来匹配由不同时钟缓冲器驱动的多个相关时钟网络的插入延迟。此约束常用于最大限度减少源自相同 MMCM、PLL 或 GT 来源的时钟之间的同步 CDC 时序路径上的偏移
为什么必须用它?——解析
同根时钟→不同 BUFG 输出→插入延迟天生不对称→Skew > 500 ps→保持时间先爆
打标签后→工具把 BUFG 对位到相邻时钟列→走线长度/缓冲级数匹配→Skew 降 30~50 ps
只在 UltraScale/UltraScale+/Versal 有效→7 系列没有此属性